VDL-第二节CNN(上)
目录
Ⅰ基本概念
一、卷积神经网络
① 人类视觉系统层次结构
② 局部感受野
③从神经网络到卷积神经网络
④ 局部连接的实现方式
⑤ 通过卷积操作实现
⑥ 卷积的作用
⑦ 池化操作
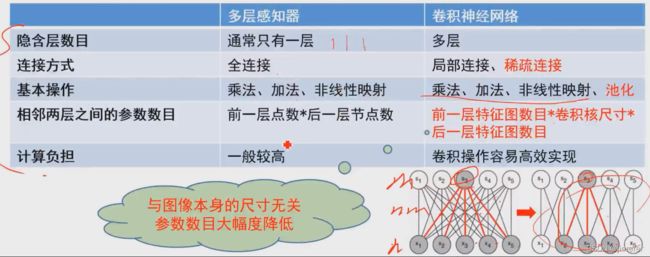
⑧ 卷积神经网络与多层感知器对比
⑨ 多通道的卷积如何实现
⑩ 卷积神经网络示意图
Ⅱ发展历程
一、 LeNet
二、AlexNet
三、 R-CNN
四、FCN
五、 Conv-Deconv Net
六、 U-Net
Ⅲ网络特点
一、层次化的特征学习
二、局部感受野(局部连接)
三、权值共享(卷积)
四、池化
深度学习入门
Ⅰ基本概念
一、卷积神经网络
① 人类视觉系统层次结构

像素——第一层处理一些线段——第二层组合起来有形状——第三层成为有语义信息的物体

② 局部感受野
前面的多层感知器是每个隐含层都对应输出层称得上是全连接,所以对于输出结点来说,他就接受所以前面结点,因此称为全局感受野,而局部感受野顾名思义就是结点只去感受一小部分,其他与他无关。
③从神经网络到卷积神经网络
传统神经网路(全连接)参数数目巨大难以训练容易梯度消失/爆炸

参数跟输入图像大小无关,跟感受野的范围和隐藏结点数目的大小有关
一个小范围内的像素和权重做加权和
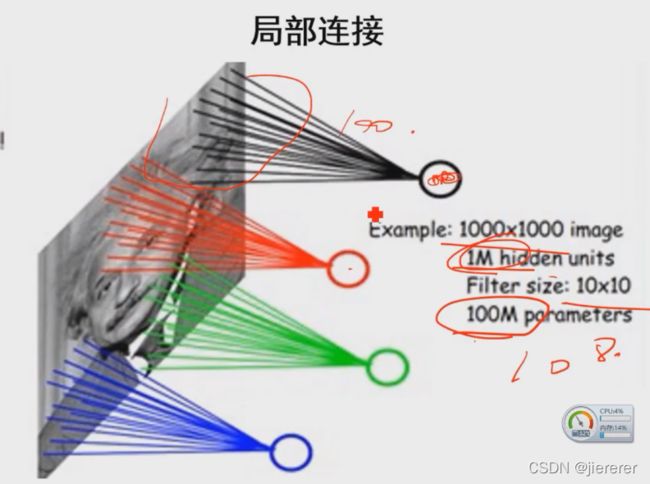
④ 局部连接的实现方式
——对应位置元素相乘再相加(加权和)
——数学上称为相关运算,记为
——Y是滑动到特定的地方的结果,不是总的结果。所以在整个图像上遍历一遍得到的也是一个二维图像。
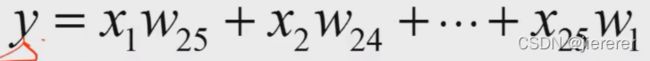


⑤ 通过卷积操作实现
—— 旋转180°——
——w' 旋转180°后变w的对应位置元素相乘再相加(加权和)
——数学上成为卷积运算,记为
卷积?
1、W(权重)旋转180°得到W’
2、X与W'进行相关运算(对应位置加权和)
,W为卷积核。
卷积相比于相关 的优势在于对称性
,相关不具备对称性


