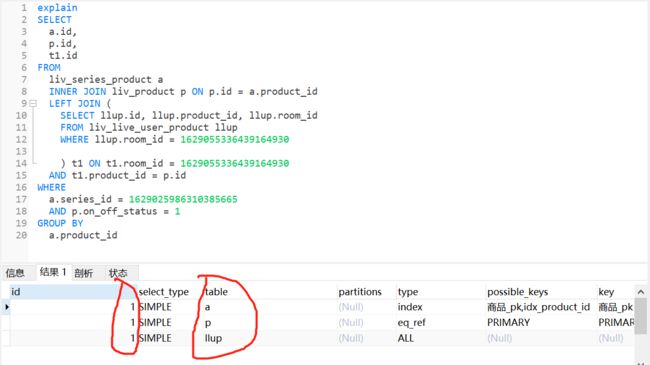
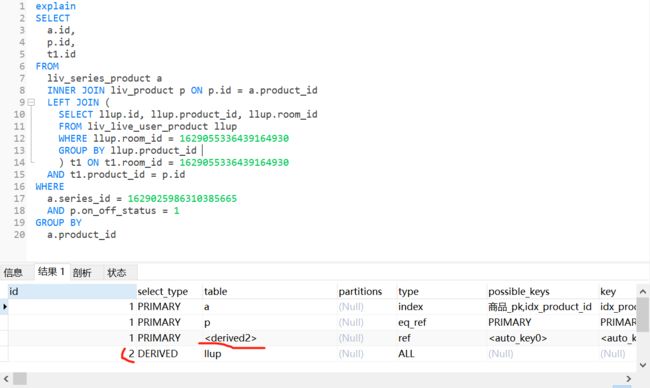
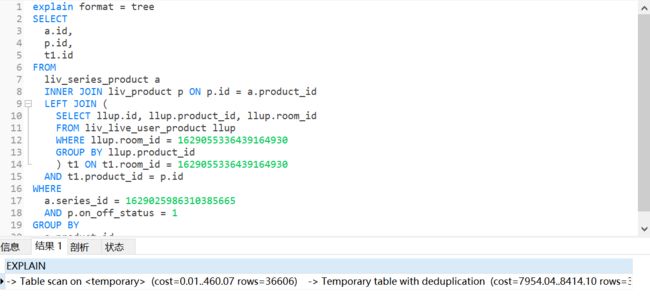
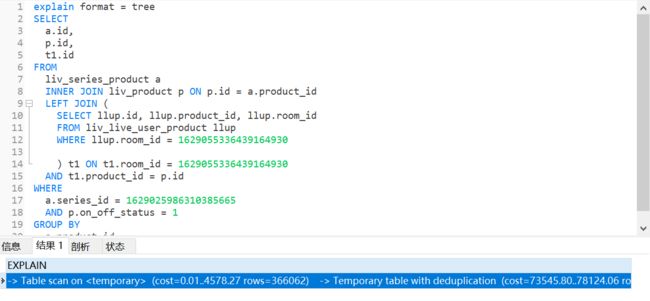
- mysql禁用远程登录
igotyback
mysql
去mysql库中的user表里,将host都改成localhost之后刷新权限FLUSHPRIVILEGES;
- Google earth studio 简介
陟彼高冈yu
旅游
GoogleEarthStudio是一个基于Web的动画工具,专为创作使用GoogleEarth数据的动画和视频而设计。它利用了GoogleEarth强大的三维地图和卫星影像数据库,使用户能够轻松地创建逼真的地球动画、航拍视频和动态地图可视化。网址为https://www.google.com/earth/studio/。GoogleEarthStudio是一个基于Web的动画工具,专为创作使用G
- 关于提高复杂业务逻辑代码可读性的思考
编程经验分享
开发经验java数据库开发语言
目录前言需求场景常规写法拆分方法领域对象总结前言实际工作中大部分时间都是在写业务逻辑,一般都是三层架构,表示层(Controller)接收客户端请求,并对入参做检验,业务逻辑层(Service)负责处理业务逻辑,一般开发都是在这一层中写具体的业务逻辑。数据访问层(Dao)是直接和数据库交互的,用于查数据给业务逻辑层,或者是将业务逻辑层处理后的数据写入数据库。简单的增删改查接口不用多说,基本上写好一
- SQL Server_查询某一数据库中的所有表的内容
qq_42772833
SQLServer数据库sqlserver
1.查看所有表的表名要列出CrabFarmDB数据库中的所有表(名),可以使用以下SQL语句:USECrabFarmDB;--切换到目标数据库GOSELECTTABLE_NAMEFROMINFORMATION_SCHEMA.TABLESWHERETABLE_TYPE='BASETABLE';对这段SQL脚本的解释:SELECTTABLE_NAME:这个语句的作用是从查询结果中选择TABLE_NAM
- 深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
- MYSQL面试系列-04
king01299
面试mysql面试
MYSQL面试系列-0417.关于redolog和binlog的刷盘机制、redolog、undolog作用、GTID是做什么的?innodb_flush_log_at_trx_commit及sync_binlog参数意义双117.1innodb_flush_log_at_trx_commit该变量定义了InnoDB在每次事务提交时,如何处理未刷入(flush)的重做日志信息(redolog)。它
- MongoDB Oplog 窗口
喝醉酒的小白
MongoDB运维
在MongoDB中,oplog(操作日志)是一个特殊的日志系统,用于记录对数据库的所有写操作。oplog允许副本集成员(通常是从节点)应用主节点上已经执行的操作,从而保持数据的一致性。它是MongoDB副本集实现数据复制的基础。MongoDBOplog窗口oplog窗口是指在MongoDB副本集中,从节点可以用来同步数据的时间范围。这个窗口通常由以下因素决定:Oplog大小:oplog的大小是有限
- python os 环境变量
CV矿工
python开发语言numpy
