Linux(5):Linux 磁盘与文件管理系统
认识 Linux 文件系统
磁盘的物理组成:
1.圆形的磁盘盘(主要记录数据的部分);
2.机械手臂,与在机械手臂上的磁盘读取头(可擦写磁盘盘上的数据);
3.主轴马达,可以转动磁盘盘,让机械手臂的读取头在磁盘盘上读写数据。
4.扇区(Sector)为最小的物理储存单位,且依据磁盘设计的不同,目前主要有 512bytes 与 4K 两种格式;
5.将扇区组成一个圆,那就是磁柱(Cylinder);
6.早期的分区主要以磁柱为最小分区单位,现在的分区通常使用扇区为最小分区单位(每个扇区都有其号码);
7.磁盘分区表主要有两种格式,一种是限制较多的 MBR 分区表,一种是较新且限制较少的 GPT 分区表;
8.MBR 分区表中,第一个扇区最重要,里面有: (1)主要开机区(Master boot record,MBR)及分区表(partition table), 其中 MBR 占有 446 bytes,而 partition table 则占有 64 bytes。
9.GPT 分区表除了分区数量扩态较多之外,支持的磁盘容量也可以超过 2TB。
/dev/sd[a-p][1-128]: 为实体磁盘的磁盘文件名
/dev/vd[a-d][1-128]: 为虚拟磁盘的磁盘文件名
文件系统特性
磁盘分区完毕后还需要进行格式化(format),之后操作系统才能够使用这个文件系统。
格式化: 每种操作系统所设定的文件属性/权限并不相同,为了存放这些文件所需的数据,因此就需要将分区槽进行格式化,以成为操作系统能够利用的文件系统格式(file system)。
一个可被挂载的数据为一个文件系统而不是一个分区槽。
文件系统通常会将这两部份的数据分别存放在不同的区块,权限与属性放置到 inode 中,至于实际数据则放置到 data block 区块中。 另外,还有一个超级区块 (super block) 会记录整个文件系统的整体信息,包括 inode 与 block 的总量、使用量、剩余量等。
superblock: 记录此 filesystem 的整体信息,包括 node/block 的总量、使用量、剩余量,以及文件系统的格式与相关信息等;
inode:记录文件的属性,一个文件占用一个 inode,同时记录此文件的数据所在的 block 号码;
block:实际记录文件的内容,若文件太大时,会占用多个 block。
索引式文件系统:如果能够找到文件的 inode 的话,那么自然就会知道这个文件所放置数据的 block 号码, 当然也就能够读出该文件的实际数据了。这是个比较有效率的作法,因为如此一来我们的磁盘就能够在短时间内读取出全部的数据, 读写的效能比较好。
闪存的文件系统一般为FAT格式,没有inode存在,因此没有办法将这个文件的所有block在一开始读出来。
碎片整理:需要碎片整理的原因就是文件写入的 block 太过于离散了,此时文件读取的效能将会变的很差所致。这个时候可以透过碎片整理将同一个文件所属的 blocks 汇整在一起,这样数据的读取会比较容易。
EXT2 文件系统(inode)
inode 的内容在记录文件的权限和相关属性;
block 区域则是在记录文件的实际内容。
文件系统一开始就将 inode 与 block 规划好了,除非重新格式化(或者利用 resize2fs 等指令变更文件系统大小),否则 inode 与 block 固定后就不再变动。
但是如果仔细考虑下,如果我的文件系统高达数百 GB 时, 那么将所有的 inode 与 block 通通放置在一起将是很不智的决定,因为 inode 与 block 的数量太庞大,不容易管理。
为此,因此 Ext2 文件系统在格式化的时候基本上是区分为多个区块群组(block group)的,每个区块群组都有独立的 inode/block/superblock 系统。
Ext2 格式化后有点像底下这样:
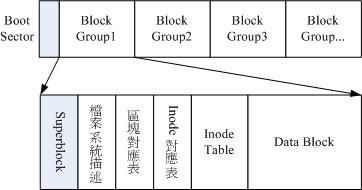
在整体的规划当中,文件系统最前面有一个启动扇区(boot sector),这个启动扇区可以安装开机管理程序,这样可以将不同的开机管理程序安装到个别的文件系统最前端,而不用覆盖整颗磁盘唯一的 MBR 。
data block:资料区块
用来放置文件内容数据,在 Ext2 文件系统中所支持的 block 大小,有 1K,2K 及 4K 三种。
在格式化时,block 的大小就固定了,且每个 block 都有编号,以便 inode 的记录。由于 block 大小的差异,会导致该文件系统能够支持的最大磁盘容量与最大单一文件容量并不相同:

