云谦:前端框架的趋势与实践
大家好,我是若川。我持续组织了近一年的源码共读活动,感兴趣的可以 点此扫码加我微信 ruochuan12 参与,每周大家一起学习200行左右的源码,共同进步。同时极力推荐订阅我写的《学习源码整体架构系列》 包含20余篇源码文章。历史面试系列。另外:目前建有江西|湖南|湖北籍前端群,可加我微信进群。
这是 2022.11.05 云谦在《渝 FE 2022》上的分享。
介绍

大家好,我是来自蚂蚁集团的云谦。很高兴能有这个机会来和大家来分享,我今天的分享主题是「前端框架的趋势与实践」,是我这段时间对前端框架领域的理解,分趋势和实践两个维度。趋势比较主观,可能和你的理解不同;实践主要基于 Umi 框架在蚂蚁的应用得出。

关于我。BALABALA。。。

关于前端框架的趋势,其实有很多可以讲的点。比如框架设计、构建、bundless、Native 语言、Islands 架构、数据流、请求方案、工程化、Headless 组件、文档方案、Monorepo、Node Runtime、React 18 等,在这段时间都发生了很多变化。但 30 分钟时间有限,我会挑 5 个点来分享我的看法,每个点 5-6 分钟。
框架设计

元框架(Meta Framework)领域近一年出现了不少新成员,比如 Remix、Svelte Kit、Solid Start、Qwik City、Fresh、Astro 等。同时不少老牌框架也做了迭代,比如 Next.js 13、Nuxt 3、Umi 4、ICE 3、Storybook 7 等。

我观察到的趋势是,
1、功能趋同
2、新框架大部分基于 Vite
3、基于路由的声明式数据获取方案
趋同指的是功能。不同的元框架 80% 的功能是类似的,剩下 20% 是有差异有亮点的。那 80% 趋同的功能,比如大家通常都有约定式路由、api 路由、ssr+ssg+isr、通过编译时的临时文件扩展框架能力、插件和扩展机制。剩下 20% 就是不同框架的卖点了,举一些例子,比如 Remix 的卖点是 loader + action 的数据加载机制、Fresh 的卖点是 0JS + deno + 真 bundless。
新出的 80% 框架都基于 Vite,上面列出的应该就只有 Fresh 是直接用 esbuild 打包。老框架升级除了 Next.js,大家都有提供 Vite 模式的支持,有些默认,有些提供配置项切换到 Vite 构建模式。选择 Vite 而非 webpack 看起来是这个阶段更合适的选择,为什么大家会选择 Vite 呢?我觉得,1)除了 Vite 的速度之外,2)易集成和 3)生态也是大家考虑的因素。(注:但是,写完这段后发现 Vercel 发布了 Turbopack,可能过个半年又要有变化了)
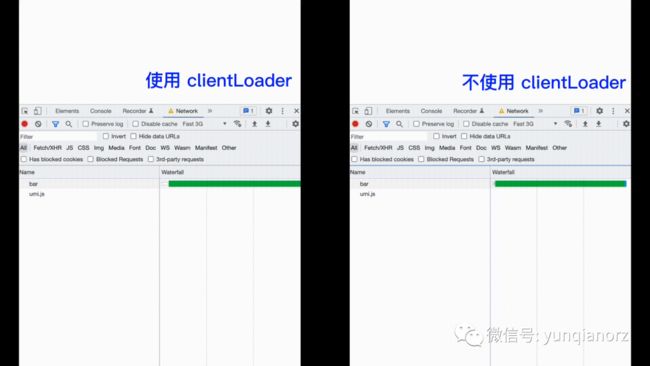
尽管有 useEffect、swr、react-query 等社区和官方的请求方案,以及 react 官方计划提供的 use,但大部分元框架都提供了框架层的数据获取方案,并且大部分是基于路由的声明式的。原因是,当追求极致的请求速度时,只有运行时库并不够用,只有和框架结合,尤其是路由和编译态的结合,才能达到最快最完美的请求状态:「尽快发起、并行执行」。比如,Remix 是 export loader 方法,Umi 是 export clientLoader 方法,Qwik City 是 export onGet 方法,Fresh 是 export 包含 GET 方法的 hander 对象,Solid Start 是 export routeData 方法。

再看 Umi 在这块的实践。
1、不能免俗,由于呼声比较大,Umi 也提供了 Vite 模式。但并没有在蚂蚁内推广,蚂蚁内还是用的 webpack + 我们自研的 MFSU 提速方案,够用。Umi 的 Vite 模式在快手公司的项目里倒是有大量应用。
2、Umi 提供了 clientLoader 请求方案,实现的时候有参考 Remix 的实现。Remix 基于 loader 达到 SSR 模式下的最快请求,但不支持 CSR,Umi 的 clientLoader 方案可实现 CSR 模式下的最快请求。
构建和 Bundless
构建一直是前端开发者关注的焦点。项目越来越大,依赖越来越大,构建越来很慢。

