【NLP】LLM 中 100K 上下文窗口背后的秘密:所有技巧都集中在一处
加速 LLM 训练和推理的技术,在训练和推理期间使用高达 100K 输入标记的大型上下文窗口:ALiBi 位置嵌入、稀疏注意力、FlashAttention、多查询注意力、条件计算和 80GB A100 GPU。
最近有几项关于新的大型语言模型 (LLM) 的公告,它可以消耗极大的上下文窗口,例如65K toke MosaicML 的(MosaicML 的MPT-7B-StoryWriter-65k+ )甚至 100K token(Antropic 的100K 上下文窗口介绍)。在 Palm-2技术报告中,Google 没有透露上下文大小,但提到他们“显着增加了模型的上下文长度”。
作为比较,当前的 GPT-4 模型可以处理32K 输入标记的上下文长度。而且大多数开源LLM的上下文长度都是2K token。
这令人印象深刻,因为上下文长度如此之大意味着提示实际上可以有书本那么大。《了不起的盖茨比》共 72K 个代币,210 页,以 1.7 分钟/页的速度阅读需要 6 小时。因此,模型可以扫描并保留大量“自定义”信息来处理查询!
我试图弄清楚这在技术上是如何实现的,因此在这篇博文中,我收集了零散的信息并涵盖以下内容:
- 为什么上下文长度很重要以及为什么它可以改变游戏规则
- 在处理大上下文长度时,原始Transformer 架构的主要限制是什么
- Transformer 架构的计算复杂度
- 目前有哪些优化技术可以加速 Transformer 并将上下文长度增加到 100K
简短的摘要
在这里和后面,我们互换使用“上下文长度”、“上下文窗口”和“输入标记的数量”,将它们表示为n。
博文有点长,所以总结一下要点和技巧:
- 第一个问题是注意层计算与输入标记n的数量相关的二次时间和空间复杂度。
- 当嵌入大小d > n时,第二个问题是线性层与嵌入大小d的二次时间复杂度。
- 第三个问题是原始架构中使用的位置正弦嵌入。
- 在 Transformer 架构中,可学习矩阵权重的形状与输入标记n的数量无关 。
- 因此,一个训练有素的 Transformer 在 2K 上下文长度中可以消耗任意长度的令牌,甚至100K。但如果未经训练,模型在推理过程中不会对 100K 个标记产生有意义的结果 100K。
- 由于n和d的二次复杂度,在巨大的语料库上并且仅在较大的上下文长度上训练普通 Transformer 的成本昂贵得不切实际。2K 上下文长度的 LLaMA训练成本估计约为 300 万美元。因此,100K 上的 LLaMA 将花费约1.5 亿美元。
- 一种选择是在 2K 令牌上下文中训练模型,然后在更长的上下文(例如 65K)中对其进行微调。但由于位置正弦编码,它无法与原始 Transformer 一起使用。
- [技巧#1]要解决这个问题,请删除位置正弦编码并使用ALiBi,这是一种简单而优雅的位置嵌入,不会影响准确性。然后你可以在 2K 上训练并在 100K 上进行微调。
- [技巧#2]您不需要计算所有标记之间的注意力分数。有些标记比其他标记更重要,因此可以使用稀疏注意力。它将加速训练和推理。
- [技巧#3] Flash Attention有效地实现了 GPU 的注意力层。它使用平铺并避免具体化不适合 GPU SRAM的大型中间矩阵(n, n) 。它将加速训练和推理。
- [技巧#4]多查询注意力而不是多头注意力。这意味着在线性投影 K 和 V 时,您可以在所有头之间共享权重。它极大地 加快了增量推理速度。
- [技巧#5] 条件计算避免将所有模型参数应用于输入序列中的所有标记。CoLT5仅对最重要的令牌应用大量计算,并使用较轻版本的层处理其余令牌。它将加速训练和推理。
- [技巧#6]为了适应大型环境,GPU 中需要大量 RAM,因此人们使用 80GB A100 GPU。
综上所述,训练和推理速度越快,可以使用的上下文长度就越大。
现在让我们更详细地讨论所有这些要点。
为什么上下文长度很重要
上下文长度是法学硕士的关键限制之一。将其增加到 100K 是一项令人难以置信的成就(我想知道一年后这个声明会是什么样子)。
