Go语言标准库之net/http(一) —— Request
Http协议(Hyper Text Transfer Protocol,超文本传输协议)是一个简单的请求-响应协议,它通常运行在TCP之上。
Http协议是基于客户端(Cilent)/服务器(Server)模式,且面向连接的。简单的来说就是客户端(Cilent)向服务器(Server)发送http请求(Request),服务器(Server)接收到http服务请求(Request)后会在http响应(Response)中回送所请求的数据。

Go的标准库 net/http 则提供了对http协议支持的封装,提供了强大而又灵活的功能实现。系列文章将通过 Cilent 、Server 、 Request 、Response 四方面去解析http协议以及 net/http 包。
本章节将重点从 Request 的组成以及 net/http 包中对Request 的相关源码进行解析。
HTTP Request 结构
Http Requset指的是客户端发送给服务器的一个请求,或者是服务器收到的一个请求。
在命令行下查看HTTP协议,可以使用 curl 或 http 命令发起HTTP请求;而在浏览器端下也可以使用开发者工具查看。
下图为一个Http Requset的示例:
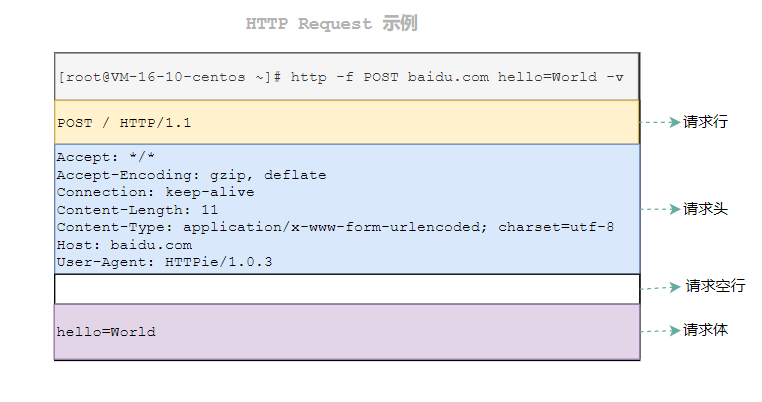
从上述图示中可以看出,Http Requset报文的格式:
请求行
请求头
请求空行
请求体
具体的我们展开的分析下。
请求行
请求行中的信息包括三部分:请求方式(Get/Post),请求URL,协议版本,他们之间使用空格隔开。
例如上述图示中请求行内容为:POST / HTTP/1.1,则:
-
请求方式为
POST在
1.1版本中,一共支持8个请求方式方法:请求方式 描述 GET 请求指定的页面信息,并返回实体主体 POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。
数据被包含在请求体中。post请求可能会导致新的资源的建立或资源的修改;一般不会被删除。HEAD 类似于get请求,但服务器不返回body部分,用于获取报头。
这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。可用于查询资源修改日期等。DELETE 请求服务器删除 Request-URI 所标识的资源 PUT 从客户端向服务器传送的数据取代指定的文档的内容。一般用于修改。 OPTIONS 返回服务器针对特定资源所支持的HTTP请求方法 CONNECT http1.1协议中预留给能够将连接改为管道方式的代理服务器 TRACE 回显服务器收到的请求,主用于测试或诊断; 一般情况下,
GET、POST使用较为多。 -
请求URL为
/请求URL就比较好理解了,就是需要请求的地址,也可以理解为需要请求的
API地址。 -
请求协议版本为
HTTP/1.1
请求头
HTTP请求头包含了客户端(如Web浏览器)向服务器发送的请求的附加信息。它可以包含多个键值对,用于描述请求的各种属性,例如请求的方法、内容类型、接受的语言、请求的来源、Cookie等。这些信息可以帮助服务器了解客户端的需求,从而提供更准确、更有效的响应。
HTTP请求头可以有多个,每个字段占一行,字段名和字段值之间用冒号和空格分隔,例如:
Accept: */*
Accept-Encoding: gzip, deflate
Connection: keep-alive
Content-Length: 11
HTTP请求头提供了很多标准属性,常见的属性如下表:
| 请求头 | 作用 | 示例 |
|---|---|---|
| Accept | 告知服务器客户端能够处理的MIME类型 | Accept: text/html, application/xhtml+xml, application/xml;q=0.9 |
| Accept-Encoding | 告知服务器客户端支持的内容编码方式 | Accept-Encoding: gzip, deflate |
| Accept-Language | 告知服务器客户端支持的语言 | Accept-Language: en-US, en;q=0.5 |
| Cache-Control | 控制缓存行为 | Cache-Control: no-cache |
| Connection | 控制连接的行为 | Connection: keep-alive |
| Content-Length | 指定请求体的长度 | Content-Length: 348 |
| Content-Type | 指定请求体的MIME类型 | Content-Type: application/x-www-form-urlencoded |
| Host | 指定服务器的域名和端口号 该属性跟请求行中请求URL一起组成一个完整的地址 |
Host: www.example.com |
| User-Agent | 提供客户端的应用程序名称和版本号 | User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 |
| Authorization | 提供访问受保护资源所需的凭证 | Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l |