Ext2 文件系统的 block 限制:
1.原则上,block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
2.每个 block 内最多只能够放置一个文件的数据;
3.承上,如果文件大于 block 的大小,则一个文件会占用多个 block 数量;
4.承上,若文件小于 block ,则该 block 的剩余容量就不能够再被使用了(磁盘空间会浪费).
inode table:inode 表格
inode 记录的文件数据有:
1.该文件的存取模式(read/write/excute);
2.该文件的拥有者与群组(owner/group);
3.该文件的容量;
4.该文件建立或状态改变的时间(ctime);
5.最近一次的读取时间(atime);
6.最近修改的时间(mtime);
7.定义文件特性的旗标(flag),如 SetUID…;
8.该文件真正内容的指向(pointer);
inode 特点:
1.每个 inode 大小均固定为 128 bytes(新的 ext4 与 xfs 可设定到 256 bytes);
2.每个文件都会占用一个 inode 而已;
3.承上,因此文件系统能够建立的文件数量与 inode 的数量有关;
4.系统读取文件时需要先找到 inode,并分析 inode 所记录的权限与用户是否符合,若符合才能开始实际读取 block 的内容。
inode 要记录的数据非常多,不够用时,可以通过定义间接记录区。
间接:再拿一个 block 来当作记录 block 号码的记录区,如果文件太大时,就会使用间接的 block 来记录编号。
双间接:第一个 block 仅再指出下一个记录编号的 block 在哪里,实际记录在第二个 block 当中。三间接以此类推。。。
Superblock:超级区块
Superblock 是记录整个 filesystem 相关信息的地方,它记录的信息有:
1.block 与 inode 的总量;
2.未使用与已使用的 inode/block 数量;
3.block 与 inode 的大小(block 为 1,2,4K,inode 为 128 bytes 或 256 bytes)
4.filesystem 的挂载时间、最近一次写入数据的时间、最近一次检验磁盘 (fsck) 的时间等文件系统的相关信息;
5.一个 valid bit 数值,若此文件系统已被挂载,则 valid bit 为 0 ,若未被挂载,则 valid bit 为 1。
Filesystem Description:文件系统描述说明
这个区段可以描述每个 block group 的开始与结束的 block 号码,以及说明每个区段 (superblock,bitmap,inodemap,data block) 分别介于哪一个 block 号码之间。
对照表
block bitmap 记录 block 的状态:【空的block】【使用中】。。。
inode bitmap 记录使用与未使用的 inode。。。
dumpe2fs:查询 Ext 家族 superblock 信息的指令
dumpe2fs [-bh] 装置文件名

与目录树的关系
当我们在 Linux 下的文件系统建立一个目录时,文件系统会分配一个 inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块 block 号码;而 block 则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。
目录并不只会占用一个 block
在目录底下的文件数如果太多而导致一个 block 无法容纳的下所有的档名与 node 对照表时,Linux 会给予该目录多一个 block 来继续记录相关的数据。
在 Linux 下的 ext2 建立一个一般文件时, ext2 会分配一个 inode 与相对于该文件大小的 block 数量给该文件。
目录树读取:由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的 inode 号码,此时就能够得到根目录的 inode 内容,并依据该 inode 读取根目录的 block 内的文件名数据,再一层一层的往下读到正确的档名。

