《数据库系统概念》学习笔记——第十章 存储和文件结构
目录
第十章 存储和文件结构
10.1 物理存储介质概述
10.2 磁盘和快闪存储器
10.2.1 磁盘的物理特性
10.2.2 磁盘性能的度量
10.2.3 磁盘块访问的优化
10.2.4 快闪存储
10.3 RAID
10.3.1 通过冗余提高可靠性
10.3.2 通过并行提高性能
10.3.3 RAID级别
10.3.4 RAID级别的选择
10.3.5 硬件问题
10.3.6 其他的RAID的应用
10.4 第三级存储
10.4.1 光盘
10.4.2 磁带
10.5 文件组织
10.5.1 定长记录
10.5.2 变长记录
10.6 文件中记录的组织
10.6.1 顺序文件组织
10.6.2 多表聚簇文件组织
10.7 数据字典存储
10.8 数据库缓存区
10.8.1 缓冲区管理器
10.8.2 缓冲区替代策略
总结
第十章 存储和文件结构
10.1 物理存储介质概述
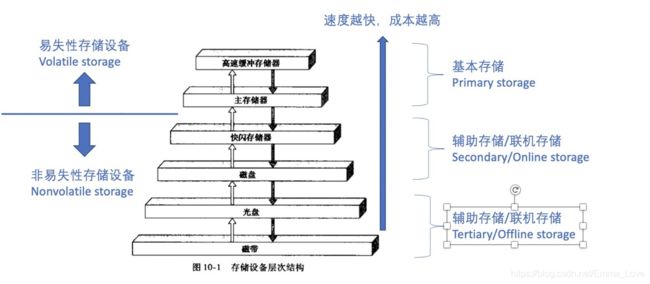
按照访问的数据的速度、购买介质的每单位数据的成本、以及介质的可靠性分类:
10.2 磁盘和快闪存储器
10.2.1 磁盘的物理特性
磁盘的物理结构:
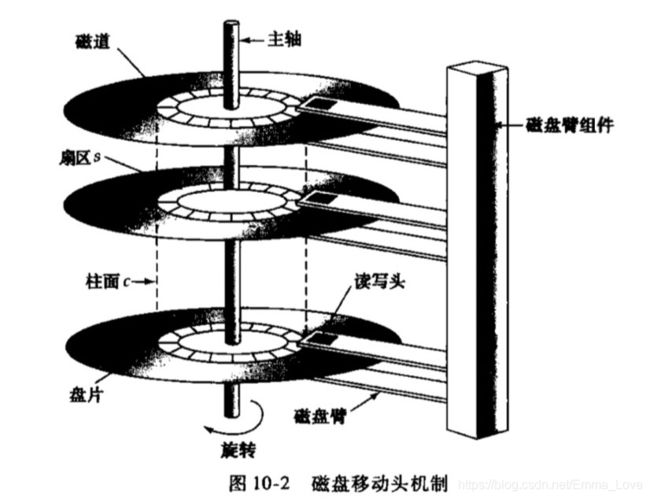
磁盘控制器(disk controller)是计算机系统和实际的磁盘驱动器硬件之间的接口。
磁盘控制器在磁盘驱动单元的内部实现。它接受高层次的读写扇区的命令,然后开始动作,如:移动磁盘臂寻找到正确的磁道,并实际的读写数据。
磁盘控制器为它所写的每个扇区附加校验和(checksum),校验和是从写到三区的数据计算得到的。
- 当读取一个扇区时,磁盘控制器会对读到的数据计算校验和,并把它与存储的校验和做比较
- 如果数据被破坏,则检验和不一致的概率就很高。
- 如果发生这种错误,磁盘控制器会重读几次。如果错误继续发生,则它会发出一个读操作失败的信号。
坏扇区的重映射(remapping of bad sector)
磁盘控制器还能够进行坏扇区的重映射。当磁盘初始格式化/试图读取一个扇区时,如果磁盘控制器检测到一个损坏的扇区,它会把这个扇区在逻辑上映射到另一个物理位置。重映射记录在磁盘或非易失性存储器中,而写操作在新的位置执行。
磁盘通过高速互联通道连接到计算机系统,通用的将磁盘连接到计算机的接口有:
- SATA,也叫串行ATA(Serial ATA)
- 小型计算进系统互联(Small-Computer-System Interconnect, SCSI)
- SAS,也叫串行附着SCSI(serial attached SCSI)
- 光纤通道接口(Fibre Channel Interface)
磁盘可以通过电缆直接与计算机系统的磁盘接口相连,也可以通过高速网络将远端磁盘与磁盘控制器相连。
存储局域网(Storage Area Network, SAN)体系结构:
在SAN中,大量的磁盘通过高速网络与许多计算机服务器相连。通常磁盘采用独立冗余阵列(Redundant Array of Independent Disk, RAID)技术进行本地化组织,从而给服务器一个很大且非常可靠的磁盘的逻辑视图。SAN意味着磁盘可以由并行运行一个应用程序的不同服务器所共享。
网络附加存储(Network Attached Storage,NAS)
由SAN发展而来。NAS和SAN类似,但是它通过使用网络文件系统协议(如NFS或CIFS)提供文件系统接口,而不是你看似一张大磁盘的网络存储器。
10.2.2 磁盘性能的度量
磁盘质量的主要度量指标:容量,访问时间,数据传输率,可靠性。

10.2.3 磁盘块访问的优化
磁盘I/O请求是由文件系统和大多数操作系统具有的虚拟内存管理器产生。