环境变量:环境变量是程序和操作系统之间的通信方式。有些字符不宜明文写进代码里,比如数据库密码,个人账户密码,如果写进自己本机的环境变量里,程序用的时候通过os.environ.get()取出来就行了。os.environ是一个环境变量的字典。环境变量的相关操作importos"""设置/修改环境变量:os.environ[‘环境变量名称’]=‘环境变量值’#其中key和value均为string类
- 【PG】常见数据库、表属性设置
江无羡
数据库
PG的常见属性配置方法数据库复制、备份相关表的复制标识单表操作批量表操作链接数据库复制、备份相关表的复制标识单表操作通过ALTER语句单独更改一张表的复制标识。ALTERTABLE[tablename]REPLICAIDENTITYFULL;批量表操作通过代码块的方式,对某个schema中的所有表一起更新其复制标识。SELECTtablename,CASErelreplidentWHEN'd'TH
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- SpringBlade dict-biz/list 接口 SQL 注入漏洞
文章永久免费只为良心
oracle数据库
SpringBladedict-biz/list接口SQL注入漏洞POC:构造请求包查看返回包你的网址/api/blade-system/dict-biz/list?updatexml(1,concat(0x7e,md5(1),0x7e),1)=1漏洞概述在SpringBlade框架中,如果dict-biz/list接口的后台处理逻辑没有正确地对用户输入进行过滤或参数化查询(PreparedSta
- insert into select 主键自增_mybatis拦截器实现主键自动生成
weixin_39521651
insertintoselect主键自增mybatisdelete返回值mybatisinsert返回主键mybatisinsert返回对象mybatisplusinsert返回主键mybatisplus插入生成id
前言前阵子和朋友聊天,他说他们项目有个需求,要实现主键自动生成,不想每次新增的时候,都手动设置主键。于是我就问他,那你们数据库表设置主键自动递增不就得了。他的回答是他们项目目前的id都是采用雪花算法来生成,因此为了项目稳定性,不会切换id的生成方式。朋友问我有没有什么实现思路,他们公司的orm框架是mybatis,我就建议他说,不然让你老大把mybatis切换成mybatis-plus。mybat
- 关于Mysql 中 Row size too large (> 8126) 错误的解决和理解
秋刀prince
mysqlmysql数据库
提示:啰嗦一嘴,数据库的任何操作和验证前,一定要记得先备份!!!不会有错;文章目录问题发现一、问题导致的可能原因1、页大小2、行格式2.1compact格式2.2Redundant格式2.3Dynamic格式2.4Compressed格式3、BLOB和TEXT列二、解决办法1、修改页大小(不推荐)2、修改行格式3、修改数据类型为BLOB和TEXT列4、其他优化方式(可以参考使用)4.1合理设置数据
- Java爬虫框架(一)--架构设计
狼图腾-狼之传说
java框架java任务html解析器存储电子商务
一、架构图那里搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容数据库:存储商品信息索引:商品的全文搜索索引Task队列:需要爬取的网页列表Visited表:已经爬取过的网页列表爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。二、爬虫1.流程1)Scheduler启动爬虫器,TaskMast
