Alert Log中“Fatal NI connect error 12170”错误
Alert Log中“Fatal NI connect error 12170”错误
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.4.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
Time: 08-MAY-2017 10:24:32
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 110
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.176.172.44)(PORT=55353))
[oracle11g@localhost admin]$ oerr ora 12170
12170, 00000, "TNS:Connect timeout occurred"
// *Cause: The server shut down because connection establishment or
// communication with a client failed to complete within the allotted time
// interval. This may be a result of network or system delays; or this may
// indicate that a malicious client is trying to cause a Denial of Service
// attack on the server.
// *Action: If the error occurred because of a slow network or system,
// reconfigure one or all of the parameters SQLNET.INBOUND_CONNECT_TIMEOUT,
// SQLNET.SEND_TIMEOUT, SQLNET.RECV_TIMEOUT in sqlnet.ora to larger values.
// If a malicious client is suspected, use the address in sqlnet.log to
// identify the source and restrict access. Note that logged addresses may
// not be reliable as they can be forged (e.g. in TCP/IP).
[oracle11g@localhost admin]$
解决方法:
listener.ora
INBOUND_CONNECT_TIMEOUT_LISTENER = 0
DIAG_ADR_ENABLED_LISTENER = OFF
sqlnet.ora
DIAG_ADR_ENABLED = OFF
SQLNET.INBOUND_CONNECT_TIMEOUT =0
之后,重新reload监听器配置,或者重启监听器。
定期检查数据库alert log信息,是我们进行数据库日常维护、巡检和故障排除的重要工作手段。数据库系统“带病运行”、“负伤运行”往往是“小病致死”的主要杀手。所谓“防患于未然”就需要数据库管理员从日常的小事微情入手,时刻了解系统运行情况,并尽早进行处理。
本文主要介绍笔者使用Oracle 11gR2过程中日志巡检中出现的问题,虽然最后没有得到圆满解决。记录下来,留待需要朋友待查。
1、问题说明
笔者使用的一套开发环境,数据库版本是11gR2,小版本号为11.2.0.4。
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit Production
PL/SQL Release 11.2.0.4.0 - Production
CORE 11.2.0.4.0 Production
TNS for Linux: Version 11.2.0.4.0 - Production
NLSRTL Version 11.2.0.4.0 – Production
在巡检数据库alert log过程中,发现一些错误提示。
Tue May 19 23:04:55 2015
*************************************
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.4.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.4.0 - Production
Time: 19-MAY-2015 23:04:55
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 110
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=172.xx.xx.xx)(PORT=50741))
相同类型错误在日志中反复出现,每天出现频率在10条左右,区别在于每次的Host对应IP地址不同。
2、问题分析
这类型错误在11gR2版本中经常出现。笔者之前的一些投产系统中,也常常出现这样的问题。当前进行开发的系统架构比较传统,是一个典型CS架构方式。客户端桌面应用是一个富客户端软件,所有业务逻辑都在客户端。客户端直接连接数据库。
这种架构方式是比较传统的方式,行业内对于这种方式的缺陷已经讨论很多年了。单从数据库角度看,这样的架构方式意味着更加多的数据库连接数量和更加频繁的访问结构。
利用IP地址,我们可以从监听器日志listener.log中,可以定位到这个IP地址连接是什么时候连接过来的。
[oracle@localhost trace]$ pwd
/u01/app/diag/tnslsnr/localhost/listener/trace
[oracle@localhost trace]$ cat listener.log | grep 172. xx.xx.xx
19-MAY-2015 13:51:10 * (CONNECT_DATA=(CID=(PROGRAM=JDBC Thin Client)(HOST=__jdbc__)(USER=visvim))(SERVICE_NAME=sicsdb)) * (ADDRESS=(PROTOCOL=tcp)(HOST=172.xx.xx.xx)(PORT=50741)) * establish * sicsdb * 0
从MOS上的信息反馈看,这个类型错误提示是一种正常的Oracle工作机制。当客户端进程Client Process与服务器进程Server Process建立联系之后,两者就形成了“同生共死”的关系(专有连接模式)。除非客户端主动发起中断或者Server Process被异常kill。
在实际运行环境中,这种理想状态常常被打破。如果Client Process只是保持连接,不执行语句,会话就处于idle状态。这种连接很容易被诸如防火墙等网络层面设备切断。
在Oracle11gR2中,如果长期没有连接动作的Server Process被外力切断,Oracle就会自动将信息作为提示错误写入到alert log中,作为一种提示。在11R1版本中,这种信息是会写入到sqlnet.log中。
3、问题解决措施
归纳MOS和网络中的各种方法,大体有两重策略,分别为使用DCD和禁用ADR。
DCD全称Dead Connection Detection,是一种基于主动测探方式检查Oracle僵尸客户端进程Client Process的策略。配置DCD的关键是设置sqlnet.expire_time参数在SQL Net体系下,Oracle会依据这个时间间隔给所有的Client Process发送网络通信包,用来确定Client是否存活。
正是借助这个包通信,可以让防火墙认为这个网络连接还是处在active状态,不会进行强制断开动作。类似的机制还有Linux上的tcp keep live机制,也是使用类似的策略进行检查。
[oracle@localhost trace]$ cd /u01/app/oracle/network/admin/
[oracle@localhost admin]$ ls -l
total 16
-rw-r--r--. 1 oracle oinstall 343 Sep 2 2014 listener.ora
drwxr-xr-x. 2 oracle oinstall 4096 Jun 16 2014 samples
-rw-r--r--. 1 oracle oinstall 381 Dec 17 2012 shrept.lst
-rw-r--r--. 1 oracle oinstall 0 Sep 2 2014 sqlnet.ora
-rw-r-----. 1 oracle oinstall 308 Sep 5 2014 tnsnames.ora
[oracle@localhost admin]$ cat sqlnet.ora
[oracle@localhost admin]$ cat sqlnet.ora
sqlnet.expire_time=10
另一种方式也是Oracle推荐的,就是关闭11g的ADR机制。ADR(Automatic Diagnostic Repository)是Oracle进行自动诊断、自动提醒的工具组件。Oracle认为如果用户不需要在SQL Net组件中应用ADR,可以再sqlnet.ora中进行配置关闭。
[oracle@localhost admin]$ cat sqlnet.ora
sqlnet.expire_time=10
DIAG_ADR_ENABLED = OFF
DIAG_ADR_ENABLED_LISTENER=OFF
之后,重新reload监听器配置,或者重启监听器。
[oracle@localhost admin]$ lsnrctl reload
LSNRCTL for Linux: Version 11.2.0.4.0 - Production on 21-MAY-2015 10:13:34
Copyright (c) 1991, 2013, Oracle. All rights reserved.
