Spring Cloud H (二)服务注册中心 CAP理论
前言
最近在学习分布式微服务的时候,接触到了CAP理论,遂想对其进行学习,并整理成帖子,记录一下。
一、CAP理论
CAP原则又称CAP定理,指的是在一个分布式系统中, Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可得兼。换句话说,就是说在一个系统中对某个数据不存在一个算法同时满足 Consistency, Availability, Partition-tolerance。
概念
一致性:指的是强一致性。就是说在分布式系统完成某个写的操作以后,在此之后的任何读操作都应该读到的是最新的数据。即保证分布式系统中的任意节点在任意时刻都要保证数据一致。
可用性:系统提供的服务一直处于可用状态,用户的操作请求在指定的响应时间内响应请求,超出时间范围,认 为系统不可用。
分区容错性:指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。也就是说部分故障不影响整体使用。以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
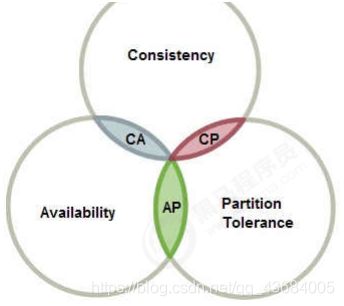
在一个分布式系统中不可能同时满足一致性、可用性、分区容错性,最多满足两个,对于分布式互联网 应用而言,必须保证P,所以要么满足AP模型、要么满足CP模型。
举例说明

如上图所示,分布式系统里面存在两个节点,假设此时G1和G2的通讯断开连接,初始数据都是v0。客户端向G1写入数据v1,由于连接断开,v1并没有更新到G2中。写完之后client再去读取这个值,这时读到了G2节点,读到的数据是修改之前的v0。此时就失去了一致性,保证了可用性。

如果系统保证了强的一致性,那么在client 写完G1节点后, 而G1向G2节点同步数据出现了问题,这时如果client再去读取G2节点的数据时,client就会一直处于等待状态,因为系统内各节点数据为同步上,需要等同步上才能使用。这就相当于满足了一致性,而失去了可用性。
应用场景
(1) CA: 优先保证一致性和可用性,放弃分区容错。这也意味着放弃系统的扩展性,系统不再是分布式的,有违设计的初衷。
(2) CP: 优先保证一致性和分区容错性,放弃可用性。在数据一致性要求比较高的场合(譬如:zookeeper,Hbase) 是比较常见的做法,一旦发生网络故障或者消息丢失,就会牺牲用户体验,等恢复之后用户才逐渐能访问。
(3) AP: 优先保证可用性和分区容错性,放弃一致性。NoSQL中的Cassandra 就是这种架构。跟CP一样,放弃一致性不是说一致性就不保证了,而是逐渐的变得一致。
二、一致性模型
一致性(Consistency)是指多副本(Replications)问题中的数据一致性。关于分布式系统的一致性模型有以下几种:
强一致性:当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值,直到这个数据被其他数据更新为止。
但是这种实现对性能影响较大,因为这意味着,只要上次的操作没有处理完,就不能让用户读取数据。
弱一致性:系统并不保证进程或者线程的访问都会返回最新更新过的值。系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。甚至不能保证可以访问到。
最终一致性:最终一致性也是弱一致性的一种,它无法保证数据更新后,所有后续的访问都能看到最新数值,而是需要一个时间,在这个时间之后可以保证这一点(就是在一段时间后,节点间的数据会最终达到一致状态),而在这个时间内,数据也许是不一致的,这个系统无法保证强一致性的时间片段被称为「不一致窗口」。不一致窗口的时间长短取决于很多因素,比如备份数据的个数、网络传输延迟速度、系统负载等。
三、分布式事务
事务
严格意义上的事务应该满足ACID,即具备原子性,一致性,隔离性和持久性。注意:这里的一致性和上面提到的CAP中的一致性并不是一个概念。