人们想要申请法学硕士的重要用例之一是“将大量自定义数据放入法学硕士”(与公司或特定问题相关的文档、各种异构文本等)并提出有关该特定数据的问题,不是LLM在培训期间看到的一些来自互联网的抽象数据。
为了克服这个限制,人们现在做了很多事情:
- 尝试总结技巧和复杂的连锁提示
- 维护矢量数据库以保留自定义文档的嵌入,然后通过某些相似性度量在它们之间“搜索”
- 尽可能使用自定义数据微调 LLM(并非所有商业 LLM 都允许这样做,对于开源 LLM 来说这也不是一项明显的任务)
- 为这个特定的数据开发定制的较小的法学硕士(同样,这不是一个明显的任务)
拥有较大的上下文长度可以让已经很强大的LLM(看到整个互联网)查看您的上下文和数据,并在完全不同的层面上以更高的个性化与您互动。所有这些都无需改变模型的权重,也无需在“内存中”即时进行“训练”。总的来说,大的上下文窗口为模型带来了更高的准确性、流畅性和创造力。
这里的一个类比可能是计算机 RAM,操作系统在其中保存所有应用程序的实时上下文。凭借大量的上下文长度,法学硕士可以像一台“推理计算机”一样,保留大量的用户上下文。
原始 Transformer 和上下文长度
值得注意的是,在 Transformer 架构中,所有可学习矩阵权重的形状并不依赖于输入标记 n的数量。所有可训练参数(嵌入查找、投影层、softmax 层和注意层)都不依赖于输入长度,并且必须处理可变长度输入。我们拥有该体系结构的开箱即用属性,这真是太好了。
这意味着如果您训练上下文长度为 2K 的 Transformer 模型,您可以推断出任何大小的标记序列。唯一的问题是,如果模型未 在 100K 上下文长度上进行训练,则在推理过程中模型将不会在 100K 标记上产生有意义的结果。在这种情况下,训练数据分布将与推理过程中的分布相差甚远,因此该模型将像此设置中的任何机器学习模型一样失败。
训练大上下文长度 Transformer 的一种解决方案是分两个阶段进行训练:在 2K 令牌上下文长度上训练基本模型,然后在更长的上下文(例如 65K 或 100K)上继续训练(微调)。这正是 MosaicML所做的。但问题是它不适用于原始的 Transformer 架构,因此您需要使用一些技巧(请参阅帖子后面的技巧#1)。
回顾多头注意力
大上下文长度的挑战与变压器架构的计算复杂性有关。为了讨论复杂性,首先让我们回顾一下注意力层的工作原理。
Q —查询,K — 键和V — 值,来自与信息检索相关的论文的符号,其中您向系统插入“查询”并搜索最接近的“键”
n — 输入的标记数
d — 文本嵌入维度
h — 注意力头的数量
k — Q 和 K 的线性投影大小
v — V 的线性投影大小
多头注意力:
- 我们有一个查找嵌入层,对于给定的标记,返回大小为(1, d)的向量。因此,对于n 个标记的序列,我们得到大小为(n, d)的文本嵌入矩阵X。然后我们用位置正弦嵌入来总结它。
- 多头注意力层旨在计算该令牌序列的新嵌入,该令牌序列可以被视为编码 X 的原始文本,但通过令牌之间相对于上下文的相对重要性进行加权(1),以及(2)通过代币。
- 我们与h 个注意层(头)并行处理这个嵌入矩阵 X (n, d) 。为了获得所有注意力头的Q、K和V,您可以分别将 X 线性投影到k、k和v维度。您可以通过将 X 乘以形状为(d, k)、(d, k)和(d, v)的h矩阵来实现。您可以将其视为(n, d)乘以(h, d, k)、(h, d, k)和(h, d, v)。
- 注意力头返回h个大小为(n, v)的注意力分数矩阵。然后我们连接所有头(n,h*v)的片段并线性投影它以用于下一步。

注意力架构的高级模式来自《Attention is All You Need》论文
缩放点积注意力:
现在,让我们放大一个注意力头。
- Q、K、V是大小为 (n, k)、(n, k)和(n, v)的X的 3 个线性投影,通过乘以每个头 单独的可学习权重而获得。