每个请求指定了要访问的磁盘地址,即:块号。
磁盘的连续请求可分为两类:。
- 顺序访问(sequantial access)模式:连续的请求会请求处于相邻的磁道或者相邻的磁道上连续的块。顺序访问中只有读取第一个块时需要寻道,后续的请求不需要寻道。
- 随机访问模式(random access)模式:相继的请求会请求那些随机位于磁盘上的块,每一次请求都需要一次磁盘寻道。一张磁盘在每秒能够满足的随机块访问的数量取决于寻道时间。
提高访问块的速度的技术:
| 缓冲 buffering |
从磁盘读取的块暂时存储在内存缓冲区中,以满足将来的需求。 缓冲区通过操作系统和数据库系统共同运作。 |
| 预读 read-ahead |
当一个磁盘块被访问时,相同磁道的连续块也被读入内存缓冲区,即便美原油针对这些块的即将来临的请求。 - 能够提高顺序访问的请求处理速度;但是对随机块访问不是很有效。 |
| 调度 scheduling |
磁盘臂调度算法(disk-arm scheduling)试图把对磁道的访问按照能增加可以处理的访问数量的方式排序。 通常用的算法有电梯算法(elevator algorithm):磁盘控制器对请求进行重新排序,因为它最清楚磁盘块的组织、盘片的旋转位置和磁盘臂的位置。电梯算法是从内到外-再从外到内的移动,在每条有请求的磁道上停下并提供服务。 |
| 文件组织 file organization |
为了减少访问块的时间,可以按照与预期的数据访问方式最接近的方式来组织磁盘上的块。 例如:WIndows和Unix OS,对用户隐藏磁盘组织,并由OS内部管理空间的分配。它们为一个文件分配一个或多个连续的块==>保证顺序文件访问只需寻道一次。过段时间,文件可能变得碎片化(fragmented),此时,OS可以对磁盘上的数据进行一次备份,然后再恢复整张磁盘。恢复操作将每个文件的块连续的写会。 |
| 非易失性写缓冲区NV-RAM Non Volatile Random-Access Memory |
主存中的内容在发生电源故障时将全部丢失,所以数据库的更新必须记录到磁盘上,这样才能再崩溃时保存。 更新密集的数据库应用的性能取决于磁盘写操作的速度。
NV-RAM大幅度加快了写磁盘的操作速度。 NV-RAM的内容在发生故障时不会丢失,一种实现方式是使用有备用电池的RAM。其思想是: 数据库系统请求往磁盘上写一个块时---磁盘控制器将这个块写到NV-RAM缓冲区,然后立刻通知写操作已经完成---当磁盘没有其他请求,或者NV-RAM缓冲区已满时,磁盘控制器将这些数据写到磁盘上相应的目标地址。
只有当NV-RAM已满时,数据库的写请求才会有延时。
从系统崩溃中恢复时,NV-RAM中所有缓冲区未完成的内容将会写回到磁盘上。 |
| 日志磁盘 log disk |
日志磁盘,即专门用于写顺序日志的磁盘,是减少写等待的另一种方法。 对日志磁盘的所有访问都是顺序的,这从根本上消除了寻道时间。 与NV-RAM类似,所有操作都在日志磁盘中记录,数据库系统不用等待操作的完整,日志磁盘会在以后完成写操作。日志磁盘可以最小化磁盘臂的移动而重排写操作的顺序。
如果系统在实际磁盘写操作完成前崩溃,则系统恢复后,可以读取日志磁盘,完成那些还没有完成的操作。
支持上述日志磁盘的文件系统称为日志文件系统(journaling file system) |
10.2.4 快闪存储
快闪存储器一共有两种:
- NOR快闪:允许随机访问闪存中的单个字,并且拥有和主存可以媲美的读取速度。
- NAND快闪:与NOR不同,它的读取是将整个数据页(page)从NAND快闪取到主存储器中,该page包括大概512-4096字节的数据。page与之前的extent的概念类似。NAND比NOR更便宜,并且拥有高速的存储容量,目前使用广泛。