| Cookie | 用于在客户端和服务器之间传递会话信息 | Cookie: $Version=1; UserId=1234; $Path=/ |
| Origin | 指示请求的来源,用于防止跨站点攻击 | Origin: http://www.example.com |
| Referer | 指示请求的来源URL,用于记录访问日志和防止跨站点攻击 | Referer: http://www.example.com/index.html |
| Accept-Charset | 浏览器可以接受的字符编码集 | Accept-Charset:iso-8859-5 |
| If-Modified-Since | 用于缓存控制,指定一个日期,如果该日期之后资源没有发生变化,则返回304 Not Modified | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT |
| If-None-Match | 用于缓存控制,指定一个实体标签,如果资源的实体标签匹配,则返回304 Not Modified | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| Range | 请求资源的某个字节范围,用于分段下载 | Range :byte=500-999 |
| Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade:Http/2.0,SHTTP/1.3,IRC/ |
| Accept-Datetime | 告知服务器客户端支持的日期时间格式 | Accept-Datetime: Thu, 31 May 2007 20:35:00 GMT |
| If-Match | 用于缓存控制,指定一个实体标签,如果资源的实体标签匹配,则返回资源,否则返回412 Precondition Failed | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| Max-Forwards | 限制转发次数,用于TRACE和OPTIONS请求 | Max-Forwards: 10 |
| Proxy-Authorization | 提供访问代理所需的凭证 | Proxy-Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l |
| TE | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade:Http/2.0,SHTTP/1.3,IRC/ |
| Warning | 关于消息实体的警告信息 | warn:199 Miscellaneous warning |
| Via | 通知中间网关或代理服务器地址,通信协议 | Vis:1.1 fred,1.1 nowhere.com(Apache/1.1) |
| Transfer-Encoding | 描述了在HTTP报文中的实体主体(body)是编码传输方式 | Transfer-Encoding字段有两种常见的取值:chunked和identity 1. chunked:表示使用分块传输编码方式。在这种方式下,实体主体被分成一系列的块,每个块都包含自己的长度和实体数据。每个块的长度是以十六进制的方式表示的。使用分块传输编码可以解决传输过程中的时延和带宽浪费问题。 2. identity:表示不使用任何编码方式,实体主体以原始数据的形式传输。在这种方式下,实体主体的长度可以通过Content-Length字段指定。 除了上述两种编码方式之外,Transfer-Encoding还可以包含其他编码方式的值,比如gzip、deflate等,表示使用相应的压缩方式对实体主体进行编码。 需要注意的是,当Transfer-Encoding字段和Content-Length字段同时存在时,Transfer-Encoding会覆盖Content-Length,只有当Transfer-Encoding的值为identity时,Content-Length字段才有效。 |
| Content-Encoding | 描述实体主体的内容编码方式 | 它通常用于标识HTTP请求和响应中的实体主体使用的编码方式,比如gzip、deflate等。这些编码方式的作用是对实体主体进行压缩,以减少传输数据的大小,提高网络传输效率。 |
| Expect | 用于告知服务器期望响应的特定行为 | 常见的用法是在客户端请求中加入 Expect: 100-continue,表示客户端希望在请求体发送前先确认服务端是否接受请求体,这样可以避免因发送大量请求体而造成的资源浪费。 |
| X-Forwarded-For(非标准) | 在通过代理的时候会加这样的一个头,这个头会携带以前的IP,所以这里面可能是一个,也可能是多个IP/域名,并用逗号隔开。 其中第一个是最原始的客户机的IP,每过一个代理就会加上自身的IP,如果你需要判断取得最原始用户的IP,可以通过这里来判断。 |
clientip,proxy1ip,proxy2ip |
| X-Requested-With(非标准) | 用来标记AJAX的。如果你在浏览器中,一般请求都是通过Ajax发出的,都会带这个头。 | XML.HttpRequest |
除了上述列出的一些标准头以外,还有很多不常用的头,再次不一一列举。