Connecting to (DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=localhost)(PORT=1521)))
4、结论
数据库“Fatal NI connect error 12170”问题,从本质上是由于长连接数据库交互方式造成的,严格意义上不应算什么错误问题。如果是一些三层架构体系应用,可以考虑使用连接池进行动态资源调配的方式,对问题进行缓解。
深蓝的blog:http://blog.csdn.net/huangyanlong/article/details/46372849
查看数据库告警日志,发现错误:Fatal NI connect error 12170报错
告警日志如下:
***********************************************************************
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.1.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.1.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.1.0 - Production
Time: 26-OCT-2014 06:05:44
Tracing not turned on.
Tns error struct:
ns main err code: 12535
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.1.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.1.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.1.0 - Production
Time: 26-OCT-2014 06:05:44
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12606
nt main err code: 0
nt secondary err code: 0
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.53.105.20)(PORT=19164))
VERSION INFORMATION:
TNS for Linux: Version 11.2.0.1.0 - Production
Oracle Bequeath NT Protocol Adapter for Linux: Version 11.2.0.1.0 - Production
TCP/IP NT Protocol Adapter for Linux: Version 11.2.0.1.0 - Production
Time: 26-OCT-2014 06:05:44
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12606
nt main err code: 0
nt secondary err code: 0
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.53.105.20)(PORT=19166))
TNS-12535: TNS:operation timed out
ns secondary err code: 12606
nt main err code: 0
nt secondary err code: 0
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.53.105.20)(PORT=19165))
Sun Oct 26 06:05:50 2014
Successfully onlined Undo Tablespace 2.
Verifying file header compatibility for 11g tablespace encryption..
Verifying 11g file header compatibility for tablespace encryption completed
***********************************************************************
【解决方式】
[oracle@node1 ~]$ lsnrctl status
LSNRCTL for Linux: Version 11.2.0.1.0 - Production on 02-MAR-2015 12:34:22
Copyright (c) 1991, 2009, Oracle. All rights reserved.
Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521))
STATUS of the LISTENER
------------------------
Alias LISTENER
Version TNSLSNR for Linux: Version 11.2.0.1.0 - Production
Start Date 02-MAR-2015 09:45:49
Uptime 0 days 2 hr. 48 min. 33 sec
Trace Level off
Security ON: Local OS Authentication
SNMP OFF
Listener Parameter File /u01/11.2.0/grid/network/admin/listener.ora
Listener Log File /u01/app/oracle/diag/tnslsnr/node1/listener/alert/log.xml
Listening Endpoints Summary...
(DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=LISTENER)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.53.105.20)(PORT=1521)))
(DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=10.53.105.24)(PORT=1521)))
Services Summary...
Service "+ASM" has 1 instance(s).
Instance "+ASM1", status READY, has 1 handler(s) for this service...
Service "xcky" has 1 instance(s).
Instance "xcky1", status READY, has 1 handler(s) for this service...
Service "xckyXDB" has 1 instance(s).
Instance "xcky1", status READY, has 1 handler(s) for this service...
The command completed successfully
[oracle@node1 ~]$ cd /u01/11.2.0/grid/network/admin/
[oracle@node1 admin]$ ls
endpoints_listener.ora listener.ora samples sqlnet.ora
listener1410255PM1539.bak listener.ora.bak.node1 shrept.lst
[root@node1 admin]# chmod 775 listener.ora
[root@node1 admin]# chmod 775 sqlnet.ora
--确认oracle用户对配置文件的访问权限
[oracle@node1 admin]$ vi listener.ora
--添加参数INBOUND_CONNECT_TIMEOUT_LISTENER = 0
--添加参数DIAG_ADR_ENABLED_LISTENER = OFF
LISTENER=(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER)))) # line added by Agent
