【Pytorch】Visualization of Fature Maps(2)

学习参考来自
- 使用CNN在MNIST上实现简单的攻击样本
- https://github.com/wmn7/ML_Practice/blob/master/2019_06_03/CNN_MNIST%E5%8F%AF%E8%A7%86%E5%8C%96.ipynb
文章目录
- 在 MNIST 上实现简单的攻击样本
-
- 1 训练一个数字分类网络
- 2 控制输出的概率, 看输入是什么
- 3 让正确的图片分类错误
在 MNIST 上实现简单的攻击样本
要看某个filter在检测什么,我们让通过其后的输出激活值较大。
想要一些攻击样本,有一个简单的想法就是让最后结果中是某一类的概率值变大,接着进行反向传播(固定住网络的参数),去修改input
原理图:
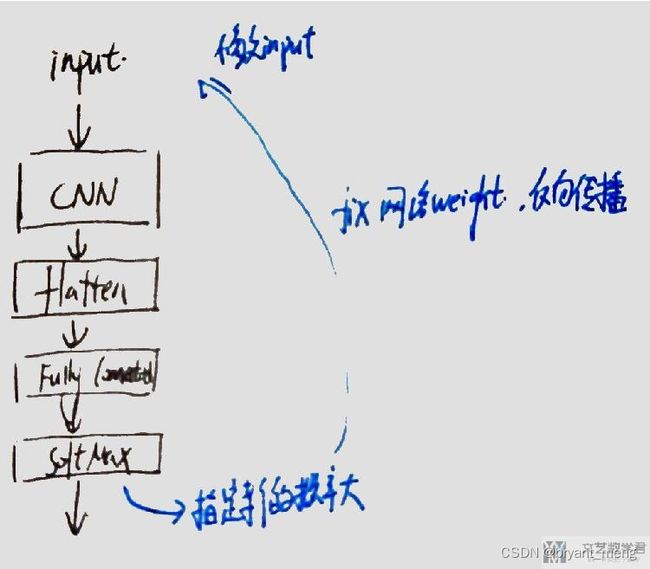
1 训练一个数字分类网络
模型基础数据、超参数的配置
import time
import csv, os
import PIL.Image
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cv2
from cv2 import resize
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data.sampler import SubsetRandomSampler
from torch.autograd import Variable
import copy
import torchvision
import torchvision.transforms as transforms
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
# --------------------
# Device configuration
# --------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# ----------------
# Hyper-parameters
# ----------------
num_classes = 10
num_epochs = 3
batch_size = 100
validation_split = 0.05 # 每次训练集中选出10%作为验证集
learning_rate = 0.001
# -------------
# MNIST dataset
# -------------
train_dataset = torchvision.datasets.MNIST(root='./',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./',
train=False,
transform=transforms.ToTensor())
# -----------
# Data loader
# -----------
test_len = len(test_dataset) # 计算测试集的个数 10000
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
for (inputs, labels) in test_loader:
print(inputs.size()) # [100, 1, 28, 28]
print(labels.size()) # [100]
break
# ------------------
# 下面切分validation
# ------------------
dataset_len = len(train_dataset) # 60000
indices = list(range(dataset_len))
# Randomly splitting indices:
val_len = int(np.floor(validation_split * dataset_len)) # validation的长度
validation_idx = np.random.choice(indices, size=val_len, replace=False) # validatiuon的index
train_idx = list(set(indices) - set(validation_idx)) # train的index
## Defining the samplers for each phase based on the random indices:
train_sampler = SubsetRandomSampler(train_idx)
validation_sampler = SubsetRandomSampler(validation_idx)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
sampler=train_sampler,
batch_size=batch_size)
validation_loader = torch.utils.data.DataLoader(train_dataset,
sampler=validation_sampler,
batch_size=batch_size)
train_dataloaders = {"train": train_loader, "val": validation_loader} # 使用字典的方式进行保存
train_datalengths = {"train": len(train_idx), "val": val_len} # 保存train和validation的长度
搭建简单的神经网络
# -------------------------------------------------------
# Convolutional neural network (two convolutional layers)
# -------------------------------------------------------
class ConvNet(nn.Module):
def __init__(self, num_classes=10):