流程:
1./的 inode:
透过挂载点的信息找到 inode 号码为 2 的根目录 inode,且 inode 规范的权限让我们可以读取该 block的内容(有 r 与 x) ;
2./的 block:
经过上个步骤取得 block 的号码,并找到该内容有 etc/ 目录的 inode 号码(524298);
3.etc/ 的 inode:
读取 524298号 inode 得知 feng 具有 r 与 x 的权限,因此可以读取 etc/ 的 block 内容;
4.etc/ 的 block:
经过上个步骤取得 block 号码,并找到该内容有 passwd 文件的 inode 号码 (526037):
5.passwd 的 inode:
读取 526037号 inode 得知 feng 具有 r 的权限,因此可以读取 passwd 的 block 内容:
6.passwd 的 block:
最后将该 block 内容的数据读出来。
filesystem 大小与磁盘读取效能
文件数据离散:文件写入的 block 分散,可能会发生读取效率低落的问题。
因为:磁盘读取头还是得要在整个文件系统中来来去去的频繁读取。
可以将整个 filesystme内的数据全部复制出来,将该 flesystem 重新格式化, 再将数据给他复制回去即可解决这个问题。
EXT2/EXT3/EXT4 文件的存取与日志式文件系统的功能
新增一个文件,文件系统的行为:
1.先确定用户对于欲新增文件的目录是否具有 w 与 x 的权限,若有的话才能新增;
2.根据 inode bitmap 找到没有使用的 inode 号码,并将新文件的权限/属性写入;
3.根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,且更新 inode 的 block指向数据:
4.将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
一般来说,将 inode table 与 data block 称为数据存放区域,至于其他例如 superblock、 blockbitmap 与 inode bitmap 等区段就被称为 metadata (中介资料),因为 superblock,inode bitmap 及block bitmap 的数据是经常变动的,每次新增、移除、编辑时都可能会影响到这三个部分的数据,因此才被称为中介数据。
数据的不一致(Inconsistent) 状态:如停电,系统核心发生错误,
所写入的数据仅有 inode table 及 data block 而已, 最后一个同步更新中介数据的步骤并没有做完,此时就会发生 metadata 的内容与实际数据存放区产生不一致。
早期:Ext2 文件系统中,如果发生这个问题,就会在系统重新启动的时候,由 Supernlock 中记录的 valid bit(是否有挂载)与 filesystem state(clean 与否)等状态来判断是否强制进行数据一致性检查。如需要,则以 e2fsc 这支程序进行。
后期:日志式文件系统
1.预备:当系统要写入一个文件时,会先在日志记录区块中纪录某个文件准备要写入的信息;
2.实际写入:开始写入文件的权限与数据;开始更新 metadata 的数据;
3.开始更新 :完成数据与 metadata 的更新后,在日志记录区块当中完成该文件的纪录。
Linux 文件系统的运作
异步处理: 当系统加载一个文件到内存后,如果该文件没有被更动过,则在内存区段的文件数据会被设定为干净(clean)的。 但如果内存中的文件数据被更改过了(例如你用 nano 去编辑过这个文件),此时该内存中的数据会被设定为脏的(Dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中。系统会不定时的将内存中设定为[Dirty] 的数据写回磁盘,以保持磁盘与内存数据的一致性。也可以利用 sync 指令来手动强迫写入磁盘。
挂载点的意义
每个 filesystem 都有独立的 inode/block/superblock 等信息,这个文件系统要能够链接到目录树才能被使用。
将文件系统与目录树结合的动作称为挂载。
挂载点一定是目录,该目录为进入该文件系统的入口。
因此并不是任何文件系统都能使用,必须要挂载到目录树的某个目录后,才能够使用该文件系统的。
XFS filesystem 最顶层目录的 inode 一般为 128 号,每一行的文件属性也相同,可以发现 /,/. ,/.. 的内容相同,也就是说根目录的上层(/..)是他自己。

其他 Linux 支持的文件系统与 VFS
传统文件系统:ext2 /minix/MS-DOS /FAT(用 vfat 模块)/iso9660(光盘)等等
日志式文件系统:ext3 /ext4/ReiserFS /Windows’NTFS /IBMsJFS/SGIs XFS/ZFS
网络文件系统:NFS/SMBFS
整个 Linux的系统都是透过一个名为 Virtual Filesystem Switch 的核心功能去读取 filesystem 的。
XFS 文件系统简介
EXT 家族:支持度最广,但格式化超慢(预先规划,不动态配置)
xfs 就是被开发来用于高容量磁盘以及高性能文件系统之用外,几乎所有 Ext4 文件系统有的功能,xfs 都可以具备。
XFS文件系统在资料上的分布:资料区、文件系统活动登录区、实时运作区。
1.资料区:(data section) 这个区块这个数据区与 ext 家族的 block group 类似,也是分为多个储存区群组allocation groups) 来分别放置文件系统所需要的数据。 每个储存区群组都包含了 (1)整个文件系统的 superblock、(2)剩余空间的管理机制、 (3)inode 的分配与追踪。此外,inode 与 block 都是系统需要用到时,这才动态配置产生,所以格式化动作超级快。
2.文件系统活动登录区(log section):主要被用来纪录文件系统的变化,其实有点像是日志区。文件的变化会在这里纪录下来,直到该变化完整的写入到数据区后, 该笔纪录才会被终结。
可以指定外部的磁盘来作为 xfs 文件系统的日志区块
3.实时运作区(realtime section):当有文件要被建立时,xfs 会在这个区段里面找一个到数个的 extent 区块,将文件放置在这个区块内,等到分配完毕后,再写入到 data section 的 inode 与 block 去。
这个 extent 区块的大小得要在格式化的时候就先指定,最小值是 4K 最大可到 1G。一般非磁盘阵列的磁盘默认为 64K容量,而具有类似磁盘阵列的 stripe 情况下,则建议 extent 设定为与 stripe 一样大较佳。
文件系统的简单操作
磁盘与目录的容量
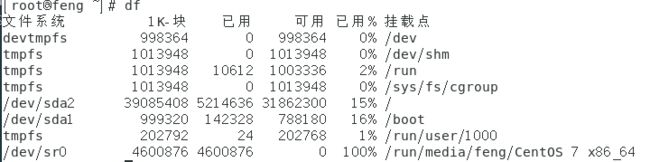
df:列出文件系统的整体磁盘使用量;
du:评估文件系统的磁盘使用量(常用在推估目录所占容量)
df [-ahikHTm] [目录或文件名]

