Excel数据分析一、数据分析步骤二、具体步骤
一、数据分析步骤
数据分析主要有以下五个步骤:
1、提出问题
2、理解数据
3、数据清洗
4、构建模型
5、数据可视化
二、具体步骤
(一)提出问题
为了更好了解上海二手房市场,
提出以下几个问题:
1)上海房价均价如何
2)哪些地区提供房源量较多
3)户型分布如何
(二)理解数据
本次练习选取的数据为上海二手房信息,来源于网上,共9个字段,总计28201条

(三)数据清洗
将原始数据保存好后另起一份,防止原始数据丢失。
1)删除重复值
利用【数据】-【删除重复项】进行查重,
![]()
添加序号列,使其具有唯一性
2)寻找缺失值
Ctrl+g,定位空值,编辑栏填入null,Ctrl+Enter将所有空值填为null
3)格式转换
为了便于之后的计算,需将总价,单价和面积列用【设置单元格格式】,设置为数值型。
4)异常值寻找
通过【筛选】,查找是否有#VALUE的值存在。无异常值
(四)构建模型
以清洗好的数据表为基础,主要进行数据透视表及数据透视图分析
根据最初问题提出时的需求,将小区、户型、面积留下,其他项暂时隐藏,用于其他方面分析。
因面积数据均为个值,为便于分析,进行分组,增加一列户型大小,并按面积分为小户型(<=60)、中户型(60-90)、大户型(90-120)、超大户型(>120)。
使用vlookup函数进行处理,新建简易4行表储存阈值,分别输入参数,面积列、阈值列、户型大小列和模糊查询,=VLOOKUP(D2,$N 2 : 2: 2:P$5,2,1),结果如下
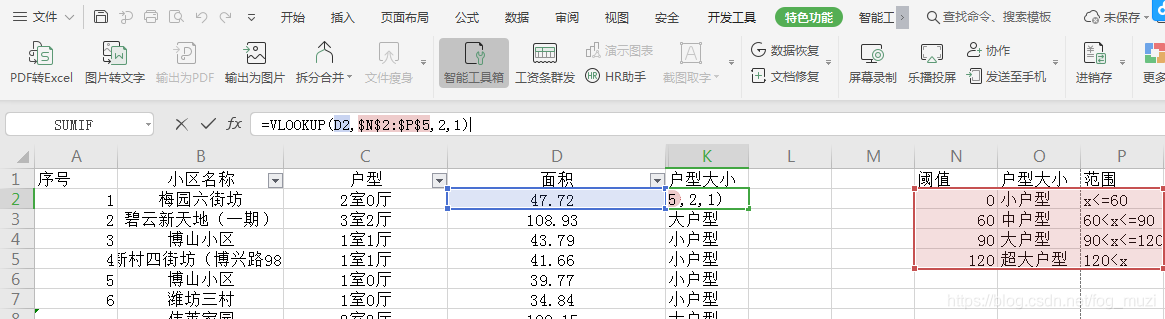
(五)数据可视化
1)均价、房源透视表

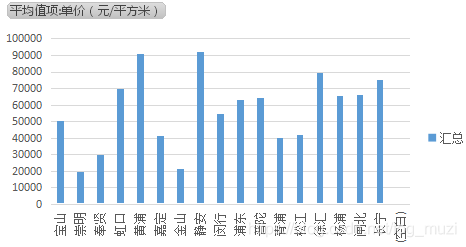
2)均价价格柱形图
3)户型分布透视表

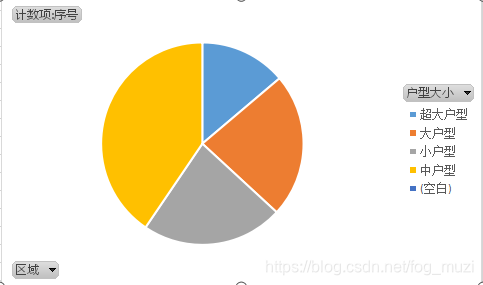
4)户型分布饼图
结论:
1.通过1)可以看出上海均价59486.88028元/平方米,通过2)可以看出,价格基本在均价以下,少数个别地区超过均价。
2.通过1)可以看出,除崇明、金山、静安,其余地区提供房源都较多。
3.通过4)中户型房源最多,超大户型最少