计算机毕业设计选题推荐-小说推荐系统-Python项目实战【爬虫+可视化+协同过滤算法】
✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目
文章目录
- 一、前言
- 二、开发环境
- 三、系统功能模块
- 四、系统界面展示
- 五、代码参考
- 六、论文参考
- 七、系统视频
- 结语
一、前言
随着互联网的普及和信息技术的快速发展,人们对于娱乐和阅读的需求越来越高。小说作为人们普遍喜欢的文学形式之一,其阅读量和影响力不容忽视。因此,建立一个高效、智能的小说推荐系统具有十分重要的意义。本课题基于当前小说推荐领域的现状和问题,旨在开发一个集成了爬虫技术、可视化技术和协同过滤算法的小说推荐系统,以满足用户对于小说信息获取和个性化推荐的需求,同时提高小说推荐的质量和效率。
当前的小说推荐系统大多数都采用了基于内容的推荐方法,这种方法主要基于用户过去的行为和偏好来推荐相似的小说。然而,这种推荐方法存在着一些问题。首先,它无法有效地发现和推荐一些新的、潜在的热门小说。其次,它对于用户偏好的理解不够深入,无法真正做到个性化的推荐。最后,由于数据稀疏性问题,推荐结果往往存在着偏差,无法做到真正的精准推荐。
本课题所研究的小说推荐系统,将通过爬虫技术从各大小说网站爬取数据,并利用可视化技术将数据呈现给用户。同时,系统将采用协同过滤算法,根据用户的历史行为和偏好,以及其他用户的评价和行为,进行深度学习和模型训练,最终为用户提供更加个性化、精准的小说推荐。
本课题的研究目的在于解决当前小说推荐领域存在的问题,提高推荐质量和效率,为用户提供更加个性化、精准的小说推荐服务。同时,通过可视化技术和协同过滤算法的应用,帮助用户更好地理解小说内容和用户群体的喜好,提高用户的阅读体验和满意度。
本课题的研究具有重要的理论和实践意义。首先,通过研究和实践,可以进一步完善和发展小说推荐领域的技术和方法,推动该领域的发展和创新。其次,课题的研究成果可以帮助各大小说网站提高服务质量,增加用户粘性和活跃度,提高网站的影响力和收益。此外,本课题的研究还可以为其他领域的个性化推荐提供参考和借鉴,推动相关领域的发展。
二、开发环境
- 开发语言:Python
- 数据库:MySQL
- 系统架构:B/S
- 后端:Django
- 前端:Vue
三、系统功能模块
- 角色:用户、管理员
- 功能:
用户:
小说信息、公告信息。
管理员:
用户管理、公告管理、小说信息爬取、可视化看板。
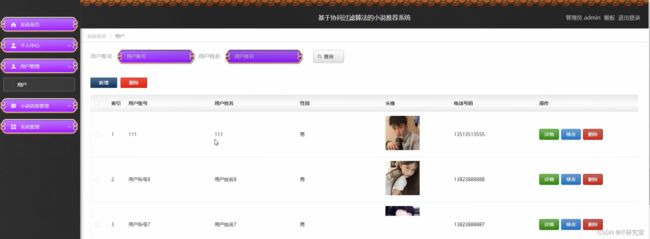
四、系统界面展示
- 小说推荐系统-界面展示:






五、代码参考
- 小说推荐系统-代码参考:
def toSplitShowWordFont(tem: str, splitKey: str) -> list[str]:
"""
从 tem 切割字符,切割关键字为 spaceWork
:param tem: 需要被切割的字符
:param splitKey: 切割关键字
:return: 切割完成的列表
"""
result: list[str] = []
if tem is None:
return None
currentStr = tem.rstrip()
if currentStr == "":
return None
temSpaceArray = currentStr.split(splitKey)
for spaceWork in temSpaceArray:
currentStr = spaceWork.rstrip()
if currentStr == "":
continue
result.append(currentStr)
if len(result) == 0:
return None
return result
def toShowWordFont(tem: str) -> list[str]:
result: list[str] = []
if tem is None:
return None
tem = tem.rstrip()
if tem == "":
return None
spaceArray = toSplitShowWordFont(tem, " ")
if spaceArray is not None:
for itemSpace in spaceArray:
tabArray = toSplitShowWordFont(itemSpace, "\t")
if tabArray is not None:
for itemTab in tabArray:
enterArray = toSplitShowWordFont(itemTab, "\n")
if enterArray is not None:
for itemEnter in enterArray:
result.append(itemEnter)
return result
def initIgnore(argvMaps: typing.Dict[str, typing.List[str]]) -> typing.Union[None, typing.List[str]]:
"""
初始化一个忽略参数
"""
igList0 = argvMaps.get("i")
igList1 = argvMaps.get("ig")
igList2 = argvMaps.get("ignore")
resultBuffList: typing.List[str] = []
if igList1 is not None:
for arg in igList1:
spriteName = requestNovelsLib.getBaseFileName(arg, checkFileSuffix=".py").upper()
resultBuffList.append(spriteName)
if igList2 is not None:
for arg in igList2:
spriteName = requestNovelsLib.getBaseFileName(arg, checkFileSuffix=".py").upper()
resultBuffList.append(spriteName)
if igList0 is not None:
for arg in igList0:
spriteName = requestNovelsLib.getBaseFileName(arg, checkFileSuffix=".py").upper()
resultBuffList.append(spriteName)
