数据在内存中的存储(详解) 不看后悔一辈子!!!
目录
1.数据类型的基本分类
2. 整形在内存空间中的存储情况
1.原码、反码、补码
2.数据的取值范围
3.什么是大端与小端?
相信很多小码农在C语言学到后期的时候,脑海里经常会浮现出这样一个问题:我定义的这些数据,他们在内存里面到底是怎样存放的?
今天,我就给大家深度探讨一下数据在内存中的一个存储情况

要知道数据在内存中的存储情况,我们首先就需要知道有哪些数据类型
1.数据类型的基本分类
1.整形家族
char
signed char
unsigned char
short
signed short
unsigned short
int
signed int
unsigned int
long
signed long
unsigned long
long long
signed long long
unsigned long long
注:char 类型的数据在内存中以ACEII码值存储,所以我们认为char 属于整形家族
2.浮点型家族
float
double
3.指针类型
int *p;
char *p;
float *p;
void *p;
4.空类型
void
注:空类型通常用于函数返回值、指针类型、函数的参数
5.构造类型
int [10] 数组类型 (除去变量名就是类型) 例:int a [5] 的类型为int [5]
struct 结构体类型
enum 枚举类型
umion 联合体类型
类型的意义:
1.决定了这个类型的变量在内存中所占空间的大小
2.用什么视角去看待
有了这些知识,我们接下来就开始进入正题了!小码农们记得看完哦 接下来才是重点!!!
2. 整形在内存空间中的存储情况
1.原码、反码、补码
首先我们要知道这么一个东西:原码、反码、补码
原码:直接将整形按照二进制位形式表示出来
反码:除符号位外,原码的其他位按位取反得到反码
补码:反码加1得到补码
特别注意:
1.正数的原码、反码、补码都相同
2.负数的原码、反码、补码遵循上面的规则
举个例子
int a = -1;
原码:10000000000000000000000000000001
反码:1111111111111111111111111111111111110
补码:1111111111111111111111111111111111111
原码转反码时符号位不变!!!
int a = 1;
原码:00000000000000000000000000000001
反码:00000000000000000000000000000001
补码:00000000000000000000000000000001
注:在内存中是以补码的形式存放的
到这里可能很多小码农就有一个疑问:我们好好的放着原码不用,为什么还要用补码去存?我只能说 ,你还是太年轻了

举个简单的例子,假设我们是以原码来存放数据类型的。
int a = 1;
原码:00000000000000000000000000000001
int b = -1;
原码:10000000000000000000000000000001
int c =a+b;
00000000000000000000000000000001
10000000000000000000000000000001
10000000000000000000000000000010
由此可见,如果在内存中用原码来存放数据,这里a+b的值就为2!而从数学的角度来说 1+-1应该等于0才对呀?
所以,科学家们就想了一个办法,就是用在内存中用补码的形式来存放数据类型
int a = -1;
原码:10000000000000000000000000000001
反码:1111111111111111111111111111111111110
补码:1111111111111111111111111111111111111
原码转反码时符号位不变!!!
int a = 1;
原码:00000000000000000000000000000001
反码:00000000000000000000000000000001
补码:00000000000000000000000000000001
a + b
(这里的1舍去 因为存不下 )
(1)00000000000000000000000000000000
补码:00000000000000000000000000000000
反码:00000000000000000000000000000000
原码:00000000000000000000000000000000
这就是为什么在内存中以补码的形式存放的原因了
2.数据的取值范围
我们都知道数据是有存储范围的,那这个范围到底有多大呢?接下来我们就以char 类型的数据为例
我们知道char 类型可以存放一个字节,也就是8个比特位的大小,如下:
注:以下是内存中的存储情况,也就是说此时存放的是数据的补码!!!
00000000 0
00000001 1
00000010 2
......
011111110 126
011111111 127
10000000 -128 注:当内存中识别到10000000时,会直接解析为-128
10000001 -127
.....
111111110 -2
111111111 -1
由此可知,char类型的数据可以存放的值为 -128~127
由此我们就可以举一反三,推出int short 等整形家族数据的取值范围啦
3.什么是大端与小端?