除了标准的头以外,HTTP协议允许用户定义自己的请求头,这些请求头通常以X-开头,例如X-Custom-Header、X-Forwarded-For等。自定义请求头通常用于在HTTP请求中添加一些自定义的元数据,以便与特定的应用程序或服务进行交互。
另外,在使用自定义请求头时需要遵循一些规则,例如请求头的名称不能包含空格、冒号等特殊字符,长度不能太长,不建议使用敏感信息等。此外,建议在编写自定义请求头时,参考RFC6648的建议和规范,以确保与HTTP标准的兼容性和互操作性。
这边重点快速介绍下 100-continue 这个比较有意思的机制。
100 Continue 是一个 HTTP 协议的状态码和机制,用于实现客户端与服务器之间的流控,防止请求数据发送过快而导致服务器无法处理。
当客户端向服务器发送带有 HTTP 请求体的请求时,请求头中可以附加 Expect: 100-continue 字段。这个字段的作用是通知服务器,客户端期望收到一个 100 Continue 的响应,告诉客户端可以继续发送请求体。服务器在接收到带有 Expect: 100-continue 请求头的请求后,会发送一个 100 Continue 的响应,告诉客户端可以继续发送请求体。
客户端收到 100 Continue 的响应后,就可以继续发送请求体了。如果服务器在接收到 Expect: 100-continue 请求头的请求后,无法或者不愿意提供 100 Continue 的响应,它可以直接返回 417 (Expectation Failed) 状态码,告诉客户端不支持该特性。
100 Continue 的机制可以有效地防止客户端发送请求体过快而导致服务器无法处理的情况。
请求体
在HTTP协议中,请求体是指在请求头后面的数据部分,通常用于向服务器传递数据。请求体的格式和内容取决于请求的类型和使用的数据格式。
在HTTP请求中:
GET请求通常不包含请求体,因为GET请求的主要目的是获取资源,不需要向服务器传递数据。- 而
POST请求和PUT请求等通常需要在请求体中传递数据,例如表单数据、JSON数据、XML数据等。
例如Http Requset的图示上的 hello=World就是一个请求体内容。
在请求体中传递数据时,需要注意数据的编码方式和格式,以确保服务器能够正确解析和处理数据,编码和格式在请求头 Content-Type 中设置。
常用的编码数据格式包括 :
- application/x-www-form-urlencoded:用于提交
form表单数据,将表单数据编码为键值对形式,并使用等号和&符号进行分隔。 - multipart/form-data:用于表单提交文件和二进制数据,将数据分解为多个部分,并使用boundary进行分隔。常用于表单文件上传提交。
- application/json:用于提交
JSON格式的数据。 - application/xml:用于提交
XML格式的数据。
在表单提交数据的时候,有type-file的时候一般采取multipart/form-data编码方式,然则用默认的application/x-www-form-urlencoded即可。
请求体的大小通常会受到服务器和客户端的限制,过大的请求体可能会导致请求失败或响应时间延长。因此,在传递大量数据时,建议采用分块传输编码或流式传输等方式,以提高传输效率和性能。
net/http包中的Request
Request结构体
net/http中的 Request结构体表示一个HTTP请求,包含请求方法、URL、请求头、请求体等信息。信息主要在文件 net/http/request.go中。
Request结构体的定义:
type Request struct {
Method string //HTTP请求方法,如GET、POST等
URL *url.URL //HTTP请求的URL地址,是一个指向url.URL类型的指针。
Proto string //HTTP协议版本,如"HTTP/1.0"或者"HTTP/1.1"
ProtoMajor int //HTTP协议的主版本号,整数类型。如1
ProtoMinor int //HTTP协议的次版本号,整数类型。如0
Header Header //HTTP请求头信息,是一个http.Header类型的映射,用于存储HTTP请求头。
Body io.ReadCloser //HTTP请求体,是一个io.ReadCloser类型的接口,表示一个可读可关闭的数据流。
GetBody func() (io.ReadCloser, error) //HTTP请求体获取函数
ContentLength int64 //HTTP请求体的长度,整数类型。
TransferEncoding []string //HTTP传输编码,如"chunked"等。
Close bool //表示在请求结束后是否关闭连接。
Host string //HTTP请求的主机名或IP地址,字符串类型。
Form url.Values //HTTP请求的表单数据,是一个url.Values类型的映射,用于存储表单字段和对应的值。
PostForm url.Values //HTTP POST请求的表单数据,同样是一个url.Values类型的映射。
MultipartForm *multipart.Form //HTTP请求的multipart表单数据,是一个multipart.Form类型的结构体。
Trailer Header //HTTP Trailer头信息,是一个http.Header类型的映射,用于存储Trailer头部字段和对应的值。