⑥ 卷积的作用
a 用于提取特征,得到的结果称为特征图
b 每个卷积核的初始值通常设为随机数,具体功能由网络学习来决定,确定卷积核各个元素的值正是网络学习的主要目的。
c 例子
学习好后的卷积:第一层是一些线段、颜色;第二层组合出一些更复杂的,圆拐点之类的,随后越来越复杂,到最后呈现出具有一定语义完整性的模式
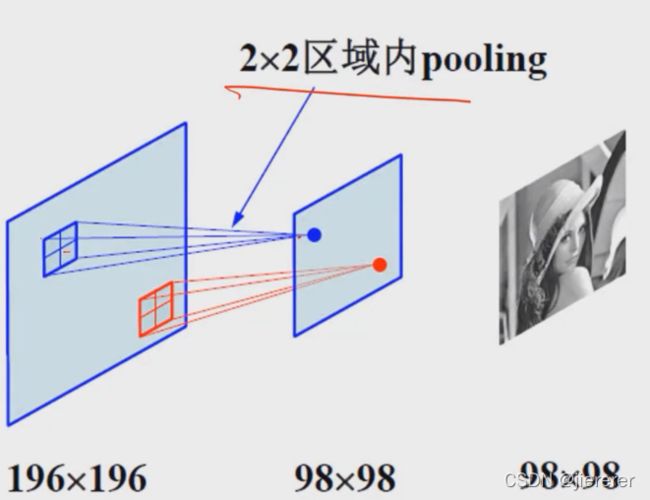
⑦ 池化操作
a 图像区域内关于某个特征的统计聚合。例如比较大的一个特征图,每个里面取一个最大的然后组成一个比较小的一个特征图,存的都是原来的最大值,反应最强烈,对于分类回归等可能最有用。其他信息量不高或者噪声。
b 除了取最大值也可以取平均值
c 本质是下采样的操作,2×2的pooling就等于是每个2×2区域只保留一个值。196→98

