mysql 同步数据到 hdfs问题分析
datax hdfswriter 的部分问题
Permission denied: user=xxxxx 用户权限问题
windows下 hdfs目录被删除问题
背景: 准备用 datax 从 mysql 同步数据到 hdfs , 记录下 遇到的问题,及解决思路
先测试将本txt地文件同步到hdfs
json job :
{
"setting": {},
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "txtfilereader",
"parameter": {
"path": ["../job/demo.txt"],
"encoding": "UTF-8",
"column": [
{
"index": 0,
"type": "STRING"
},
{
"index": 1,
"type": "long"
},
{
"index": 2,
"type": "DOUBLE"
},
{
"index": 3,
"type": "date"
}
],
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://139.9.xxx.157:9000",
"fileType": "text",
"path": "/data",
"fileName": "demo.txt",
"column": [
{
"name": "姓名",
"type": "VARCHAR"
},
{
"name": "年龄",
"type": "TINYINT"
},
{
"name": "身高",
"type": "DOUBLE"
},
{
"name": "日期",
"type": "date"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
}
}
}
]
}
}
文件内容
张三 20 179.5 2021-01-01
李四 22 179.5 2020-08-01
王五 25 172.0 2020-12-08
赵六 29 169.8 2020-10-20

运行报错:

Permission denied: user=xxxxx, access=WRITE, inode="/data":root:supergroup:drwxr-xr-x
这一看就是 用户权限问题,网上稍微搜了下,结合源码

翻译注释:如果我们没有kerberos用户并且安全性已禁用,请检查//是否在环境或属性中指定了user
解决办法,可以在jvm环境或者系统环境设置 HADOOP_USER_NAME 用户
两种解决办法:
1、jvm环境设置用户 , 简单点就直接在 python 脚本的启动参数上添加(如下) 。当然也可以改源码,或者改python脚本
python datax.py -p "-DHADOOP_USER_NAME=xxx" .xxxjob.json
2、系统环境设置用户
//linux
vim /etc/profile
export HADOOP_USER_NAME=xxx
source /etc/profile
//windows cmd
set HADOOP_USER_NAME=xxx
//查看一下是否成功
echo %HADOOP_USER_NAME%
//也可以直接在环境变量窗口里改,但是好像得重启才生效
使用第一种:
![]()
执行成功:
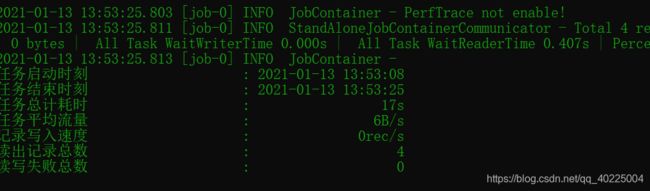
上hdfs查看一下

。。。。。。我淦,目录不见了,上网搜了下,windows下确定存在这种问题。
问题原因就是:上传文件 demo.txt 时,在文件上层生成了一个临时父目录 ,然后完成上传后删除临时父目录。
但是windows环境的文件分隔符是 \ ,所以找父目录时直接找到了之上的一层目录。
理想情况 : / data / temp / demo.txt -> 要删除的父目录 / data/ temp /
实际情况 :/ data / temp \ demo.txt -> 要删除的父目录 / data /
源码调试截图:HdfsHelper 类中