LISTENER_SCAN1=(DESCRIPTION=(ADDRESS_LIST=(ADDRESS=(PROTOCOL=IPC)(KEY=LISTENER_SCAN1)))) # line added by Agent
ENABLE_GLOBAL_DYNAMIC_ENDPOINT_LISTENER_SCAN1=ON # line added by Agent
ENABLE_GLOBAL_DYNAMIC_ENDPOINT_LISTENER=ON # line added by Agent
INBOUND_CONNECT_TIMEOUT_LISTENER = 0
DIAG_ADR_ENABLED_LISTENER = OFF
~
~
[oracle@node1 admin]$ vi sqlnet.ora
--添加参数DIAG_ADR_ENABLED = OFF
--添加参数SQLNET.INBOUND_CONNECT_TIMEOUT =0
# sqlnet.ora.node1 Network Configuration File: /u01/11.2.0/grid/network/admin/sqlnet.ora.node1
# Generated by Oracle configuration tools.
NAMES.DIRECTORY_PATH= (TNSNAMES, EZCONNECT)
ADR_BASE = /u01/app/oracle
DIAG_ADR_ENABLED = OFF
SQLNET.INBOUND_CONNECT_TIMEOUT =0
~
~
【官方文档】
来看一下官方文档中的说明,如下:
ORA-12170: TNS:Connect timeout occurred
Cause: The client failed to establish a connection and complete authentication in the time specified by the SQLNET.INBOUND_CONNECT_TIMEOUT parameter in the sqlnet.ora file. This error may be a result of network or system delays, or it may indicate that a malicious client is trying to cause a denial-of-service attack on the database server.
See Also:
"Configuring the Listener and the Oracle Database To Limit Resource Consumption By Unauthorized Users" further information about setting the SQLNET.INBOUND_CONNECT_TIMEOUT parameter
Action: If the error occurred due to system or network delays that are normal for the particular environment, then perform these steps:
Turn on tracing to determine where clients are timing out.
See Also:
"Tracing Error Information for Oracle Net Services"
Reconfigure the SQLNET.INBOUND_CONNECT_TIMEOUT parameter in sqlnet.ora to a larger value.
If you suspect a malicious client, then perform these steps:
Locate the IP address of the client in the sqlnet.log file on the database server to identify the source.
For example, the following sqlnet.log excerpt shows a client IP address of 10.10.150.35.
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for Solaris: Version 10.1.0.2.0
Oracle Bequeath NT Protocol Adapter for Solaris: Version 10.1.0.2.0
TCP/IP NT Protocol Adapter for Solaris: Version 10.1.0.2.0
Time: 03-JUL-2002 13:51:12
Tracing to file: /ora/trace/svr_13279.trc
Tns error struct:
nr err code: 0
ns main err code: 12637
TNS-12637: Packet receive failed
ns secondary err code: 12604
nt main err code: 0
nt secondary err code: 0
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.10.150.35)(PORT=52996))
Beware that an IP address can be forged.
If the time out occurs before the IP address can be retrieved by the database server, then enable listener tracing to determine the client that made the request.
See Also:
Tracing Error Information for Oracle Net Services
Restrict access to the client. For example, you can configure parameters for access rights in the sqlnet.ora file.
See Also:
"Configuring Database Access Control"
【过程梳理】
上面是10G的官方文档内容,可以看到官方文档,给出了一个建议:Reconfigure the SQLNET.INBOUND_CONNECT_TIMEOUT parameter in sqlnet.ora to a larger value.
再找找官方文档对于SQLNET.INBOUND_CONNECT_TIMEOUT的说明,如下图:
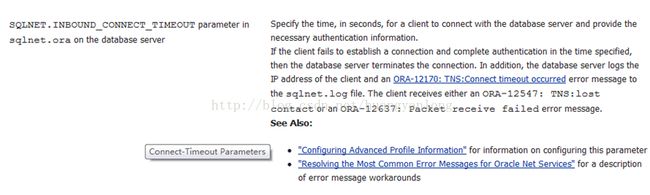

如上,这个问题的出现是由于数据库连接没能成功完成,在连接结果来看出现了延迟造成的。在官方文档中并没有找到明确的处理方式,只是一些配置建议。
后续在网上搜了搜同类的错误处理方式(有资料说这个错误可以再MOS文档中找到),再结合官方文档,初步了解到对于ORA-12170错误,由于在Automatic Diagnostic Repository中的 Oracle Net diagnostic是开启状态,从而对连接延迟错误进行获取并且将其写入告警日志。
网友贴出来的MOS文档参考,如下:
To revert to Oracle Net Server tracing/logging, set following parameter in the server's sqlnet.ora :
DIAG_ADR_ENABLED = OFF
Also, to back out the ADR diag for the Listener component, set following parameter in the server's listener.ora:
DIAG_ADR_ENABLED_
- Where the
DIAG_ADR_ENABLED_LISTENER = OFF
-Reload or restart the TNS Listener for the parameter change to take effect.
网友贴出的Metalink上给出的解决方案
1. set INBOUND_CONNECT_TIMEOUT_=0 in listener.ora
2. set SQLNET.INBOUND_CONNECT_TIMEOUT = 0 in sqlnet.ora of server.
3. stop and start both listener and database.
4. Now try to connect to DB and observe the behaviour
Fatal NI Connect Error 12170, 'TNS-12535: TNS:operation timed out' Reported in 11g Alert Log (文档 ID 1286376.1)
In this Document
| Symptoms |
| Changes |
| Cause |
| Solution |
| References |
APPLIES TO:
Oracle Net Services - Version 11.1.0.6 to 12.1.0.2 [Release 11.1 to 12.1]Information in this document applies to any platform.
TNS-12170, ORA-12170, TNS-12535, TNS-00505 alert.log
SYMPTOMS
nt secondary err code: 110 Monitoring of the 11g database Alert log(s) may show frequent timeout related messages such as:
- On Oracle Solaris:
***********************************************************************
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for Solaris: Version 11.2.0.1.0 - Production
Oracle Bequeath NT Protocol Adapter for Solaris: Version 11.2.0.1.0 - Production
TCP/IP NT Protocol Adapter for Solaris: Version 11.2.0.1.0 - Production
Time: 22-JAN-2011 21:48:23
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 145
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.xxx.yy.117)(PORT=1092))
---------
The "nt secondary err code" will be different based on the operating system.