- 我们通过计算Q和K (转置)之间的距离(点积)来获得注意力分数。将矩阵(n, k)乘以(k, n)并得到矩阵(n, n)。然后我们将其乘以掩码矩阵,将一些标记归零(解码器中需要)。然后我们对其进行缩放并应用 softmax 从 0 到 1。这样,我们得到形状为(n, n)的矩阵,其中n_ij - 第i和第 j标记之间从 0 到 1 的相对注意力分数显示这些标记在长度为n的特定上下文中的“接近”程度。
- 然后,我们将此注意力分数矩阵(n, n)乘以大小为(n, d)的“值”V ,以获得由这些相对注意力分数加权的文本嵌入。

原论文中,一个头中的Attention Score矩阵就是通过这个公式计算的。
让我们看一下多查询注意力论文中的这段代码。它展示了如何通过批处理计算多头注意力,并且每一步的形状都很清晰。它们还包括解码期间使用的掩码乘法。

一个非常好的代码,显示了注意力层中每个步骤的形状。来自多查询论文。
Transformer 的复杂性和上下文长度
2 个矩阵乘法 (a,b)*(b,c) 的复杂度为O(a*b*c)。为了简单
起见,我们假设k*h = O(d) ,我们将用它来推导注意力的复杂性。
注意力层的复杂度由两部分组成:
- 线性投影以获得 Q、K、V:大小为(n, d)的嵌入矩阵乘以h 个可学习矩阵(d, k)、(d, k)和(d, v)。因此,复杂度 ~ O(nd²)
- Q乘以K进行变换,然后乘以V:(n,k) * (k,n) = (n,n)和(n,n)*(n,v) = (n,v)。复杂度 ~ O(n²d)
因此,注意力层的复杂度为O(n²d + nd²),其中n — 是上下文长度(输入标记的数量),d — 嵌入大小。因此,从这里我们可以看到,注意力层计算的复杂度是输入标记数量n 的二次方,也是嵌入大小 d 的二次方。
当 d > n 时, O(nd²)项很重要(例如,在 LLaMa 中,n=2K 且 d=4K)。当 n > d 时, O(n²d)
项很重要(例如,使用 n=65K 和 d=4K 训练 MosaicML)。
只是提醒您二次增长有多糟糕:
2 000² = 4 000 000,100 000² = 10 000 000 000。
让我举一个例子来说明这种二次复杂性如何影响模型训练的价格。训练 LLaMa 的估计价格约为300万美元,它有 65B 个参数、2K 上下文长度和 4K 嵌入大小。预计时间主要是GPU训练时间。如果我们将上下文长度从 2K 增加到 100K (50 倍),训练时间也会增加约 50 倍(我们需要更少的迭代,因为上下文更大,但每次需要更长的时间)。因此,在 100K 上下文中训练 LLaMA 将花费约1.5 亿美元。
有关此计算的一些详细信息:
对于令牌数量等于n的情况,注意力的复杂度为O(n²d + nd²),需要M次迭代来训练。如果我们从n → p*n增加上下文长度,则需要M/p次迭代,因为上下文长度变得更大(为了简单起见,我们假设它是线性的,根据任务的不同,它可能是高估或低估)。现在我们有 2 个方程:
(1) n ~ M * (n²d + nd²)
的复杂性(2) p*n ~ M/p * ((p*n)²d + (p*n)d²) 的 复杂性一系列简化和除法,比率 (2)/(1) ~ (d + p*n)/(d + n)如果d << n,则将n增加p倍将导致迭代次数增加约 p 倍。
如果d ~ n,则将n增加p倍将导致迭代次数增加 ~ p/2 倍。
Transformer 中训练阶段和推理阶段的区别
在深入研究优化技术之前要讨论的最后一件事是训练和推理过程中计算的差异。
在训练期间,您可以并行运行,而对于推理期间的文本生成,您需要按顺序执行,因为下一个标记取决于前一个标记。实现推理的直接方法是增量计算注意力分数并缓存以前的结果以用于将来的标记。
这种区别带来了加速训练和推理的不同方法。这就是为什么下面的一些技巧会优化两个阶段,但有些技巧只会优化推理。
增加上下文长度的优化技术
现在,让我们来谈谈研究人员如何克服所有这些挑战并能够培养具有大背景长度的LLM。
[技巧#1]更好的位置编码——ALiBi
训练大上下文长度 Transformer 的一种解决方案是分两个阶段进行训练:在 2K 令牌上下文长度上训练基本模型,然后在更长的上下文(例如 65K)上进行微调。但之前,我们说过它不适用于原始的 Transformer 架构。为什么?
