【C语言:深入理解指针二】
文章目录
- 1. 二级指针
- 2. 指针数组
- 3. 字符指针变量
- 4. 数组指针变量
- 5. 二维数组传参的本质
- 6. 函数指针变量
- 7. 函数指针数组
- 8. 转移表
- 9. 回调函数
- 10. qsort函数的使用与模拟实现

1. 二级指针
我们知道,指针变量也是变量,它也有自己的地址,使用什么来存放它的地址呢?答案是:二级指针。
int main()
{
int a = 10;
int* p = &a;
int** pp = &p; //二级指针变量pp
return 0;
}

关于二级指针的运算

- *pp先解引用,对pp中的地址进行访问,访问的就是p
- **pp, 先通过*pp找到p,再对p进行解引用,访问的就是a
2. 指针数组
指针数组,顾名思义,它应该是一个数组,是用来存放指针的。
指针数组中的每一个元素又是一个地址,可以指向另一个区域。
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
//数组名是数组首元素的地址,类型是int*,可以存放在数组指针arr中
int* arr[3] = { arr1, arr2, arr3 };
return 0;
}

- 使用指针数组模拟二维数组
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
//数组名是数组首元素的地址,类型是int*,可以存放在数组指针arr中
int* arr[3] = { arr1, arr2, arr3 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 5; j++)
{
printf("%d ", arr[i][j]);
//也可以写成下面这种形式
//printf("%d ", *(*(arr + i) + j));
}
printf("\n");
}
return 0;
}
3. 字符指针变量
在指针的类型中,我们知道有一种指针类型叫字符指针。
一般使用:
int main()
{
char ch = 'c';
char* pc = &ch;
*pc = 'a';
printf("%c\n", ch);
return 0;
}
还有一种使用方式:
int main()
{
char* pc = "abcdef";
printf("%s\n", pc);
return 0;
}
- 可以把字符串想象为一个字符数组,但是这个数组是不能修改的,因此为了避免出错,常常加上const
const char* pc = "abcdef";
- 当常量字符串出现在表达式中的时候,他的值是第一个字符的地址。当我们知道存放的是第一个字符的地址的时候,我们就可以这样玩
int main()
{
char* pc = "abcdef";
printf("%c\n", "abcdef"[3]); //d
printf("%c\n", pc[3]); //d
return 0;
}
下面来看一道题目:
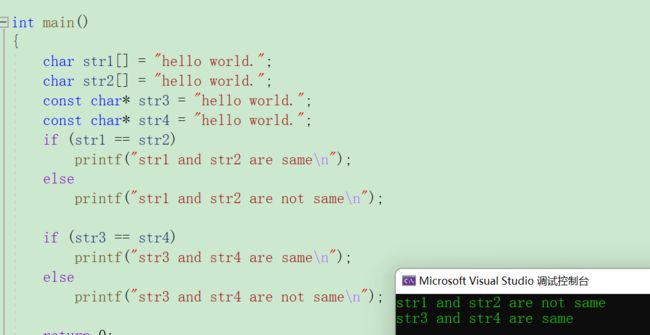
str1 不等于 str2 这个很好理解;str3 等于str4怎么理解呢?

由于str3 与 str4中存放的都是常量字符串,C/C++会把常量字符串存储到单独的⼀个内存区域,当⼏个指针指向同⼀个字符串的时候,他们实际会指向同⼀块内存。(内容相等的常量字符串仅保存一份)
但是⽤相同的常量字符串去初始化不同的数组的时候就会开辟出不同的内存块。所以str1和str2不同,str3和str4相同。
4. 数组指针变量
数组指针变量是数组还是指针呢?答案是:指针。
我们已经熟悉:
- 整形指针变量: int * pint; 存放的是整形变量的地址,能够指向整形数据的指针。
- 浮点型指针变量: float * pf; 存放浮点型变量的地址,能够指向浮点型数据的指针。
那数组指针变量应该是:存放的应该是数组的地址,能够指向数组的指针变量。
int main()
{
int arr[10] = { 0 };
int(*parr)[10] = &arr; //数组指针变量parr
return 0;
}

