MySQL的Redo Log跟Binlog
文章目录
-
- 概要
- Redo Log日志
-
- Redo Log的作用
- Redo Log的写入机制
- Binlog日志
-
- Binlog的作用
- Binlog写入机制
- 两段提交
概要
Redo Log和Binlog是MySQL日志系统中非常重要的两种机制,也有很多相似之处,本文主要介绍两者细节和区别。
Redo Log日志
Redo Log的作用
准备一张测试表
create table test_redo(id int primary key, c int);
假设现在要执行这样一条sql
update test_redo set c = c + 1 where id = 1;
修改一条数据,首先是修改了Buffer Pool中该条数据所在的数据页。假如说我们刚提交了事务,发生了某个故障,内存中的数据都失效了,就会导致所做的修改跟着丢失了。这是不能接受的。
如何避免这样的情况发生?
一个简单粗暴的做法是:在事务提交完成之前把该事务所修改的所有页面都刷新到磁盘
这样做有以下两个问题:
- 刷新一个完整的数据也太浪费
比如上面只修改了一个字段,就要刷新整个页(16KB),InnoDB是以页为单位进行IO的,很浪费 - 随机IO速度很慢
涉及到多个页时,页与页之间在磁盘上可能是不连续的,随机IO要比顺序IO慢很多。
为了达到系统崩溃后,服务重启也能恢复原来提交的事务修改的目的,同时避免出现上面提到的问题,Redo Log就是一种解决方案。
Redo Log,重做日志,其本质是记录⼀下事务对数据库做了哪些修改。
将第0号表空间的100号页面的偏移量为1处的值更新为2
具体来说,当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 Redo Log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面。
这就是 MySQL 里经常说到的 WAL 技术,WAL 的全称是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘。
通过事务执行过程中产生的redo日志刷新到磁盘的方式,跟前面提到的简单粗暴的方式比较,有如下好处:
- redo日志占用的空间非常少
- redo日志是顺序写入磁盘的
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
Redo Log的写入机制
日志文件
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共就可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示

write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件。
write pos 和 checkpoint 之间空着的部分,可以用来记录新的操作。如果 write pos 追上 checkpoint,表示写满,这时候不能再执行新的更新,把 checkpoint 推进一下。
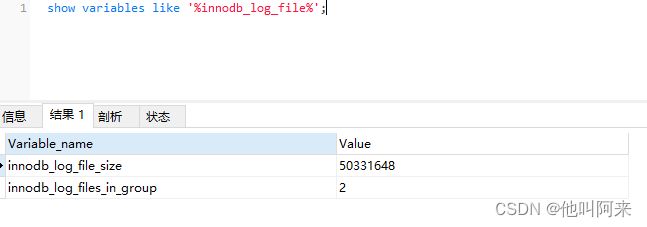
可通过以下查询redo log文件的数量跟大小
show variables like '%innodb_log_file%';
在服务器端可看到对应的文件
![]()
redo log buffer
假如执行如下sql
begin;
insert into t1 ...
insert into t2 ...
commit;
这个事务要往两个表中插入记录,插入数据的过程中,还没有执行 commit 的时候,就是是不能直接写到 redo log 文件里的。这时候回显记录在redo log buffer
redo log buffer 就是一块内存,用来先存 redo 日志。也就是说,在执行第一个 insert 的时候,数据的发生了修改,redo log buffer 也写入了日志。但是,真正把日志写到 redo log 文件(文件名是 ib_logfile+ 数字),是在执行 commit 语句的时候做的。
单独执行一个更新语句的时候,InnoDB 会自己启动一个事务,在语句执行完成的时候提交。过程跟上面是一样的。
redo log buffer是什么时候持久化到Redo Log中的呢?有如下3种策略,可通过innodb_flush_log_at_trx_commit进行配置。它有3种取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,由后台线程每隔1s执行一次刷盘操作 ;
- 设置为 1 的时候(默认值),表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 OS cache,然后由后台Master线程再每隔1秒执行OS
cache -> flush cache to disk 的操作。