寻找父路径


删除

修改意见: 自定义分隔符 dirSeparator,默认为 IOUtils.DIR_SEPARATOR_UNIX , 替换 原来的 IOUtils.DIR_SEPARATOR,如果确实有windows服务端情况,可通过自定义jvm参数 -Ddir_separator=\ 修改
修改 HdfsWriter 类中 265 - 326行 为如下
//自定义分隔符,默认DIR_SEPARATOR_UNIX
//可以通过定义jvm参数 dir_separator修改
static Character dirSeparator;
static {
dirSeparator = Optional.ofNullable(System.getProperty("dir_separator"))
.map(i -> i.toCharArray()[0]).orElse(IOUtils.DIR_SEPARATOR_UNIX);
}
private String buildFilePath() {
boolean isEndWithSeparator = false;
switch (dirSeparator) {
case IOUtils.DIR_SEPARATOR_UNIX:
isEndWithSeparator = this.path.endsWith(String
.valueOf(IOUtils.DIR_SEPARATOR_UNIX));
break;
case IOUtils.DIR_SEPARATOR_WINDOWS:
isEndWithSeparator = this.path.endsWith(String
.valueOf(IOUtils.DIR_SEPARATOR_WINDOWS));
break;
default:
break;
}
if (!isEndWithSeparator) {
this.path = this.path + dirSeparator;
}
return this.path;
}
/**
* 创建临时目录
*
* @param userPath
* @return
*/
private String buildTmpFilePath(String userPath) {
String tmpFilePath;
boolean isEndWithSeparator = false;
switch (dirSeparator) {
case IOUtils.DIR_SEPARATOR_UNIX:
isEndWithSeparator = userPath.endsWith(String
.valueOf(IOUtils.DIR_SEPARATOR_UNIX));
break;
case IOUtils.DIR_SEPARATOR_WINDOWS:
isEndWithSeparator = userPath.endsWith(String
.valueOf(IOUtils.DIR_SEPARATOR_WINDOWS));
break;
default:
break;
}
String tmpSuffix;
tmpSuffix = UUID.randomUUID().toString().replace('-', '_');
if (!isEndWithSeparator) {
tmpFilePath = String.format("%s__%s%s", userPath, tmpSuffix, dirSeparator);
} else if ("/".equals(userPath)) {
tmpFilePath = String.format("%s__%s%s", userPath, tmpSuffix, dirSeparator);
} else {
tmpFilePath = String.format("%s__%s%s", userPath.substring(0, userPath.length() - 1), tmpSuffix, dirSeparator);
}
while (hdfsHelper.isPathexists(tmpFilePath)) {
tmpSuffix = UUID.randomUUID().toString().replace('-', '_');
if (!isEndWithSeparator) {
tmpFilePath = String.format("%s__%s%s", userPath, tmpSuffix, dirSeparator);
} else if ("/".equals(userPath)) {
tmpFilePath = String.format("%s__%s%s", userPath, tmpSuffix, dirSeparator);
} else {
tmpFilePath = String.format("%s__%s%s", userPath.substring(0, userPath.length() - 1), tmpSuffix, dirSeparator);
}
}
return tmpFilePath;
}
}
重新打包:


打包完的jar包 替换到原来的plugin\writer\hdfswriter中
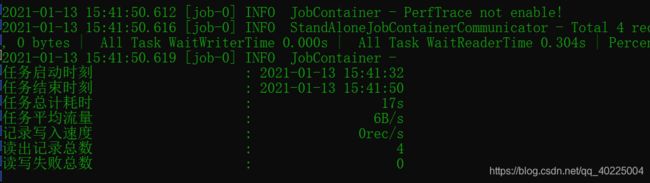
再次尝试
![]()
执行成功:
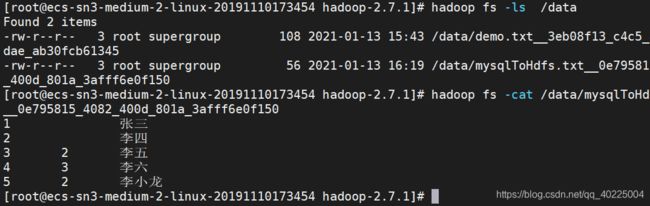
上hdfs查看一下

也成功上传,目录没有被删除。另外,如果出现多个文件 可以把json中job中的channel改为1的
再测试从 hdfs 读数据到内存中再打印
{
"job": {
"setting": {
"speed": {
"channel": 3
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/data/*",
"defaultFS": "hdfs://139.9.xxx.157:9000",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "long"
},
{
"index": 2,
"type": "double"
},
{
"index": 3,
"type": "string"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": true
}
}
}
]
}
}
很顺利,成功:

最后再测试从 mysql 同步数据到 hdfs
json:文件
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "xxxx",
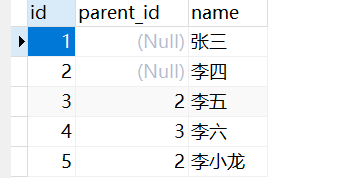
"column": [
"id",
"parent_id",
"name"
],
"splitPk": "id",
"connection": [
{
"table": [
"di"
],
"jdbcUrl": [
"jdbc:mysql://localhost:3306/xxxxx"
]
}
]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://139.9.xxx.157:9000",
"fileType": "text",
"path": "/data/",
"fileName": "mysqlToHdfs.txt",
"column": [
{
"name": "id",
"type": "BIGINT"
},
{
"name": "parent_id",
"type": "BIGINT"
},
{
"name": "姓名",
"type": "VARCHAR"
}
],
"writeMode": "append",
"fieldDelimiter": "\t",
}
}
}
]
}
}
执行:

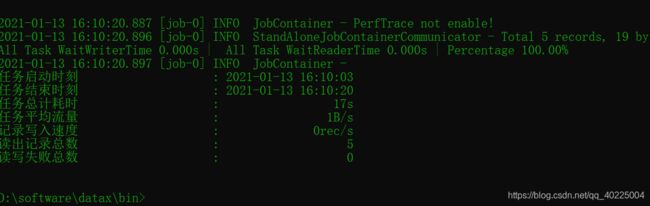
上hdfs查看一下