前言
这是面向初学者的Scala教程的第5部分。 该博客上还有其他文章,您可以在我正在为其创建的计算语言学课程的链接页面上找到这些链接和其他资源。 此外,您可以在“ JCG Java教程”页面上找到本教程和其他教程系列。
这篇文章是有关正则表达式(regexes)的两个文章中的第一篇,正则表达式对于广泛的编程任务,尤其是计算语言学任务至关重要。 本教程介绍了如何在Scala中使用它们,并假定读者已经熟悉正则表达式语法。 它展示了如何在Scala中创建正则表达式,以及如何将它们与Scala强大的模式匹配功能一起使用,尤其是在变量表达式和匹配表达式中的情况下。
创建正则表达式
Scala提供了一种非常简单的创建正则表达式的方法:只需将正则表达式定义为字符串,然后在其上调用r方法。 下面定义了表征字符串语言的正则表达式 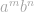 (一个或多个a后面跟一个或多个b ,不一定与a的数量相同)。
(一个或多个a后面跟一个或多个b ,不一定与a的数量相同)。
scala> val AmBn = "a+b+".r
AmBn: scala.util.matching.Regex = a+b+要使用元字符,如\ s , \ w和\ d ,您必须转义斜杠或使用多引号字符串,这称为原始字符串。 以下是两种等效的写正则表达式的方法,它覆盖一系列单词字符的字符串和一系列数字。
scala> val WordDigit1 = "\\w+\\d+".r
WordDigit1: scala.util.matching.Regex = \w+\d+
scala> val WordDigit2 = """\w+\d+""".r
WordDigit2: scala.util.matching.Regex = \w+\d+最好转义还是使用原始字符串取决于上下文。 例如,使用上面的代码,我将使用原始字符串。 但是,对于使用正则表达式在空白字符上分割字符串,转义在某种程度上是可取的。
scala> val adder = "We're as similar as two dissimilar things in a pod.\n\t-Blackadder"
adder: java.lang.String =
We're as similar as two dissimilar things in a pod.
-Blackadder
scala> adder.split("\\s+")
res2: Array[java.lang.String] = Array(We're, as, similar, as, two, dissimilar, things, in, a, pod., -Blackadder)
scala> adder.split("""\s+""")
res3: Array[java.lang.String] = Array(We're, as, similar, as, two, dissimilar, things, in, a, pod., -Blackadder)关于命名的注意事项:Scala中的约定是将变量名称的首字母大写用于正则表达式对象。 这使它们与在match语句中使用模式匹配一致,如下所示。
与正则表达式匹配
我们在上面看到,在String上使用r方法将返回一个正则表达式对象的值(有关下面的scala.util.matching部分的更多信息)。 您实际上如何使用这些Regex对象做有用的事情? 有很多方法。 对于非计算语言学家来说,最漂亮的,也许是最常见的,是将它们与Scala的标准模式匹配功能结合使用。 让我们考虑一下解析名称并将其转换为有用的数据结构以执行各种有用操作的任务。
scala> val Name = """(Mr|Mrs|Ms)\. ([A-Z][a-z]+) ([A-Z][a-z]+)""".r
Name: scala.util.matching.Regex = (Mr|Mrs|Ms)\. ([A-Z][a-z]+) ([A-Z][a-z]+)
scala> val Name(title, first, last) = "Mr. James Stevens"
title: String = Mr
first: String = James
last: String = Stevens
scala> val Name(title, first, last) = "Ms. Sally Kenton"
title: String = Ms
first: String = Sally
last: String = Kenton注意在Array和List之类的模式匹配上的相似性。
scala> val Array(title, first, last) = "Mr. James Stevens".split(" ")
title: java.lang.String = Mr.
first: java.lang.String = James
last: java.lang.String = Stevens
scala> val List(title, first, last) = "Mr. James Stevens".split(" ").toList
title: java.lang.String = Mr.