RemoteAddr string //请求客户端的地址。
RequestURI string //请求的URI,包括查询字符串。
TLS *tls.ConnectionState //如果请求是使用TLS加密的,则该字段存储TLS连接的状态信息。
Cancel <-chan struct{} //一个只读通道,用于在请求被取消时发送信号。
Response *Response //一个指向http.Response类型的指针,表示HTTP响应信息。
ctx context.Context //一个context.Context类型的上下文,用于控制请求的超时和取消。
}
上述的字段定义表示一个HTTP请求,包含了HTTP请求的各种元信息和数据。
NewRequest
NewRequest 函数用于创建一个新的Request类型,并将请求的方法、URL、请求体设置为传入的参数:
func NewRequest(method, url string, body io.Reader) (*Request, error) {
return NewRequestWithContext(context.Background(), method, url, body)
}
由代码可以得出,NewRequest调用了 NewRequestWithContext函数,该函数才是创建Request类型的核心函数,这个函数与NewRequest函数类似,区别在于NewRequestWithContext函数增加了一个Context参数,将请求的上下文设置为传入的Context类型。
func NewRequestWithContext(ctx context.Context, method, url string, body io.Reader) (*Request, error) {
//如果method未设置值,则默认使用GET方法
if method == "" {
method = "GET"
}
//校验方法有效性,此处不具体校验方法类型,指检验方法名称字符的是否来自TokenTable(数字/字母/某些特殊符号)中的内容
if !validMethod(method) {
return nil, fmt.Errorf("net/http: invalid method %q", method)
}
// ctx必须要传递,NewRequest方法调用时会传递context.Background()
if ctx == nil {
return nil, errors.New("net/http: nil Context")
}
// 解析URL,解析Scheme、Host、Path等信息
u, err := urlpkg.Parse(url)
if err != nil {
return nil, err
}
// 将body类型包装成io.ReadCloser类型
rc, ok := body.(io.ReadCloser)
if !ok && body != nil {
rc = io.NopCloser(body)
}
u.Host = removeEmptyPort(u.Host)
//根据解析的内容创建Request对象
req := &Request{
ctx: ctx,
Method: method,
URL: u,
Proto: "HTTP/1.1",
ProtoMajor: 1,
ProtoMinor: 1,
Header: make(Header),
Body: rc,
Host: u.Host,
}
//如果body不为空,则进入语句
if body != nil {
// 断言body的类型
switch v := body.(type) {
case *bytes.Buffer:
req.ContentLength = int64(v.Len())
buf := v.Bytes()
req.GetBody = func() (io.ReadCloser, error) {
r := bytes.NewReader(buf)
return io.NopCloser(r), nil
}
case *bytes.Reader:
req.ContentLength = int64(v.Len())
snapshot := *v
req.GetBody = func() (io.ReadCloser, error) {
r := snapshot
return io.NopCloser(&r), nil
}
case *strings.Reader:
req.ContentLength = int64(v.Len())
snapshot := *v
req.GetBody = func() (io.ReadCloser, error) {
r := snapshot
return io.NopCloser(&r), nil
}
default:
// body的类型断言失败,不处理
}
// 对于body如果不等于nil,但是content-length又是0,则对req.Body和req.GetBody进行重新赋值。
if req.GetBody != nil && req.ContentLength == 0 {
req.Body = NoBody
req.GetBody = func() (io.ReadCloser, error) { return NoBody, nil }
}
}
return req, nil