- MongoDB知识概括
GeorgeLin98
持久层mongodb
MongoDB知识概括MongoDB相关概念单机部署基本常用命令索引-IndexSpirngDataMongoDB集成副本集分片集群安全认证MongoDB相关概念业务应用场景:传统的关系型数据库(如MySQL),在数据操作的“三高”需求以及应对Web2.0的网站需求面前,显得力不从心。解释:“三高”需求:①Highperformance-对数据库高并发读写的需求。②HugeStorage-对海量数
- Mongodb Error: queryTxt ETIMEOUT xxxx.wwwdz.mongodb.net
佛一脚
errorreactmongodb数据库
背景每天都能遇到奇怪的问题,做个记录,以便有缘人能得到帮助!换了一台电脑开发nextjs程序。需要连接mongodb数据,对数据进行增删改查。上一台电脑好好的程序,新电脑死活连不上mongodb数据库。同一套代码,没任何修改,搞得我怀疑人生了,打开浏览器进入mongodb官网毫无问题,也能进入线上系统查看数据,网络应该是没问题。于是我尝试了一下手机热点,这次代码能正常跑起来,连接数据库了!!!是不
- JAVA·一个简单的登录窗口
MortalTom
java开发语言学习
文章目录概要整体架构流程技术名词解释技术细节资源概要JavaSwing是Java基础类库的一部分,主要用于开发图形用户界面(GUI)程序整体架构流程新建项目,导入sql.jar包(链接放在了文末),编译项目并运行技术名词解释一、特点丰富的组件提供了多种可视化组件,如按钮(JButton)、文本框(JTextField)、标签(JLabel)、下拉列表(JComboBox)等,可以满足不同的界面设计
- 入门MySQL——查询语法练习
K_un
前言:前面几篇文章为大家介绍了DML以及DDL语句的使用方法,本篇文章将主要讲述常用的查询语法。其实MySQL官网给出了多个示例数据库供大家实用查询,下面我们以最常用的员工示例数据库为准,详细介绍各自常用的查询语法。1.员工示例数据库导入官方文档员工示例数据库介绍及下载链接:https://dev.mysql.com/doc/employee/en/employees-installation.h
- 博客网站制作教程
2401_85194651
javamaven
首先就是技术框架:后端:Java+SpringBoot数据库:MySQL前端:Vue.js数据库连接:JPA(JavaPersistenceAPI)1.项目结构blog-app/├──backend/│├──src/main/java/com/example/blogapp/││├──BlogApplication.java││├──config/│││└──DatabaseConfig.java
- ubuntu安装wordpress
lissettecarlr
1安装nginx网上安装方式很多,这就就直接用apt-get了apt-getinstallnginx不用启动啥,然后直接在浏览器里面输入IP:80就能看到nginx的主页了。如果修改了一些配置可以使用下列命令重启一下systemctlrestartnginx.service2安装mysql输入安装前也可以更新一下软件源,在安装过程中将会让你输入数据库的密码。sudoapt-getinstallmy
- 深入浅出 -- 系统架构之负载均衡Nginx的性能优化
xiaoli8748_软件开发
系统架构系统架构负载均衡nginx