在 Linux 底下如果 df 没有加任何选项,那么默认会将系统内所有的(不含特殊内存内的文件系统与 swap)都以 1 Kbytes 的容量来列出来。
du [-ahskm] 文件或目录名称

直接输入 du 没有加任何选项时,则 du 会分析[目前所在目录]的文件与目录所占用的磁盘空间。但是,实际显示时,仅会显示目录容量(不含文件因此 ,目录有很多文件没有被列出来,所以全部的目录相加不会等于.的容量。此外,输出的数值数据为 1K 大小的容量单位

实体链接与符号链接:ln
在 Linux 底下的连结档有两种,一种是类似 Windows 的快捷方式功能的文件,可以让你快速的链接到目标文件(或目录);另一种则是透过文件系统的 inode 连结来产生新档名,而不是产生新文件。这种称为实体链接(hard link)。
Hard Link(实体链接硬连结或实际连结)
每个文件都会占用一个 inode ,文件内容由 inode 的记录来指向;想要读取该文件,必须要经过目录记录的文件名来指向到正确的 inode 号码才能读取。
hard link 是在某个目录下新增一笔档名链接到某 inode 号码的关连记录而已。
如果两个档名连接到同一个 inode,那个这两个文件名的相关信息除了文件名之外,其他所有相关信息会一模一样。可以透过另一个档名来读取到正确的文件数据,无论修改哪个,都会写入相同的 inode 和 block。而将其中任何一个档名删除,其 inode 和 block 都还会存在。

一般来说,使用 hard link 设定链接文件时,磁盘的空间与 inode 的数目都不会改变。hard link 只是在某个目录下的 block 多写入一个关连数据而已,既不会增加 inode 也不会耗用 block 数量。
改变系统block的情况: 新增数据刚好将目录的 block 填满时,就可能会新加一个 block 来记录文件名关连性,而导致磁盘空间的变化(通常不会发生)
hard link 的限制:1.不能跨 Filesystem;2.不能 link 目录。
因为如果使用 hard link 链接到目录时, 链接的数据需要连同被链接目录底下的所有数据都建立链接。
Symbolic Link(符号链接,亦即是快捷方式)
Symbolic link 就是在建立一个独立的文件,而这个文件会让数据的读取指向他 link 的那个文件的档名。由于只是利用文件来做为指向的动作, 所以,当来源档被删除之后,symbolic link 的文件会开不了, 会一直说了无法开启某文件。
由 Symbolic link 所建立的文件为一个独立的新的文件,所以会占用掉 inode 与 block。
制作连接档
ln [-sf] 来源文件 目标文件

