【MySQL】多表查询、子查询、自连接、合并查询详解,包含大量示例,包你会。
复合查询
- 前言
- 正式开始
-
- 一些开胃菜
- 多表查询
- 自连接
- 子查询
-
- 单行子查询
- 多行子查询
- in关键字
- all关键字
- any关键字
- 多列子查询
- 在from中使用子查询
- 合并查询
-
- union 和 union all

前言
我前面博客讲的所有的查询都是在单表中进行的,从这里开始就要专门针对查询这个话题进行进一步的讲解。
前面有一篇专门介绍select的博客,如果你是一个小白,对于一些单表中的基本查询操作还不是很熟练的话,建议先看看我之前写的那一片更基础的查询:select单表查询详解
本篇主要讲解:
- 多表查询
- 子查询
- 自连接
- 合并查询。
我这一篇博客重点讲查询,主要用到前面博客中搞的三张表(不用细看这三张表,大概过一眼就行):
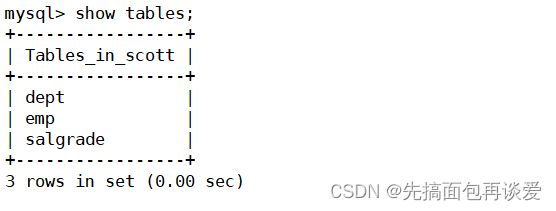
雇员表emp:
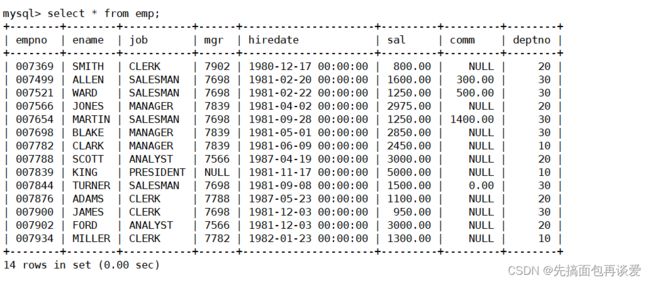
部门表dept:

薪资等级表:
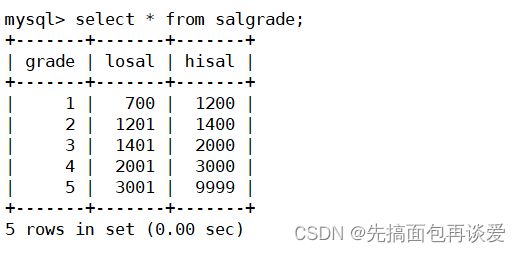
这三张表中没有明确指出外键和主键约束,但是是有外键和主键约束的样子的:

其中不同薪资对应不同的薪资等级。
这三张表就不细说了,等会给查询示例的时候慢慢了解。
正式开始
一些开胃菜
题目>> 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
看题目,其要求工资高于500或者岗位为MANAGER,这是一个条件,满足姓名首字母为大写的J,这是另一个条件,而这两个条件在emp表中都能找到:

所以这其实还是一个单表查询。
所以先来搞出工资高于500或者岗位为MANAGER:

然后再加上姓名首字母为大写J的条件:

或者用我前一篇讲过的内置函数substring:

关于这个内置函数我就不讲了,不懂的同学可以看看我前一篇博客:【MySQL】一些内置函数(时间函数、字符串函数、数学函数等,学会了有妙用)
题目>> 按照部门号升序而雇员的工资降序排序
题目要求有:
- 按照部门号升序
- 再按照雇员的工资降序,意思就是如果部门号相同了再按照工资降序排序
那么用一个order by将两个排序放一块就行,还是一个单表的,先升序排deptno:

再降序排sal:

很简单,不过多赘述了。
题目>> 使用年薪进行降序排序
注意,这里表中只有月薪,想要有年薪还要给月薪乘以12:

这就完了么?并没有,还有一个问题,有的员工是有奖金的,在comm这一列:

这里意思就是有的部门中的员工有奖金,这里就是30号部门的员工有,但是也有奖金为0.00的,意思就是这个部门中的有些特定人员也是没有奖金的,其他部门中根本不谈奖金这件事。
但是直接加上奖金会出问题:

因为NULL是不参与运算的,任何数和NULL进行运算,结果都是NULL:

这一点在我前面的博客中也是一直在强调的。
那么怎么搞呢?
可以用我前一篇讲的另一个函数ifnull:

ifnull左右就是如果comm为null了就返回第二个参数0,如果comm不为null就返回comm。
题目>> 显示工资最高的员工的名字和工作岗位
还是单表的,直接以工资降序排序,然后limit一下就行:

这里再给一下所有人工资降序的结果:
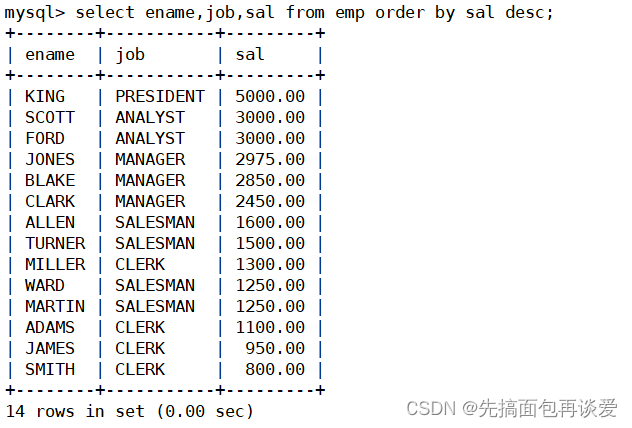
可以看到就是KING。
题目>> 显示工资高于平均工资的员工信息
高于平均工资的员工,那首先就要算出所有员工的平均工资:

然后再找出工资高于这个的员工,这里有点小难度,涉及到了子查询,我等会会细讲子查询,这里先带你看一下长什么样子:

这里意思就是将select avg(sal) 平均 from emp的结果交给where作为sal的筛选条件,满足条件的就会留下来。
题目>> 显示每个部门的平均工资和最高工资
这里有个关键字:每个,一般见到这个都要考虑是不是要进行分组了,这里要求是每个部门,那就得要按照部门进行分组。那就先来按照部门分个组:

再看TA要每个部门的平均工资和最高工资,那么就得再用聚合函数统计一下分组后各个组的平均工资和最高工资:

题目>> 显示平均工资低于2000的部门号和它的平均工资
首先要找到每个部门的平均工资:

然后才能对这些部门进行筛选(注意聚合的要和having搭配进行筛选):

题目>>显示每种岗位的雇员总数,平均工资
又出现了“每种”,还是要根据岗位进行分组:

分完组之后再用聚合函数统计雇员总数和岗位的平均工资:

注意分组其实就是将一张大表分成了好几个小表,然后聚合函数会对每个小表进行聚合统计。
ok,就简单回顾到这里,下面来开始本篇的重点内容。
多表查询
实际开发中往往数据来自不同的表,所以需要多表查询。
下面要用到的还是上面的简单的公司管理系统,也就是用EMP,DEPT,SALGRADE这三张表来演示如何进行多表查询。
理论没有什么要讲的,直接上例子把。
题目>>显示雇员名、雇员工资以及所在部门的名字。
首先明确一点,雇员名、雇员工资是在emp表中的:

但是部门名字是在dept表中的:

这一点就决定了下面要进行多表查询。
怎么查呢?
将两张表进行拼接,在from 后面写两张表的名字就行,不过这里emp表有点大,我就将拼接后的一部分内容截出来:

这里是如何拼接的呢?
左表emp的第一行数据与右表dept的所有行数据拼接到一块,看SMITH有4个,对应记录中的emp数据都是一样的,但是右边dept表的数据是四份不一样的,也就是所有dept表的数据。
左表剩下的记录的拼接方式和SMITH一样,都是一行对应多行拼一块。就不细说了。
这就是笛卡尔积。理论啥的就不讲了。有张图可以看看:

其实就是对数据做穷举组合。
但是可以发现这样拼接出来的数据很多都是没有意义的,因为一个人不可能同时属于多个部门:

所以要对拼接好的表进行有效数据的筛选,那如何筛选呢?
这里的emp表和dept表是有联系的,emp表中的deptno就相当于emp的外键,而dept表中的deptno就是dept表的主键,这样就可以根据两个表的deptno来进行有效数据的筛选:

注意上面两张表都有deptno列,如果要进行筛选,就得在前面加上表名. 来表示某一列属于哪一个表,不然会出现列名不明确的问题:

这样就可以一一对应上,一个人对应一个所属部门,这样就得到了一张新的表,再对这张表进行筛选,就能得到题目要求的雇员名、雇员工资以及所在部门的名字:

这里还是要指明deptno在哪一个表中,不过这里emp和dept的deptno的值已经一样了,给dept的也行:

题目>>显示部门号为10的部门名,员工名和工资
这里要的是部门名字,员工名和工资,还是这三样。不过还有一个条件就是部门号得是10。
先把三样搞出来:

然后再加上部门号为10的条件:

题目>>显示各个员工的姓名,工资,及工资级别
题目中要的是姓名、工资、工资级别,姓名和工资在emp表中,而工资级别在salgrade表中:

这里是每一个级别对应一个工资范围,只要某个员工工资在一个范围当中就会有一个级别,那还是多表查询,先来将两张表拼一块:

还是出现了很多的无效的数据,因为一个人不可能有多个工资等级。
还是需要对有效记录进行筛选,这里的筛选条件就是工资在哪个范围:
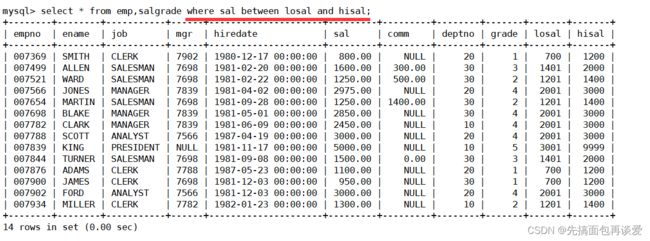
这样就得到了一张有效的新表,然后题目要啥拿啥就行:

自连接
一个表可以和自己进行笛卡尔积吗?
试试:

这里显示不可以,其实不是不可以,上面也提示你了两个表表名不一样才能进行拼接,所以重命名一下就行:

又是拼出了一堆。
这里要知道在from中也是能进行重命名的。不是只有select中才可以。
来个例子:
题目>> 显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号–empno)
这里首先要找到FORD领导的编号,就是mgr:

也就是:

但是然后怎么搞呢?
直接用这个7566吗?

可以是可以,但是有点挫。
可以用子查询来实现(子查询我还没讲,但是我相信你能看到这里也绝对是能看懂的):

这个题讲完就说子查询。
这里用自连接也可实现,先将两表拼一块:

不过还是有些数据没用,在筛一下,这里可以根据t1表的empno和t2表中的mgr来拼(或者反过来,用t2表的empno和t1表中的mgr):

这样就可以筛出来每个人的上司,左边t1是上司,右边的t2是员工,然后再筛出来员工FORD就行:

这样也就筛选出来了。
用自己表中的数据来筛选自己表中的某一条记录,可以用自连接,也可以用子查询,下面就来讲讲子查询。
子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
子查询可以分为三种,单行子查询、多行子查询和多列子查询(其实多列也可再分为多列单行和多列多行)。
单行子查询和多行子查询都是指单列中的单行或者多行。
这里就按照这三种来说。
单行子查询
返回一行记录的子查询。
上例子:
题目>>显示SMITH同一部门的员工
首先要找到SMITH在哪个部门:

然后再用这个deptno的20来找到对应的员工:
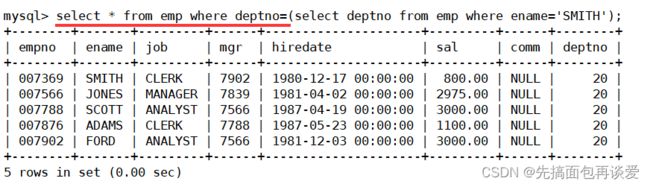
这就是子查询。
用一个查询的结果再进行查询。
刚刚也说了,用自己表中的数据来筛选自己表中的某一条记录,可以用自连接:

就不讲为啥了。
多行子查询
返回多行记录的子查询。
分三种:in、all、any,三个例子都给一下。
in关键字
题目>>查询和10号部门的工作岗位相同的所有雇员的名字,岗位,工资,部门号,但是不包含10自己的
首先要找到10号部门的工作岗位都有什么:

假如说这个表叫做t1。
然后再对每个雇员的job和这里的查询结果进行对比,但是不能直接用=:

这里报错的信息是子查询返回的结果超过1行。这里也就说明=只能用于单行的查询。
这里题目是只要满足job是上面表中的任意一个就行了,用in就可以表示:

这里用in表达的意思就是只要某个员工的job在t1表中job其中的任意一个就行了。
其实还可以用等会要讲的any:

这里表达的意思就是只要工作岗位是筛出来的任何一个就行。
根据题目要求,雇员的名字,岗位,工资,部门号,但是不包含10自己的,去掉部门为10的:

然后挑出雇员的名字,岗位,工资,部门号:

我在再来改一下条件,将部门号换成部门名称,你又该如何应对?
很简单,当前查询出来的还是一张表,这个表中也是有deptno的,那就还可以继续让这个表和dept表进行笛卡尔积,拼起来之后再筛选出有效的记录,然后再挑出来需要的列就行。
先来拼接:

然后挑出来有效的,条件就是deptno相同就行:

然后再挑选出来想要的列就行,想要部门名,挑出来就行:

所以其实多表的查询完全可以看成是单表查询,只要你熟练了所有的select操作,不管多少张表,最后都会拼成一张表。
其实刚刚的单行查询也可以用这里的in,再来看一下刚刚的题目:
题目>>显示SMITH同一部门的员工
这里虽然查找的只有单行,但是用in也是符合的逻辑的。

all关键字
题目>>显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
这里题目意思是比30号部门所有员工工资高的员工,那么可以找出30号部门的最高工资,然后只要其他部门的员工工资比这个最高工资高就行,那先来找30号部门的最高工资:

然后再对整表中的所有员工工资做对比:

挑出来想要的列:

这里是可以实现的,但是没有用到刚刚给的all。那用all怎么搞呢?
首先就要找到30号部门的所有员工的工资:

不过这里有重复的,重复的没用,去一下重:

假如说这个表为t1。
然后就可以用all了:

这里意思是员工工资sal比t1表中的所有sal高的就筛出来。
然后挑出来想要的列:

all是比所有的都要怎么怎么样。
any关键字
题目>>any关键字;显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
这里的任意不是指所有,而是指任意一个,也就是找出比30号部门任意一个员工工资高的员工就行。其实就是比最小的工资高了就能满足,这里就不用最小值搞了,直接用any来搞,那么首先搞出来30号部门的所有员工的工资:

然后再筛出来比任意一个高的员工:

sal > any(),就是比任意一个大就行的意思。
any是比任何一个怎么怎么样就行。
多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句。
直接上例子:
题目>>查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
根据题目,首先找出来SMITH的部门和岗位:

这里查出来的数据是多列的,然后直接用where和=来筛选:

其实也可以用in:

这样就能说明多列子查询对于单行和多行都是支持的,只不过用多行的比较少。
在from中使用子查询
将子查询的表放到from后面,一般就是用来进行笛卡尔积的。
再强调一遍,不是只有存放在磁盘中的那个表才算表,只要是用select查询出来的表都是表,这些表都能进行任何的表操作,包括笛卡尔积,子查询的结果也是一个表,也能进行笛卡尔积。
直接上例子:
题目>>显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
首先要搞出来每个部门的平均工资:

下面如何让自己和自己部门的平均工资做对比呢?
上面所讲的多行多列子查询是用不了的,因为自己只能和自己部门对比。
可以将这张表和emp表进行笛卡尔积,连接条件为二者的deptno相同:

然后再拿emp的sal和tmp的avg(sal)做对比,大于的就留下来:

再挑出来题目要求的列:

如果还想要看部门名称,就再拿这个表与emp表进行组合,挑出来dname列就行。
题目>>查找每个部门工资最高的人的姓名、工资、部门、最高工资
这里首先要搞出不同部门的最高工资:

然后再将这个表和emp表进行连接,连接条件为二者的deptno相等:

然后再挑选出来题目所要的列:

题目>>显示每个部门的信息(部门名,编号,地址)和人员数量
部门名、编号、地址都在dept表中,统计人员数量得在emp表中。
先来搞人员数量:

再将这个表和dept表合并,合并条件还是deptno:

再挑选出来需要的列:

注意count(*)要重命名一下,不然会出错。
还有第二种解法。
使用多表。
就是不管三七二十一直接大力出奇迹,反正结果在两张表中,直接将emp表和dept直接拼接到一块,拼接的条件还是二者的deptno:
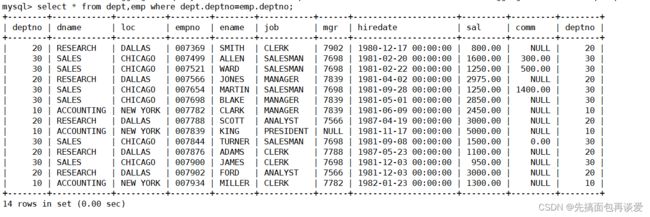
然后再进行聚合统计和:

但是此时如果加上题目要求的部门名、地址的话会出问题:

我这里将完整的报错给出来:
Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'scott.dept.dname' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
其实这里说的是dname没有进行分组排序,所以select后面不能跟上dname这一列,但是这样很扯,因为逻辑上dname绝对是和dept一一对应的,按道理是不需要再进行group by一下,但是语法不支持,还是得加:

同样的地址也得要在后面的order by加上去:

讲到这里就能再次印证一点,所有的表都能进行组合,变成一张表,再根据题目要求对这张合并的表进行后续操作,而且所有的操作都是死的。
那么解决多表问题的本质就是:想办法将多表转化成为单表。
所有的select问题全部都可以转化成单表问题。
合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。
union 和 union all
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
题目>>将工资大于2500或职位是MANAGER的人找出来
很简单,其实可以直接用or:

其实就是将两个完整的select拼接一下:
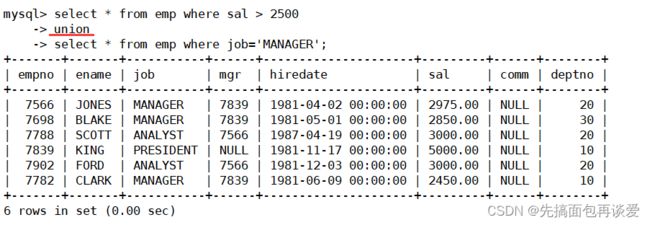
这样如果出现重复的数据(重复的数据是指两个select中相同的记录),用union会自动去重。
如果不想去重的话就用union all:

就是这么简单。
还有一点,用union拼接的时候union两边的表中列数必须是相同的,不相同就会报错:

很好理解,两张表想要拼到一块就是得列数相同。列数不同拼起来会有部分列没有值。
就讲到这里。
到此结束。。。