⑧ 卷积神经网络与多层感知器对比
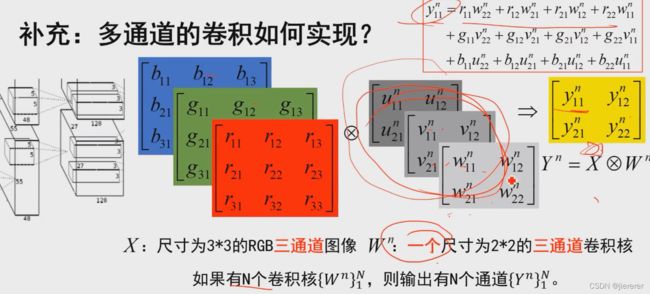
⑨ 多通道的卷积如何实现
给定一个三通道的卷积核得到一个单通道的输出
卷积核的通道数=输入的通道数
输出的通道数=卷积核的个数
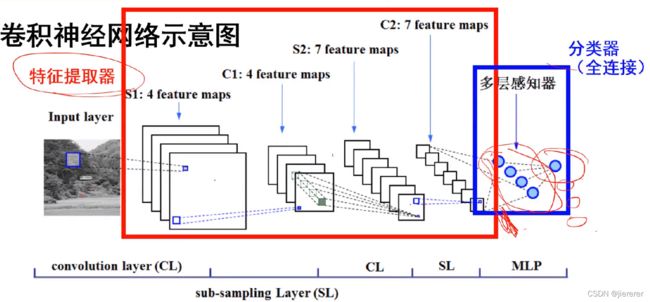
⑩ 卷积神经网络示意图
a 特征相当于输入——隐层——输出,要分成多少类
b 卷积神经网络= 特征提取器+分类器这样的
c 特征提取器 里通过(卷积)(下采样)交替操作,整个特征提取器是通过训练来学习这些参数的
d 多层感知器 有特征了就要进行分类,用多层感知器前后都是神经网络,可以联合训练,分多少类就多少个节点
Ⅱ发展历程
一、 LeNet
——图像分类(手写数字识别)。
二、AlexNet
——证实了卷积神经网络可以用大规模训练数据得到优秀的分类效果/GPU在深度学习中重要作用/ReLU\Dropout。
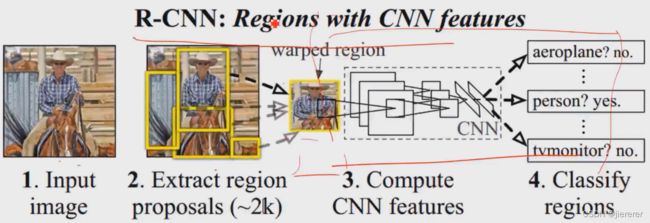
三、 R-CNN
——从图像分类到目标检测,证实将图像局部作为基本研究对象,将原问题转为分类问题/ fast R-CNN.. / 图像分割、图像描述、图像解析
① 目标检测流程:
② Proposals用传统方法提取,后面的用网络来分类,相当于把目标检测问题转换为图像分类问题。
③ 基于R-cnn的目标检测的工作
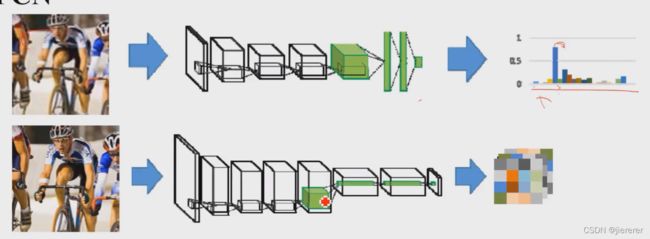
四、FCN
——整幅图像输入,整幅分割结果输出,第一个“端到端”式分割模型/可以接受任意尺寸
① 端到端?
有很多pixel-wise的标注问题,需要对图像中每一个像素都有特定的标记,分割所属的 类别,前景还是背景,深度估计深度值等等。
输入是待处理的图像,处理之后能够直接输出要的结果,不管是深度图还是分割结果
② 怎么做?改进:把全连接层变成卷积,全连接输出是节点就不是二维的了改成卷积也 是map
上图全连接丢了位置信息
下图FCN,得到一个更小的图,放大之后就是分割
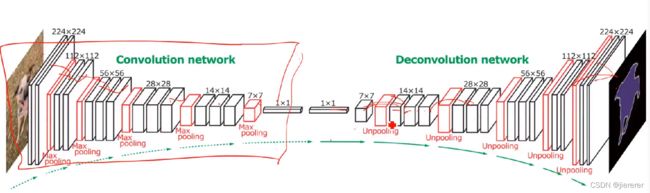
五、 Conv-Deconv Net
实现由粗到精力、恢复细节弥补FCN的一步到位 / “沙漏级”网络成为后面很多像素级标注问题的基础
FCN 一直特征提取从100×100到7×7好几步,最后一步恢复回100×100,损失太多细节信息,提出Conv-Deconv Net,对称,逐级上采样,精度细节信息都要好很多。
具体实现是在pooling的时候记录位置,在unpooling的时候拿来用。
如下图在pooling的时候记得抽取的位置Locations,然后拿去处理,最后unpooling的时候把位置拿出来对着。
六、 U-Net
(Conv-Deconv形式的各种模型)
如何提高分割结果中边界部分的精度?
在图像输入,浅层的空间位置保存的比较好,跟漏斗型过去的特征图并到一起。
深层的语义信息更好,并到一起




Ⅲ网络特点
一、层次化的特征学习
① 从图像底层开始学习,层数加深能够学到更高层的语义信息
② 不必事先提取人为设计的特征
③ 机器学习的特性未必优于人工
二、局部感受野(局部连接)
① 图像的空间相关性:局部区域内像素联系强,远的弱
② 没必要对全局图像感知,只需要对局部区域感知
③ 极大降低了网络参数的数目
④ 增加网络层数能保证节点具有更大范围的实际感受野
感受野怎么计算?