if len(resultBuffList) == 0:
return None
return resultBuffList
def getTargetAbsFilePath(rootPath: str, fileSuffix: str = None) -> list[str]:
"""
获取目录下的所有指定的后缀名,返回的是绝对路径
:param rootPath: 根目录
:param fileSuffix: 后缀
:return: 匹配的后缀文件名
"""
result: list[str] = []
if not os.path.exists(rootPath):
return None
if fileSuffix is not None and len(fileSuffix) == 0:
fileSuffix = None
if fileSuffix is not None and fileSuffix[0] != '.':
fileSuffix = f".{fileSuffix}"
buffSubResult: list[str] = None
buffPath: str = None
fileOrDirs = requestNovelsLib.getTargetInDirAbsFilePath(rootPath)
for fileOrDir in fileOrDirs:
if os.path.isfile(fileOrDir):
if fileSuffix is not None:
if fileOrDir.endswith(fileSuffix) == 1:
result.append(fileOrDir)
else:
result.append(fileOrDir)
return result
def getRunPyScripts(runScriptNameArgs: list[str], ignorePyNames: list[str]) -> list[str]:
"""
运行指定的模块
:param runScriptNameArgs: 是否运行模块, 非空表示运行,若需要指定运行,则需要输入匹配的模块名称
:param ignorePyNames: 忽略的模块名称
"""
runScriptFilesPath = []
ignore = False
buff = []
buffRunScriptFilesPath = requestNovelsLib.getTargetInDirAbsFilePath(requestNovelsLib.getCallAbsDirPath())
## 获取所有 .py 结尾
for fileItem in buffRunScriptFilesPath:
if fileItem.endswith(".py"):
buff.append(fileItem)
buffRunScriptFilesPath = buff
if runScriptNameArgs is not None:
## 获取需要运行的
if len(runScriptNameArgs) != 0:
for pythonName in runScriptNameArgs:
basePythonName = requestNovelsLib.getBaseFileName(pythonName).upper()
for fullPath in buff:
baseName = requestNovelsLib.getBaseFileName(fullPath).upper()
if baseName == basePythonName:
runScriptFilesPath.append(fullPath)
else:
runScriptFilesPath = buffRunScriptFilesPath
## 获取所有忽略的
if ignorePyNames is not None:
buff = []
buffRunScriptFilesPath = []
for image in ignorePyNames:
buff.append(requestNovelsLib.getBaseFileName(image).upper())
ignore = True
for fileAllName in runScriptFilesPath:
ignore = False
pyBaseName = requestNovelsLib.getBaseFileName(fileAllName).upper()
for compIgnore in buff:
if compIgnore == pyBaseName:
ignore = True
break
if not ignore:
buffRunScriptFilesPath.append(fileAllName)
runScriptFilesPath.clear()
for pyFile in buffRunScriptFilesPath:
name = requestNovelsLib.getBaseFileName(pyFile)
path = requestNovelsLib.getTargetAbsSavePath(pyFile)
improtMode = importlib.util.find_spec(name, path)
if improtMode is not None:
modeResult = improtMode.loader.load_module()
for getDir in dir(modeResult):
if getDir == "modeRequestGetUrl":
runScriptFilesPath.append(pyFile)
break
return runScriptFilesPath
buffRunScriptFilesPath = []
for pyFile in runScriptFilesPath:
name = requestNovelsLib.getBaseFileName(pyFile)
path = requestNovelsLib.getTargetAbsSavePath(pyFile)
improtMode = importlib.util.find_spec(name, path)
if improtMode is not None:
modeResult = improtMode.loader.load_module()
for getDir in dir(modeResult):
if getDir == "modeRequestGetUrl":