建立一个新的目录时,新的目录的 link 数为 2 ,而上层目录的 link 数则会增加 1。

磁盘的分区、格式化、检验与挂载
新增磁盘时:
1.对磁盘进行分区,以建立可用的 partition;
2.对该 partition 进行格式化 (format),以建立系统可用的 filesystem;
3.若想要仔细一点,则可对刚刚建立好的 filesystem 进行检验;
4.在 Linux 系统上,需要建立挂载点 (亦即是目录),并将他挂载上来;
观察磁盘分区状态
lsblk:列出系统上的所有磁盘列表
lsblk 为 【list block device】的缩写,列出所有储存装置的意思。
lsblk [-dfimpt] [device]


blkid:列出装置的 UUID 参数
lsblk 可以使用 -f 列出文件系统与装置的 UUID数据,blkid 也具有同样的功能。
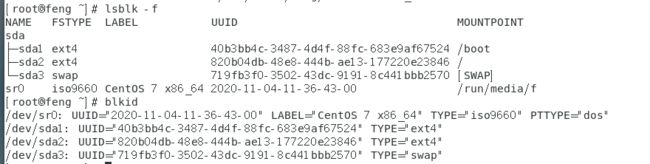
UUID是全局单一标识符 (universally unique identifier),Linux 会将系统内所有的装置都给予一个独一无二的标识符, 这个标识符可以拿来作为挂载或者是使用这个装置/文件系统之用。
parted:列出磁盘的分区表类型与分区信息
可以输出磁盘的分区类型。

MBR 分区使用 fdisk 分区,GPT分区使用 gdisk 分区。
gdisk
gdisk 装置名称
整部磁盘可以进行额外的分区,因为最大扇区为 83886080,但只使用到 65026047 号而已;
分区槽的设计中,新分区通常选用上一个分区的结束扇区号码数加 1 作为起始扇区号码!
gdisk 只有 root 才能执行,此外,使用的装置文件名不要加上数字,因为 partition是针对整个磁盘装置而不是某个 partition。
例如,不要写[gdisk /dev/vda1],而是写[gdisk /dev/vda]
可以用 gdisk 新增分区槽。操作完成后,使用 partprobe 更新 Linux 核心的分区表信息。
fdisk
fdisk 有时会使用磁柱 (cylinder) 作为分区的最小单位,和 gdisk 默认使用sector不太一样,两者使用方式几乎一样。
MBR 分区是有限制的。
磁盘格式化
格式化其实应该称为建置文件系统 (make filesystem)
使用 mkfs 进行格式化。
xfs 系统的 mkfs.xfs
mkfs.xfs [-b bsize] [-d parms] [-i parms] [-l parms] [-L label] [-f] \ [-r parms] 装置名称


XFS 文件系统 for RAID 效能优化(Optional)
磁盘阵列(RAID):磁盘阵列是多颗磁盘组成一颗大磁盘的意思, 利用同步写入到这些磁盘的技术,不但可以加快读写速度,还可以让某颗磁盘坏掉时,整个文件系统还是可以持续运作的状态。那就是所谓的容错。
基本上,磁盘阵列(RAID) 就是透过将文件先细分为数个小型的分区区块 (stripe) 之后,然后将众多的 stripes 分别放到磁盘阵列里面的所有磁盘, 所以一个文件是被同时写入到多个磁盘去,当然效能会好一些。
为了文件的保全性,所以在这些磁盘里面,会保留数个 (与磁盘阵列的规划有关)备份磁盘 (parity disk), 以及可能会保留一个以上的备用磁盘 (spare disk),这些区块基本上会占用掉磁盘阵列的总容量,不过对于数据的保全会比较有保障。
EXT4 文件系统格式化使用 mkfs.ext4

文件系统检验
xfs_repair 处理 XFS 文件系统
当有 xfs 文件系统错乱才需要使用这个指令:
xfs_repair [-fnd] 装置名称
-f:后面的装置其实是个文件而不是实体装置;
-n:单纯检查并不修改文件系统的任何数据(检查而已);
-d:通常用在单人维护模式底下,针对根目录(/)进行检查与修复的动作(很危险)。
修复时,该文件系统不能被挂载。
根目录有问题时,需要加入 -d 选项,强制检验该装置,完毕后自动启动。
fsck.ext4 处理 EXT4 文件系统
fsck.ext4 [-pf] [-b superblock] 装置名称

无论是 xfs_repair 或 fsck.ext4,这都是用来检查与修正文件系统错误的指令。通常只有身为root且文件系统有问题才会使用。
执行 xfs_repair/fsck.ext4 时,被检查的 partition 务必不可挂载到系统上。亦即是需要在卸除的状态。
文件系统挂载与删除
挂载点是目录,这个目录是进入磁盘分区槽(文件系统)的入口。
挂载要注意:
1.单一文件系统不应该被重复挂载在不同的挂载点(目录)中;
2.单一目录不应该重复挂载多个文件系统;
3.要作为挂载点的目录,理论上应该都是空目录才是。
如果要用来挂载的目录里面并不是空的,那么挂载了文件系统之后,原目录下的东西就会暂时的消失(被隐藏掉)。
mount -a
mount [-l]
mount [-t 文件系统] LABEL='' 挂载点
mount [-t 文件系统] UUID='' 挂载点
mount [-t 文件系统] 装置文件名 挂载点

