详解StringBuilder和StringBuffer(区别,使用方法,含源码讲解)
目录
一.为什么要使用StringBuilder和StringBuffer
字符串的不可变性
性能损耗
二.StringBuilder和StringBuffer
StringBuffer源码讲解
使用方式
三.常用方法总结
示例:
四.StringBuilder和StringBuffer的区别
一.为什么要使用StringBuilder和StringBuffer
在引入StringBuilder和StringBuffer之前,我们可以回顾一下之前我们对于字符串的拼接操作,大多都是如下直接进行拼接:
public static void main(String[] args) {
String s = "hello";
s += " world";
System.out.println(s); // 输出:hello world
}这样的操作固然是没有问题的,但是如果要说到效率的话,这样的代码效率就非常的低下了,为什么低下呢?说到这里我们就要提到字符串的相关性质了。
字符串的不可变性
String类在设计的时候就是不可改变的,我们可以在JDK1.8的源码中看见如下的注释

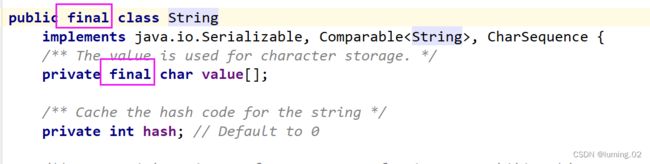
因此,我们平常使用的对于String字符串操作的方法,都是新建了一个对象来进行操作,想验证这个结论也很简单,我们随便选择一个方法,我们使用 “ == ” 相当于比较的是俩边变量的地址的哈希值,我们将一个字符串和对它进行大写转换后的字符串进行对比
public static void main(String[] args) {
String s = "hello";
//s.toUpperCase(Locale.of(s));
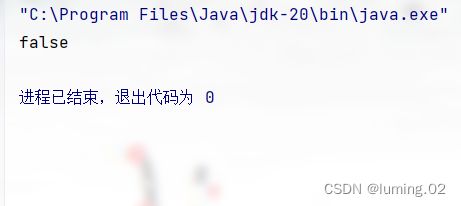
System.out.println( s == s.toUpperCase(Locale.of(s)));
}输出结果:
性能损耗
我们再回顾刚才对于字符串的拼接操作,每一次拼接都要新建一个对象的, 当拼接次数非常多的时候,会造成非常严重的性能问题,我们当然也可以验证这个性能问题,使用 currentTimeMillis 方法可以直接拿到当前时刻系统的时间戳,我们可以通过一个循环来展示一下使用传统方式拼接字符串的方式会有怎么样的一个性能损耗
public static void main(String[] args) {
long start = System.currentTimeMillis();
String s = " ";
for(int i = 0; i < 10000; ++i){
s += i;
}
long end = System.currentTimeMillis();
System.out.println(end - start);
}输出结果:

当然这还只是10000次循环就造成了82毫秒的运行时间,实际工程中所需的循环次数往往是不可估摸的,因此使用这种方式进行拼接往往是不能完成我们的性能要求的
二.StringBuilder和StringBuffer
为了解决上述的问题,我们就可以使用StringBuilder和StringBuffer来进行字符串的拼接等操作,我们可以打开API来查看什么是StringBuilder和StringBuffer
StringBuilder:

StringBuffer:

StringBuffer源码讲解
在一般使用的时候,他们的功能大致相同,这里笔者进行讲解就只选取其中一种,整体的包含的方法,使用的技巧大多都是一样的,因此不用担心知识覆盖面不全面,笔者这里就以 StringBuffer 来举例,我们可以在IDEA中打开 StringBuffer 的源码,我们可以发现它也是被 final 修饰,继承了父类 AbstractStringBuilder 并且实现了部分接口
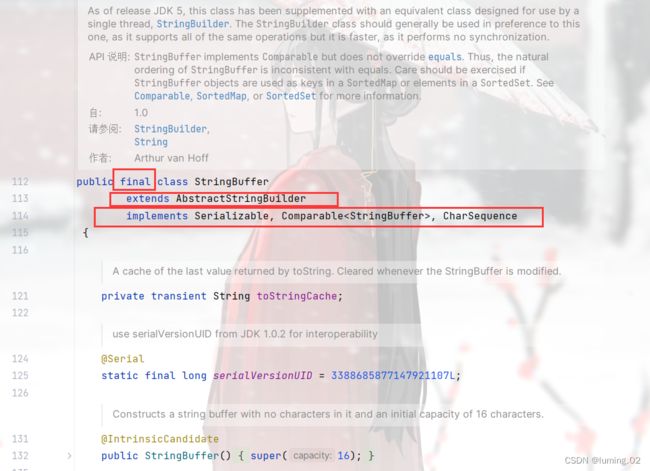
父类 AbstractStringBuilder 中一共俩个成员变量:

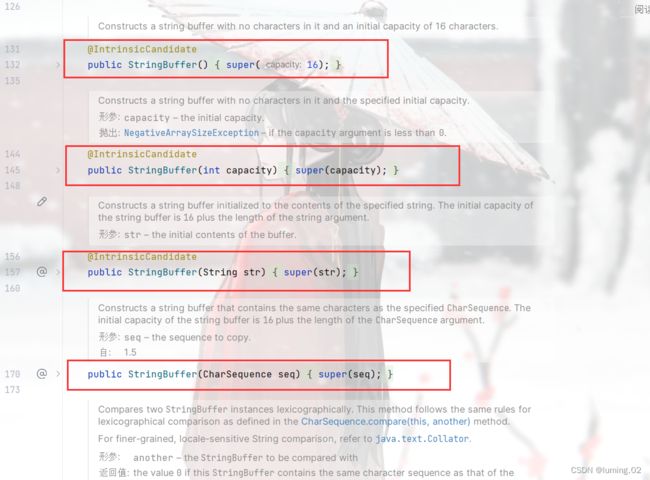
我们可以看见它的构造方法包含了不同初始化对应的操作:
使用方式
通过源码中的的super关键字结合和上述父类中的成员变量,我们可以得到以下结论:我们默认新建一个 StringBuffer 的时候实际上是新建了一个16字节的数组,我们也可以使用其他的俩个构造方法在传参的时候直接传入大小参数或者直接传入一个字符串
我们总结三种常用的初始化方式如下:
- 不传参数,默认16字节大小的数组
- 传入参数直接申明大小
- 传入字符串
StringBuffer stringBuffer1 = new StringBuffer();
StringBuffer stringBuffer3 = new StringBuffer(20);
StringBuffer stringBuffer2 = new StringBuffer("hello");三.常用方法总结
我们的StringBuilder和StringBuffer最大的特征就是他们内部是可变的,我们通过这俩个类去操作字符串的时候,可以不用新建一个对象,因此我们在进行字符串的拼接的时候往往都是用的这俩个类进行操作,这极大程度上有利于我们提高程运行的效率
我们再谈文章开始说的那个例子,我们使用StringBuffer中的 append 方法可以直接拼接字符,我们分别使用传统的拼接字符和这里的StringBuffer来对比拼接字符所需要的时间
public static void main(String[] args) {
long start = System.currentTimeMillis();
String s = "";
for(int i = 0; i < 10000; ++i){
s += i;
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println("=======分割行========");
start = System.currentTimeMillis();
StringBuffer sbf = new StringBuffer("");
for(int i = 0; i < 10000; ++i){
sbf.append(i);
}
end = System.currentTimeMillis();
System.out.println(end - start);
}输出结果:

我们可以直观的发现:使用 StringBuffer 来拼接字符比直接拼接的效率提高了几十倍,而如果加多循环次数的话,这个倍数还能继续再增加,将原本程序的效率提高几百倍不是梦
除了上述的appen方法,我们将常用的方法总结如下:
| 方法 | 说明 |
|
StringBuff append(String str)
|
在尾部追加,相当于 String 的 += ,可以追加: boolean 、 char 、 char[] 、 double、 float 、 int 、 long 、 Object 、 String 、 StringBuff 的变量
|
|
char charAt(int index)
|
获取 index 位置的字符
|
|
int length()
|
获取字符串的长度
|
|
int capacity()
|
获取底层保存字符串空间总的大小
|
|
void ensureCapacity(int mininmumCapacity)
|
扩容
|
|
void setCharAt(int index, char ch)
|
将 index 位置的字符设置为 ch
|
|
int indexOf(String str)
|
返回 str 第一次出现的位置
|
|
int indexOf(String str, int fromIndex)
|
从 fromIndex 位置开始查找 str 第一次出现的位置
|
|
int lastIndexOf(String str)
|
返回最后一次出现 str 的位置
|
|
int lastIndexOf(String str, int fromIndex)
|
从 fromIndex 位置开始找 str 最后一次出现的位置
|
|
StringBuff insert(int
offset, String str)
|
在 offset 位置插入:八种基类类型 & String 类型 & Object 类型数据
|
|
StringBuffer deleteCharAt(int index)
|
删除 index 位置字符
|
|
StringBuffer delete(int start, int end)
|
删除 [start, end) 区间内的字符
|
|
StringBuffer replace(int start, int end, String str)
|
将 [start, end) 位置的字符替换为 str
|
|
String substring(int start)
|
从 start 开始一直到末尾的字符以 String 的方式返回
|
|
String substring(int start, int end)
|
将 [start, end) 范围内的字符以 String 的方式返回
|
|
StringBuffer reverse()
|
反转字符串
|
|
String toString()
|
将所有字符按照 String 的方式返回
|
示例:
public static void main(String[] args) {
StringBuilder sb1 = new StringBuilder("hello");
StringBuilder sb2 = sb1;
// 追加:即尾插-->字符、字符串、整形数字
sb1.append(' '); // hello
sb1.append("world"); // hello world
sb1.append(123); // hello world123
System.out.println(sb1); // hello world123
System.out.println(sb1 == sb2); // true
System.out.println(sb1.charAt(0)); // 获取0号位上的字符 h
System.out.println(sb1.length()); // 获取字符串的有效长度14
System.out.println(sb1.capacity()); // 获取底层数组的总大小
sb1.setCharAt(0, 'H'); // 设置任意位置的字符 Hello world123
sb1.insert(0, "Hello world!!!"); // Hello world!!!Hello world123
System.out.println(sb1);
System.out.println(sb1.indexOf("Hello")); // 获取Hello第一次出现的位置
System.out.println(sb1.lastIndexOf("hello")); // 获取hello最后一次出现的位置
sb1.deleteCharAt(0); // 删除首字符
sb1.delete(0, 5); // 删除[0, 5)范围内的字符
String str = sb1.substring(0, 5); // 截取[0, 5)区间中的字符以String的方式返回
System.out.println(str);
sb1.reverse(); // 字符串逆转
str = sb1.toString(); // 将StringBuffer以String的方式返回
System.out.println(str);
}从上述例子可以看出:String和StringBuilder最大的区别在于String的内容无法修改,而StringBuilder的内容可以修改,因此频繁修改字符串的情况考虑使用StringBuilder
注意:String和StringBuilder类不能直接转换。如果要想互相转换,可以采用如下原则:
- String变为StringBuilder: 利用StringBuilder的构造方法或append()方法
- StringBuilder变为String: 调用toString()方法
四.StringBuilder和StringBuffer的区别
我们可以打开StringBuffer的源码,我们观察到几乎每一个StringBuffer的前面都有一个synchronized来修饰StringBuffer,这里的synchronized其实就可以理解为一个锁,被synchronized修饰的方法不允许同时被多个对象在同一时刻调用,这样的设立是为了多线程的程序的安全性。
举个通俗的例子:现在有小王,小李,小红三个人想上厕所,但是厕所只有一个,小王先去上厕所,那么小李或者小红就只能等小王用完厕所出来了后,才能去上厕所
而我们的StringBuffer就是类似这样设置的,当一个对象调用被synchronized修饰的方法的时候,这个方法就会被上锁,其他对象不能使用,只有当前这个对象使用完这个方法之后,也就是解锁之后,其他对象才能访问

当我们打开StringBuilder的源码会发现我们的StringBuilder并没有这样的设置操作

总结:
也就是说StringBuffer是为了多线程的安全,但是频繁的上锁解锁会降低代码的运行效率,而StringBuilder虽然没有安全性的考虑,但是它不用开锁解锁,所以运行效率更高,我们在编程中如果需要安全性就使用StringBuffer,如果是为了高效率就使用StringBuilder
 本次的分享就到此为止了,希望我的分享能给您带来帮助,也欢迎大家三连支持,你们的点赞就是博主更新最大的动力!
本次的分享就到此为止了,希望我的分享能给您带来帮助,也欢迎大家三连支持,你们的点赞就是博主更新最大的动力! 如有不同意见,欢迎评论区积极讨论交流,让我们一起学习进步!
如有不同意见,欢迎评论区积极讨论交流,让我们一起学习进步! 有相关问题也可以私信博主,评论区和私信都会认真查看的,我们下次再见
有相关问题也可以私信博主,评论区和私信都会认真查看的,我们下次再见