first: java.lang.String = James
last: java.lang.String = Stevens当然,请注意此处的“。” 被正则表达式切除时被捕获。 与正则表达式更实质性的区别在于,它只接受格式正确的字符串,而拒绝其他字符串,这与简单的拆分和与Array的匹配不同。
scala> val Array(title, first, last) = "221B Baker Street".split(" ")
title: java.lang.String = 221B
first: java.lang.String = Baker
last: java.lang.String = Street
scala> val Name(title, first, last) = "221B Baker Street"
scala.MatchError: 221B Baker Street (of class java.lang.String)
at .(:12)
at .()
at .(:11)
at .()
at $export()
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25)
at java.lang.reflect.Method.invoke(Method.java:597)
at scala.tools.nsc.interpreter.IMain$ReadEvalPrint.call(IMain.scala:592)
at scala.tools.nsc.interpreter.IMain$Request$$anonfun$10.apply(IMain.scala:828)
at scala.tools.nsc.interpreter.Line$$anonfun$1.apply$mcV$sp(Line.scala:43)
at scala.tools.nsc.io.package$$anon$2.run(package.scala:31)
at java.lang.Thread.run(Thread.java:680) 当然,这会让人抱怨很多,但实际上,您通常会(a)绝对确定自己的字符串格式正确,或者(b)将检查这种可能的异常,或者(c)将正则表达式用作匹配表达式中许多选项的一种。
现在,让我们假设输入是适当的。 这意味着我们可以使用map和match表达式轻松地将名称列表作为字符串转换为元组列表。
scala> val names = List("Mr. James Stevens", "Ms. Sally Kenton", "Mrs. Jane Doe", "Mr. John Doe", "Mr. James Smith")
names: List[java.lang.String] = List(Mr. James Stevens, Ms. Sally Kenton, Mrs. Jane Doe, Mr. John Doe, Mr. James Smith)
scala> names.map(x => x match { case Name(title, first, last) => (title, first, last) })
res11: List[(String, String, String)] = List((Mr,James,Stevens), (Ms,Sally,Kenton), (Mrs,Jane,Doe), (Mr,John,Doe), (Mr,James,Smith))注意名称正则表达式中组的关键用法:组的数量等于匹配中要初始化的变量的数量。 先生,太太和女士的替代品需要第一组。 没有其他组,我们会得到一个错误。 (从这里开始,我将缩短MatchError输出。)
scala> val NameOneGroup = """(Mr|Mrs|Ms)\. [A-Z][a-z]+ [A-Z][a-z]+""".r
NameOneGroup: scala.util.matching.Regex = (Mr|Mrs|Ms)\. [A-Z][a-z]+ [A-Z][a-z]+
scala> val NameOneGroup(title, first, last) = "Mr. James Stevens"
scala.MatchError: Mr. James Stevens (of class java.lang.String)当然,我们仍然可以匹配第一组。
scala> val NameOneGroup(title) = "Mr. James Stevens"
title: String = Mr如果我们朝另一个方向发展,创建更多的组,以便例如可以在各个标题中共享“ M”,该怎么办? 这是一个尝试。
scala> val NameShareM = """(M(r|rs|s))\. ([A-Z][a-z]+) ([A-Z][a-z]+)""".r
NameShareM: scala.util.matching.Regex = (M(r|rs|s))\. ([A-Z][a-z]+) ([A-Z][a-z]+)
scala> val NameShareM(title, first, last) = "Mr. James Stevens"
scala.MatchError: Mr. James Stevens (of class java.lang.String)发生的事情是创建了一个新组,因此现在有四个组可以匹配。
scala> val NameShareM(title, titleEnding, first, last) = "Mr. James Stevens"
title: String = Mr
titleEnding: String = r
first: String = James
last: String = Stevens
scala> val NameShareM(title, titleEnding, first, last) = "Mrs. Sally Kenton"
title: String = Mrs
titleEnding: String = rs
first: String = Sally
last: String = Kenton因此,存在子匹配的组捕获。 要阻止(r | rs | s)部分创建匹配组,同时仍然可以将其用于组合其他选择项,请使用? :运算符。
scala> val NameShareMThreeGroups = """(M(?:r|rs|s))\. ([A-Z][a-z]+) ([A-Z][a-z]+)""".r
NameShareMThreeGroups: scala.util.matching.Regex = (M(?:r|rs|s))\. ([A-Z][a-z]+) ([A-Z][a-z]+)
scala> val NameShareMThreeGroups(title, first, last) = "Mr. James Stevens"
title: String = Mr
first: String = James
last: String = Stevens至此,共享M并没有节省太多(Mr | Mrs | Ms) ,但是在很多情况下,这很有用。
我们还可以使用正则表达式反向引用。 假设我们要匹配“ John Bohn先生 ”,“ Joe Doe先生 ”和“ Jill Hill夫人 ”之类的名字。
scala> val RhymeName = """(Mr|Mrs|Ms)\. ([A-Z])([a-z]+) ([A-Z])\3""".r
RhymeName: scala.util.matching.Regex = (Mr|Mrs|Ms)\. ([A-Z])([a-z]+) ([A-Z])\3
scala> val RhymeName(title, firstInitial, firstRest, lastInitial) = "Mr. John Bohn"
title: String = Mr
firstInitial: String = J
firstRest: String = ohn
lastInitial: String = B然后,我们可以将事情拼凑起来,以获得我们想要的名称。
scala> val first = firstInitial+firstRest
first: java.lang.String = John
scala> val last = lastInitial+firstRest
last: java.lang.String = Bohn但是我们可以通过使用嵌入式组并仅将其匹配结果与下划线_相去掉来做得更好。
scala> val RhymeName2 = """(Mr|Mrs|Ms)\. ([A-Z]([a-z]+)) ([A-Z]\3)""".r
RhymeName2: scala.util.matching.Regex = (Mr|Mrs|Ms)\. ([A-Z]([a-z]+)) ([A-Z]\3)
scala> val RhymeName2(title, first, _, last) = "Mr. John Bohn"
title: String = Mr
first: String = John
last: String = Bohn注意 :我们不能将?:运算符与([az] +)一起使用来停止匹配,因为稍后我们需要该字符串与\ 3进行匹配。
使用正则表达式通过模式匹配进行分配需要完整的字符串匹配。
scala> val Name(title, first, last) = "Mr. James Stevens"
title: String = Mr
first: String = James
last: String = Stevens
scala> val Name(title, first, last) = "Mr. James Stevens walked to the door."