Linux x86 or Linux x86-64: "nt secondary err code: 110"
HP-UX Server: "nt secondary err code: 238"
AIX: "nt secondary err code: 78"
CHANGES
No changes are necessary, but may have recently upgraded the database to 11g release 1 or higher, or installed a new Oracle11g database.
Note: Prior to 11gR1 these same 'Fatal NI connect error 12170' are written to the sqlnet.log
CAUSE
These time out related messages are mostly informational in nature. The messages indicate the specified client connection (identified by the 'Client address:' details) has experienced a time out. The 'nt secondary err code' identifies the underlying network transport, such as (TCP/IP) timeout limits after a client has abnormally terminated the database connection.
The 'nt secondary err code' translates to underlying network transport timeouts for the following Operating Systems:
For the Solaris system: nt secondary err code: 145:
ETIMEDOUT 145 /* Connection timed out */
For the Linux operating system: nt secondary err code: 110
ETIMEDOUT 110 Connection timed out
For the HP-UX system: nt secondary err code: 238:
ETIMEDOUT 238 /* Connection timed out */
For AIX: nt secondary err code: 78:
ETIMEDOUT 78 /* Connection timed out */
For Windows based platforms: nt secondary err code: 60 (which translates to Winsock Error: 10060)
Description: A connection attempt failed because the connected party did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
The reason the messages are written to the alert log is related to the use of the new 11g Automatic Diagnostic Repository (ADR) feature being enabled by default. See (Doc ID 454927.1).
SOLUTION
Suggested Actions:
- Search the corresponding text version of the listener log located on the database server for the corresponding client connection referenced by the Client address details referenced in the alert log message.
For the message incident below you would search the listener log for the 'Client address' string:
(ADDRESS=(PROTOCOL=tcp)(HOST=10.xxx.yy.117)(PORT=1092))
The search of the listener log should find the most recent connection before the time reference displayed in the alert log message, e.g. '22-JAN-2011 21:48:23'.
-Corresponding listener log entry:
22-JAN-2011 21:20:12 * (CONNECT_DATA=(SERVER=DEDICATED)(SERVICE_NAME=AMN11264.us.oracle.com)(CID=(PROGRAM=D:\app\mcassady\product\11.2.0\dbhome_1\bin\sqlplus.exe)(HOST=mcassady-lap)(USER=mca
ssady))) * (ADDRESS=(PROTOCOL=tcp)(HOST=10.xxx.yy.117)(PORT=1092)) * establish * AMN11264.us.oracle.com * 0
- Alert log entry:
------------
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for Solaris: Version 11.2.0.1.0 - Production
Oracle Bequeath NT Protocol Adapter for Solaris: Version 11.2.0.1.0 - Production
TCP/IP NT Protocol Adapter for Solaris: Version 11.2.0.1.0 - Production
Time: 22-JAN-2011 21:48:23
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 145
nt OS err code: 0
Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=10.xxx.yy.117)(PORT=1092))
------------
Note the time of the client corresponding client connection(s) in the listener log. Here you may find a particular client, set of clients or particular applications that are improperly disconnecting causing the timeout errors to be raised and recorder in the database alert log.
See the following for more information and a potential solution where a firewall may be causing this issue: Note:1628949.1 Alert Log Errors: 12170 TNS-12535/TNS-00505: Operation Timed Out
You may choose to revert from the new Automatic Diagnostic Repository (ADR) method to prevent the Oracle Net diagnostic details from being written to the alert log(s) by setting the following Oracle Net configuration parameters:
To revert to Oracle Net Server tracing/logging, set following parameter in the server's sqlnet.ora :
DIAG_ADR_ENABLED = OFF
Also, to back out the ADR diag for the Listener component, set following parameter in the server's listener.ora:
DIAG_ADR_ENABLED_
- Where the
DIAG_ADR_ENABLED_LISTENER = OFF
-Reload or restart the TNS Listener for the parameter change to take effect.
REFERENCES
NOTE:151972.1 - Dead Connection Detection (DCD) ExplainedNOTE:454927.1 - Using and Disabling the Automatic Diagnostic Repository (ADR) with Oracle Net for 11g
NOTE:1628949.1 - Alert Log Errors: 12170 TNS-12535/TNS-00505: Operation Timed Out
Alert Log Errors: 12170 TNS-12535/TNS-00505: Operation Timed Out (文档 ID 1628949.1)
In this Document
| Symptoms |
| Changes |
| Cause |
| Solution |
| References |
APPLIES TO:
Oracle Net Services - Version 11.2.0.3 to 12.1.0.2 [Release 11.2 to 12.1]Oracle Database - Standard Edition - Version 11.2.0.3 to 11.2.0.3 [Release 11.2]
Information in this document applies to any platform.
SYMPTOMS
The following error is reported in the database alert log.
***Note the "Client address" is posted within the error stack in this case.
Fatal NI connect error 12170.
VERSION INFORMATION:
TNS for 64-bit Windows: Version 11.2.0.3.0 - Production
Oracle Bequeath NT Protocol Adapter for 64-bit Windows: Version 11.2.0.3.0 - Production
Windows NT TCP/IP NT Protocol Adapter for 64-bit Windows: Version 11.2.0.3.0 - Production
Time: 22-FEB-2014 12:45:09
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 60
nt OS err code: 0
***Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=121.23.142.141)(PORT=45679))
This does not correspond to the listener port.
