Python实战案例:旅游方面博文的数据分析
Python实战案例:旅游方面博文的数据分析
一、旅游方面博文数据展示
数据分析的出现便利了每个人,企业,竞争者。在以前的时候,如果想要了解市场的动向,就设计了调查问卷或者现场采访的方式,以至于被很多人误以为不法之举。而如今如果在想了解市场,我们只需要简单的设计和建立一个数据库,以此来监测人们的行为和动向,一段时间之后,数据结果自然会告知你一切。在很多的时候,爬虫工程师爬取数据之后,都需要进行后续的数据分析。
这里以旅游微博的数据分析为例。旅游微博的数据是以excel表展现的,这个项目中的excel表有五个表格。
其中all表是第一张表格,表中的数据是具体微博的每一篇博文,对应每篇博文的转发数,评论数和点赞数,以及发表博文的时间。表中的内容如下图所示。
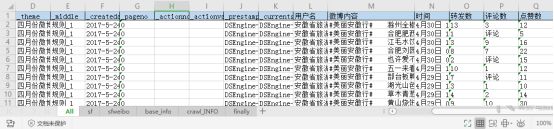
其中sf表说明省份名的简称。表中的内容如下图所示。

其中sfweibo表说明微博名称及省份简称的对应关系。表中的内容如下图所示。

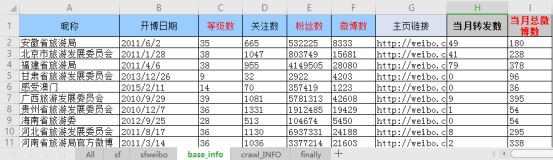
其中base_info表说明微博的名称及微博的信息情况,如发表的微博数、粉丝数及微博的关注数。表中的内容如下图所示。
其中crawl_info是从网上爬取的各旅游局四月份的微博情况,从网上爬取相关的粉丝数、微博数、转发数。

其中最后形成的final表中的结果。

二、旅游方面博文的数据处理
首先,这些数据是存储在excel表中的,需要从excel表中把数据读取出来。读取excel表的方法是read_excel,代码如下。
data=pandas.read_excel('test1.xlsx')
如果读取的是其中某个表格,则把表格的名字带上就可以。
data=pandas.read_excel('test1.xlsx',sheet_name=”sf”)
这样的语句就是读取text1.xlsx中的sf表。
如果没有加sheet_name,则默认会读取第一张表。
读出的数据字段包括了很多,这里有的字段是有分析的必要,有的字段不需要使用。输出表中所有字段的语句是:
data.columns
执行此语句后,最终的输出结果如下图所示。

从图中可以看出,从“用户名”开始,到“点赞数”为止,是对数据分析有意义的字段,可以通过切片的方法对几列的数据进行提取。代码如下。
data=data.iloc[:,11:-1]
这句实际上就是使用切片的方法提取从11列到倒数第二列的有意义的列数据。
提取到有效字段的数据以后,需要查看数据中是否有重复数据,判断数据中是否重复是data.duplicated(),语句可以输出布尔型数据,这些在布尔型数据表明了数据是否是重复的。具体哪些数据是重复的,可以通过data[data.duplicated()==True]这种语句形式显示出来,如果需要引用前几十条数据,可以通过语句data[data.duplicated()==True][:20],这样显示的是前20条重复的数据。调用语句后最终的结果如图所示。
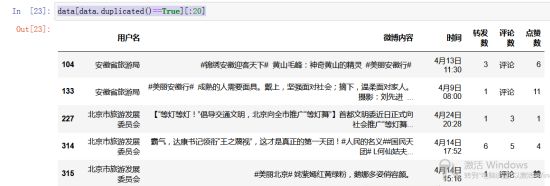
从执行结果的图示来看,表中的数据是有重复数据的,对于博文来讲,重复的数据就没有任何意义了,直接删除掉即可,pandas模块中drop_duplicates(inplace=True)方法可以删除重复的数据,inplace=True表示删除重复数据后的数据是覆盖原数据的,如果没有inplace=True删除后的数据不覆盖原有数据。执行结果如下图所示。