一、Nginx性能优化到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等,对于性能调优比较感兴趣的可以参考之前《JVM性能调优》中的调优思想。优化一:打开长连接配置通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启H
- 【RabbitMQ 项目】服务端:数据管理模块之绑定管理
月夜星辉雪
rabbitmq分布式
文章目录一.编写思路二.代码实践一.编写思路定义绑定信息类交换机名称队列名称绑定关键字:交换机的路由交换算法中会用到没有是否持久化的标志,因为绑定是否持久化取决于交换机和队列是否持久化,只有它们都持久化时绑定才需要持久化。绑定就好像一根绳子,两端连接着交换机和队列,当一方不存在,它就没有存在的必要了定义绑定持久化类构造函数:如果数据库文件不存在则创建,打开数据库,创建binding_table插入
- 计算机毕业设计PHP仓储综合管理系统(源码+程序+VUE+lw+部署)
java毕设程序源码王哥
php课程设计vue.js
该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程。欢迎交流项目运行环境配置:phpStudy+Vscode+Mysql5.7+HBuilderX+Navicat11+Vue+Express。项目技术:原生PHP++Vue等等组成,B/S模式+Vscode管理+前后端分离等等。环境需要1.运行环境:最好是小皮phpstudy最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发
- MyBatis 详解
阿贾克斯的黎明
javamybatis
目录目录一、MyBatis是什么二、为什么使用MyBatis(一)灵活性高(二)性能优化(三)易于维护三、怎么用MyBatis(一)添加依赖(二)配置MyBatis(三)创建实体类和接口(四)使用MyBatis一、MyBatis是什么MyBatis是一个优秀的持久层框架,它支持自定义SQL、存储过程以及高级映射。MyBatis免除了几乎所有的JDBC代码以及设置参数和获取结果集的工作。它可以通过简
- 3.增删改查--连接查询
问女何所忆
关系型数据库的一个特点就是,多张表之间存在关系,以致于我们可以连接多张表进行查询操作,所以连接查询会是关系型数据库中最常见的操作。连接查询主要分为三种,交叉连接、内连接和外连接,我们一个个说。1、交叉连接交叉连接其实连接查询的第一个阶段,它简单表现为两张表的笛卡尔积形式,具体例子:如果你没学过数学中的笛卡尔积概念,你可以这样简单的理解这里的交叉连接:两张表的交叉连接就是一个连接合并的过程,T1表中
- You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version
努力的菜鸟~
sql数据库
YouhaveanerrorinyourSQLsyntax;checkthemanualthatcorrespondstoyourMySQLserverversionfortherightsyntaxtousenear‘IDENTIFIEDBY‘123456’WITHGRANTOPTION’atline1在mysql5.7之前GRANTALLPRIVILEGESON*.*TO'root'@'%'I
- docker from指令的含义_多个FROM-含义
weixin_39722188
dockerfrom指令的含义