NAND构建的存储系统提供与磁盘存储器相同的面向块的接口。
相对于磁盘,NAND的优点有:
- 提供更快的随机存取
- 虽然闪存的传输速率(通常为20MB/s)比磁盘低,但是固态驱动器可并行的使用多块闪存芯片,将传输速率提高到200M/s,这比大多数磁盘要快。
NAND的缺点:
- 写入比较复杂。写一个闪存页面通常要几微秒。
- 一旦写入,不能直接覆盖,只能先擦除,在重写。
- 一个闪存页面可擦除的次数存在限制,通常约为10万-100万次。一旦达到限制,在存储位可能会发生错误。
闪存转换层(flash translation layer)
混合硬盘驱动器(Hybrid Disk Drive):
它结合了小容量闪存存储器的硬盘系统,对频繁访问的数据,该驱动器作为缓存使用。频繁访问但很少更新的数据最适合存储域闪存存储器中。
10.3 RAID
10.3.1 通过冗余提高可靠性
N张磁盘组成的集合中某张磁盘发生故障的概率会比特定的以一张磁盘发生的概率要高。
引入冗余(redundancy)是解决这个可靠性问题的方法。冗余对发生故障时重建信息。
实现冗余最简单的方式是:复制每一张磁盘。这种技术称为镜像(mirroring)。
- 一张逻辑磁盘由两张物理磁盘组成,并且每月一次写操作都要在两张磁盘上执行。如果其中一张磁盘发生了故障,数据可以从另一张磁盘读出。只有两张磁盘都发生故障,数据才会丢失。
- 一般情况下,先写一个磁盘,再对另一个进行拷贝。
10.3.2 通过并行提高性能
磁盘镜像可以使得我们对多张磁盘进行并行访问,提高访问速度。
此外,也可以采用数据拆分(Striping Data)提高传输速率。有不同层次的数据拆分形式,如:块级拆分和比特级拆分等。其中块级拆分是最常用的数据拆分。
- 比特级拆分(Bit-Level Striping):将每个字节按照比特拆分,存储到多个磁盘上。
- 例如:有一个由8张磁盘组成的阵列,将每个字节的第i位存储到第i张磁盘,这8张磁盘阵列可以被看成单一的磁盘。这张大磁盘的一个扇区的大小是通常大小的8倍。它的传输速率也是通常的8倍。每张磁盘都参与每次的访问,每次读取的数据量是一张磁盘上的8倍。位级别的拆分可以推广到磁盘综述为8的整数倍或8的因子情况,如使用4张磁盘,则第第i位和第i+4位可以写到第i章磁盘上。
- 块级别的拆分(Block-Level Striping):将块拆分到多张磁盘上。假设有n张磁盘,则将第i块存储到第(i mod n)+1张磁盘上。块级拆分也提高了数据的传输速率。
磁盘中的并行主要有两个目的:
- 负载平衡多个小的操作(块访问),以提高这种访问操作的吞吐量。
- 并行执行大的访问操作,以减少大的访问操作的响应时间。
10.3.3 RAID级别
RAID,Redundant Array of Independent Disk, 独立磁盘冗余阵列。
除了磁盘镜像,奇偶校验结合磁盘拆分思想也可以实现冗余。
结合奇偶校验位、磁盘拆分思想、以及磁盘镜像,并对成本和性能进行权衡,提供了多种不同的冗余替代方案,并且分为RAID级别。下图中P表示纠错位,C表示数据的拷贝。
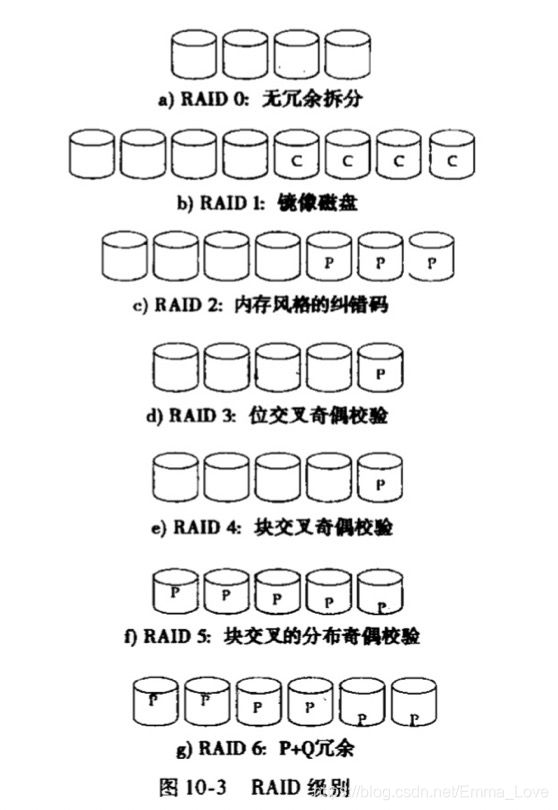
| RAID 0: 无冗余拆分 |
块级拆分,无任何冗余的磁盘阵列。图10-3(a)提供了大小为4的磁盘阵列 |
| RAID 1: 镜像磁盘 |
使用块级拆分的磁盘镜像。为每个磁盘提供一个镜像备份。 |
| RAID 2: 内存风格的纠错码 |
也称为内存风格的纠错码(Error-Correcting-Code, ECC)组织结构。 通过结合字节拆分分散存储在多张磁盘上,可以直接在磁盘陈列上使用奇偶校验位。 10-3(c)显示了RAID2级方案,标记P存储了纠错位。如果一张磁盘发生故障,可通过其余位+纠错码来重建数据。