因为位置正弦编码没有“外推”能力。在ALiBI [4] 论文中,作者表明位置正弦编码对于推理过程中上下文窗口的扩展并不鲁棒。更多令牌后,性能开始下降。因此,缺乏“外推”能力基本上意味着您在推理/微调期间不能使用比训练期间更大的上下文长度。术语“外推”和各种位置编码的比较在[4]中描述。
在最初的 Transformer 论文中,Positional Sinusoidal Embedding 与架构底部的 token Embeddings 相加,以添加有关单词顺序的信息。
因此,第一个技巧是删除位置正弦嵌入并将其替换为另一个位置嵌入 -带线性偏差的注意力(ALiBI)。
它应用于注意力头(而不是网络底部),并且它以与距离成正比的惩罚来偏置查询键注意力分数(在 softmax 之前)。
![]()
这个技巧可以加快训练速度。
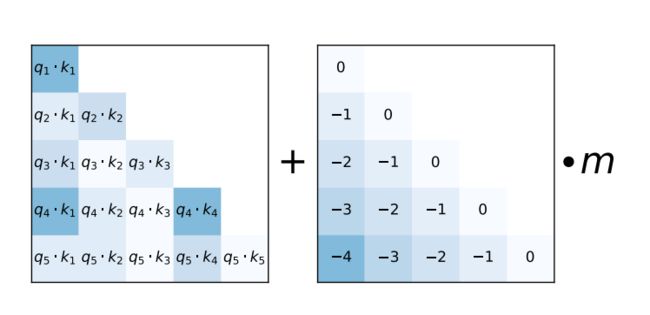
当计算每个头的注意力分数时,ALiBi 为每个注意力分数(qi·kj,左)添加一个常数偏差(右)。与在未修改的注意力子层中一样,softmax 函数随后应用于这些分数,其余计算未修改。m 是一个特定于头部的标量,它是在整个训练过程中设置的而不是学习的。来自ALiBI 论文。
[技巧#2] 稀疏注意力
并非大小为 100K 的上下文中的所有令牌都彼此相关。减少计算次数的一种方法是在计算注意力分数时仅考虑一些标记。添加稀疏性的目标是使计算与 n 呈线性关系,而不是二次关系。有多种方法可以选择令牌之间的连接,Google博客文章对此有一个很好的说明:
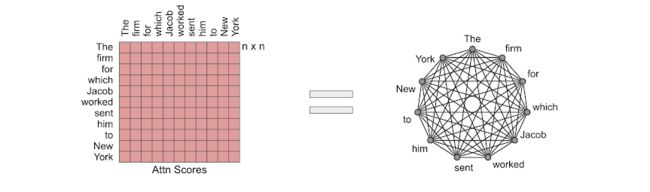
完全注意力可以看作是一个完整的图。稀疏注意力方法

稀疏注意力方法
例如,滑动窗口注意力(也称为本地注意力)在每个标记周围采用固定大小的窗口注意力。在此注意力模式中,给定固定的窗口大小w ,每个标记在每一侧关注w /2 个标记。此模式的计算复杂度为O(n*w),其随输入序列长度n线性缩放。为了提高效率,w应该比n小。诀窍在于,注意力信息在近标记内“流动”整个上下文窗口,近似完整的图。
BigBird注意力评分方法结合了全局、局部和随机机制。在论文中,作者展示了一个重要的观察结果,即计算出的相似度分数与不同节点之间的信息流(即一个令牌相互影响的能力)之间存在固有的张力。
这个技巧可以加快训练和推理的速度。
[技巧#3] FlashAttention — GPU 注意力层的高效实现
注意力层中有几个计算操作被一遍又一遍地重复:
- S = Q*K
- P = softmax(S)
- O = P*V
记住P、S和O结果的概念;我们稍后会用到它。FlashAttention作者“融合”了这些操作:他们实现了一种注意力层算法,可以有效地利用 GPU 内存并计算出准确的注意力。
为了让 GPU 执行操作,输入数据必须存在于名为 SRAM 的“快速”存储器中。数据从“慢速”HBM 内存复制到 SRAM,并在计算结束后返回到 HBM。SRAM 内存比 HBM 快得多,但尺寸小得多(A100 40GB GPU 中为 20MB,而 A100 40GB GPU 为 40GB)。

A100 GPU 内存层次结构。FlashAttention
因此,访问 HBM 是一项昂贵的操作。
注意力层中关于 GPU 内存利用率的主要问题是“中间”乘法结果P、S和O,它们的大小(n, n)很大。我们需要将它们保存到 HBM 并在注意力操作之间再次读取它们。将 P、S 和 O 从 HBM 到 SRAM 来回移动是瓶颈,作者在论文中解决了这个问题。
FlashAttention 算法背后的主要思想是将输入 Q、K 和 V 矩阵分割成块,将这些块从 HBM 加载到 SRAM,然后计算这些块的注意力输出。此过程称为平铺。

左图: FlashAttention 使用平铺来防止大型 n × n 注意力矩阵(虚线框)o HBM 的具体化。在外部循环(红色箭头)中,FlashAttention 循环遍历 K 和 V 矩阵块并将它们加载到 SRAM。在每个块中,FlashAttention 循环遍历 Q 矩阵块(蓝色箭头),将它们加载到 SRAM,并将注意力计算的输出写回 HBM。右:7.6 倍加速。FlashAttention