小编典典什么是基本图片?一组文件,加上EXPOSE端口ENTRYPOINT和CMD。您可以添加文件并基于该基础图像构建新图像,Dockerfile并以FROM指令开头:后面提到的图像FROM是新图像的“基础图像”。这是否意味着如果我neo4j/neo4j在FROM指令中声明,则在运行映像时,neo数据库将自动运行并且可在端口7474的容器中使用?仅当您不覆盖CMD和时ENTRYPOINT。但是图像
- Redis:缓存击穿
我的程序快快跑啊
缓存redisjava
缓存击穿(热点key):部分key(被高并发访问且缓存重建业务复杂的)失效,无数请求会直接到数据库,造成巨大压力1.互斥锁:可以保证强一致性线程一:未命中之后,获取互斥锁,再查询数据库重建缓存,写入缓存,释放锁线程二:查询未命中,未获得锁(已由线程一获得),等待一会,缓存命中互斥锁实现方式:redis中setnxkeyvalue:改变对应key的value,仅当value不存在时执行,以此来实现互
- mysql学习教程,从入门到精通,TOP 和MySQL LIMIT 子句(15)
知识分享小能手
大数据数据库MySQLmysql学习oracle数据库开发语言adb大数据
1、TOP和MySQLLIMIT子句内容在SQL中,不同的数据库系统对于限制查询结果的数量有不同的实现方式。TOP关键字主要用于SQLServer和Access数据库中,而LIMIT子句则主要用于MySQL、PostgreSQL(通过LIMIT/OFFSET语法)、SQLite等数据库中。下面将分别详细介绍这两个功能的语法、语句以及案例。1.1、TOP子句(SQLServer和Access)1.1
- ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your
†徐先森®
Oracle数据库Web相关错误集
createtablestudents(idintunsignedprimarykeyauto_increment,namevarchar(50)notnull,ageintunsigned,highdecimal(3,2),genderenum('男','女','中性','保密','妖')default'保密',cls_idintunsigned);在对数据库插入如上带有中文带有默认值的字段的时
- jquery实现的jsonp掉java后台
知了ing
javajsonpjquery
什么是JSONP?
先说说JSONP是怎么产生的:
其实网上关于JSONP的讲解有很多,但却千篇一律,而且云里雾里,对于很多刚接触的人来讲理解起来有些困难,小可不才,试着用自己的方式来阐释一下这个问题,看看是否有帮助。
1、一个众所周知的问题,Ajax直接请求普通文件存在跨域无权限访问的问题,甭管你是静态页面、动态网页、web服务、WCF,只要是跨域请求,一律不准;
2、
- Struts2学习笔记
caoyong
struts2
SSH : Spring + Struts2 + Hibernate
三层架构(表示层,业务逻辑层,数据访问层) MVC模式 (Model View Controller)
分层原则:单向依赖,接口耦合
1、Struts2 = Struts + Webwork
2、搭建struts2开发环境
a>、到www.apac
- SpringMVC学习之后台往前台传值方法
满城风雨近重阳
springMVC
springMVC控制器往前台传值的方法有以下几种:
1.ModelAndView
通过往ModelAndView中存放viewName:目标地址和attribute参数来实现传参:
ModelAndView mv=new ModelAndView();
mv.setViewName="success
- WebService存在的必要性?