奇偶校验: 内存系统的每个字节都有一个与之相关的奇偶校验位,它记录了这个字节中为1的位数是偶数(奇偶校验位=0)还是奇数(奇偶校验位=1)。如果其中一位被破坏,那么奇偶校验位就会改变,而与存储的奇偶校验位不匹配。同样,我们也可以发现存储的奇偶校验位的改变。 通过奇偶校验位内存可以检测到所有1位的错误。
纠错码机制存储两个或更多的附加位,并且如果有一位被破坏,它可以重建数据。 |
| RAID 3: 位交叉奇偶校验 |
位交叉的奇偶校验组织结构。在RAID2级的基础上进行改进。 因为磁盘存储器可以检测到一个扇区是否正确地读出,所以可以使用一个唯一的奇偶校验位来检测和纠错。 其思想: 如果一个扇区被破坏,系统能够准确的知道是哪个扇区坏了,并对扇区中的每一位,通过计算其他磁盘上对应扇区的对应位的奇偶值来推断出该扇区是1还是0。如果其余位的奇偶校验位等于存储的奇偶校验位,则丢失的位是0,反之是1。
RAID3级比RAID2级优于节省了存储空间。 RAID3级比RAID1级的优势: - 减少了存储的开销 - RAID3使用N道数据拆分,所以对每个字节的读写散步在多张磁盘中,所以传输率是RAID1级的N倍;但另一方面每个磁盘都要参与到I/O请求中,所以它每秒钟支持的I/O操作数要少。 |
| RAID 4: 块交叉奇偶校验 |
它也是用块级拆分,此外在一张独立的磁盘上为其他N张磁盘上对应的块保留一个奇偶校验位。如果一张磁盘发生故障,可以用其他磁盘对应的块和奇偶校验块进行数据重建。
它读取一个块时只访问一张磁盘,因此允许其他的请求在其他磁盘上执行==>每个访问的数据传输率较低,但是可以并行的执行多个读操作,产生较高的I/O传输率。
由于所有磁盘都可以并行的读,所以读取大数据和写入大数据时,传输率很高,因为奇偶校验也可以并行操作。
对于小数据的写入不能并行执行。写一个块需要执行以下2次旧值读取和2次新值写入操作:读取存储这个块的磁盘+存储奇偶校验位的磁盘;写入这个块+更新奇偶校验位。 |
| RAID 5: 块交叉的分布奇偶校验 |
块交叉的分布奇偶校验位的组织结构。在RAID4上进行改进,将数据和奇偶校验位分布到所有的N+1张磁盘中,而不是N张磁盘存数据,1张存储奇偶校验位。 如下图所示, P0是 其余四个块的奇偶校验块;每张磁盘都存储了其他四张磁盘对应位置的奇偶校验块。 注意:奇偶校验块不能和其所对应的数据库存储在同一磁盘下。否则可能会同时丢失二者的信息。 ----------------------- P0 | 0 | 1 | 2 | 3 | ----------------------- 4 | P1 | 5 | 6 | 7 | ----------------------- 8 | 9 | P2 | 10 | 11 | ----------------------- 12 |13 | 14 | P3 | 15 | ----------------------- 12 |13 | 14 | 15 |P4 | ----------------------- |
| RAID 6: P+Q冗余 |
P+Q冗余方案。与RAID5相似,引入了额外的冗余信息。 |
10.3.4 RAID级别的选择
选择RAID级别应该考虑以下的因素:
- 所需的额外磁盘存储带来的花费
- 在I/O操作数量方面的性能需求
- 磁盘故障时的性能
- 在数据重建过程(rebuild performance 即,故障磁盘上的数据在新磁盘上重建的过程)中的性能
重建故障磁盘上数据的时间:RAID1最简单,直接从另一张磁盘中拷贝即可得到;其他级别的重建需要访问磁盘阵列中所有其他的磁盘来进行重建,比较复杂,耗时较长。
RAID0 - 可以用于数据安全不是很重要的高性能应用。
RAID2和RAID4被RAID3级和RAID5级所包含,所以一般RAID的选择只在RAID0,RAID1,RAID3和RAID5,RAID6上进行。