“矩阵乘法”运算已经针对 GPU 进行了优化。您可能会认为 FlashAttention 算法是实现针对 GPU 优化的“注意力层”操作。作者将多个乘法和 softmax 运算与平铺和优化的 HBM 访问“融合”。
FlashAttention论文有很好的概述。
最近,PyTorch 2.0内置了 flash- attention。这是作者用Triton 语言实现的FlashAttention 。
这个技巧可以加快训练和推理的速度。
[技巧#4] 多查询注意力(MQA)
原始的多头注意力(MHA)在每个头中都有一个单独的 K 和 V 矩阵线性层。
在推理过程中,解码器中先前令牌的键和值会被缓存以防止重新计算它们,因此GPU 内存使用量会随着每个生成的令牌而增加。
多查询注意力(MQA)是一种优化,建议在线性投影 K 和 V 时在所有注意力头之间共享权重,因此我们只需要保留 2 个大小为 (n, k)和(n, v)的矩阵。一个大模型最多可以有 96 个头(例如 GPT-3),这意味着使用 MQA 可以节省 96 倍的键/值解码器缓存的内存消耗。
这种优化在生成长文本时特别有用。例如,上下文长度较长并要求进行长而有意义的分析或总结。
这种方法的主要优点是在推理过程中显着加快增量注意力分数的计算。训练速度基本保持不变。例如,PaLM 正在使用它。
[技巧#5]条件计算
当d > n时,速度瓶颈不是注意力层,而是前馈层和投影层。减少 FLOP 的常见方法是采用某种形式的条件计算,避免将所有模型参数应用于输入序列中的所有标记。
在稀疏注意力部分,我们讨论了某些标记比其他标记更重要。遵循相同的直觉,在CoLT5 论文中,作者将所有前馈和注意力计算分为两个分支:重分支和轻分支。轻量层适用于所有令牌,重层仅适用于重要的令牌。
“轻量前馈分支和重量前馈分支仅在隐藏维度上有所不同,轻量分支的隐藏维度比标准 T5 前馈层更小,而重量分支的隐藏维度更大”。
事实证明,对于高达 64K 输入标记的极长序列,这种方法的速度和准确性均优于现有LongT5模型。

具有条件计算的 COLT5 Transformer 层的概述。所有令牌均由轻量注意力和 MLP 层处理,而 q 路由查询令牌对 v 路由键值令牌执行更重的注意力,m 路由令牌由更重的 MLP 处理。CoLT5纸
[技巧#6] 大 RAM GPU
这不是技巧,而是必要的。为了适应大型环境,GPU 中需要大 RAM,因此人们使用 80GB A100 GPU。
结论
我希望它有帮助!我学到了很多东西,我希望你也学到了,现在我们可以猜测这些具有数十亿参数的大型语言模型是如何在前所未有的 65-100K 令牌上下文窗口中进行训练的。
看到不同的聪明人如何从不同的角度解决同一问题,到处优化,并提出很酷的想法,这会激发灵感。所有这些导致了一个有意义且优雅的解决方案。
我喜欢一位研究人员关于在大背景下培训LLM的说法“没有秘密武器,只有经过严格审查的研究。”
参考
[1] Antropic介绍 100K 上下文窗口
[2] MosaicML 的MPT-7B
[3] Google 的Palm-2 技术报告
[4] ALiBI:训练短,测试长:带有线性偏差的注意力支持输入长度外推
[5] FlashAttention :具有 IO 意识的快速且内存高效的精确注意力
[6]多查询注意力:快速 Transformer 解码:您只需要一个写头
[8]注意力就是您所需要的
[9]关于位置正弦嵌入的视频
[10 ] FlashAttention 论文概述
[11]滑动窗口注意
[12]使用稀疏注意方法构造更长序列的 Transformers
[13] Triton语言中的FlashAttention实现
[14]如何使用 Triton 和 ClearML 将 HuggingFace 吞吐量加速 193%
[15] ClearML Serving
[16]分析 NVIDIA Triton 推理服务器与其他推理引擎的优缺点
[17] COLT5:具有条件计算的更快的远程转换器
[18] LongT5:适用于长序列的高效文本到文本转换器
[19] ] PaLM
[20] BigBird注意力机制