pytorch中.to(device) 和.cuda()的区别
在PyTorch中,使用GPU加速可以显著提高模型的训练速度。在将数据传递给GPU之前,需要将其转换为GPU可用的格式。
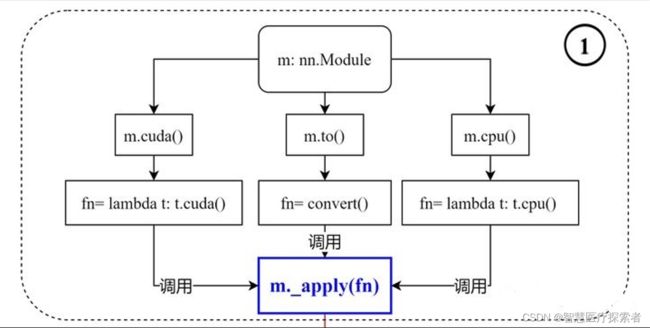
函数原型如下:
def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
return self._apply(lambda t: t.cuda(device))
def cpu(self: T) -> T:
return self._apply(lambda t: t.cpu())
def to(self, *args, **kwargs):
...
def convert(t):
if convert_to_format is not None and t.dim() == 4:
return t.to(device, dtype if t.is_floating_point() else None, non_blocking, memory_format=convert_to_format)
return t.to(device, dtype if t.is_floating_point() else None, non_blocking)
return self._apply(convert)1 .to(device)
.to(device)是PyTorch中的一个方法,可以将张量、模型转换为指定设备(如CPU或GPU)可用的格式。示例代码如下:
import torch
# 创建一个张量
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(x)
# 将张量转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.to(device)
print(x)运行结果如下:
tensor([[1., 2., 3.],
[4., 5., 6.]])
tensor([[1., 2., 3.],
[4., 5., 6.]], device='cuda:0')在上述代码中,我们首先创建了一个形状为(2, 3)的张量x,然后使用x.to(device)将其转换为GPU可用的格式。其中,device是一个torch.device对象,可以使用torch.cuda.is_available()函数来判断是否支持GPU加速。
import torch
from torch import nn
from torch import optim
# 创建一个模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
net = Net()
# 将模型参数和优化器转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = net.to(device)
print(net)
optimizer = optim.SGD(net.parameters(), lr=0.01)运行结果显示如下:
Net(
(fc1): Linear(in_features=3, out_features=2, bias=True)
(fc2): Linear(in_features=2, out_features=1, bias=True)
)在上述代码中,首先创建了一个模型net,然后使用net.to(device)将其模型参数转换为GPU可用的格式。
2 .cuda()
.cuda()是PyTorch中的一个方法,可以将张量、模型转换为GPU可用的格式,示例代码如下:
import torch
# 创建一个张量
x = torch.Tensor([[1, 2, 3], [4, 5, 6]])
print(x)
# 将张量转换为GPU可用的格式
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
x = x.cuda()
print(x)运行结果显示如下:
tensor([[1., 2., 3.],
[4., 5., 6.]])
tensor([[1., 2., 3.],
[4., 5., 6.]], device='cuda:0')在上述代码中,我们首先创建了一个形状为(2, 3)的张量x,然后使用x.cuda()将其转换为GPU可用的格式。
import torch
from torch import nn
from torch import optim
# 创建一个模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
net = Net()
# 将模型参数和优化器转换为GPU可用的格式
net = net.cuda()
optimizer = optim.SGD(net.parameters(), lr=0.01)在上述代码中,首先创建了一个模型net,然后使用net.cuda()将模型转换为GPU可用的格式。
3 总结
推荐使用to(device)的方式,主要原因在于这样的编程方式更加易于扩展,而cuda()必须要求机器有GPU,否则需要修改所有代码;to(device)的方式则不受此限制,device既可以是CPU也可以是GPU;