super(ConvNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2))
self.fc = nn.Linear(7*7*32, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
return out
绘制损失和精度变化曲线
# -----------
# draw losses
# -----------
def draw_loss_acc(train_list, validation_list, mode="loss"):
plt.style.use("seaborn")
# set inter
data_len = len(train_list)
x_ticks = np.arange(1, data_len + 1)
plt.xticks(x_ticks)
if mode == "Loss":
plt.plot(x_ticks, train_list, label="Train Loss")
plt.plot(x_ticks, validation_list, label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.savefig("Epoch_loss.jpg")
elif mode == "Accuracy":
plt.plot(x_ticks, train_list, label="Train AccuracyAccuracy")
plt.plot(x_ticks, validation_list, label="Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.savefig("Epoch_Accuracy.jpg")
定义训练模型的函数
# ---------------
# Train the model
# ---------------
def train_model(model, criterion, optimizer, dataloaders, train_datalengths, scheduler=None, num_epochs=2):
"""传入的参数分别是:
1. model:定义的模型结构
2. criterion:损失函数
3. optimizer:优化器
4. dataloaders:training dataset
5. train_datalengths:train set和validation set的大小, 为了计算准确率
6. scheduler:lr的更新策略
7. num_epochs:训练的epochs
"""
since = time.time()
# 保存最好一次的模型参数和最好的准确率
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
train_loss = [] # 记录每一个epoch后的train的loss
train_acc = []
validation_loss = []
validation_acc = []
for epoch in range(num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, num_epochs))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
if scheduler != None:
scheduler.step()
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0 # 这个是一个epoch积累一次
running_corrects = 0 # 这个是一个epoch积累一次
# Iterate over data.
total_step = len(dataloaders[phase])
for i, (inputs, labels) in enumerate(dataloaders[phase]):
# inputs = inputs.reshape(-1, 28*28).to(device)
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1) # 使用output(概率)得到预测
loss = criterion(outputs, labels) # 使用output计算误差
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if (i + 1) % 100 == 0:
# 这里相当于是i*batch_size的样本个数打印一次, i*100
iteration_loss = loss.item() / inputs.size(0)
iteration_acc = 100 * torch.sum(preds == labels.data).item() / len(preds)
print('Mode {}, Epoch [{}/{}], Step [{}/{}], Accuracy: {}, Loss: {:.4f}'.format(phase, epoch + 1,
num_epochs, i + 1,
total_step,
iteration_acc,
iteration_loss))
epoch_loss = running_loss / train_datalengths[phase]
epoch_acc = running_corrects.double() / train_datalengths[phase]
if phase == 'train':
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
else:
validation_loss.append(epoch_loss)
validation_acc.append(epoch_acc)
print('*' * 10)
print('Mode: [{}], Loss: {:.4f}, Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
print('*' * 10)
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('*' * 10)