CHANGES
No changes are necessary, but may have recently upgraded the database to 11g release 1 or higher, or installed a new Oracle11g database and they are now visible in the alert log.
Note: Prior to 11gR1 these same 'Fatal NI connect error 12170' are written to the sqlnet.log. This document describes a problem that arises when a firewall exists between the client and the database server.
CAUSE
We can search the listener log covering the same time period using this search criteria.
(HOST=121.23.142.141)(PORT=45679)
The 11g listener log in text format is located here:
$ORACLE_BASE/diag/tnslsnr/
Again, this is the client's IP address and the unique ephemeral port assigned to the client for this connection.
In this case, we find that this connection was established at the listener at this timestamp:
22-FEB-2014 10:42:10 * (CONNECT_DATA=(SID=test)(CID=(PROGRAM=)(HOST=__jdbc__)(USER=))) * (ADDRESS=(PROTOCOL=tcp)(HOST=121.23.142.141)(PORT=45679)) * establish * test* 0 .
Compare this to the event in the alert.log with special attention to the timestamp.
The connection was dropped by the instance at 22-FEB-2014 12:45:09 or roughly 2 hours later.
Time: 22-FEB-2014 12:45:09
Tracing not turned on.
Tns error struct:
ns main err code: 12535
TNS-12535: TNS:operation timed out
ns secondary err code: 12560
nt main err code: 505
TNS-00505: Operation timed out
nt secondary err code: 60
nt OS err code: 0
***Client address: (ADDRESS=(PROTOCOL=tcp)(HOST=121.23.142.141)(PORT=45679))
The 'nt secondary err code' identifies the underlying network transport, such as (TCP/IP) timeout limit. In the current case 60 identifies Windows underlying transport layer.
The "nt secondary err code" will be different based on the operating system:
Linux x86 or Linux x86-64: "nt secondary err code: 110"
HP-UX : "nt secondary err code: 238"
AIX: "nt secondary err code: 78"
Solaris: "nt secondary err code: 145"
The alert.log message indicates that a connection was terminated AFTER it was established to the instance. In this case, it was terminated 2 hours and 3 minutes after the listener handed the connection to the database.
This would indicate an issue with a firewall where a maximum idle time setting is in place.
The connection would not necessarily be "idle". This issue can arise during a long running query or when using JDBC Thin connection pooling. If there is no data 'on the wire' for lengthy
periods of time for any reason, the firewall might terminate the connection.
SOLUTION
The non-Oracle solution would be to remove or increase the firewall setting for maximum idle time. In cases where this is not feasible, Oracle offers the following suggestion:
The following parameter, set at the **RDBMS_HOME/network/admin/sqlnet.ora, can resolve this kind of problem. DCD or SQLNET.EXPIRE_TIME can mimic data transmission between the server and the client during long periods of idle time.
SQLNET.EXPIRE_TIME=n Where
Once this change is in place, there is NO need to restart the listener or the database. The change will be in place for all newly spawned server processes following the change.
Be aware that connections that were established prior to this setting would not be affected by this change. Therefore, you may continue to experience some timeouts until all remote connection are established with this setting in place.
See the following : Note 257650.1 Resolving Problems with Connection Idle Timeout With Firewall
**In an installation that includes GRID, this parameter should be set in the RDBMS_HOME/network/admin/sqlnet.ora file. This would be the default location for sqlnet.ora file parameters referenced by the instance.
Please consider your business requirement for allowing connections to remain or appear 'idle' before implementing these suggestions and note that this is a workaround which, on some occasions, may not overpass all the network timeouts.
REFERENCES
NOTE:257650.1 - Resolving Problems with Connection Idle Timeout With FirewallNOTE:1286376.1 - Fatal NI Connect Error 12170, 'TNS-12535: TNS:operation timed out' Reported in 11g Alert Log
Dead Connection Detection (DCD) Explained (文档 ID 151972.1)
***Checked for relevance on 08-APR-2016***
DEAD CONNECTION DETECTION
=========================
OVERVIEW
--------
Dead Connection Detection (DCD) is a feature of SQL*Net 2.1 and later, including
Oracle Net8 and Oracle NET. DCD detects when a partner in a SQL*Net V2 client/server
or server/server connection has terminated unexpectedly, and flags the dead session
so PMON can release the resources associated with it.
DCD is intended primarily for environments in which clients power down their
systems without disconnecting from their Oracle sessions, a problem
characteristic of networks with PC clients.
DCD is initiated on the server when a connection is established. At this
time SQL*Net reads the SQL*Net parameter files and sets a timer to generate an
alarm. The timer interval is set by providing a non-zero value in minutes for
the SQLNET.EXPIRE_TIME parameter in the sqlnet.ora file.
When the timer expires, SQL*Net on the server sends a "probe" packet to the
client. (In the case of a database link, the destination of the link
constitutes the server side of the connection.) The probe is essentially an
empty SQL*Net packet and does not represent any form of SQL*Net level data,
but it creates data traffic on the underlying protocol.
If the client end of the connection is still active, the probe is discarded,
and the timer mechanism is reset. If the client has terminated abnormally,
the server will receive an error from the send call issued for the probe, and
SQL*Net on the server will signal the operating system to release the
connection's resources.
On Unix servers, the sqlnet.ora file must be in either $TNS_ADMIN or
$ORACLE_HOME/network/admin. Neither /etc nor /var/opt/oracle alone is valid.