参考:
/etc/filesystems:系统指定的测试挂载文件系统类型的优先级;
/proc/filesystems:Linux 系统已经加载的文件系统类型;
/lib/modules/$(uname -r)/kernel/fs :Linux 支持的文件系统的驱动程序。
将装置文件卸除:umount
umount [-fn] 装置文件名或挂载点

离开该文件系统的挂载点,再进行 umount。
磁盘/文件系统参数修订
mknod
在 Linux 下,所有的装置都以文件来代表。
透过文件的 major【主要装置代码】 与 minor 【次要装置代码】数值来代替。
mknod 装置文件名 [bcp] [Major] [Minor]

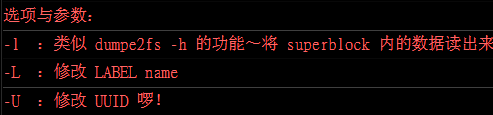
xfs_admin 修改 XFS 文件系统的 UUID 与 Label name
xfs_adimin [-lu] [-L label] [-U uuid] 装置文件名

tune2fs 修改 cxt4 的 label name 与 UUID
tune2fs [-l] [-L label] [-U uuid] 装置文件名
设定开机挂载
开机挂载 /etc/fstab 及 /etc/mtab
系统挂载的限制:
1.根目录/是必须挂载的﹐而且一定要先于其它 mount point 被挂载进来。
2.其它 mount point 必须为已建立的目录,可任意指定,但一定要遵守必须的系统目录架构原则(FHS)
3.所有 mount point 在同一时间之内﹐只能挂载一次。
4.所有 partition 在同一时间之内﹐只能挂载一次。
5.如若进行卸除﹐必须先将工作目录移 到mount point (及其子目录)之外。

[装置/UUID等] [挂载点] [文件系统] [文件系统参数] [dump] [fsck]
dump 是一个用来做为备份的指令;
fsck 是否以fsck检验扇区
特殊装置 loop 挂载(印象档不可录就挂在使用)
如果有光盘映像文件,或者是使用文件作为磁盘的方式时,那就得要使用特别的方法来将他挂载起来。
这里先不学了。。。
内存置换空间(swap)之建置
一般来说,如果硬件的配备资源足够的话,那么 swap应该不会被我们的系统所使用到, swap 会被利用到的时刻通常就是物理内存不足的情况了。
swap 是用磁盘来暂时放置内存中的信息。
使用实体分区槽建置 swap
1.分区:先使用gdisk在磁盘中分区出一个分区槽给系统作为 swap 。由于 Linux 的 gdisk 预设会将分区槽的 ID 设定为 Linux 的文件系统,所以可能还得要设定一下 system ID。
2.格式化:利用建立 swap 格式的【mkswap 装置文件名】就能够格式化该分区槽成为 swap 格式;
3.使用:最后将该 swap 装置启动,方法为:【swapon 装置文件名】。
4.观察:最终透过 free 与 swapon -s 这个指令来观察内存的用量。
使用文件建置 swap
1.使用dd 这个指令来新增一个 128MB 的文件在 /tmp 底下:

2.使用 mkswap 将 /tmp/swap 这个文件格式化为 swap 的文件格式:
![]()
3.使用swapon来将 /tmp/swap启动:
swapon /tmp/swap
4.使用 swapoff 关掉swap file,并设定自动启用.
swapoff /tmp/swap /dev/vda6
因为 swap主要的功能是当物理内存不够时,则某些在内存当中所占的程序会暂时被移动到 swap当中,让物理内存可以被需要的程序来使用 。
另外,如果主机支持电源管理模式,也就是说,Linux主机系统可以进入【休眠】模式的话,那么,运作当中的程序状态则会被纪录到 swap 去,以作为【唤醒】主机的状态依据。
另外,有某些程序在运作时,本来就会利用 swap 的特性来存放一些数据段,所以,swap来是需要建立的。只是不需要太大。
《鸟哥的Linux私房菜-基础篇》学习笔记