而RAID3的比特级拆分不如RAID5的块级拆分,RAID5在大数据上与RAID3同样好的数据传输率,同时对小数据的传输使用更少的磁盘,其并行性会减少延迟。实际中RAID3的性能会比RAID5的更差。
==>那么问题就变成如何在RAID1,RAID5和RAID6上进行。
RAID6级比RAID5具有更高的可靠性,可以用于数据安全十分重要的应用。
RAID1:提供较好的写操作的性能,在例如数据库系统日志文件的存储这类的应用中使用广泛
RAID5:相比RAID1需要较低的存储负载,但是写操作具有更高的开销。对于经常用读操作而很少进行写操作的应用,RAID5是首选。
此外,设计者还要考虑到磁盘陈列包含的磁盘的数量,每个奇偶校验位应该保护多少位数据?
- 磁盘阵列中的磁盘越多,数据传输率越高,但是系统会更昂贵
- 奇偶校验位保护的数据位越多,存储奇偶校验位的空间越小,但是会导致数据丢失的概率增加。
10.3.5 硬件问题
RAID的实现还需要靠考虑硬件层的因素。
RAID可以不改变硬件层,只在软件层上实现=>软件RAID(software RAID);具有硬件支持的系统称为硬件RAID(hardware RAID)系统。
硬件RAID能够实现使用非易失性RAM在需要执行的写操作执行之前记录它们。发生故障,系统恢复时,可以从非易失性RAM中读取未完成写操作的信息,并完成它们。
如果没有这种硬件支持,据需要通过其他方式,检查在故障前只有部分写入的块。
潜在故障(latent failure)或位腐(bit rot):虽然写入成功,也可能存在其他的数据损坏,如:制作缺陷或者在相邻轨道重复写入导致的数据损坏。
擦洗(scrubbing): 为了尽量减少数据丢失,好的RAID控制器会进行擦洗。即:在磁盘空闲期间,对每张磁盘的扇区进行读取,如果发现无法读取,则数据从RAID组织的其它磁盘进行恢复,并重新写入。如果物理扇区被破坏,磁盘控制器可以以将逻辑扇区地址重映射到磁盘上其他的物理扇区的地址。
热交换(Hot swapping):在不切断电源的情况下将出错的磁盘用新的磁盘进行替换。由于磁盘的替换不需要等待系统关闭这段时间,因此减少了平均恢复时间。可以通过为每张磁盘提供一张空闲磁盘,当故障发生时,可以利用空前磁盘直接替换,这样减少了数据丢失的机会,也减少了平均恢复时间。
RAID系统也需要考虑到电源、磁盘控制器或者系统互联接口 都可能发生故障。==> 备用电源
10.3.6 其他的RAID的应用
RAID的概念可以推广到其他存储设备,如:磁带阵列,无线系统上的数据广播(数据拆分+奇偶校验)
10.4 第三级存储
常用的第三级存储:磁带,光盘
10.4.1 光盘
光盘CD的存储了约为640-700M。价格便宜。
数字视频光盘DVD可以替代光盘,存储更大的数据。例如,蓝光DVD格式可以存储27-54G的数据。
CD和DVD驱动器的激光头组件更重,所以它们的寻道时间比磁盘驱动器更长,其数据传输率也低于磁盘。
可记录一次的光盘(CD-R,DVD-R,DVD+R):容量大,寿命比磁盘更长,可以再远程存储和移除,==>适用于数据的归档存储。因为不能被重写,所以可用于存储不更改的信息,如:审计追踪信息。
可多次重写的版本(CD-RW,DVD-RW,DVD+RW,DVD-RAM):也可以用于数据归档。
自动光盘机(jukebox):是存储大量的光盘的设备,可以按照需求自动将光盘装载到少量驱动器中的一个上。这样的系统的存储总量是若干个TB。机械手可以对光盘进行装载和卸载,时间是几秒级,这比光盘的访问时间要长很多。
10.4.2 磁带
磁带的速度低于磁盘和光盘,并且它只能顺序存取,不支持随机访问。
磁带主要用于备份,存储不经常使用的数据,以及作为将数据从一个系统转到另一个系统的脱机介质。