buffRunScriptFilesPath.append(pyFile)
break
return buffRunScriptFilesPath
class Pari:
def __init__(self, key, value):
self.key = key
self.value = value
def runTargetScriptsModeAtThread(filePath):
modeName = requestNovelsLib.getBaseFileName(filePath)
print(f"=================> 运行 {modeName} <=========")
model = requestNovelsLib.getPathPythonModels(filePath)
if model is None:
return None
try:
model.modeRequestGetUrl()
except:
traceback.print_exc()
print(f"=================> 执行完毕 {modeName} <=========")
return model
def getFileFindKeyWords(filePath: str, pythonScriptPath: str, cutterStr: str) -> list[str]:
"""
查找文件关键字
@param filePath: 文件路径
@param pythonScriptPath: 脚本路径
@param cutterStr: 分割字符串
@return: 文件中的关键字列表
"""
## 获取文件内容
try:
print(f"获取 {filePath} 路径关键字")
if os.path.isfile(filePath):
absFilePath = requestNovelsLib.getTargetInDirAbsFilePath(filePath)
if len(absFilePath) == 0:
return []
conent = requestNovelsLib.readFile(absFilePath[0])
return conent.upper().replace("\ufeff", "").split(cutterStr)
filesContenMap = requestNovelsLib.readDirFiles(filePath)
resultList: list[str] = []
for fileFullPathName, fileConten in filesContenMap.items():
replactConten = fileConten.upper().replace("\ufeff", "").split(cutterStr)
for key in replactConten:
newKey = key.strip()
if len(newKey) != 0:
resultList.append(newKey)
return resultList
except:
traceback.print_exc()
return []
def initFindKeys(kOption: list[str], fOption: list[str], fOptionFileCutterStr: str = None) -> typing.Dict[str, list[str]]:
"""
获取所有关键字,他不允许使用 py 后缀来指定关键字文件
@param kOption: k 选项关键字,由命令行提供
@param fOption: f 选项文件/文件夹,由命令行提供,该函数会读取所有匹配的文件或文件夹
@param fOptionFileCutterStr: 文件内容的切分符
@return: 路径映射到关键字的配对,可以参考路径来实现相对存放,-k 选项发挥为 “”
"""
## 处理空的非法分隔符
if fOptionFileCutterStr is None or len(fOptionFileCutterStr) == 0:
fOptionFileCutterStr = '\n'
else:
fOptionFileCutterStr = fOptionFileCutterStr.replace("\\t", '\t').replace("\\n", '\n')
result: typing.Dict[str, list[str]] = {}
currentPath = requestNovelsLib.getCallAbsDirPath()
global __PoolCount
with multiprocessing.Pool(__PoolCount) as processPool:
## 存储进程返回
processRunTimeObjMap: Dict[str, multiprocessing.pool.ApplyResult] = {}
## 遍历所有文件
for argFilePath in fOption:
if not argFilePath.endswith("py"):
processRunTimeObjMap[argFilePath] = processPool.apply_async(getFileFindKeyWords, (argFilePath, currentPath, fOptionFileCutterStr,))
## 终止进程分配
processPool.close()
## 配置 -k 选项
if kOption is not None and len(kOption):
kOptionFileName = requestNovelsLib.getPathName(__file__)
buffHumanNameList = []
for keyWord in kOption:
for humanNames in requestNovelsLib.getHumanNameList(keyWord):
buffHumanNameList.append(humanNames)
## 缩短字符串
buffHumanNameList = requestNovelsLib.strListAtStrip(buffHumanNameList, 0)
buffHumanNameList = requestNovelsLib.strListToChange(buffHumanNameList, True)