我观察到的趋势是,
1、情理之中的 Turbopack
2、Vite 大热
3、Webpack 依旧是生产构建的主力
4、真 Bundless 只存于企业内
Turbopack 是临时加的。前几天 Next.js 13 发布时出的消息,出自 webpack 作者之手,是基于 Rust 重写的类 webpack 方案,计划实现 80% 的 webpack 功能。时间原因,具体不展开了,前几天我有在公众号里写过一篇介绍。为啥说是情理之中?因为 webpack 已经 4 个月没更新了,webpack 作者一直在提私有库的 commit。前几天还在和同事闲聊,要么是被 Vite 逼躺平了,要么就是在憋大招。果然!目前还非常 alpha,可以等个半年再来看进展。
Vite 大热有多方因素,其一是因为有大量新兴框架采用,这在上一章节「框架设计」里有过介绍。另外,也可以从 npm 下载量看出,vite 周下载有 200W,已经快接近 webpack 的 1/10 了。这不是反话!
Webpack 依旧是生产构建的主力。尽管 Vite 大热,但据观察,包括使用 Umi 的 Vite 模式的用户来看,很多人用 Vite 的同学会把 Vite 只用于 dev,build 阶段依旧是用 Webpack。可能有几方面的考虑,1)Vite 的 build 也是 bundle,并不能少做什么,所以速度并没有优势,2)上生产时通常比较谨慎,大家觉得 Webpack 的 build 更可靠,3)Webpack 支持文件系统的持久缓存,合理利用对于 build 速度来说简直是神器。
真 bundless 只存于企业内。什么是真 bundless?就是比如我们要依赖 antd,只要 import 即可,无需在本地的任何时机做打包这件事。为啥 vite 不是?因为 vite 会在 optmize 阶段用 esbuild 打包依赖。为啥说只存于企业内?因为这依赖内部基建,现在的前端体系不打包是不可能的,本地不做打包这件事,总得有个地方做打包吧。那就是云端。蚂蚁内部今年依旧在推进这块的建设。

我们在这块的实践是,
1、ESMi 2
2、MFSU 3 和 4
3、基于持久缓存的 CI/CD 提速
ESMi 是我们内部的真 bundless 方案。本来计划搞个简单的 DEMO 来演示下 ESMi 2,但由于要提前录视频,相比计划提前了一周,目前 ESMi 2 还在联调阶段。大家可以关注我的公众号,如果有消息,我可以后续补一篇。前面说打包不再本地,总得有个地方做吧?那 ESMi 是在什么阶段做?简单来说,80% 的 npm 包会在我们将其 sync 到内网源的时候就做掉,然后使用时只管 import 即可。
MFSU 是关于基于 Webpack 的提速方案,已经迭代了好几个大版本,今年分别更新了 V3 和 V4,V4 可以将冷启动时间提升 25% 到 50%,根据项目类型效果不同。展开讲来不及,感兴趣的可以搜下我之前在 SEE Conf 的分享。

基于持久缓存的 CI/CD 提速是内部做的一个优化,基于 webpack 5 的持久缓存能力。效果是,在缓存生效的场景下,可以做到从 106s 到 10s 的十倍提速。实现比较简单,见图,在构建前置阶段下载缓存,然后构建,然后上传缓存。需要注意的是,1)缓存失效的控制非常重要,2)涉及缓存和 CD 环境,遇到问题是比较难排查的。但是这个方案上了近半年,还是比较稳定的。
原生语言
基于原生语言的前端工具大家不一定写过,但多少都有直接或间接地用过,因为大家在用的 Vite、Remix、Next.js、Umi 等框架和工具的背后,都有基于这些工具的使用。

我观察到的趋势是,
1、新工具不断涌现,全面占领前端工具领域
2、元框架大量应用基于原生语言的工具
除了之前就有的 esbuild、swc、es-module-lexer、sucrase、deno_lint、dprint,近期也涌现了一批新的这一类的工具,比如 bun、@parcel/css、rome format、turborepo、turbopack、stc 等,分别覆盖 javascript runtime、css、lint、monorepo、bundle、TypeScript 类型校验 等子领域。有一种 Native 语言全面占领前端工具领域的感觉。大家也可以考虑下,还有哪些领域可以有原生语言的发挥空间?
新出的元框架出于性能考虑,要么基于 Vite(间接使用 Native 语言工具),要么直接基于 esbuild 或 esbuild-wasm,已经不会纯用 JS 工具来实现。举一些例子,Umi 用了 esbuild、es-module-lexer、swc、@parcel/css;Fresh 用了 esbuild-wasm;remix 用了 esbuild;Astro Parser 用了 go 编译成 wasm;Next.js 用了 swc 和 turbopack。