print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
print('*' * 10)
# load best model weights
final_model = copy.deepcopy(model) # 最后得到的model
model.load_state_dict(best_model_wts) # 在验证集上最好的model
draw_loss_acc(train_list=train_loss, validation_list=validation_loss, mode='Loss') # 绘制Loss图像
draw_loss_acc(train_list=train_acc, validation_list=validation_acc, mode='Accuracy') # 绘制准确率图像
return (model, final_model)
开始训练,并保存模型
if __name__ == "__main__":
# 模型初始化
model = ConvNet(num_classes=num_classes).to(device)
# 打印模型结构
#print(model)
"""
ConvNet(
(layer1): Sequential(
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(fc): Linear(in_features=1568, out_features=10, bias=True)
)
"""
# -------------------
# Loss and optimizer
# ------------------
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# -------------
# 进行模型的训练
# -------------
(best_model, final_model) = train_model(model=model, criterion=criterion, optimizer=optimizer,
dataloaders=train_dataloaders, train_datalengths=train_datalengths,
num_epochs=num_epochs)
"""
Epoch [1/3]
----------
Mode train, Epoch [1/3], Step [100/570], Accuracy: 96.0, Loss: 0.0012
Mode train, Epoch [1/3], Step [200/570], Accuracy: 96.0, Loss: 0.0011
Mode train, Epoch [1/3], Step [300/570], Accuracy: 100.0, Loss: 0.0004
Mode train, Epoch [1/3], Step [400/570], Accuracy: 100.0, Loss: 0.0003
Mode train, Epoch [1/3], Step [500/570], Accuracy: 96.0, Loss: 0.0010
**********
Mode: [train], Loss: 0.1472, Acc: 0.9579
**********
**********
Mode: [val], Loss: 0.0653, Acc: 0.9810
**********
Epoch [2/3]
----------
Mode train, Epoch [2/3], Step [100/570], Accuracy: 99.0, Loss: 0.0005
Mode train, Epoch [2/3], Step [200/570], Accuracy: 98.0, Loss: 0.0003
Mode train, Epoch [2/3], Step [300/570], Accuracy: 98.0, Loss: 0.0003
Mode train, Epoch [2/3], Step [400/570], Accuracy: 97.0, Loss: 0.0005
Mode train, Epoch [2/3], Step [500/570], Accuracy: 98.0, Loss: 0.0004
**********
Mode: [train], Loss: 0.0470, Acc: 0.9853
**********
**********
Mode: [val], Loss: 0.0411, Acc: 0.9890
**********
Epoch [3/3]
----------
Mode train, Epoch [3/3], Step [100/570], Accuracy: 99.0, Loss: 0.0006
Mode train, Epoch [3/3], Step [200/570], Accuracy: 99.0, Loss: 0.0009
Mode train, Epoch [3/3], Step [300/570], Accuracy: 98.0, Loss: 0.0004
Mode train, Epoch [3/3], Step [400/570], Accuracy: 99.0, Loss: 0.0003
Mode train, Epoch [3/3], Step [500/570], Accuracy: 100.0, Loss: 0.0002
**********
Mode: [train], Loss: 0.0348, Acc: 0.9890
**********
**********
Mode: [val], Loss: 0.0432, Acc: 0.9867
**********
**********
Training complete in 0m 32s
Best val Acc: 0.989000
**********
"""
torch.save(model, 'CNN_MNIST.pkl')
训练完的 loss 和 acc 曲线
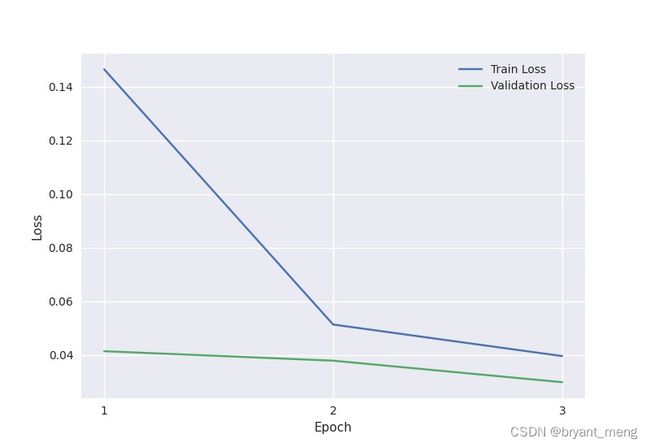

载入模型进行简单的测试,以下面这张 7 为例子

model = torch.load('CNN_MNIST.pkl')