执行删除指令后的数据,再执行data[data.duplicated()==True][:20]语句查看重复数据的前20条数据,最终显示的数据就是空数据了。

从图中可以看出,已经没有重复数据了。
然后,可以使用pandas.describe()函数进行一些统计信息的收集,自动统计的字段有count(非空值数)、unique(唯一值数)、top(频数最高者)、freq(最高频数)。把去重后的data数据describe之后的结果如下图所示。
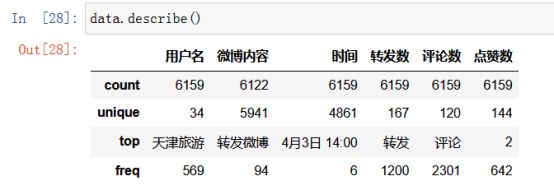
从上图中看,微博内容的count值为6122,用户名的统计为6159,两个数字不相等,可能微博内容会有空数据。Is_null()是判断空数据的方法,dropna()是删除空数据的方法。执行data.dropnal(inplace=True)语句即可删除空数据,删除以后可以通过data.describe()继续统计数据情况,执行结果如图所示。

从执行结果上看,用户名和微博内容的count值达到了一致,通过dropna方法已经把空数据删除掉了。
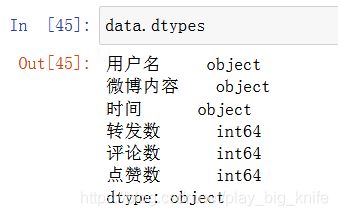
接下来可以检查一下数据类型,在微博读取维度中的“转发数”、“评论数”、“点赞数”按道理来说,都应该是数字,但从统计的结果上来看,有“转发”和“评论”的中文显示,实际上“转发”和“评论”表示的是转发量为0,即没有转发,字段中出现“评论”也是因为评论量为0,即没有评论。如果需要计算“转发量”、“评论量”及“点赞量”是需要检查对应维度的数据类型的。通过data.dtypes来检查每个维度的数据类型。执行语句后的运行结果如下图所示。

从图中输出的结果上看,“转发数”、“评论数”和“点赞数”均为object字符串类型,需要将“转发数”、“评论数”和“点赞数”转化成为整型。
通过统计会知道,“转发数”中有哪些数据不是整型数的异常,“评论数”中有些数据不是整型数的异常,“点赞数”还不知道有没有异常,这里也可以通过unique方法把“转发数”、“评论数”和“点赞数”三个维度中的数据列举出来,对于不是数值数据可以进行数据类型的转换。执行“转发数”的unique()方法的结果如下图所示。

从图中看,这里有文字“转发”,需要把“转发”变成数字0。
接下来,继续执行data["评论数"].unique()方法的结果如下图所示。

从图中看,这里有文字“评论”,需要把“评论”变成数据0。
接下来,继续执行data["点赞数"].unique()方法的结果如下图所示。
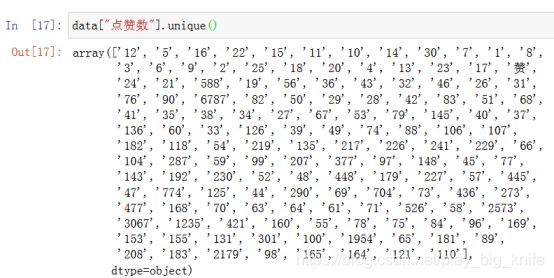
从图中看,这里有文字“赞”,需要把“赞”变成数据0。
这里把上述“转发数”、“评论数”和“点赞数”中的“转发”、“评论”和“赞”转换成0。可以使用下面的语句。
把“评论数”的“评论”值设置为0的语句代码如下。
data['评论数'][data['评论数']=='评论']=0
把“转发数”的“转发”值设置为0的语句代码如下。
data['转发数'][data['转发数']=='转发']=0
把“点赞数”的“赞”值设置为0的语句代码如下。
data['点赞数'][data['点赞数']=='赞']=0
把数据转换成功后,进行数据类型的转换,把object转换成int代码如下。
把“转发数”数据类型转成int代码如下。
data['转发数']=data['转发数'].astype(int)
把“评论数”数据类型转成int代码如下。
data['评论数']=data['评论数'].astype('int')
把“点赞数”数据类型转成int代码如下。
data['点赞数']=data['点赞数'].astype('int')
再继续利用data.dtypes查看数据类型,结果如下。
三、旅游局四月博文的转发数、评论数等内容的统计
关于旅游局四月博文的转发数、评论数等内容的统计内容,比如某个旅游局博客在四月份转发数一共有多少,可以通过透视表技术来进行统计,pandas的透视表使用pivot_table来实现。具体格式如下。
pd.pivot_table(df,index=["Manager","Rep"],values=["Price"],aggfunc=[np.mean,len])
其中df是需要透视表统计的表格DataFrame,index参数决定的是统计表格时的索引项,values是需要汇总统计的具体值,aggfunc对汇总统计的值采用的运算方式是什么。np.sum采用的是求和运算,np.mean采用的是求平均数的运算。
现在使用pivot_table透视表技术统计每个旅游局的合计转发数,评论数、点赞数,微博量。具体代码如下。
all_data=data.pivot_table(values=['转发数','评论数','点赞数','微博内容'],index='用户名',aggfunc={'转发数':numpy.sum,'评论数':numpy.sum,'点赞数':numpy.sum,'微博内容':numpy.size})
代码的最终执行结果如下图所示。