三、权值共享(卷积)
这个区域的每个像素值是共享卷积核中的参数的,
四、池化
① 降低特征图的尺寸,牺牲空间细节信息,突出更强烈的响应。
② 是卷积神经网络具有平移不变性和畸变不变性。图像中某种特征被检测出(即他在对卷积核有较高响应),具体位置便不再重要,之后需要大致保持与其他特征相对位置即可。利于应对实际问题中各种不同类型、不同质量
③ 池化与参数数目
④ 数据增广 专门对输入图像进行平移、畸变等处理来提高网络泛化性能
深度学习入门
1、自己对哪个方向感兴趣(分类?检测?分割?)
2、技术的发展路线。要研究DeconvNet ,基于VGG实现的,要先学号VGG。
现在网络种类特别多,但是大多数都是已有模型基础改造。加入多尺度、BN、multi-task,多极子网络cascade等,关键学好基础的模型Alexnet、VGG、ResNet,这三个使用频率高尤其后两者,有了这个基础能看到其他基于他们的工作。
总结整理哪些改进具有哪些特定的效果,自己后面也有可能用到。
CNN
——最左边是数据输入层
——中间是
- CONV:卷积计算层,线性乘积 求和。
- RELU:激励层,上文2.2节中有提到:ReLU是激活函数的一种。
- POOL:池化层,简言之,即取区域平均或最大。
——最右边是全连接层。
卷积计算层
这几个部分中,卷积计算层是CNN的核心
它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)
为对原始图像进行过滤的结果,我们称之为feature map,它是每一个feature从原始图像中提取出来的“特征
——几个重要参数
a. 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
b. 步长stride:决定滑动多少步可以到边缘。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。

- 两个神经元,即depth=2,意味着有两个滤波器。
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2。
- zero-padding=1。
局部感知机制。
左边数据在变化,每次滤波器都是针对某一局部的数据窗口进行卷积,这就是所谓的CNN中的局部感知机制。
打个比方,滤波器就像一双眼睛,人类视角有限,一眼望去,只能看到这世界的局部。如果一眼就看到全世界,你会累死,而且一下子接受全世界所有信息,你大脑接收不过来。当然,即便是看局部,针对局部里的信息人类双眼也是有偏重、偏好的。比如看美女,对脸、胸、腿是重点关注,所以这3个输入的权重相对较大。
参数(权重)共享机制。
与此同时,数据窗口滑动,导致输入在变化,但中间滤波器Filter w0的权重(即每个神经元连接数据窗口的权重)是固定不变的,这个权重不变即所谓的CNN中的参数(权重)共享机制。
再打个比方,某人环游全世界,所看到的信息在变,但采集信息的双眼不变。btw,不同人的双眼 看同一个局部信息 所感受到的不同,即一千个读者有一千个哈姆雷特,所以不同的滤波器 就像不同的双眼,不同的人有着不同的反馈结果。
ReLu

加大层数

全连接层


一套下来是前向传播,得到一组输出,然后通过反向传播来不断纠正错误,进行学习。
输入层——数据输入预处理
原因:
- 输入数据单位不一样,可能会导致神经网络收敛速度慢,训练时间长
- 数据范围大的输入在模式分类中的作用可能偏大,而数据范围小的作用就有可能偏小
- 由于神经网络中存在的激活函数是有值域限制的,因此需要将网络训练的目标数据映射到激活函数的值域
- S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X),f(100)与f(5)只相差0.0067
功能:(一般均值化处理和归一,后两者不用)
- 均值化处理 --- 即对于给定数据的每个特征减去该特征的均值(将数据集的数据中心化到0)
- 归一化操作 --- 在均值化的基础上再除以该特征的方差(将数据集各个维度的幅度归一化到同样的范围内)
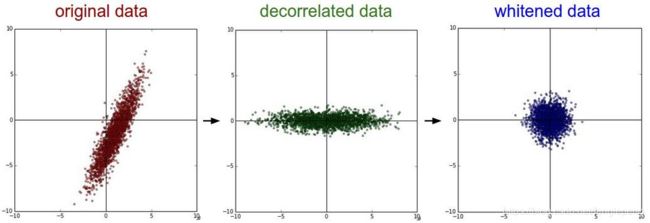
- PCA降维 --- 将高维数据集投影到低维的坐标轴上, 并要求投影后的数据集具有最大的方差.(去除了特征之间的相关性,用于获取低频信息)
- 白化 --- 在PCA的基础上, 对转换后的数据每个特征轴上的幅度进行归一化.用于获取高频信息.

Batch Normalization 层——一般用于卷积层后面,主要是使得期望结果服从高斯分布,好像使用之后可以更快的收敛
——切分层
——融合层
——感受野
在卷积神经网络中,感受野的定义是卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
VGG
2、2、3、3、3 尺寸变小,宽度变大。臃肿计算量很大准确度不是很高