一炮送你回车库
webservice
做Java的经常在选择Webservice框架上徘徊很久,Axis Xfire Axis2 CXF ,他们只有一个功能,发布HTTP服务然后用XML做数据传输。
是的,他们就做了两个功能,发布一个http服务让客户端或者浏览器连接,接收xml参数并发送xml结果。
当在不同的平台间传输数据时,就需要一个都能解析的数据格式。
但是为什么要使用xml呢?不能使json或者其他通用数据
- js年份下拉框
3213213333332132
java web ee
<div id="divValue">test...</div>测试
//年份
<select id="year"></select>
<script type="text/javascript">
window.onload =
- 简单链式调用的实现技术
归来朝歌
方法调用链式反应编程思想
在编程中,我们可以经常遇到这样一种场景:一个实例不断调用它自身的方法,像一条链条一样进行调用
这样的调用你可能在Ajax中,在页面中添加标签:
$("<p>").append($("<span>").text(list[i].name)).appendTo("#result");
也可能在HQ
- JAVA调用.net 发布的webservice 接口
darkranger
webservice
/**
* @Title: callInvoke
* @Description: TODO(调用接口公共方法)
* @param @param url 地址
* @param @param method 方法
* @param @param pama 参数
* @param @return
* @param @throws BusinessException
- Javascript模糊查找 | 第一章 循环不能不重视。
aijuans
Way
最近受我的朋友委托用js+HTML做一个像手册一样的程序,里面要有可展开的大纲,模糊查找等功能。我这个人说实在的懒,本来是不愿意的,但想起了父亲以前教我要给朋友搞好关系,再加上这也可以巩固自己的js技术,于是就开始开发这个程序,没想到却出了点小问题,我做的查找只能绝对查找。具体的js代码如下:
function search(){
var arr=new Array("my
- 狼和羊,该怎么抉择
atongyeye
工作
狼和羊,该怎么抉择
在做一个链家的小项目,只有我和另外一个同事两个人负责,各负责一部分接口,我的接口写完,并全部测联调试通过。所以工作就剩下一下细枝末节的,工作就轻松很多。每天会帮另一个同事测试一些功能点,协助他完成一些业务型不强的工作。
今天早上到公司没多久,领导就在QQ上给我发信息,让我多协助同事测试,让我积极主动些,有点责任心等等,我听了这话,心里面立马凉半截,首先一个领导轻易说
- 读取android系统的联系人拨号
百合不是茶
androidsqlite数据库内容提供者系统服务的使用
联系人的姓名和号码是保存在不同的表中,不要一下子把号码查询来,我开始就是把姓名和电话同时查询出来的,导致系统非常的慢
关键代码:
1, 使用javabean操作存储读取到的数据
package com.example.bean;
/**
*
* @author Admini
- ORACLE自定义异常
bijian1013
数据库自定义异常
实例:
CREATE OR REPLACE PROCEDURE test_Exception
(
ParameterA IN varchar2,
ParameterB IN varchar2,
ErrorCode OUT varchar2 --返回值,错误编码
)
AS
/*以下是一些变量的定义*/
V1 NUMBER;
V2 nvarc
- 查看端号使用情况
征客丶
windows
一、查看端口
在windows命令行窗口下执行:
>netstat -aon|findstr "8080"
显示结果:
TCP 127.0.0.1:80 0.0.0.0:0 &
- 【Spark二十】运行Spark Streaming的NetworkWordCount实例
bit1129
wordcount
Spark Streaming简介
NetworkWordCount代码
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
- Struts2 与 SpringMVC的比较
BlueSkator
struts2spring mvc
1. 机制:spring mvc的入口是servlet,而struts2是filter,这样就导致了二者的机制不同。 2. 性能:spring会稍微比struts快。spring mvc是基于方法的设计,而sturts是基于类,每次发一次请求都会实例一个action,每个action都会被注入属性,而spring基于方法,粒度更细,但要小心把握像在servlet控制数据一样。spring
- Hibernate在更新时,是可以不用session的update方法的(转帖)
BreakingBad
Hibernateupdate
地址:http://blog.csdn.net/plpblue/article/details/9304459
public void synDevNameWithItil()
{Session session = null;Transaction tr = null;try{session = HibernateUtil.getSession();tr = session.beginTran
- 读《研磨设计模式》-代码笔记-观察者模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
import java.util.Observable;
import java.util.Observer;
/**
* “观
- 重置MySQL密码
chenhbc
mysql重置密码忘记密码
如果你也像我这么健忘,把MySQL的密码搞忘记了,经过下面几个步骤就可以重置了(以Windows为例,Linux/Unix类似):
1、关闭MySQL服务
2、打开CMD,进入MySQL安装目录的bin目录下,以跳过权限检查的方式启动MySQL
mysqld --skip-grant-tables
3、新开一个CMD窗口,进入MySQL
mysql -uroot
- 再谈系统论,控制论和信息论
comsci
设计模式生物能源企业应用领域模型
再谈系统论,控制论和信息论
偶然看
- oracle moving window size与 AWR retention period关系
daizj
oracle
转自: http://tomszrp.itpub.net/post/11835/494147
晚上在做11gR1的一个awrrpt报告时,顺便想调整一下AWR snapshot的保留时间,结果遇到了ORA-13541这样的错误.下面是这个问题的发生和解决过程.