对于任何一下旅游局微博来说,“点赞数”、“评论数”、“转发数”均可以认为是旅游局的微博活动量,将“点赞数”、“评论数”、“转发数”三个数值相加就是旅游局的微博活量。如下图所示。

四、省份和省份微博对应的表格读取
接下来处理对省份的简称及省份对应的旅游微博的对应关系,也就是pandas在数据分析上常常使有的两表相连,这里需要通过特定的字段来进行连接。根据两个表格的结构对比,如下图所示。

上图所示的两表相连,两个表读取后会发现,省份名是连接两个表的唯一标志,但是两个表的省份名也不是完全相同,需要通过一些技术手段的处理,这里的技术手段就是截取两个字段中内容的前两位即可。处理方法是添加一个新的字段,存储的内容是省份名称中的前两位字符。
代码如下。
import numpy
sf=pandas.read_excel('test1.xlsx',sheet_name='sf')
sfweibo=pandas.read_excel('test1.xlsx',sheet_name='sfweibo')
sf['省份前两位']=numpy.nan
sfweibo['省份前两位']=numpy.nan
sf['省份前两位']=sf['省份名'].str.slice(0,2)
sfweibo['省份前两位']=sfweibo['省份名'].str.slice(0,2)
运行代码合可以输出sf表格的内容如下图所示。

再输出sfweibo表格的内容如下图所示。

从图中可以看到,两个表现在有了一个意义相同的字段,即“省份前两位”,pandas可以用“省份前两位”进行字段进行整合,merge方法是把两个表合成一个表的方法。格式如下。
pd.merge(df_1,df_2, on = '城市', how = 'right')
merge中的第一个参数df1是第一个需要合并的DataFrame表格,第二个参数df2是第二个需要合并的DataFrame表格,on是两个表需要合并的指定字段,how表示连接的方式,是外连接、左连接还是右连接。
现在使用pandas中merge的方法实现两个省份表的连接,具体代码如下。
sf_data=pandas.merge(sf,sfweibo,on='省份前两位')
代码执行后的输出两表连接后的结果如下图所示。

现在两个省份表连接了起来。
五、多表连接和其它维度的增加
省份表连接后,现在将省份表及微博活动量表进行合并,形成一个大的表格,把每个微博对应的省份及简称也加入到表格中。这里通过“微博用户名”字段进行连结。代码如下。
all_sf=pandas.merge(sf_data,all_data,left_on='微博用户名',right_on='用户名')
连接后,可以改变维度显示的顺序,可以使用[[]],在内中括号中写入维度的具体顺序。代码如下。
all_sf=all_sf[['微博用户名','转发数','评论数','点赞数','单条最大活动量','微博内容','简称']]
输出all_sf的结果如下图所示。

继续读出baseinfo微博的名称及微博的信息情况。将合并的allsf表和base_info两个表相连。合并的字段依据“微博用户名”和“昵称”进行合并。
base_info=pandas.read_excel('test1.xlsx',sheet_name='base_info')
all_base=pandas.merge(all_sf,base_info,left_on='微博用户名',right_on='昵称')
代码运行后的字段显示如图所示。