原子性:可以理解为一个事务内的所有操作要么都执行,要么都不执行。
一致性:可以理解为数据是满足完整性约束的,并不会存在中间状态的数据。比如转账过程,不会存在一个账户扣钱而另一个账户没有加钱的状态。
隔离性:多个事务并发执行的时候并不会被互相干扰,即一个事务内部的数据对于其他事务来说是隔离的。
持久性:指的是一个事务完成了一个就被永久的保存下来,之后的其他操作或者故障都不会对事务的结果产生影响。
通俗的讲,事务就是为了使一些更新操作要么都成功要么都不成功。
分布式事务
顾名思义就是要在分布式系统中实现事务,他其实是由多个本地事务组合而成。对于分布式事务而言几乎满足不了ACID,其实对于单机事务来说大部分情况下也满足不了ACID,不然怎么会有四种隔离级别呢?(数据库事务和四种隔离级别日后会写)更不用说分布在不同数据库或者不同应用上的分布式事务了。
2PC(二阶段提交)
二阶段提交是一种强一致性设计,它引入了一个事务协调者的决策来管理各个参与者的提交和回滚,二阶段分别指的是准备和提交两个阶段。
2PC是一个同步阻塞协议,像第一阶段协调者会等待所有参与者响应才会进行下一步操作,当然第一阶段的协调者有超时机制,假设因为网络原因没有收到某参与者的响应或某参与者挂了,那么超时后就会判断事务失败,向所有参与者发送回滚命令。
准备阶段:协调者给各个参与者发送准备命令,意味提交的准备工作已经完成,准备提交。在同步等待所有资源响应以后进入提交阶段(发生错误则会回滚)。
假如在第一阶段的所有参与者都返回准备成功,那么协调者则向所有参与者发送提交事务命令,等待所有的事务都提交成功,则事务执行成功。
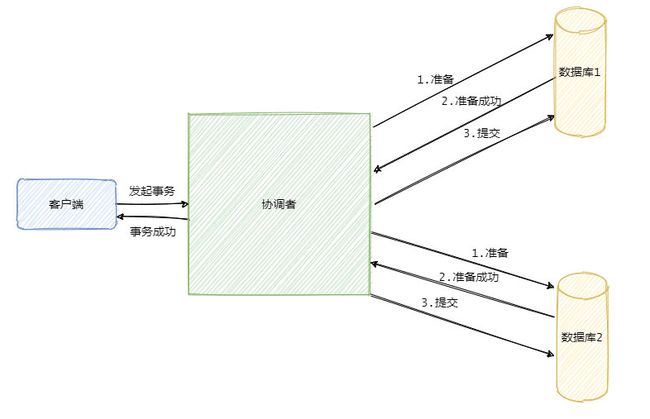
如果在第一阶段有参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即提交失败。

如果在第二阶段发生错误了呢?
第一种是第二阶段执行的是回滚事务操作,那么答案是不断重试,直到所有参与者都回滚了,不然那些在第一阶段准备成功的参与者会一直阻塞着。
第二种是第二阶段执行的是提交事务操作,那么答案也是不断重试,因为有可能一些参与者的事务已经提交成功了,这个时候只有一条路,就是头铁往前冲,不断的重试,直到提交成功,到最后真的不行只能人工介入处理。
协调者单点故障分析:
(1)在准备命令发送之前挂掉,事务还没开始,无事发生。
(2)在准备命令发送以后挂掉,参与者都执行了事务资源锁定状态。不但事务执行不下去了,而且还会因为锁定了一些公共资源而导致阻塞了系统的其他操作。
(3)在发送回滚命令之前挂掉,事务执行不下去,并且在第一阶段那些准备成功的参与者都将会阻塞。
(4)在发送回滚命令之后挂掉,很大概率回滚成功,资源会被释放。但是如果因为网络分区的问题,某些参与者会收不到命令而一直阻塞。
(5)在发送提交命令之前挂掉,所有资源全部阻塞。
(6)在发送提交命令之后挂掉,命令发出大概率提交成功,释放资源。但是也可能会因为网络分区等原因某些参与者因为收不到命令而阻塞。
协调者故障后选举
因为协调者单点问题,因此我们可以通过选举等操作选出一个新协调者来顶替。
如果处于第一阶段,其实影响不大都回滚好了,在第一阶段事务肯定还没提交。如果处于第二阶段,假设参与者都没挂,此时新协调者可以向所有参与者确认它们自身情况来推断下一步的操作。
假设有个别参与者挂了!这就有点僵硬了,比如协调者发送了回滚命令,此时第一个参与者收到了并执行,然后协调者和第一个参与者都挂了。此时其他参与者都没收到请求,然后新协调者来了,它询问其他参与者都说OK,但它不知道挂了的那个参与者到底O不OK,所以它傻了。问题其实就出在每个参与者自身的状态只有自己和协调者知道,因此新协调者无法通过在场的参与者的状态推断出挂了的参与者是什么情况。
虽然协议上没说,不过在实现的时候我们可以灵活的让协调者将自己发过的请求在哪个地方记一下,也就是日志记录,这样新协调者来的时候不就知道此时该不该发了?