buffHumanNameList = requestNovelsLib.strListreduce(buffHumanNameList)
result[kOptionFileName] = requestNovelsLib.removeRepeateUnity(buffHumanNameList)
## 等待所有进程
processPool.join()
resulitItems = processRunTimeObjMap.items()
for filePath, processPoolResult in resulitItems:
buffHumanNameList = []
for keyWord in processPoolResult.get():
for humanNames in requestNovelsLib.getHumanNameList(keyWord):
buffHumanNameList.append(humanNames)
buffHumanNameList = requestNovelsLib.strListAtStrip(buffHumanNameList, 0)
buffHumanNameList = requestNovelsLib.strListToChange(buffHumanNameList, True)
buffHumanNameList = requestNovelsLib.strListreduce(buffHumanNameList)
arrayList = requestNovelsLib.removeRepeateUnity(buffHumanNameList)
if len(arrayList) != 0:
result[filePath] = arrayList
return result
def findNovelExisKey(findNovelInfo: requestNovelsLib = None, keys: list[str] = None) -> str:
"""
判断是否存在关键字
@param findNovelInfo: 判断对象
@param keys: 关键字列表
@return: 存在返回 关键字,否则返回 None
"""
upName = findNovelInfo.novelName.upper()
upInfo = findNovelInfo.info.upper()
upLastItem = findNovelInfo.lastItem.upper()
upAuthor = findNovelInfo.author.upper()
for key in keys:
if upName.find(key) != -1 or upInfo.find(key) != -1 or upLastItem.find(key) != -1 or upAuthor.find(key) != -1:
if len(findNovelInfo.attFlide) > 0:
findNovelInfo.attFlide = f"{findNovelInfo.attFlide}\n\t关键字: {key}"
else:
findNovelInfo.attFlide = f"关键字: {key}"
return key
return None
def fromDbGetNovelInfo(dbPath: str, findObjs: list[requestNovelsLib.NovelInfo], iniFilePath, keys, runScrictPath, targetTopDirPath, allKeyIngFilePath, inKeyIngFilePath, oldIngFilePath, userMakeName=False) -> dict[str, Pari]:
"""
查找匹配的小说内容
@param dbPath: db 路径
@param findObjs: 所有的小说信息
@param iniFilePath: 配置文件路径
@param keys: 查找的关键字
@param runScrictPath: 脚本运行的路径
@param targetTopDirPath: 顶部文件夹(带路径)
@param allKeyIngFilePath: 全匹配过滤路径
@param inKeyIngFilePath: 存在配过滤路径
@param oldIngFilePath: 已经查找到的小说文件路径
@param userMakeName: 是否使用标记
@return: 已经匹配好的对象, [路径,[关键字,小说对象]]
"""
if iniFilePath != "":
iniFileBaseName = requestNovelsLib.getPathName(iniFilePath)
dbBaseName = requestNovelsLib.getBaseFileName(requestNovelsLib.getPathName(dbPath))
targetDir = f"{runScrictPath}{os.sep}{targetTopDirPath}{os.sep}{iniFileBaseName}{os.sep}{dbBaseName}"
targetFilePath = ""
## 删除已经存在的文件
# if os.path.exists(targetDir):
# requestNovelsLib.removePath(targetDir)
## 返回列表
resultDict: dict[str, Pari] = {}
## 遍历所有对象
ingKey: str = ""
## 过滤不需要的小说
oldNovelName: list[str] = []
if userMakeName:
lock = requestNovelsLib.getMultiProcessDBLock()
try:
lock.acquire()
oldNovelName = requestNovelsLib.readFile(oldIngFilePath).split("\n")
oldNovelName = requestNovelsLib.strListRmoveSpace(oldNovelName, False, 0)
finally:
lock.release()
## 过滤配置文件
findObjs = requestNovelsLib.filterListNovel(findObjs, allKeyIngFilePath, inKeyIngFilePath, appendAllKeyList=oldNovelName)