}
该函数的作用在于创建一个新的带有上下文的HTTP请求,以便在进行异步处理时,能够正确地控制请求的上下文和超时。同时,它也提供了一个方便的方式来设置HTTP请求的上下文。
ReadRequest
ReadRequest函数作用是从bufio.Reader类型的参数b中读取HTTP请求,并解析请求行、请求头和请求体,返回一个*http.Request类型的指针。
func ReadRequest(b *bufio.Reader) (*Request, error) {
return readRequest(b, deleteHostHeader)
}
该函数主要调用readRequest函数,功能与ReadRequest函数一致,只是增加了一个deleteHostHeader参数,该参数主要来控制是否删除请求头的Host值。
readRequest代码如下:
func readRequest(b *bufio.Reader, deleteHostHeader bool) (req *Request, err error) {
//使用textproto.Reader包装TCP连接读取HTTP请求
tp := newTextprotoReader(b)
//创建Request对象
req = new(Request)
//逐行读取HTTP请求信息并转为字符串
var s string
if s, err = tp.ReadLine(); err != nil {
return nil, err
}
defer func() {
//使用sync.pool来保存textproto.Reader变量
putTextprotoReader(tp)
if err == io.EOF {
err = io.ErrUnexpectedEOF
}
}()
var ok bool
//解析HTTP请求的Method RequestURI RequestURI信息
req.Method, req.RequestURI, req.Proto, ok = parseRequestLine(s)
//解析失败则返回错误
if !ok {
return nil, badStringError("malformed HTTP request", s)
}
//校验HTTP请求方法
if !validMethod(req.Method) {
return nil, badStringError("invalid method", req.Method)
}
//校验HTTP协议版本号
rawurl := req.RequestURI
if req.ProtoMajor, req.ProtoMinor, ok = ParseHTTPVersion(req.Proto); !ok {
return nil, badStringError("malformed HTTP version", req.Proto)
}
//检查一个HTTP请求是否为CONNECT方法,并且请求的URL不是以斜杠“/”开头,满足条件返回true,否则返回false
justAuthority := req.Method == "CONNECT" && !strings.HasPrefix(rawurl, "/")
if justAuthority {
rawurl = "http://" + rawurl
}
//通过rawurl字符串解析URL值,并将其赋值给 req.URL
if req.URL, err = url.ParseRequestURI(rawurl); err != nil {
return nil, err
}
//如果 justAuthority 为真(即上一个问题中提到的条件满足),则将 req.URL.Scheme 设为一个空字符串,这样在后续处理中,只使用 req.URL.Host 来获取主机和端口号信息,而不会使用 URL 中的协议信息。
//这是为了保持与 HTTP CONNECT 方法的语义一致,因为 CONNECT 方法中的 URL 只包含主机和端口号信息,没有协议部分。
if justAuthority {
req.URL.Scheme = ""
}
//从 tp 中读取 HTTP 请求的 MIME 头部,并将其解析为一个 map[string][]string 类型的对象 mimeHeader
mimeHeader, err := tp.ReadMIMEHeader()
//如果读取过程中出现错误,会返回一个错误对象
if err != nil {
return nil, err
}
//将 MIME 头部中的字段复制到请求的 Header 对象中
req.Header = Header(mimeHeader)
req.Host = req.URL.Host
if req.Host == "" {
req.Host = req.Header.get("Host")
}
//如果 deleteHostHeader 为真,即需要删除请求头部中的 Host 字段,那么会从 req.Header 中删除 Host 字段
//这通常用于 HTTP 请求中的代理场景,因为代理服务器会在转发请求时修改 Host 字段。
if deleteHostHeader {
delete(req.Header, "Host")
}
//处理请求头部中的 Pragma 和 Cache-Control 字段,以满足 HTTP 协议的要求
fixPragmaCacheControl(req.Header)