我们在这块的实践是,
1、Umi 大量应用基于原生语言的工具。我们把 esbuild 用到了 JS 压缩、CSS 压缩、MFSU 依赖编译、SSR 编译、Jest 的 JS Transformer;把 swc 用到了 JS 编译、JS 压缩、Jest 的 JS Transformer;把 @parcel/css 用到了 CSS 压缩。
2、前面提到的 bundless 方案 ESMi。把 esbuild 用到了依赖编译、把 es-module-lexer 用到了依赖解析。
数据流

说到数据流,大家可能会想到老牌的 Redux、Dva、Mobx、RxJS、XState,也可能会想到新一代的 Recoil、Jotai、Zustand、Valtio、React Tracked、Redux Toolkit,以及还有很多使用度没那么广的方案 use-context-selector、react-easy-state、hox、useModel in umi、icestore、kylva、overmind 等,同时很多简单场景可能会直接裸用 hooks 组织。

我观察到的趋势是。
1、请求方案即数据流满足大量 CURD 场景
2、原子化数据流方案呈上升趋势
请求方案比如 SWR、React Query、Apollo、Relay、RTK Query、use-request 等算数据流方案吗?广义上看我觉得算,这属于直接把 client 的 ui 和 server 的数据串起来,省去了中间客户端数据处理的环节,解远程状态同步的问题,是另一种形式的数据流方案。随着以上这些库的流行,很多 CURD 项目其实已不需要传统的数据流方案,优点是用法简单,缺点是功能有限,扩展性有限。虽然有些库已经开始往传统数据流的功能上靠,增加了比如乐观更新、缓存等能力,但如果要加传统数据流的比如 redu/undo 之类的功能,大概率就不行了。
数据流领域个人感觉已经挖地差不多,较少有看到新出的眼前一亮的方案。除了原子化数据流,比如 Recoil、Jotai。最近新出的 Preact Signals 也是这一类型。这一类数据流是用原子化的方式,在 React 内部组织数据流,感觉是一种趋势,但我个人用起来心智上不太习惯。同时,他们有个缺点是 React 内部的数据流,有些方案会不允许在外部访问相应的 Store。

关于数据流,蚂蚁的实践是「确定了中后台新的数据流方案为 valtio」。光看结论比较简单,相比之下推导过程会更有意思一些,就是我们是怎么做出这个决定,怎么从数十个数据流方案里选择 valtio 的。

数据流方案有很多考量,比如心智模型、读取数据、写入数据、数据推导、异步 Action、渲染性能优化、Suspense 并发模式支持、SSR 支持、React 之外访问、组件封装、瞬时更新、插件中间件扩展、Redux DevTools 支持、兼容性、多实例和单实例、数据序列化能力、同步/异步更新、内存管理、测试、包尺寸等。具体不展开,感兴趣的可以去我的公众号搜「数据流2022」,有详细介绍。
我们的选择过程是这样。首先,从心智模型上考虑,我们有大量初级程序员,所以沿袭传统的数据流心智,用外部 Store 的方式会比较好,所以就淘汰了大量用原子化从下而上组织的数据流方案。然后做选择要基于业务场景,我们的场景是中后台业务,兼容性要求比较宽松,可以用基于 proxy 的数据流方案。最后对比了基于 proxy 的数据流方案,发现 valtio 相比下能满足各种需求,并且容易扩展,DX(开发体验)也很好。
Islands 架构
Islands 是新出的架构方案,可能不少同学没了解过,先花一些篇幅做下科普。

Islands 架构是 preact 作者提出的,解性能、JavaScript 尺寸、注水效率、SEO 等问题。比如图中的渲染,最右的是 Islands 架构的渲染方式,页面大部分是通过 HTML 做静态渲染,剩下一些包含交互的部分就是这个架构里的 Island(岛),会对他们产出单独的 JavaScript,做单独的渲染。据 Astro 的统计来看,基于 Islands 架构相比传统的 CSR/SSR 架构,能减少 83% 的 JavaScript 代码。
Islands 架构的实现不挑技术栈,现有实现有 Marko、Eleventy、Astro、Fresh、Island.js 等。Marko 和 Eleventy 甚至是在 Islands 架构提出之前就有的实现。但这些实现通常是基于 SSR/SSG + MPA 的。注意是「MPA」。所以虽然性能非常好,但我个人理解有个缺点是,在大家用习惯了 SPA 的时代,回归到 MPA,没有路由,切换页面从 HTML 开始,可能在交互上可能会带来一些不适应。

Islands 架构我理解的趋势是,框架大热但应用不多。比如头部的 astro 和 marko,star 数很高,但周下载分别只有 3w 和 1w 不到。那 Islands 架构适用于哪类应用呢?基于 SSR/SSG + MPA 的特点,我觉得潜在的场景比如:1、文档站,2、官网类应用,3、交互少的页面比如只有添加到购物车的宝贝详情页、4、天生就是 MPA 的 Hybrid 应用,等等。
Islands 架构我们还在观望,没有具体实践,有计划会在 Umi 中考虑增加一类应用类型做探索,同时在蚂蚁的业务中找到适合落地的应用。