hadoop性能调优
一、禁止文件系统记录时间
Linux文件系统会记录文件创建、修改和访问操作的时间信息,这在读写操作频繁的应用中将带来不小的性能损失。在挂载文件系统时设置noatime和nodiratime可禁止文件系统记录文件和目录的访问时间,这对HDFS这种读取操作频繁的系统来说,可以节约一笔可观的开销。可以修改/etc/fstab文件中noatime和nodiratime来实现这个设置。
如对/mnt/disk1使用noatime属性,可以做如下修改:
$ vim /etc/fstab
/ ext4 defaults 1 1
/mnt/disk1 ext4 defaults,noatime 1 2
/mnt/disk2 ext4 defaults 1 2
/mnt/disk3 ext4 defaults 1 2
修改完成后,运行下述命令使之生效:
$ mount –o remount /mnt/disk1
二.预读缓冲
预读技术可以有效的减少磁盘寻道次数和应用的I/O等待时间,增加Linux文件系统预读缓冲区的大小(默认为256 sectors,128KB),可以明显提高顺序文件的读性能,建议调整到1024或2048 sectors。预读缓冲区的设置可以通过blockdev命令来完成。下面的命令将/dev/sda的预读缓冲区大小设置为2048 sectors。
$ blockdev –setra 2048 /dev/sda
注意:预读缓冲区并不是越大越好,多大的设置将导致载入太多无关数据,造成资源浪费,过小的设置则对性能提升没有太多帮助
三、
dfs.namenode.handler.count
NameNode中用于处理RPC调用的线程数,默认为10。对于较大的集群和配置较好的服务器,可适当增加这个数值来提升NameNode RPC服务的并发度。
dfs.datanode.handler.count
DataNode中用于处理RPC调用的线程数,默认为3。可适当增加这个数值来提升DataNode RPC服务的并发度。
***线程数的提高将增加DataNode的内存需求,因此,不宜过度调整这个数值。
四、
dfs.replication
数据块的备份数。默认值为3,对于一些热点数据,可适当增加备份数。
dfs.block.size
HDFS数据块的大小,默认为64M。数据库设置太小会增加NameNode的压力。数据块设置过大会增加定位数据的时间。
dfs.datanode.data.dir
HDFS数据存储目录。将数据存储分布在各个磁盘上可充分利用节点的I/O读写性能。
设置多个磁盘目录
hadoop.tmp.dir
Hadoop临时目录,默认为系统目录/tmp。在每个磁盘上都建立一个临时目录,可提高HDFS和MapReduce的I/O效率。
设置多个磁盘目录
dfs.data.dir
HDFS数据存储配置 提高I/O效率
以逗号隔开
dfs.name.dir
HDFS元数据存储配置, 要想提升hadoop整体IO性能,对于hadoop中用到的所有文件目录,都需要评估它磁盘IO的负载,对于IO负载可能会高的目录,最好都配置到多个磁盘上,以提示IO性能
Io.file.buffer.size
HDFS文件缓冲区大小,默认为4096(即4K)
131072(128K)
fs.trash.interval
HDFS清理回收站的时间周期,单位为分钟。默认为0,表示不使用回收站特性。为防止重要文件误删,可启用该特性1440(1day)
dfs.datanode.du.reserved
DataNode保留空间大小,单位为字节。默认情况下,DataNode会占用全部可用的磁盘空间,该配置项可以使DataNode保留部分磁盘空间工其他应用程序使用。视具体应用而定
机架感应
对于较大的集群,建议启用HDFS的机架感应功能。启用机架感应功能可以使HDFS优化数据块备份的分布,增强HDFS的性能和可靠性。
Hadoop 对机架的感知并非是自适应的,亦即,hadoop 集群分辨某台 slave 机器是属于哪个 rack 并非是智能感知的,而是需要 hadoop的管理者人为的告知 hadoop 哪台机器属于哪个 rack,这样在 hadoop的 namenode 启动初始化时,会将这些机器与 rack 的对应信息保存在内存中,用来作为对接下来所有的 HDFS 的写块操作分配 datanode列表时(比如 3 个 block 对应三台 datanode)的选择 datanode 策略,尽量将三个副本分布到不同的 rack。
1.默认情况下,hadoop 的机架感知是没有被启用的。所以,在通常情况下,hadoop 集群的 HDFS 在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop 将第一块数据 block1 写到了rack1 上,然后随机的选择下将 block2 写入到了 rack2 下,此时两个rack 之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3 重新又写回了 rack1,此时,两个 rack 之间又产生了一次数据流量。在 job 处理的数据量非常的大,或者往 hadoop 推送的数据量非常大的时候,这种情况会造成 rack 之间的网络流量成倍的上升,
在hadoop-site.xml配置脚本路径来实现
通过脚本告诉hadoop,该主机属于那个机架
hadoop合并小文件
Hadoop的应用中,Hadoop可以很好的处理大文件,不过当文件很多,并且文件很小时,Hadoop会把每一个小文件传递给map()函数,而Hadoop在调用map()函数时会创建一个映射器,这样就会创建了大量的映射器,应用的运行效率并不高。如果使用和存储小文件,通常就会创建很过的映射器。例如,如果有2000个文件,每一个文件的大小约为2-3MB,在处理这一批文件时,就需要2000个映射器,将每一个文件发送到一个映射器,效率会非常低的。所以,在Hadoop的环境环境中,要解决这个问题,就需要把多个文件合并为一个文件,然后在进行处理。如上面的例子中,可以把40-50个文件合并为衣蛾块大小的文件(接近块大小128MB),通过合并这些小文件,最后就只需要40-50个映射器,这样效率就可以有较大提升了。Hadoop主要设计批处理大量数据的大文件,不是很多小文件。解决小文件问题的主要目的就是通过合并小文件为更大的文件来加快Hadoop的程序的执行,解决小文件问题可以减少map()函数的执行次数,相应地提高hadoop作业的整体性能。
将小文件提交到MapReduce/Hadoop之前,需要先把这些小文件合并到大文件中,再把合并的大文件提交给MapReduce驱动器程序。
定义一个SmallFilesConsolidator类接受一组小文件,然后将这些小文件合并在一起,生成更大的Hadoop文件,这些文件的大小接近于HDFS块大小(dfs.block.size),最优的解决方案便是尽可能创建少的文件。
定义一个BucketThread类,这个类把小文件合并为一个大小于或接近于HDFS块大小的大文件。BucketThread是一个实现了Runable接口的独立线程,通过提供copyMerge()方法,把小文件合并为一个大文件。由于BucketThread是一个线程,所有的BucketThread对象可以并发的合并小文件。copyMerge()是BucketThread类的核心方法,它会把一个桶中的所有小文件合并为为一个临时的HDFS文件。例如,如果一个同种包含小文件{file1,file2,file3,file4,file5},那么合并得到的文件如下图所示:
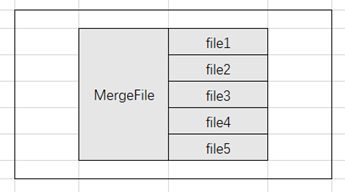 Hadoop合并小文件的两种解决方案
Hadoop合并小文件的两种解决方案