//判断当前的请求是否应该关闭连接,并将结果设置为req.Close。
//shouldClose() 函数会根据 HTTP 版本、请求头部和其他条件来判断是否需要关闭连接。
req.Close = shouldClose(req.ProtoMajor, req.ProtoMinor, req.Header, false)
// 读取请求中的数据(例如 POST 请求中的请求体),并将其存储在 req.Body 中。如果读取过程中出现错误,会返回一个错误对象。
err = readTransfer(req, b)
if err != nil {
return nil, err
}
//如果请求头部中包含了 Upgrade 字段,且其值为 "h2c",表示该请求需要升级到 HTTP/2 协议
//那么会将 req.ContentLength 设为 -1,并将 req.Close 设为 true
if req.isH2Upgrade() {
req.ContentLength = -1
req.Close = true
}
return req, nil
}
Request.write
Request.write() 方法用于将 HTTP 请求写入一个 io.Writer 对象中,以便将其发送到服务器。
func (r *Request) write(w io.Writer, usingProxy bool, extraHeaders Header, waitForContinue func() bool) (err error) {...}
该方法接收四个参数:
w:要写入的目标io.Writer对象;usingProxy:一个布尔值,表示是否使用代理服务器;extraHeaders:一个额外的请求头部,以Header对象的形式提供;waitForContinue:一个函数,用于处理 100 Continue 情况,返回一个布尔值,表示是否需要等待服务器的确认继续发送请求数据
源码如下:
func (r *Request) write(w io.Writer, usingProxy bool, extraHeaders Header, waitForContinue func() bool) (err error) {
closed := false
defer func() {
if closed {
return
}
if closeErr := r.closeBody(); closeErr != nil && err == nil {
err = closeErr
}
}()
// cleanHost() 函数的作用是对主机名进行规范化处理,主要是去掉主机名中的端口号和空格等无关字符。
// 调用 cleanHost() 函数,将 r.Host 中的主机名进行规范化处理。
// 如果主机名为空,那么会从 r.URL.Host 中获取主机名。
// 如果 r.URL 也为空,则会返回一个错误对象 errMissingHost。
host := cleanHost(r.Host)
if host == "" {
if r.URL == nil {
return errMissingHost
}
host = cleanHost(r.URL.Host)
}
//调用 removeZone() 函数,去掉主机名中的 IPv6 地址的 Zone Identifier 部分
host = removeZone(host)
//调用 r.URL.RequestURI() 函数获取请求的相对路径部分
ruri := r.URL.RequestURI()
//1. 如果使用了代理服务器且 URL 中包含了协议和主机名,则会将它们拼接到相对路径前面,形成完整的 URI
//2. 如果是 CONNECT 方法且 URL 的路径为空,则 URI 只包含主机名。
if usingProxy && r.URL.Scheme != "" && r.URL.Opaque == "" {
ruri = r.URL.Scheme + "://" + host + ruri
} else if r.Method == "CONNECT" && r.URL.Path == "" {
ruri = host
if r.URL.Opaque != "" {
ruri = r.URL.Opaque
}
}
//如果 URI 中包含控制字符,则会返回一个错误对象。
//控制字符是指 ASCII 字符集中,数值为 0 至 31 和 127 的字符。它们没有可见的图形符号,主要用于控制计算机的硬件设备和通讯协议。
//在 HTTP 协议中,请求和响应中的头部和正文部分都只能包含 ASCII 字符集中的可见字符。如果包含了控制字符,则可能会导致解析错误或安全问题。
if stringContainsCTLByte(ruri) {
return errors.New("net/http: can't write control character in Request.URL")
}
//检查w是否实现了io.ByteWriter接口,如果没实现,则创建一个新的bufio.Writer
//将它的输出流定向到传入的io.Writer,并将新创建的bufio.Writer赋值给变量bw
var bw *bufio.Writer
if _, ok := w.(io.ByteWriter); !ok {
bw = bufio.NewWriter(w)
w = bw
}