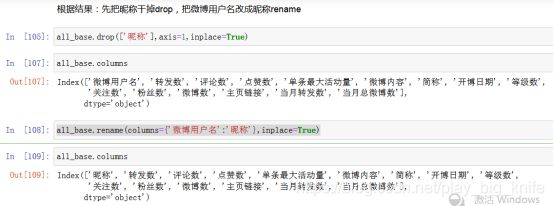
根据图中字段显示的内容,把“微博用户名”改成为“昵称”,把原来的“昵称”字段去掉。使用drop方法删除原有的“昵称”字段,用rename方法把原有的“微博用户名”改成“昵称”,代码及运行结果如下图所示。
从crawl_info表中的地址上看,如下图所示的特点。

博文链接中的地址就是home之前的地址与后面的“?profileftype=1&isall=1#0”内容的结合,而home之间的内容在baseinfo中有所体现,如下表所示。
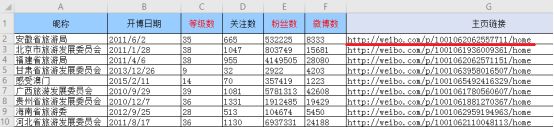
图中的主页链接内容到home就结束了,只需将主页链接内容加上字符串内容“?profileftype=1&isall=1#_0”就可以实现全部博文链接的内容。代码如下。
alllink='?profile_ftype=1&is_all=1#_0'
all_base.insert(12,'全部博文链接',all_base['主页链接']+alllink)
insert方法就是在表格中插入数据的方法,第一个参数12是列数的意思,第二个参数是列的名字,意思是在12列插入的列名为“全部博文链接”,具体内容决定了第三个参数,第三个参数就是把all_base表中的“主页链接”字段的内容加上alllink字符串的内容。
同理,当月的博文链接也出现如下图的特点。
也同样使用insert方法插入到具体的列中,代码如下。
monthlink='?is_ori=1&is_forward=1&is_text=1&is_pic=1&is_video=1&is_music=1&is_article=1&key_word=&start_time=2017-04-01&end_time=2017-04-30&is_search=1&is_searchadv=1#_0'
all_base.insert(14,'当月博文链接',all_base['主页链接']+monthlink)
代码执行后对应的截图如下所示。

利用这些数据, 还可以计算“当月的原创数”,代码如下。
all_base.insert(16,'当月原创数',all_base['当月总微博数']-all_base['当月转发数'])
这样这个微博博文数据表的维度已经扩展到了很多方面。输出具体维度的运行截图如下图所示。

六、根据微博博文的用户名进行分组排序
数据分析在很多程度上都需要进行分组和排序,只有分组和排序才能看清一些数据的具体排名,根据具体的排名才能更好的分析具体的问题。
pandas是用groupby进行分组的,排名的方法可以使用sort_values来进行的。
先用pandas.groupby对“用户名”进行分组,代码如下。
gb=data.groupby('用户名')
分组后可以获取分组后的大小和索引值,相当于计算统计旅游局发展了多少篇微博各获取过的分组索引名。代码如下。
gb1=gb.size()
gbindex=gb1.index
size()方法获取分组的大小。
index属性是获取分组后的索引
输出size大小和index索引的信息结果如下图所示.

从图中的结果可以看出,每个旅游局的微博的发表的数量.
接下来就可对数据进行排序,可以比较出哪一个旅游局发表的文章是最多的,哪一个旅游局发表的文章是最少的.哪一个旅游局博文被转发的量是最大的,哪一个旅游局博文被评论量的最大的.这些都是数据分析进行分析展示的根本。具体代码如下。
按用户转发量的大小排序。
sortallf=data.sort_values(by=['用户名','转发数'],ascending=[True,False])
ascending表示用户名的排序是升序,转发数的排序是降序.
按用户的评论量大小排序。
sortallc=data.sort_values(by=['用户名','评论数'],ascending=[True,False])
ascending表示用户名的排序是升序,转发数的排序是降序。
按用户的点赞数大小排序。
sortalll=data.sort_values(by=['用户名','点赞数'],ascending=[True,False])
ascending表示用户名的排序是升序,转发数的排序是降序。
其转发量大小排序的结果如下图所示。

七、微博数据分析的总结
微博数据分析重要的在于pandas模块中对数据分析方法的使用,去重去空清洗提纯的方法,异常值是如何判断出来的,如何把异常值做一些转化处理,数据分析常用的方法有哪些,如何进行group by分组,如何sort_values排序,这些内容都是数据分析必须掌握的技术能力,旨在通过微博数据的分析过程,对数据分析的常用方法有一个总体上的掌握。
代码的github地址:https://github.com/wawacode/travel_weibo_analyse