# print(test_dataset.data[0].shape) # torch.Size([28, 28])
# print(test_dataset.targets[0]) # tensor(7)
#
unload = transforms.ToPILImage()
img = unload(test_dataset.data[0])
img.save("test_data_0.jpg")
# 带入模型进行预测
inputdata = test_dataset.data[0].view(1,1,28,28).float()/255
inputdata = inputdata.to(device)
outputs = model(inputdata)
print(outputs)
"""
tensor([[ -7.4075, -3.4618, -1.5322, 1.1591, -10.6026, -5.5818, -17.4020,
14.6429, -4.5378, 1.0360]], device='cuda:0',
grad_fn=)
"""
print(torch.max(outputs, 1))
"""
torch.return_types.max(
values=tensor([14.6429], device='cuda:0', grad_fn=),
indices=tensor([7], device='cuda:0'))
"""
OK,预测结果正常,为 7
2 控制输出的概率, 看输入是什么
步骤
- 初始随机一张图片
- 我们希望让分类中某个数的概率最大
- 最后看一下这个网络认为什么样的图像是这个数字
# hook类的写法
class SaveFeatures():
"""注册hook和移除hook
"""
def __init__(self, module):
self.hook = module.register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
# self.features = output.clone().detach().requires_grad_(True)
self.features = output.clone()
def close(self):
self.hook.remove()
下面开始操作
# hook住模型
layer = 2
activations = SaveFeatures(list(model.children())[layer])
# 超参数
lr = 0.005 # 学习率
opt_steps = 100 # 迭代次数
upscaling_factor = 10 # 放大的倍数(为了最后图像的保存)
# 保存迭代后的数字
true_nums = []
random_init, num_init = 1, 0 # the type of initial
# 带入网络进行迭代
for true_num in range(0, 10):
# 初始化随机图片(数据定义和优化器一定要在一起)
# 定义数据
sz = 28
if random_init:
img = np.uint8(np.random.uniform(0, 255, (1,sz, sz))) / 255
img = torch.from_numpy(img[None]).float().to(device)
img_var = Variable(img, requires_grad=True)
if num_init:
# 将7变成0,1,2,3,4,5,6,7,8,9
img = test_dataset.data[0].view(1, 1, 28, 28).float() / 255
img = img.to(device)
img_var = Variable(img, requires_grad=True)
# 定义优化器
optimizer = torch.optim.Adam([img_var], lr=lr, weight_decay=1e-6)
for n in range(opt_steps): # optimize pixel values for opt_steps times
optimizer.zero_grad()
model(img_var) # 正向传播
if random_init:
loss = -activations.features[0, true_num] # 这里的loss确保某个值的输出大
if num_init:
loss = -activations.features[0, true_num] + F.mse_loss(img_var, img) # 这里的loss确保某个值的输出大, 并且与原图不会相差很多
loss.backward()
optimizer.step()
# 打印最后的img的样子
print(activations.features[0, true_num]) # tensor(23.8736, device='cuda:0', grad_fn=)
print(activations.features[0])
"""
tensor([ 23.8736, -32.0724, -5.7329, -18.6501, -16.1558, -18.9483, -0.3033,
-29.1561, 14.9260, -13.5412], device='cuda:0',
grad_fn=)
"""
print('========')
img = img_var.cpu().clone()
img = img.squeeze(0)
# 图像的裁剪(确保像素值的范围)
img[img > 1] = 1
img[img < 0] = 0
true_nums.append(img)
unloader = transforms.ToPILImage()
img = unloader(img)
img = cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
sz = int(upscaling_factor * sz) # calculate new image size
img = cv2.resize(img, (sz, sz), interpolation=cv2.INTER_CUBIC) # scale image up
if random_init:
cv2.imwrite('random_regonize{}.jpg'.format(true_num), img)