一般建议选择取值2,因为 MySQL 挂了数据没有损失,整个服务器挂了才会损失1秒的事务提交数据。设置为1时最为安全,但是性能也是最差。
Binlog日志
Binlog的作用
Redo Log 是属于InnoDB引擎所特有的日志,而MySQL Server层也有自己的日志,即 Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。
最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。而 InnoDB 是另一个公司以插件形式引入 MySQL 的,既然只依靠 binlog 是没有 crash-safe 能力的,所以 InnoDB 使用另外一套日志系统——也就是 redo log 来实现 crash-safe 能力。
Binlog日志有以下两个最重要的应用场景:
- 主从复制:在主库中开启Binlog功能,这样主库就可以把Binlog传递给从库,从库拿到Binlog后实现数据恢复达到主从数据一致性。
- 数据恢复:通过mysqlbinlog工具来恢复数据
Binlog日志文件记录模式有STATEMENT、ROW和MIXED三种,具体含义如下。
-
ROW(row-based replication, RBR):日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
优点:能清楚记录每一个行数据的修改细节,能完全实现主从数据同步和数据的恢复。
缺点:批量操作,会产生大量的日志,尤其是alter table会让日志暴涨。 -
STATMENT(statement-based replication, SBR):每一条被修改数据的SQL都会记录到master的Binlog中,slave在复制的时候SQL进程会解析成和原来master端执行过的相同的SQL再次执行。简称SQL语句复制。
优点:日志量小,减少磁盘IO,提升存储和恢复速度
缺点:在某些情况下会导致主从数据不一致,比如last_insert_id()、now()等函数。 -
MIXED(mixed-based replication, MBR):以上两种模式的混合使用,一般会使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择写入模式。
可通过以下sql查看Binlog信息
show variables like '%log_bin%';
show variables like '%binlog%';
格式查看
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.00 sec)
Biglog文件格式
MySQL的binlog文件中记录的是对数据库的各种修改操作,用来表示修改操作的数据结构是Log event。不同的修改操作对应的不同的log event。比较常用的log event有:Query event、Row event、Xid event等。binlog文件的内容就是各种Log event的集合。
Binlog文件中Log event结构如下图所示:

查看当前的二进制日志文件列表及大小。指令如下:
mysql> SHOW BINARY LOGS;
+---------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+---------------+-----------+-----------+
| binlog.000004 | 712684 | No |
| binlog.000005 | 179 | No |
| binlog.000006 | 179 | No |
| binlog.000007 | 3412930 | No |
+---------------+-----------+-----------+
4 rows in set (0.00 sec)
查看具体的文件
语法:show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
-- 文件内容太多了 这里限制了从 pos 156开始查看 限制5条
mysql> show binlog events in 'binlog.000004' from 156 limit 5 \G;
*************************** 1. row ***************************
Log_name: binlog.000004
Pos: 156
Event_type: Anonymous_Gtid
Server_id: 1
End_log_pos: 235
Info: SET @@SESSION.GTID_NEXT= 'ANONYMOUS'
*************************** 2. row ***************************
Log_name: binlog.000004
Pos: 235
Event_type: Query
Server_id: 1
End_log_pos: 317
Info: BEGIN
*************************** 3. row ***************************
Log_name: binlog.000004
Pos: 317
Event_type: Table_map
Server_id: 1
End_log_pos: 402
Info: table_id: 92 (small_admin.QRTZ_CRON_TRIGGERS)
*************************** 4. row ***************************
Log_name: binlog.000004
Pos: 402
Event_type: Delete_rows
Server_id: 1
End_log_pos: 502
Info: table_id: 92 flags: STMT_END_F
*************************** 5. row ***************************
Log_name: binlog.000004
Pos: 502
Event_type: Xid
Server_id: 1
End_log_pos: 533
Info: COMMIT /* xid=392 */
5 rows in set (0.00 sec)
binlog是二进制文件,无法直接查看,借助mysqlbinlog命令工具了,可以查看其中的内容
# mysqlbinlog使用语法
[root@node1 data]# mysqlbinlog --no-defaults --help
查看文件
mysqlbinlog --no-defaults --base64-output=decode-rows -vv binlog.000004 |tail -100
Binlog写入机制
事务执行过程中,先把日志写到 binlog cache,事务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。这就涉及到了 binlog cache 的保存问题。
系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。

write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。
但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
两段提交
结合redo log 跟bin log ,执行update test_redo set c = c + 1 where id = 1 这条语句的大致过程如下:
- 执行器先找引擎取 id=1 这一行。id 是主键,引擎直接用树搜索找到这一行。如果 id=1 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把c的值加 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。

Q:为什么需要两段提交?
A:用上面的更新语句作为例子
如果不用两阶段提交,要么就是先写完 redo log 再写 binlog,或者是先写binlog再写redo log,下面对这两种情况讨论
- 先写 redo log 后写 binlog。假设在 redo log 写完,binlog 还没有写完时MySQL 进程异常重启。由于redo log 写完后,系统即使崩溃,仍然能够把数据恢复回来,所以恢复后这一行 c 的值是 1。 但是由于 binlog 没写完, binlog 里面就没有记录这条语句。因此,之后备份日志的时候用这个 binlog 来恢复临时库的话,就会与原库的值有差异。
- 先写 binlog 后写 redo log。如果在 binlog 写完之后 crash,由于 redo log 还没写,崩溃恢复以后这个事务无效,所以这一行 c 的值是 0。但是 binlog 里面已经记录了“把 c 从 0 改成 1”这个日志。在之后用 binlog 来恢复的时候就会与原库有差异。
Q:上图中,如果在时刻A,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了奔溃呢?
A:由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库
Q:如果在B时刻,也就是 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理?
A:崩溃恢复时的判断如下
- 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
- 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整: a. 如果是,则提交事务; b. 否则,回滚事务。
Q:redo log 和 binlog 是怎么关联起来的?
A:它们有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:
如果碰到既有 prepare、又有 commit 的 redo log,就直接提交;
如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。