磁带相当可靠,但是磁带能可靠读写的次数有限。
磁带的容量取决于磁带的长度、宽度和读写头所能读写的密度。不同类型的磁带可存储的容量也不同,从几个G,到几百个G不等。
自动磁带机:类似于自动光盘机,可以存放大量的磁带,并有少量用于安装磁带的驱动器。存储的数据最大范围可达到若干PB,存取时间在几秒到几分钟。
磁带驱动器和磁带库的成本高,所以对于大量应用而言,备份数据到磁盘驱动器更划算。
10.5 文件组织
一个数据库被映射为多个不同的文件(file)。文件由底层的OS来维护,永久的存储在磁盘上。
一个文件在逻辑上组织成为记录的一个序列。每个文件分成定长的存储单元,称为块(block)。
块是存储分配和数据传输的基本单元,多数数据库默认使用4-8KB大小的块。当创建数据库时,可以指定块大小。
一个块可以包含多条记录。要求每条记录存储在单个块中,即:没有一条记录是部分包含在一个块中的,以加速数据访问。
关系数据库中,不同关系的元组通常具有不同的大小,记录可分为定长记录和变长记录。
10.5.1 定长记录
type instructor = record
ID varchar(5);
name varchar(20);
dept_name varchar(20);
salary numberic(8,2);
end假设每个字符占用1个字节,假设使用53个字节存储instructor记录。这种方式存在的问题:
- 如果块的大小不是53,那么可能会存在记录跨边界存储。于是,读这样的一条记录需要两次块访问。
- 解决方案:对一个块中只分配它能够完整容纳下的最大记录数。
- 从这个结构中删除一条记录很困难。删除的记录所占用的空间必须由文件的其它记录填充;或者标记该空间为忽略。
- 方法一:删除一条记录后,依次将后面的记录往前挪。
- 缺点:需要额外的块访问操作。
- 方法二:将被删除的记录的存储空间用来存储新插入的记录。这就需要标记该空间。引入如下结构:
- 在文件的开始处,分配一定数量的字节作为文件头(file header)。
- 令文件头中除了文件的相关信息外,还包括被删除的第一条记录的地址。
- 在第一条被删除的记录处,来存储第二条被删除的记录的地址。以此类推。
- ==>形成了有一个空闲列表(free list)
- 方法一:删除一条记录后,依次将后面的记录往前挪。
10.5.2 变长记录
变长记录以下面几种方式出现在数据库中:
- 多种记录类型在一个文件中存储
- 允许一个或多个字段是变长的记录类型
- 允许可重复字段的记录类型,例如数组或多重集合
实现变长记录需要解决的两个关键问题:
- 如何描述一条记录,使得单个属性可以轻松的抽取
- 在块中如何存储变长记录,使得块中的记录可以轻松的抽取
一条有变长属性的记录:定长属性+变长属性。其组成格式:
- 首先,记录初始部分:记录变长属性对应的值对(偏移量,长度)。其中偏移量为变长属性的开始位置,长度表示变长属性的字节长度。
- 接着,记录定长属性
- 最后,记录变长属性
10.6 文件中记录的组织
10.5研究了如何在文件结构中表示记录。
关系是记录的集合,接下来就是看如何在文件中组织记录。
- 堆文件组织(heap file organization): 将每个关系存储到一个单独的文件。文件中的记录是无顺序的。
- 顺序文件组织(sequential file organization): 记录根据“搜索码”的值顺序存储。
- 散列文件组织(hashing file organization): 在记录的某些属性上计算一个散列函数,散列函数的结果确定了记录应放到文件的哪个块中。
通常每个记录存储在一个文件中,但是多表聚簇文件组织(multitable clustering file organization)中,几个不同的关系的记录存储在同一个文件中。
10.6.1 顺序文件组织