writeListNovelName: list[str] = []
try:
noveName = ""
for findNovelInfo in findObjs:
exisKeyWork = findNovelExisKey(findNovelInfo, keys)
if exisKeyWork:
targetFilePath = f"{targetDir}{os.sep}{findNovelInfo.novelTypeName}.txt"
resultPari = resultDict.get(targetFilePath)
if resultPari is None:
resultPari = Pari(keys, [])
resultDict[targetFilePath] = resultPari
resultPari.value.append(findNovelInfo)
except:
msg = f"查找异常({dbPath})\n {traceback.format_exc()}"
sys.stderr.write(msg)
requestNovelsLib.writeLogFile(msg, httpUrl="find novel error")
for file, pair in resultDict.items():
pair.value = requestNovelsLib.novelInfoTypeSort(requestNovelsLib.removeNovelsRepeatAtUrl(pair.value))
return resultDict
return {}
def getFindKeyInfo(keyFindMap: dict[str, list[str]], dbFilePaths: list[str], currentTimeStr: str, userMakeName=False) -> dict[str, list[requestNovelsLib.NovelInfo]]:
"""
获取所有匹配的小说
@param keyFindMap: 路径与查找关键字的匹配
@param dbFilePaths: 请求的 db 文件路径,包含所有的 db
@param currentTimeStr: 当前时间的字符串格式
@param userMakeName: 是否使用记录标记
@return: 已经匹配好的小说列表
"""
dbFilePaths = requestNovelsLib.removeRepeateUnity(dbFilePaths)
if len(dbFilePaths) == 0:
return {}
poolResultObjList = []
scriptPath = f"{requestNovelsLib.getCallAbsDirPath()}"
result: dict[str, list[requestNovelsLib.NovelInfo]] = {}
global __PoolCount
with multiprocessing.Pool(__PoolCount) as processPool:
allKeyIngFilePath = f"{requestNovelsLib.getCallAbsDirPath()}/out/ini/jumpOut.ini"
inKeyIngFilePath = f"{requestNovelsLib.getCallAbsDirPath()}/out/ini/filter.ini"
novels: list[requestNovelsLib.NovelInfo] = []
## 获取数据库内容
for dbPath in dbFilePaths:
novels = requestNovelsLib.outputSqlite3(dbPath)
print("\n===")
dbFileCount = 0
for filePath, initKeys in keyFindMap.items():
dbFileCount += 1
iniFileBaseName = requestNovelsLib.getPathName(filePath)
dbBaseName = requestNovelsLib.getBaseFileName(requestNovelsLib.getPathName(dbPath))
oldIngFilePath = f"{requestNovelsLib.getCallAbsDirPath()}/out/ini/ingFindInDBFiles/{dbBaseName}.ini"
print(f"在《{dbBaseName}》中匹配 -《{iniFileBaseName}》- 文件保留的关键字 => 配置文件计数 : {dbFileCount}")
poolResultObjList.append(processPool.apply_async(fromDbGetNovelInfo, (dbPath, novels, filePath, initKeys, scriptPath, "out/find", allKeyIngFilePath, inKeyIngFilePath, oldIngFilePath, userMakeName)))
print("\n===")
## 关闭资源
processPool.close()
## 等待结束
processPool.join()
for processResult in poolResultObjList:
for writePathFileName, resultNovelsPair in processResult.get().items():
exisNovelsPair = result.get(writePathFileName)
if exisNovelsPair is None:
result[writePathFileName] = resultNovelsPair
else:
for saveNovel in resultNovelsPair.value:
exisNovelsPair.value.append(saveNovel)
return result
def writeFindResultNovels(wirteDict: dict[str, Pari] = None):
"""
把查找到的小说写入文件
@param wirteDict: 内容映射,从文件到小说内容的映射
"""
if wirteDict is None:
return
allLen = 0
lens = 0