//向w写入请求行
_, err = fmt.Fprintf(w, "%s %s HTTP/1.1\r\n", valueOrDefault(r.Method, "GET"), ruri)
if err != nil {
return err
}
//向w写入请求头的HOST信息
_, err = fmt.Fprintf(w, "Host: %s\r\n", host)
if err != nil {
return err
}
//向w写入请求头的User-Agent信息
userAgent := defaultUserAgent
if r.Header.has("User-Agent") {
userAgent = r.Header.Get("User-Agent")
}
if userAgent != "" {
_, err = fmt.Fprintf(w, "User-Agent: %s\r\n", userAgent)
if err != nil {
return err
}
if trace != nil && trace.WroteHeaderField != nil {
trace.WroteHeaderField("User-Agent", []string{userAgent})
}
}
//调用了一个名为newTransferWriter的函数,该函数返回一个实现了io.Writer接口的transferWriter类型的变量tw,并将传入的HTTP请求r传递给它
tw, err := newTransferWriter(r)
if err != nil {
return err
}
//调用transferWriter类型变量tw的writeHeader方法,该方法向io.Writer写入HTTP请求头的第一行和其它一些元数据,如请求方法、请求URI和HTTP协议版本号
err = tw.writeHeader(w, trace)
if err != nil {
return err
}
//调用HTTP请求头变量r.Header的writeSubset方法,将HTTP请求头中的一些特定字段写入io.Writer,如内容长度、Cookie等
err = r.Header.writeSubset(w, reqWriteExcludeHeader, trace)
if err != nil {
return err
}
//检查是否有额外的HTTP请求头字段需要写入,如果有,则将它们写入io.Writer
if extraHeaders != nil {
err = extraHeaders.write(w, trace)
if err != nil {
return err
}
}
//向io.Writer写入HTTP请求头的末尾,即CRLF(回车换行)
_, err = io.WriteString(w, "\r\n")
if err != nil {
return err
}
/**
下面这段代码主要处理HTTP请求中的Expect: 100-continue头部。
在HTTP协议中,客户端可以在请求头部中加入这个字段,表示它期望服务器发送一个100 Continue响应,然后客户端才会发送请求体
*/
//如果waitForContinue不为nil
if waitForContinue != nil {
//则首先将写入缓冲区中的数据刷新到底层写入器中,以确保请求体发送之前的数据全部发送完毕
if bw, ok := w.(*bufio.Writer); ok {
err = bw.Flush()
if err != nil {
return err
}
}
//如果在trace中定义了Wait100Continue函数,则调用该函数以表示等待了100 Continue响应,否则跳过
if trace != nil && trace.Wait100Continue != nil {
trace.Wait100Continue()
}
//客户端不希望继续发送请求,可以直接关闭连接并返回。如果返回true,则继续执行发送请求体的操作
if !waitForContinue() {
closed = true
r.closeBody()
return nil
}
}
//检查w是否为*bufio.Writer类型,如果是并且tw.FlushHeaders标志为true,则将缓冲区的数据刷新到底层的io.Writer接口中,确保请求头部已经发送完毕
if bw, ok := w.(*bufio.Writer); ok && tw.FlushHeaders {
if err := bw.Flush(); err != nil {
return err
}
}
//将closed标志设为true,表示连接已关闭
closed = true
//调用tw.writeBody(w)方法发送请求体,并检查是否发生了requestBodyReadError。
err = tw.writeBody(w)
if err != nil {
if tw.bodyReadError == err {
err = requestBodyReadError{err}
}
return err
}
//如果bw不为nil,则将缓冲区的数据刷新到底层的io.Writer接口中,以确保所有数据都被写入底层接口。
if bw != nil {
return bw.Flush()
}
return nil
}
本节内容大致就这些,下节内容来讲讲Response的。