顺序文件(sequential file)是为了高效处理按某个搜索码的顺序排序的记录而设计的。顺序文件组织形式使用指针按顺序连接记录。
搜索码(search key)可以使任意一个属性或属性的组合。
执行插入的过程:
- 找到待插入记录之前的一条记录。
- 如果这条记录后有空闲记录,则插入新的记录,在调整指针
- 如果这条记录之后没有空闲记录,则插入到溢出块,再调整指针
插入过程的缺点:
- 如果存储在溢出块过多,会导致搜索码的顺序和物理顺序之间的一致性丧失,此时顺序处理的效率会变得低下。
- 解决:文件重组(reorganized),使其在物理上顺序存储。
- 重组待机爱很高,应该在负载低时执行
- 重组的频率取决于新纪录插入的频率
- 解决:文件重组(reorganized),使其在物理上顺序存储。

10.6.2 多表聚簇文件组织
虽然通常一个关系存储在一个文件中,这样可以简化数据管理。
但是,将多个关系存储在一个文件中,或者在一个块中存储多个关系的记录也很有用。
多表聚簇文件组织(multitable clustering file organization)中,是一种在每个块中存储两个或者更多个关系的相关记录的文件结构。
- 例如:自然连接 select dept_name, building, budget, ID, name, salary from department natural join instructor
- 可以将instructor中具有相同dept_name的记录 存储在department中具有相同dept_name记录的附近,这样可以加快自然连接时查询块的数量。
- 缺点:对于某些查询,处理速度很慢。如:select * from department
- 解决方案:可以用指针把同一个关系的元组连接起来
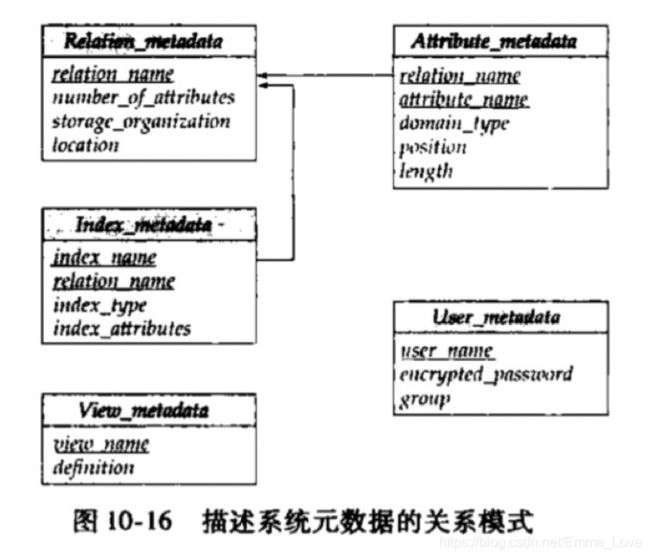
10.7 数据字典存储
元数据(meta data):数据的数据。
数据字典(data dictionary)/ 系统目录(system catalog):存储元数据的结构
系统必须存储到数据字典中的内容可以包括以下:
| 关系的名字 关系中的属性名字 属性的域和长度 视图的名字和视图的定义 完整性约束 |
授权用户的名字 关于用户的授权和账户信息 用于认证用户的密码和其他信息 |
| 记录关系的描述数据或统计数据: 每个关系中元组的数目 每个关系所使用的存储方法(聚簇或非聚簇) |
记录关系的存储组织(顺序、散列、或堆): 如果关系存储在操作系统文件中,数据字典会记录包含每个关系的文件名。 如果数据库把所有关系存储在一个文件中,数据字典可能会将每个关系中记录的块记在如链表这样的数据结构中。 |
| 记录每个关系的索引信息: 索引的名字 被索引的关系的名字 在其上定义索引的属性 构造的索引的类型 |
通常使用数据库中存储关于数据库本身的元数据:
10.8 数据库缓存区
数据库系统的主要目标之一是:减少磁盘和存储器之间传输的块数目。主存储器中保留所有的块时不可能的。
缓冲区(buffer) 是主存储器中用于存储磁盘块拷贝的那部分。每个块总有一个拷贝放在磁盘上,但是它可能比缓冲区中的拷贝旧。
缓冲区管理器(buffer manager)是负责缓冲区分配的子系统。
10.8.1 缓冲区管理器
应用程序请求块的流程:
- 应用程序向缓冲区管理器发送块请求
- 如果该块在缓冲区存在,则缓冲区管理器将这个块在主存中的地址发给请求者
- 如果该块在缓冲区不存在,则:
- 缓冲区管理器首先为该块分配空间,如果需要会把其他的块移出主存储器 (移出的块当且仅当放生改变时才被写回磁盘)
- 然后把读请求的块从磁盘读入缓冲区
- 将这个块在主存中的地址发给请求者。
缓冲区管理器必须实现的技术:
- 缓冲区替换策略(buffer replacement strategy):当缓冲区没有剩余空间时,在新块读入缓冲区之前,把旧块移出的策略。如:最近最少使用策略(Least Recently Used, LRU),即最近访问最少的块被写回磁盘,并从缓冲区中移走。
- 被钉住的块(pinned block):为了使数据库系统能够从系统崩溃中恢复,限制一个块写回磁盘的时间是十分必要的。这种不允许写回磁盘的块称为被钉住的块。例如:当块正在更新时,则不允许将该块写回磁盘。该特性对可从崩溃中恢复的数据库系统十分重要
- 块的强制写出(forced output of block): 在某些情况下,尽管不需要将一个块所占用的缓冲区空间,但是也必须把这个块强制写回磁盘,这样的写操作称为块的强制写出(forced output)。 ===> 原因:主存储器的内容,包括缓冲区的内容,在崩溃时会丢失;而磁盘上的数据一般在崩溃时可以保留。
10.8.2 缓冲区替代策略
缓冲区替代方法有:
- 最近最少使用(Least Recently Used,LRU)块替换策略:替换最近访问最少的块。最常用的方法。
- 立即丢弃(toss-immediate)策略:一个块中最后一个原则处理完毕,就命令缓冲区释放这个块所占用的空间。
- 最近最常使用策略(Most Recently Used,MRU):替换最近最常使用的块。
缓冲区管理器也可以使用对某个特定关系的访问请求做的统计信息。例如:
- 数据字典是数据库中最经常访问的部分,尽量不将它从主存中迁出。
- 索引的更新和访问会很频繁,所以一般不应该把索引块从主存中删除。
缓冲区管理在使用块替换策略时,还要考虑到其他因素的影响。如:并发处理多个用户请求,例如:保留被延迟的请求所需要的块。
崩溃-恢复子系统对块提供了更加严格的约束。
- 如果一个块修改了,不允许缓冲区管理器将这个块在缓冲区中的新内容协会磁盘,因为这会破坏旧的数据。块管理器子写回块之前,必须获得崩溃-子系统的许可。
总结
- 大多数计算机系统存在多种数据存储类型。可以根据访问数据的速度、购买介质时每单位数据的成本和介质的可靠性,对这些存储介质进行分类。可用的介质包括:告诉缓冲存储器、主存储器、快闪存储器、磁盘、光盘和磁带。
- 存储介质的可靠性由两个因素决定:电源故障或系统崩溃是否导致数据丢失,存储设备发生物理故障的可能性有多大
- 通过保留数据的多个拷贝,可以减少物理故障的可能性。对磁盘来说,可以使用镜像技术。或者可以使用更复杂的RAID(独立磁盘冗余阵列)的方法。通过把数据拆分到多张磁盘上,可以提高大数据访问的吞吐率;通过引入多张磁盘上的冗余存储,可以显著提高可靠性。有多种不同的RAID的组织形式,它们有不同的成本、性能和可靠性。最常用的是RAID1级(镜像)和RAID5级。
- 可以把一个文件逻辑上组织映射到磁盘块的一个记录序列。把数据库映射到文件的一种方法是使用多个文件,每个文件只存储固定长度的记录。另一种方法是构造文件,使之能够存储可变长度的记录。分槽的页方法广泛用于在磁盘块中处理变长记录。
- 因为数据以块为单位在磁盘存储器和主存储器之间传输,所以采取用一个单独的块包含相关联的记录的方式,将文件记录分配到不同的块中是可取的。如果我们能够仅使用一次块访问就可以存取我们想要的多个记录,就能节省磁盘访问次数。因为磁盘访问通常是数据库系统性能的瓶颈,所以设计块中记录的分配可以获得显著的性能提高。
- 数据字典,也称为系统目录。用于记录元数据,即关于数据的数据。
- 减少磁盘访问数量的一种方法是在主存储器中保留尽可能多的块。因为在主存储中保留尽可能多的块。因为在主存储器中保留所有的块是不可能的,所以需要为块的存储而管理主存储器中可用空间的分配。缓冲区是主存储器中的一部分,可以用于存储磁盘块的拷贝。负责分配缓冲区空间的子系统称为缓冲区管理器。