writeFileCount = 0
keyCount = 0
removeDirList = []
for file, pair in wirteDict.items():
## 是否删除文件夹内的所有内容
fileDirPath = requestNovelsLib.getTargetAbsSavePath(file)
fileBaseName = os.path.basename(fileDirPath)
fileDirPath = fileDirPath[0: len(fileDirPath) - len(fileBaseName)]
lens = 0
for dirPath in removeDirList:
if dirPath == fileDirPath:
lens = 1
break
if lens == 0:
removeFileList = requestNovelsLib.removePath(fileDirPath)
print(f"\n删除目录 {fileDirPath} (文件夹与文件)数量 : {len(removeFileList)}")
removeDirList.append(fileDirPath)
lens = len(pair.value)
keyCount = len(pair.key)
allLen += lens
requestNovelsLib.writeFile(f"{requestNovelsLib.toStr(pair.value)}\nkey = {', '.join(pair.key)}\n关键字 : {keyCount}\n已经查找到小说数量 : {lens}\n", file, "w")
writeFileCount += 1
print(f"文件=> {file} 写入 {lens} 个小说,关键字为 {keyCount} 个, 第 {writeFileCount} 个文件")
print(f"共存在 => {allLen}, 写入文件数量 : {writeFileCount}")
if __name__ == '__main__':
print(f"正在从 {requestNovelsLib.currentCallThisFunctionFileName()} : {requestNovelsLib.currentCallThisFunctionFileLine()} 行 开始执行代码")
## 当前时间的字符串
currentTimeStr = datetime.datetime.now().strftime(f'%d_%H_%M_%S')
## 查找配置文件 -f
runFindCmdKeyFileList = []
## 查找关键字 -k
## 以 空格 为分隔符的关键字
spaceSplitKeyWork = ""
## 以 元素 为单位的关键字
runFindCmdKeyList = []
if spaceSplitKeyWork is not None and spaceSplitKeyWork != "":
showWordArray = toShowWordFont(spaceSplitKeyWork)
if showWordArray is not None:
for x in showWordArray:
runFindCmdKeyList.append(x)
## 去掉重复
runFindCmdKeyList = requestNovelsLib.removeRepeateUnity(runFindCmdKeyList)
## 填充脚本目录到查找列表
argvDict = {'f': runFindCmdKeyFileList, 'k': runFindCmdKeyList}
## 初始化查找信息
paramArgs = requestNovelsLib.initParamArgs(argvDict)
## 初始化忽略参数
ignorePyNames = initIgnore(argvDict)
## 存在 get 参数则开始运行爬虫
getArgs = argvDict.get("get")
## 删除重复
ignorePyNames = requestNovelsLib.removeRepeateUnity(ignorePyNames, 0, 0)
if getArgs is not None:
## 脚本代理运行
runScritpList = getRunPyScripts(getArgs, ignorePyNames)
if len(runScritpList) > 0:
with ThreadPoolExecutor(max_workers=__workerThreads) as pool:
threadList = []
removeLogFiles = requestNovelsLib.removeLogFiles()
for filePaths in runScritpList:
try:
threadList.append(pool.submit(lambda p: runTargetScriptsModeAtThread(*p), [filePaths]))
except:
traceback.print_exc()
pool.shutdown(wait=True)
for modeResult in threadList:
model = modeResult.result()
if model is None:
continue
urlNameFormat = '{0: >20}'.format(f'{model.getRootUrl()}')
timeFormat = '{0: <20}'.format(f'{model.getRunTime()}')
print(f"====> {urlNameFormat} 执行时间 {timeFormat}")
print(f"=================> 所有脚本运行完毕 <=========")
else:
print("没有找到( 需要运行/可用 )的脚本,请检查参数")
else:
print("\n====\n\t没有发现运行的脚本\n====\n")
## 是否激活删除选项
getArgs = argvDict.get("rp")
if getArgs is not None:
print("\n====\n\t移除过期小说信息\n====\n")
## 匹配时间
arrayLen = len(getArgs)
day = -1
month = 0
year = 0
if arrayLen > 0:
arrayIndex = 0
while arrayIndex < arrayLen:
try:
if getArgs[arrayIndex] == "day":
day = int(getArgs[arrayIndex + 1])
arrayIndex = arrayIndex + 1
elif getArgs[arrayIndex] == "month":
month = int(getArgs[arrayIndex + 1])
arrayIndex = arrayIndex + 1
elif getArgs[arrayIndex] == "year":
year = int(getArgs[arrayIndex + 1])
arrayIndex = arrayIndex + 1
finally:
arrayIndex = arrayIndex + 1
if day == -1:
arrayIndex = 0
while arrayIndex < arrayLen:
try:
day = int(getArgs[arrayIndex])
break
finally:
arrayIndex = arrayIndex + 1
if day == -1:
## 如果无法找到日期,则使用默认
day = 2
## 删除过期信息
requestNovelsLib.removeRepeateSqlite3DB(f"{requestNovelsLib.getCallAbsDirPath()}{os.sep}/out/db", day=day, month=month, year=year)
else:
print("\n====\n\t没有发现 -rp 选项\n====\n")
### 解压和查找选项
writeMakeName = True ## 是否写入文件
userMakeName = True ## 是否读取文件
if argvDict.get("wn") is None:
writeMakeName = False
if argvDict.get("mn") is None:
userMakeName = False
## 是否解压到txt 文件
getArgs = argvDict.get("db")
if getArgs is not None:
print("\n====\n\t小说信息写入 txt 文件\n====\n")
currentPath = requestNovelsLib.getCallAbsDirPath() + os.sep
## 解压文件
dbPath = f"{currentPath}out{os.sep}db{os.sep}"
targetPath = f"{currentPath}out{os.sep}txt{os.sep}"
requestNovelsLib.getSqlite3DBFileToFiles(dbPath, targetPath, None, writeMakeName, userMakeName)
else:
print("\n====\n\t没有发现 -db 选项\n====\n")
afOption = argvDict.get("af")
if afOption is not None and len(afOption) > 0:
fOption = argvDict.get("f")
if fOption is None:
fOption = []
argvDict["f"] = fOption
for path in afOption:
afOptionFiles = requestNovelsLib.getPathFilesNames(path)
for file in afOptionFiles:
fOption.append(file)
isFind = False
kOption = argvDict.get("k")
if kOption is not None and len(kOption) < 1:
fOption = argvDict.get("f")
if fOption is not None and len(fOption) > 0:
isFind = True
else:
isFind = True
if not isFind:
print("\n====\n\t没有发现需要查找的项目\n====\n")
else:
print("\n====\n\t开始查找。并且录入 txt 文件\n====\n")
## 获取所有查找的数据库
getRequestFiles = getTargetAbsFilePath("out", "db")
workPathRequestFiles = getTargetAbsFilePath(requestNovelsLib.getCallAbsDirPath(), "out/db")
for workFileDb in workPathRequestFiles:
getRequestFiles.append(workFileDb)
workPathRequestFiles.clear()
workPathRequestFiles = None
if getRequestFiles is None or len(getRequestFiles) == 0:
print("\n====\n\t不存在任意数据库,请更新数据库\n====\n")
else:
keyFindResult = None
## 文件映射到信息
print("获取相关关键小说")
## 文件映射到查找关键字
keyFindMap = initFindKeys(argvDict.get('k'), argvDict.get('f'), argvDict.get('a'))
fileContenMap = getFindKeyInfo(keyFindMap, getRequestFiles, currentTimeStr, userMakeName=userMakeName)
## 写入文件
print("\n====\n\t开始写入文件\n====\n")
writeFindResultNovels(fileContenMap)
exit(0)
六、论文参考
- 计算机毕业设计选题推荐-小说推荐系统-论文参考:

七、系统视频
小说推荐系统-项目视频:
【爬虫+可视化+协同过滤算法】基于Python的小说推荐系统
结语
计算机毕业设计选题推荐-小说推荐系统-Python项目实战【爬虫+可视化+协同过滤算法】
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目