5. 二维数组传参的本质
我们知道一维数组传参的本质是:传的是数组首元素的地址。
那二维数组呢?
过去我们使用二维数组时,是这样的:
void func(int arr[][5], int row, int col)
{
int i = 0;
for (i = 0; i < row; i++)
{
int j = 0;
for (j = 0; j < col; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
}
int main()
{
int arr[3][5] = { {1,2,3,4,5}, {2,3,4,5,6}, {3,4,5,6,7} };
func(arr, 3, 5);
return 0;
}
这里实参是⼆维数组,形参也写成⼆维数组的形式,那还有什么其他的写法吗?
首先,我们应该知道⼆维数组其实可以看做是每个元素是⼀维数组的数组,也就是⼆维数组的每个元素是⼀个⼀维数组。那么⼆维数组的首元素就是第一行,是个⼀维数组。
所以,根据数组名是数组首元素的地址这个规则,⼆维数组的数组名表示的就是第⼀⾏的地址,是⼀维数组的地址。根据上⾯的例⼦,第⼀行的⼀维数组的类型就是 int [5] ,所以第⼀行的地址的类型就是数组指针类型 int(*)[5] 。那就意味着⼆维数组传参本质上也是传递了地址,传递的是第⼀行这个⼀维数组的地址,那么形参也是可以写成指针形式的。如下:
void func(int (*arr)[5], int row, int col)
{
int i = 0;
for (i = 0; i < row; i++)
{
int j = 0;
for (j = 0; j < col; j++)
{
printf("%d ", *(*(arr + i) + j));
}
printf("\n");
}
}
6. 函数指针变量
函数指针变量应该是用来存放函数地址的,未来通过地址能够调用函数,那函数是否真的有地址呢?
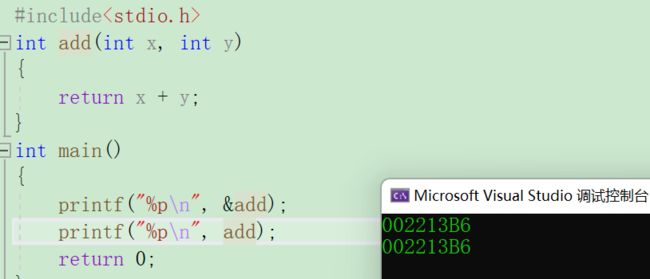
确实打印出来了地址,所以函数是有地址的。
- 函数名就是函数的地址
- &函数名 也是函数的地址。
这里和数组相比还是有区别的
- 数组名是数组首元素的地址;
- &数组名是整个数组的地址
函数指针类型解析:

函数指针变量的使用
int add(int x, int y)
{
return x + y;
}
int main()
{
int (*p1)(int, int) = &add;
int ret1 = add(3, 5);
printf("%d\n", ret1); //8
int ret2 = (*p1)(3, 5);
printf("%d\n", ret2); //8
int (*p2)(int, int) = add;
int ret3 = (*p2)(4, 6);
printf("%d\n", ret3); //10
int ret4 = p2(4, 6);
printf("%d\n", ret4); //10
return 0;
}
因为函数名就是地址,我们调用函数的时候没有使用解引用,所以函数指针也可以不解引用, 如ret4。
两段有趣的代码:
(*(void (*)())0)();
- 上述代码是一次函数调用
- 将0强制类型转换成一个函数指针,这个函数没有参数,返回类型是void
- (*0)()调用0地址处的函数
void (* signal(int , void(*)(int)) )(int);
- signal是一个函数名,这个函数有两个参数,一个是整型int,一个是函数指针类型的 void (*)(int),这个函数的参数是int,返回值是void
- void (*)(int) 去掉函数名和函数参数,剩下的就是函数的返回类型。该signal函数的返回类型是 void ( * )(int)的函数指针。
这样写是不是挺不好理解的,我们可以使用typedef将复杂的类型简单化。
比如,将 int* 重命名为 int_p ,这样写
typedef int* int_p;
但是对于数组指针和函数指针稍微有点区别:新的名字必须在*的旁边
比如我们有数组指针类型 int(*)[5] ,需要重命名为 parr_t ,那可以这样写:
typedef int (*parr_t)[5];
将 void(*)(int) 类型重命名为 pf_t ,就可以这样写:
typedef void (*pf_t)();
pf_t signal(int, pf_t); //signal函数就可以被这样简化
7. 函数指针数组
数组是⼀个存放相同类型数据的存储空间,而且我们已经学习了函数指针。
int Add(int x, int y)
{
return x + y;
}
int main()
{
int (*p)(int, int) = Add; //函数指针
return 0;
}
那么如果要把多个函数(函数参数的类型、返回值的类型都应相同 )的地址存放起来,那函数指针数组应该如何定义呢?
int Add(int x, int y)
{
return x + y;
}
int Sub(int x, int y)
{
return x - y;
}
int Mul(int x, int y)
{
return x * y;
}
int Div(int x, int y)
{
return x / y;
}
int main()
{
int (*p)(int, int) = Add;//函数指针
int (*pArr[])(int, int) = { Add, Sub, Mul, Div }; //函数指针数组
return 0;
}
我们都知道,一个数组,去掉数组名和 [ ] 剩下的就是数组元素的类型。例如 int arr[ ], int 就是数组元素的类型。
因此 int (* pArr[ ] )(int, int),去掉数组名和 [],剩下的int (*)(int ,int)就是这个数组元素的类型,很显然,这是数组元素的类型是函数指针类型。
函数指针数组的使用:

8. 转移表
当我们学习完函数指针数组以后,你是否也有过这样的疑问:我直接通过函数名调用函数不是更简单吗,干嘛还要放进数组中,然后再调用函数呢?请看下面的代码:
假设我们要实现一个计算器,一般写法是不是这样呢?
void menu()
{
printf("****************************\n");
printf("******1.Add 2.Sub*****\n");
printf("******3.Mul 4.Div*****\n");
printf("******0.exit *****\n");
printf("****************************\n");
}
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
do
{
menu();
printf("请选择:\n");
scanf("%d", &input);
switch (input)
{
case 1:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = Add(x, y);
printf("%d\n", ret);
break;
case 2:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = Sub(x, y);
printf("%d\n", ret);
break;
case 3:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = Mul(x, y);
printf("%d\n", ret);
break;
case 4:
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = Div(x, y);
printf("%d\n", ret);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误,请重新选择!\n");
}
} while (input);
return 0;
}

因此,我们就可以利用转移表来解决代码的冗余问题,首先,我们要知道什么是转移表?
转移表就是用一个函数指针数组存储每一个自定义的函数指针,在调用自定义函数的时候,就可以通过数组下标访问 ----总结于《C和指针》
利用转移表解决问题:
int main()
{
int input = 0;
int x = 0;
int y = 0;
int ret = 0;
int (*pArr[])(int, int) = { NULL, Add, Sub, Mul ,Div };
// 0 1 2 3 4 使用NULL巧妙地与选择相对应
do
{
menu();
printf("请选择:\n");
scanf("%d", &input);
if (input == 0)
{
printf("退出计算器\n");
}
else if (input >= 1 && input <= 4)
{
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = pArr[input](x, y);
printf("%d\n", ret);
}
else
{
printf("选择错误,请重新选择!\n");
}
} while (input);
return 0;
}
这样是不是就很好地解决了代码地冗余问题,同时也方便了以后再增加新的功能,只需向函数指针数组中添加函数的地址即,改变以下判断的范围即可,无需再写一大串的case了。
9. 回调函数
- 回调函数是什么呢?
回调函数就是⼀个通过函数指针调用的函数。
如果你把函数的指针(地址)作为参数传递给另⼀个函数,当这个指针被用来调用其所指向的函数时,被调用的函数就是回调函数。回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的⼀方调用的,用于对该事件或条件进行响应
Calculate函数的参数是函数指针类型的
void Calculate(int (*pfunc)(int, int))
{
int x = 0;
int y = 0;
int ret = 0;
printf("请输入两个操作数:");
scanf("%d %d", &x, &y);
ret = pfunc(x, y); //通过函数指针调用函数
printf("%d\n", ret);
}
int main()
{
int input = 0;
do
{
menu();
printf("请选择:\n");
scanf("%d", &input);
switch (input)
{
case 1:
Calculate(Add);
break;
case 2:
Calculate(Sub);
break;
case 3:
Calculate(Mul);
break;
case 4:
Calculate(Div);
break;
case 0:
printf("退出计算器\n");
break;
default:
printf("选择错误,请重新选择!\n");
}
} while (input);
return 0;
}
我们可以发现,当Calculate函数的参数是函数指针类型时,只要你给Calculate函数传递一个函数指针类型的变量,它都可以调用,这样看它的功能是不是强大了不少。
10. qsort函数的使用与模拟实现
- qsort函数是什么?
qsort函数是可以排序任何类型数据的一个函数。 - qsort是如何设计的?
void qsort (void* base,
size_t num,
size_t size,
int (*compar)(const void*,const void*));
这个函数有四个参数,各参数的说明如下:

第四个参数有点特别,它是一个函数指针,指针指向的函数的功能是比较两个元素的大小,这个函数需要qsort函数的使用者自己实现,并且函数的返回值要符合qsort函数的要求

那么我们先来使用以下qsort函数吧:
struct Stu
{
int age;
char name[20];
};
//使用者自己实现两个元素的比较函数
int cmp(const void* p1, const void* p2)
{
return *((int*)p1) - *((int*)p2);
//此处是将p1、p2变量强制转换为 整型指针变量 然后解引用
}
int cmp_struct_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
void print1(int arr[], int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}
void print2(struct Stu arr[],int sz)
{
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d %s\n", arr[i].age, arr[i].name);
}
printf("\n");
}
int main()
{
int arr1[] = { 2,1,8,5,6,3,4,9,7,0 };
int sz1 = sizeof(arr1) / sizeof(arr1[0]);
print1(arr1, sz1);
qsort(arr1, sz1, sizeof(arr1[0]), cmp);
print1(arr1, sz1);
struct Stu arr2[] = { {18, "zhangsan"}, {38, "lisi"}, {25, "wangwu"} };
int sz2 = sizeof(arr2) / sizeof(arr2[0]);
print2(arr2, sz2);
qsort(arr2, sz2, sizeof(arr2[0]), cmp_struct_name);
print2(arr2, sz2);
return 0;
}

接下来,我们就来模拟实现一个qsort函数,由于qsort的实现使用的是快速排序,我们在此就使用冒泡排序
//使用者自己实现两个元素的比较函数
int cmp(const void* p1, const void* p2)
{
return *((int*)p1) - *((int*)p2);
//此处是将p1、p2变量强制转换为 整型指针变量 然后解引用
}
int cmp_struct_name(const void* p1, const void* p2)
{
return strcmp(((struct Stu*)p1)->name, ((struct Stu*)p2)->name);
}
int cmp_struct_age(const void* p1, const void* p2)
{
return (*(struct Stu*)p1).age - (*(struct Stu*)p2).age;
}
//由于被交换的数据的类型不是固定的,但是数据类型的大小是知道的
//因此我们可以交换数据的每一个字节的数据
void _Swap(const void* p1, const void* p2, int sz)
{
int i = 0;
//交换数据的每一个字节
for (i = 0; i < sz; i++)
{
char tmp = *((char*)p1 + i);
*((char*)p1 + i) = *((char*)p2 + i);
*((char*)p2 + i) = tmp;
}
}
void my_qsort(void* base, int num, int size, int (*compar)(const void*, const void*))
{
int i = 0;
for (i = 0; i < num - 1; i++)
{
int j = 0;
for (j = 0; j < num - 1 - i; j++)
{
//此处应该是传给compar()两个参数arr[j]与arr[j+1],让其进行比较
//但是怎么拿到要传的数呢?
//qsort函数只有这个数组首元素的地址,和数组元素类型的大小
//因此我可以让base指针加上 j个类型的大小 找到某个元素的首地址,具体比较多大内容的数据,看比较什么类型的数据,由使用者决定
//但是我得到的数组首元素的地址也是void* 类型的,所以我们可以将base转换位char*类型的指针,一次访问 j*size 大小
if (compar((char*)base + j * size, (char*)base + (j + 1) * size) > 0)
{
//交换
_Swap((char*)base + j * size, (char*)base + (j + 1) * size, size);
}
}
}
}
int main()
{
//比较整型的数据
int arr1[] = { 2,1,8,5,6,3,4,9,7,0 };
int sz1 = sizeof(arr1) / sizeof(arr1[0]);
printf("排序整型\n");
print1(arr1, sz1);
my_qsort(arr1, sz1, sizeof(arr1[0]), cmp);
print1(arr1, sz1);
//比较结构体类型的数据
struct Stu arr2[] = { {38, "lisi"}, {18, "zhangsan"}, {25, "wangwu"} };
int sz2 = sizeof(arr2) / sizeof(arr2[0]);
printf("排序结构体型-按姓名\n");
print2(arr2, sz2);
my_qsort(arr2, sz2, sizeof(arr2[0]), cmp_struct_name);
print2(arr2, sz2);
printf("排序结构体型-按年龄\n");
print2(arr2, sz2);
my_qsort(arr2, sz2, sizeof(arr2[0]), cmp_struct_age);
print2(arr2, sz2);
return 0;
}

本次的分享就到这里啦~