It should be also be noted that in SQL*Net 2.1.x, an active orphan process
(one processing a query, for example) will not be killed until the query
completes. In SQL*Net 2.2, orphaned resources will be released regardless of
activity.
This is a server feature only. The client may be running any supported
SQL*Net V2 release.
THE FUNCTION OF THE PROTOCOL STACK
----------------------------------
While Dead Connection Detection is set at the SQL*Net level, it relies heavily
on the underlying protocol stack for it's successful execution. For example,
you might set SQLNET.EXPIRE_TIME=1 in the sqlnet.ora file, but it is unlikely
that an orphaned server process will be cleaned up immediately upon expiration
of that interval.
TCP/IP, for example, is a connection-oriented protocol, and as such, the
protocol will implement some level of packet timeout and retransmission in an
effort to guarantee the safe and sequenced order of data packets. If a timely
acknowledgement is not received in response to the probe packet, the TCP/IP
stack will retransmit the packet some number of times before timing out. After
TCP/IP gives up, then SQL*Net receives notification that the probe failed.
The time that it takes TCP/IP to timeout is dependent on the TCP/IP stack, and
timeouts of many minutes are entirely common. This has been an area of concern
for many customers, as many retransmissions at the protocol layer causes what
could be a significant lag between the expiration of the DCD interval and the
time when the orphaned process is actually killed.
The easiest way to determine if the protocol stack is causing such a delay
involves testing different DCD intervals.
TESTING THE PROTOCOL STACK
--------------------------
Set the SQLNET.EXPIRE_TIME parameter to 1 minute and note the time required to
clean up an orphaned server process. Then set SQLNET.EXPIRE_TIME to 5 minutes
and again observe the time required to clean up the shadow. If the TCP/IP
timeout is the reason the server resources do not get released, the time to
clean up the shadow should increase by about 4 minutes.
If the TCP/IP retransmission timeout is indeed the problem, the Operating
System kernel can be tuned to reduce the interval for and number of packet
retransmissions (on many Unix platforms, the file
/usr/include/netinet/tcp_timer.h contains the configuration parameters).
Reducing the interval and number of retransmissions may impact other system
components, since in effect you are shrinking the window allowed for
connections to process data, possibly resulting in inadvertent loss of
connections during periods of heavy system load. Slower connections from
remote sites may be impacted by this change.
Kernel parameters that may affect retransmission include but are not limited
to TCP_TTL, TCPTV_PERSMIN, TCPTV_MAX, and TCP_LINGERTIME.
*** To avoid disrupting other system processes, it is important to contact the
appropriate vendor for assistance in tuning the operating system kernel or
protocol stack. ***
MONITORING DEAD CONNECTION DETECTION
------------------------------------
The best way to determine if DCD is enabled and functioning properly is to
generate a server trace and search the file for the DCD probe packet. To
generate a server trace, set TRACE_LEVEL_SERVER=16 and
TRACE_DIRECTORY_SERVER= in sqlnet.ora on the server (note the location
of the sqlnet.ora file). The resulting trace file will have a filename of
svr_.trc and will be located in the specified directory.
Is DCD Enabled?
---------------
For pre-Oracle8i versions, enable level 16 SQL*Net server tracing and search
the resultant server trace file for an entry like the following:
osntns: Enabling dead connection detection (1 min)
The timer interval listed should match the value of SQLNET.EXPIRE_TIME.
For Oracle8i onwards, you should see the following:
nstimini: entry
nstimig: entry
nstimig: normal exit
nstimini: initializing NLTM in asynchronous mode
nstimini: normal exit
nstimstart: entry
Is DCD Working?
---------------
Search the server trace file for DCD probe packets. They will appear in the
form of empty data packets, as follows:
nstimexp: entry
nstimexp: timer expired at 05-OCT-95 12:15:05
nsdo: entry
nsdo: cid=0, opcode=67, *bl=0, *what=1, uflgs=0x2, cflgs=0x3
nsdo: nsctx: state=8, flg=0x621c, mvd=0
nsdo: gtn=93, gtc=93, ptn=10, ptc=2048
nsdoacts: entry
nsdofls: entry
nsdofls: DATA flags: 0x0
nsdofls: sending NSPTDA packet
nspsend: entry
nspsend: plen=10, type=6
nttwr: entry
nttwr: socket 4 had bytes written=10
nttwr: exit
nspsend: 10 bytes to transport
nspsend:packet dump
nspsend:00 0A 00 00 06 00 00 00 |........|
nspsend:00 00 00 00 00 00 00 00 |........|
nspsend: normal exit
nsdofls: exit (0)
nsdoacts: flushing transport
nttctl: entry
nsdoacts: normal exit
nsdo: normal exit
nstimexp: normal exit
The entry:
nspsend:00 0A 00 00 06 00 00 00 |........|
nspsend:00 00 00 00 00 00 00 00 |........|
represents the probe packet. Note that DCD packets are 10 bytes long when they
are issued to the protocol stack. Once the protocol header and trailer bytes
for the underlying protocols have been added, the packet could be approximately
70 bytes long.
If DCD is enabled, you will see these probe packets written to the trace file
when the timer expires. If the server is a UNIX system, it might be useful to
establish a connection and tail the trace file:
tail -f svr_.trc
The time elapsed after each probe packet is written to the server trace should
match the SQLNET.EXPIRE_TIME value.
Note: from version 9.2.0.4.0 onwards, DCD probe packets are no longer traced in
SQL*Net trace files, however DCD packets can be observed using other forms of
tracing, such as network sniffer tracing.