SQL> select * from v$version;
BANNER
-------------------
- Python版B树
dieslrae
python
话说以前的树都用java写的,最近发现python有点生疏了,于是用python写了个B树实现,B树在索引领域用得还是蛮多了,如果没记错mysql的默认索引好像就是B树...
首先是数据实体对象,很简单,只存放key,value
class Entity(object):
'''数据实体'''
def __init__(self,key,value)
- C语言冒泡排序
dcj3sjt126com
算法
代码示例:
# include <stdio.h>
//冒泡排序
void sort(int * a, int len)
{
int i, j, t;
for (i=0; i<len-1; i++)
{
for (j=0; j<len-1-i; j++)
{
if (a[j] > a[j+1]) // >表示升序
- 自定义导航栏样式
dcj3sjt126com
自定义
-(void)setupAppAppearance
{
[[UILabel appearance] setFont:[UIFont fontWithName:@"FZLTHK—GBK1-0" size:20]];
[UIButton appearance].titleLabel.font =[UIFont fontWithName:@"FZLTH
- 11.性能优化-优化-JVM参数总结
frank1234
jvm参数性能优化
1.堆
-Xms --初始堆大小
-Xmx --最大堆大小
-Xmn --新生代大小
-Xss --线程栈大小
-XX:PermSize --永久代初始大小
-XX:MaxPermSize --永久代最大值
-XX:SurvivorRatio --新生代和suvivor比例,默认为8
-XX:TargetSurvivorRatio --survivor可使用
- nginx日志分割 for linux
HarborChung
nginxlinux脚本
nginx日志分割 for linux 默认情况下,nginx是不分割访问日志的,久而久之,网站的日志文件将会越来越大,占用空间不说,如果有问题要查看网站的日志的话,庞大的文件也将很难打开,于是便有了下面的脚本 使用方法,先将以下脚本保存为 cutlog.sh,放在/root 目录下,然后给予此脚本执行的权限
复制代码代码如下:
chmo
- Spring4新特性——泛型限定式依赖注入
jinnianshilongnian
springspring4泛型式依赖注入
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- centOS安装GCC和G++
liuxihope
centosgcc
Centos支持yum安装,安装软件一般格式为yum install .......,注意安装时要先成为root用户。
按照这个思路,我想安装过程如下:
安装gcc:yum install gcc
安装g++: yum install g++
实际操作过程发现,只能有gcc安装成功,而g++安装失败,提示g++ command not found。上网查了一下,正确安装应该
- 第13章 Ajax进阶(上)
onestopweb
Ajax
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- How to determine BusinessObjects service pack and fix pack
blueoxygen
BO
http://bukhantsov.org/2011/08/how-to-determine-businessobjects-service-pack-and-fix-pack/
The table below is helpful. Reference
BOE XI 3.x
12.0.0.
y BOE XI 3.0 12.0.
x.
y BO
- Oracle里的自增字段设置
tomcat_oracle
oracle
大家都知道吧,这很坑,尤其是用惯了mysql里的自增字段设置,结果oracle里面没有的。oh,no 我用的是12c版本的,它有一个新特性,可以这样设置自增序列,在创建表是,把id设置为自增序列
create table t
(
id number generated by default as identity (start with 1 increment b
- Spring Security(01)——初体验
yang_winnie
springSecurity
Spring Security(01)——初体验
博客分类: spring Security
Spring Security入门安全认证
首先我们为Spring Security专门建立一个Spring的配置文件,该文件就专门用来作为Spring Security的配置