大端:将数据的高位字节序存放在低地址处,数据的低位字节序存放在高地址处
小端:将数据的高位字节序存放在高地址处,数据的低位字节序存放在低地址处
注:这里看不懂没关系,详解在下面呢
首先,我们在vs上面进行调试,观察数据在里面的存储情况
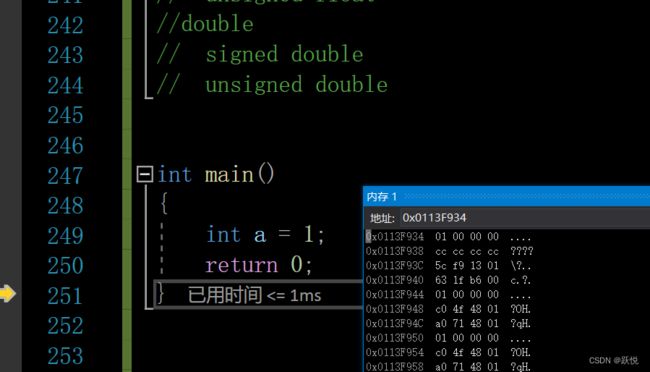
int a =1;
原码:00000000000000000000000000000001
反码:00000000000000000000000000000001
补码:00000000000000000000000000000001
注:在内存中存的是二进制的表示形式,而为了我们更好的观察,vs是以16进制的形式来给我们展示的
转换为16进制的表示形式
0x00000001
按理来说应该在内存中存的是00 00 00 01呀 这里为啥是01 00 00 00呢?
其实在内存中你是怎样存进去的并不重要,只要你能准确的拿出来就行
这里为了方便,我们以0x11 22 33 44 来举例子
注:假设左边为低地址,右边为高地址(下同)
1. 11 22 33 44
2. 44 33 22 11
3. 11 22 44 33
4. 11 33 22 44
...
后面还有很多很多种写法
而经过删选,有两种写法相对而言比较简单,被保留了下来
第一种:11 22 33 44 (这种就叫大端存储)
第二种:44 33 22 11 (这种就叫小端存储)
现在,相信你可以很好的理解下面这句话了
大端:将数据的高位字节序存放在低地址处,数据的低位字节序存放在高地址处
小端:将数据的高位字节序存放在高地址处,数据的低位字节序存放在低地址处
接下来我们写个代码来判断当前电脑上是大端存储还是小端存储(注:你的电脑是大端存储还是小端存储在你买电脑的时候就已经确定了,跟你用什么编译器无关)
思路:如果是大端存储,数据 1 的低地址处存放的就是0;而如果是小端存储,数据1的低地址处就是1。我们可以定义一个整形变量 int a = 1;用一个char * 类型的指针去存放它,此时存放的就是a的低位字节序的一个字节
int check_sys()
{
int i = 1;
return (*(char*)&i);
}
int main()
{
int ret = check_sys();
if (ret == 0)
{
printf("大端");
}
else if (ret == 1)
{
printf("小端");
}
return 0;
}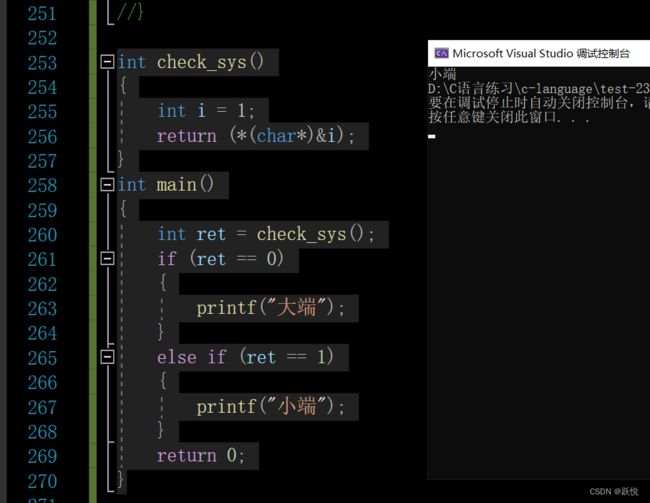
在我自己的电脑上就是小端存储,你们也可以去照着我这个思路,去看看自己电脑执行的的大端存储还是小端存储
相信你看完之后会对数据有更深的理解,那么本章就到此位置啦,各位小码农们,砸门下一篇文章见.