KNOWN PROBLEMS OR LIMITATIONS
-----------------------------
- Of the few reported problems, perhaps the most significant is DCD's poor
performance on Windows NT. Dead connections are cleaned up only when the
server is rebooted and the database is restarted. Exactly how well DCD works
on NT depends on the client's protocol implementation. SQL*Net v2.3 has
improved the performance over earlier releases.
This has been logged as port-specific Bug#303578.
- On SCO Unix, a problem was reported in which server processes spin, consuming
large amounts of CPU, once the DCD timer expires. The problem is due to improper
signal handling and can be eliminated by disabling DCD.
This is port-specific Bug#293264
- Orphaned resources are not released if only the client application is
terminated. Only after the client PC has been rebooted does DCD release these
resources. For example, if a Windows application is killed yet Windows remains
running, the probe packet may be received and discarded as if the connection is
still active. As it currently stands, it appears that DCD detects dead client
machines, but not dead client processes.
This is logged as generic Bug#280848.
- The SQL*Net V2 implementation on MVS does not use the generic DCD mechanism,
and therefore the SQLNET.EXPIRE_TIME parameter does not apply. The KEEPALIVE
function of IBM's TCP/IP is used instead. This was implemented prior to
development of DCD.
This is documented in port-specific Bug#301318.
- DCD relies heavily on issuing probe packets during any phase of the connection.
This is not be possible with some protocols which run half-duplex. Hence, DCD is
not enabled on protocols like APPC/LU6.2.
This is not a bug, but is rather the intended design.
- Local connections using BEQ protocol adapters are not supported with DCD.
Local connections using the IPC protocol adapters are supported with DCD.
-BUG#1388806 : On Windows NT, DCD FAILS AFTER 16 CONNECTIONS
A FINAL NOTE...
--------------
On most OS'es (even more recent versions of Windows) if a process exits
abnormally or is killed by an administrator, the OS will still gracefully
clean up resources associated with that process including the network
connection(s). It will tell the server on the other end that it is closing
the network connection. DCD is still useful for times when there are problems
with the physical network (e.g. ethernet cable falls off the machine) or if
the OS kernel panics and crashes (e.g. blue screen of death) before it can
close the network connections. It may have another side benefit with certain
load balancing hardware, that may prematurely abort connections it thinks have
been idle too long, by sending a dummy packet to the client periodically.
Under no circumstances should you rely 100% on Dead Connection Detection.
It was developed to handle clients that have abnormally exited. Clients should
always exit their applications gracefully. It is the responsibility of the
application developer to make this possible. DCD is intended only to clean up
after abnormal events.
DCD is much more resource-intensive than similar mechanisms at the protocol
level, so if you depend on DCD to clean up all dead processes, that will put
an undue load on the server.
Clearly it is advantageous to exit applications cleanly in the first place.
REFERENCES
---------- Note:395505.1 How to Check if Dead Connection Detection (DCD) is Enabled in 9i and 10g Note:438923.1 How To Track Dead Connection Detection(DCD) Mechanism Without Enabling Any Client/Server Network Tracing
Resolving Problems with Connection Idle Timeout With Firewall (文档 ID 257650.1)
In this Document
| Purpose |
| Scope |
| Details |
| An Overview |
| Blackout |
| Resolving problems with connection idle time-out |
APPLIES TO:
Oracle Net Services - Version 9.2.0.2 to 12.1.0.1 [Release 9.2 to 12.1]Oracle Net Services - Version 12.1.0.2 to 12.1.0.2 [Release 12.1]
Information in this document applies to any platform.
***Checked for relevance on 29-SEPT-2015***
PURPOSE
This article describes about the connection idle time-out issues that occur while a firewall or load balancer is used to monitor and control TCP traffic between clients (such as application servers / iAS components) and Oracle Databases.
SCOPE
This article is primarily intended for Application/Database Administrators and Network Administrators who would like to understand and try to workaround connection "IDLE TIMEOUT" issues in a firewall or F5 load balancer environment.
DETAILS
An Overview
Firewalls (FW) has become common in today's networking to protect the network environment. The firewall recognizes the TCP protocol and it records the client server socket end-points. Also, FW recognize the TCP connection closure, and then will release the resources allocated for recording the opening connection. For every end-point pairs , the firewall must also allocate some resources(may be small).
When the client or server closes the communication it sends TCP FIN type packet, this is a normal socket closure. However, it is not uncommon that the client server communication abruptly ending without closing the end points properly by sending FIN packet, for example, when the client or server crashed, power down or a network error which prevents sending the closure packet to the other end. In that cases, the firewall will not know that the end-points will no longer use the opened channel. As a passive intermediary, it had no way to determine if the endpoints are still active. As is it not possible to maintain resources forever, and also, it is a security threat keeping a port open for undefined time. So, firewall imposes a BLACKOUT on those connections that stay idle for a predefined amount of time.
Initially FW were designed to protect the application servers, network and then to protect client/server connection. With these in mind, a time-out in terms of hours (1 hour is the default for most FW) is reasonable. With the advent of more complex security schemes, FW are not only between client and server, but also between different application servers ( intranet, demilitarized zone (DMZ) , and such) and database servers. So, the horizon of 1 hour idle time for communication between servers maybe not be appropriate.
Idle connections can be expected from an application server. There is the case of J2EE using pooled JDBC connections. The pool usually returns the first available connection to the requester, so the first connections of the pool list are the most likely to be active. The last one, which are at the end of the list, are only used at peak loads, and most of the time it will be inactive.