if num_init:
cv2.imwrite('real7_regonize{}.jpg'.format(true_num), img)
"""
========
tensor(22.3530, device='cuda:0', grad_fn=)
tensor([-22.4025, 22.3530, 6.0451, -9.4460, -1.0577, -17.7650, -11.3686,
-11.8474, -5.5310, -16.9936], device='cuda:0',
grad_fn=)
========
tensor(50.2202, device='cuda:0', grad_fn=)
tensor([-16.9364, -16.5120, 50.2202, -9.5287, -25.2837, -32.3480, -22.8569,
-20.1231, 1.1174, -31.7244], device='cuda:0',
grad_fn=)
========
tensor(48.8004, device='cuda:0', grad_fn=)
tensor([-33.3715, -30.5732, -6.0252, 48.8004, -34.9467, -17.8136, -35.1371,
-17.4484, 2.8954, -11.9694], device='cuda:0',
grad_fn=)
========
tensor(31.5068, device='cuda:0', grad_fn=)
tensor([-24.5204, -13.6857, -5.1833, -22.7889, 31.5068, -20.2855, -16.7245,
-19.1719, 2.4699, -16.2246], device='cuda:0',
grad_fn=)
========
tensor(37.4866, device='cuda:0', grad_fn=)
tensor([-20.2235, -26.1013, -25.9511, -2.7806, -19.5546, 37.4866, -10.8689,
-30.3888, 0.1591, -8.5250], device='cuda:0',
grad_fn=)
========
tensor(35.9310, device='cuda:0', grad_fn=)
tensor([ -6.1996, -31.2246, -8.3396, -21.6307, -16.9098, -9.5194, 35.9310,
-33.0918, 10.2462, -28.6393], device='cuda:0',
grad_fn=)
========
tensor(23.6772, device='cuda:0', grad_fn=)
tensor([-21.5441, -10.3366, -4.9905, -0.9289, -6.9219, -23.5643, -23.9894,
23.6772, -0.7960, -16.9556], device='cuda:0',
grad_fn=)
========
tensor(57.8378, device='cuda:0', grad_fn=)
tensor([-13.5191, -53.9004, -9.2996, -10.3597, -27.3806, -27.5858, -15.3235,
-46.7014, 57.8378, -17.2299], device='cuda:0',
grad_fn=)
========
tensor(37.0334, device='cuda:0', grad_fn=)
tensor([-26.2983, -37.7131, -16.6210, -1.8686, -11.5330, -11.7843, -25.7539,
-27.0036, 6.3785, 37.0334], device='cuda:0',
grad_fn=)
========
"""
# 移除hook
activations.close()
for i in range(0,10):
_ , pre = torch.max(model(true_nums[i][None].to(device)),1)
print("i:{},Pre:{}".format(i,pre))
"""
i:0,Pre:tensor([0], device='cuda:0')
i:1,Pre:tensor([1], device='cuda:0')
i:2,Pre:tensor([2], device='cuda:0')
i:3,Pre:tensor([3], device='cuda:0')
i:4,Pre:tensor([4], device='cuda:0')
i:5,Pre:tensor([5], device='cuda:0')
i:6,Pre:tensor([6], device='cuda:0')
i:7,Pre:tensor([7], device='cuda:0')
i:8,Pre:tensor([8], device='cuda:0')
i:9,Pre:tensor([9], device='cuda:0')
"""

可以看到相应最高的图片的样子,依稀可以看见 0,1,2,3,4,5,6,7,8,9 的轮廓
3 让正确的图片分类错误
步骤如下
- 使用特定数字的图片,如数字7(初始化方式与前面的不一样,是特定而不是随机)
- 使用上面训练好的网络,固定网络参数;
- 最后一层因为是10个输出(相当于是概率), 我们 loss 设置为某个的负的概率值(利于梯度下降)
- 梯度下降, 使负的概率下降,即相对应的概率值上升,我们最终修改的是初始的图片
- 这样使得网络认为这张图片识别的数字的概率增加
简单描述,输入图片数字7,固定网络参数,让其他数字的概率不断变大,改变输入图片,最终达到迷惑网络的目的
只要将第二节中的代码 random_init, num_init = 1, 0 # the type of initial 改为 random_init, num_init = 0, 1 # the type of initial 即可

成功用 7 迷惑了所有类别
注意损失函数中还额外引入了 F.mse_loss(img_var, img) ,确保某个数字类别的概率输出增大, 并且与原图数字 7 像素上不会相差很多