但是就算协调者知道自己该发提交请求,那么在参与者也一起挂了的情况下没用,因为你不知道参与者在挂之前有没有提交事务。如果参与者在挂之前事务提交成功,新协调者确定存活着的参与者都没问题,那肯定得向其他参与者发送提交事务命令才能保证数据一致。如果参与者在挂之前事务还未提交成功,参与者恢复了之后数据是回滚的,此时协调者必须是向其他参与者发送回滚事务命令才能保持事务的一致。
所以说极端情况下还是无法避免数据不一致问题。
3PC
3PC在参与者中也引入了超时机制,并增加一个阶段,使得参与者能够利用这个阶段同一各自状态。
3PC的三个阶段:准备阶段,预提交阶段和提交阶段
准备阶段:询问参与者是否准备好开始事务。
预提交阶段:和2PC的准备阶段相同,准备好提交前的事情
提交阶段:同2PC
不管哪一个阶段有参与者返回失败都会宣布事务失败,这和 2PC 是一样的(当然到最后的提交阶段和 2PC 一样只要是提交请求就只能不断重试)
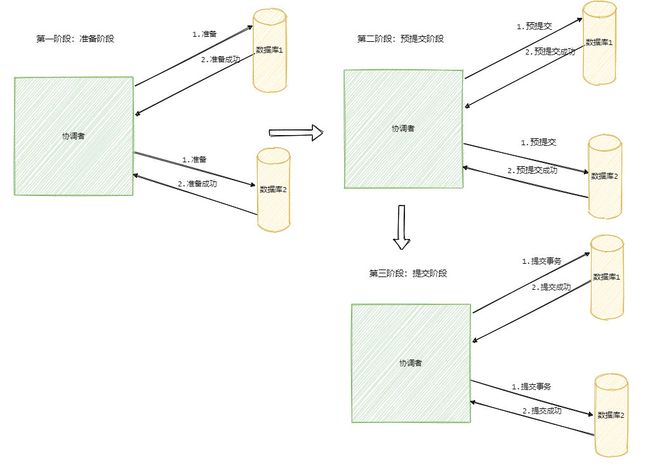
3PC的变更和2PC的对比
(1)准备阶段:准备阶段变成不直接执行事务,而是询问此时的参与者是否有调节接手这个事务。即不会上来就直接锁资源,使得在某些资源不可用的情况下,所有的参与者都阻塞。
(2)预提交阶段:当进入预提交阶段时就代表着所有的参与者都进行了准备阶段的回应。假如你是一位参与者,你知道自己进入了预提交状态那你就可以推断出来其他参与者也都进入了预提交状态。但是多引入一个阶段也多一个交互,因此性能会差一些,而且绝大部分的情况下资源应该都是可用的,这样等于每次明知可用执行还得询问一次。
(3)提交阶段:和2PC相同,失败了就要无限重试。
引入的参与者超时机制
引入了超时机制,参与者就不会傻等了,如果是等待提交命令超时,那么参与者就会提交事务了,因为都到了这一阶段了大概率是提交的,如果是等待预提交命令超时,那该干啥就干啥了,反正本来啥也没干。
然而超时机制也会带来数据不一致的问题,比如在等待提交命令时候超时了,参与者默认执行的是提交事务操作,但是有可能执行的是回滚操作,由于有发生错误的参与者,这样一来数据就不一致了。
3PC 的引入是为了解决提交阶段 2PC 协调者和某参与者都挂了之后新选举的协调者不知道当前应该提交还是回滚的问题。
新协调者来的时候发现有一个参与者处于预提交或者提交阶段,那么表明已经经过了所有参与者的确认了,所以此时执行的就是提交命令。
所以说 3PC 就是通过引入预提交阶段来使得参与者之间的状态得到统一,也就是留了一个阶段让大家同步一下。
但是这也只能让协调者知道该如果做,但不能保证这样做一定对,这其实和上面 2PC 分析一致,因为挂了的参与者到底有没有执行事务无法断定。
所以说 3PC 通过预提交阶段可以减少故障恢复时候的复杂性,但是不能保证数据一致,除非挂了的那个参与者恢复。
TCC 本地事务表 消息事务 最大努力通知见参考吧
参考
https://blog.csdn.net/qq_35190492/article/details/108000380