Other cases are the connections established from a HTTP Server, either SQL connections from mod_plsql, or AJP connections from mod_oc4j.
Blackout
One of the inconvenience of theses blackout, is that they are passive. None of the endpoints will be notified that the communication was banned . Only when the client or server tries to contact its peer, it comes to know that the peer end is no more active and the communication has already been broken.
The worst of all scenarios are the so called "passive listeners" . They will never know. Because, passive listeners are those processes at an endpoint that are simply waiting for commands to arrive from the other end. A typical example of this are the backend database server processes, which are reading from the socket looking new SQL statements to execute , and after the request is answered, they return to their passive state. When a blackout occurs, they will stay forever in this reading state, unless some of the following techniques are applied.
Resolving problems with connection idle time-out
TCP KeepAlive
Ensure TCP KeepAlive is set appropriately for your environment. Refer to your OS documentation for details.
DCD for DataBase Servers
For database connections, one of the endpoints is a passive listener, either is a dedicated process or a dispatcher process. If the connection becomes blacked out , this backend will never know that client cannot send any more requests, and then will lock important resources as database sessions, locks , and at least , a file descriptor used for maintaining the socket.
A solution is to make this backend "not so" passive, using the DCD (dead connection detection) to figure out if the communication is still possible.
Simply, set in the $ORACLE_HOME/network/admin/sqlnet.ora, in the server side SQLNET.EXPIRE_TIME=10 (10 minutes, for example). With this parameter in place, after 10 minutes of inactivity, the server send a small 10 bytes probe packet to the client. If this packet is not acknowledge, the connection will be closed and the associated resources will be released.
There are two benefits with this DCD
1. If the SQLNET.EXPIRE_TIME is less than the FW connection idle time-out, then the firewall *may* consider this packet as activity, and the idle time-out (firewall blackout) will never happen until both the client and the server processes are alive.
2. If the SQLNET.EXPIRE_TIME (let's say a little bit higher) than the FW idle limit, then , as soon as the blackout happens , the RDBMS will know and will close the connection.
The first case is recommended when the connection comes from another application server , and the second makes sense for client applications.
DCD works at the application level and also works on top of TCP/IP protocol. If you have set the SQLNET.EXPIRE_TIME=10 then do not expect that the connections will be flagged as dead exactly after 10 minutes of the blackout or network outage. Please seeNote:151972.1 "Dead Connection Detection (DCD) Explained" for details on DCD. The TCP timeout and TCP retransmission values also adds to this time.
DCD was never designed to be used as a "virtual traffic generator" as we are wanting to use it for here. This is merely a useful side-effect of the feature.
In fact, some later firewalls and updated firewall firmware may not see DCD packets as a valid traffic possibly because the packets that DCD sends are actually empty packets. Therefore, DCD may not work as expected and the firewall / switch may still terminate TCP sockets that are idle for the period monitored, even when DCD is enabled and working.
In such cases, the firewall timeout should be increased or users should not leave the application idle for longer than the idle time out configured on the firewall.
AJP Connections
It is not a default behavior in 9.0.2, but if Patch 2862660 is installed, the connection between and OHS server process and the J2EE can be maintained for more than a single request. If the parameter Oc4jConnTimeout is set, the OHS will maintain the connection for at least that time. The problem is that the child process may became inactive before that time-out occurs, and then the connection will remain open. While the child process is inactive, the connection will be idle, and there is chance to be blackout by the FW.
If this happens, the first thing that the child will do is to close it when it becomes active. But at this time, the TCP socket closing cannot be completed, due the blackout. Although the http child process can simply ignore the closing failure and continue the creation of a new connection, the passive listener at the
j2ee side (the worker thread) will be hook without a chance for the resources to be released.
To solve this , the Patch 3151686 must be installed and the java-option
-Dajp.keepalive=true
must be enabled.
After this, the blackout detection will rely on the TCP KeepAlive provided by the operating system.
As DCD , this process consist in send probes -empty packages- when a socket had been inactive for a period of time. If there is no response, the socket will be closed, and then, even the passive listener, will receive and exception or signal to let him know that the no further communication is possible.
CONCLUSION
As the firewalls extend their functionality , and are now are placed in between application servers, some tuning and parameter adjusting must be made to overcome the default rules established for client/server communications. However, remember that a firewall idle timeout setting is simply the way this product functions and any changes to it should be made with agreement between all parties involved.
About Me
...............................................................................................................................
● 本文整理自网络
● 本文在itpub(http://blog.itpub.net/26736162)、博客园(http://www.cnblogs.com/lhrbest)和个人微信公众号(xiaomaimiaolhr)上有同步更新
● 本文itpub地址:http://blog.itpub.net/26736162/abstract/1/
● 本文博客园地址:http://www.cnblogs.com/lhrbest
● 本文pdf版及小麦苗云盘地址:http://blog.itpub.net/26736162/viewspace-1624453/
● 数据库笔试面试题库及解答:http://blog.itpub.net/26736162/viewspace-2134706/
● QQ群:230161599 微信群:私聊
● 联系我请加QQ好友(646634621),注明添加缘由
● 于 2017-04-28 09:00 ~ 2017-04-30 22:00 在魔都完成
● 文章内容来源于小麦苗的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
...............................................................................................................................
拿起手机使用微信客户端扫描下边的左边图片来关注小麦苗的微信公众号:xiaomaimiaolhr,扫描右边的二维码加入小麦苗的QQ群,学习最实用的数据库技术。