scala.MatchError: Mr. James Stevens walked to the door. (of class java.lang.String)这是在匹配表达式中使用它们的关键方面。 考虑一个需要能够解析不同格式的电话号码的应用程序,例如(123)555-5555和123-555-5555 。 这是这两种模式的正则表达式,以及它们用于解析这些数字的正则表达式。
scala> val Phone1 = """\((\d{3})\)\s*(\d{3})-(\d{4})""".r
Phone1: scala.util.matching.Regex = \((\d{3})\)\s*(\d{3})-(\d{4})
scala> val Phone2 = """(\d{3})-(\d{3})-(\d{4})""".r
Phone2: scala.util.matching.Regex = (\d{3})-(\d{3})-(\d{4})
scala> val Phone1(area, first3, last4) = "(123) 555-5555"
area: String = 123
first3: String = 555
last4: String = 5555
scala> val Phone2(area, first3, last4) = "123-555-5555"
area: String = 123
first3: String = 555
last4: String = 5555我们当然可以使用单个正则表达式,但是我们将同时使用这两个正则表达式,以便它们可以在match表达式中用作单独的case语句,该match表达式是采用电话号码的字符串表示形式并返回a的函数的一部分三个字符串的元组(从而将数字标准化)。
def normalizePhoneNumber (number: String) = number match {
case Phone1(x,y,z) => (x,y,z)
case Phone2(x,y,z) => (x,y,z)
}每场比赛所采取的行动只是将单独的值打包到一个Tuple3中 —如果人们正在寻找国家/地区代码,与多个国家打交道等,那么可能会做更多有趣的事情。这里的目的是看看正则表达式如何用于案例来捕获值并将它们分配给局部变量,每次都适合于所引入的字符串的形式。(我们将在后面的教程中看到如何保护这种方法不受非电话输入的影响)数字等。)
现在有了该功能,我们可以轻松地将其应用于代表电话号码的字符串列表,并仅过滤掉特定区域中的那些字符串。
scala> val numbers = List("(123) 555-5555", "123-555-5555", "(321) 555-0000")
numbers: List[java.lang.String] = List((123) 555-5555, 123-555-5555, (321) 555-0000)
scala> numbers.map(normalizePhoneNumber)
res16: List[(String, String, String)] = List((123,555,5555), (123,555,5555), (321,555,0000))
scala> numbers.map(normalizePhoneNumber).filter(n => n._1=="123")
res17: List[(String, String, String)] = List((123,555,5555), (123,555,5555))从字符串构建正则表达式
有时,人们希望从较小的组成部分中构建正则表达式,例如,定义什么是名词短语,然后搜索名词短语的序列。 为此,我们首先必须看到创建正则表达式的较长形式。
scala> val AmBn = new scala.util.matching.Regex("a+b+")
AmBn: scala.util.matching.Regex = a+b+这是在这些教程中我们第一次使用保留字new显式创建对象。 稍后我们将更详细地介绍对象,但是您现在需要知道的是Scala具有很多默认情况下不可用的功能。 通常,我们一直在使用诸如Strings,Ints,Doubles,List等之类的东西,并且在大多数情况下,它们看起来像是“只是” String,Ints,Doubles和Lists。 但是,事实并非如此:实际上,它们被完全指定为:
- java.lang.String
- scala.Int
- 斯卡拉
- 标量表
而且,对于最后一个, scala.List是一种类型,实际上由scala.collection.immutable.List中的具体实现支持。 因此,当您仅看到“列表”时,Scala实际上就隐藏了一些细节。 最重要的是,它使得使用非常常见的类型而不必大惊小怪。
什么scala.util.matching.Regex告诉你的是,正则表达式类是scala.util.matching包的一部分(和scala.util.matching是scala.util的子包,这本身就是阶的子包包)。 幸运的是,您不需要每次使用Regex时都键入scala.util.matching :只需使用import语句,然后使用Regex而无需额外的程序包规范。
scala> import scala.util.matching.Regex
import scala.util.matching.Regex
scala> val AmBn = new Regex("a+b+")
AmBn: scala.util.matching.Regex = a+b+另一件事要解释的是新部分。 再次,我们将在以后更详细地介绍这一点,但是现在请按照以下方式考虑它。 Regex类就像一个生产正则表达式对象的工厂,而您请求(订购)这些对象之一的方式是说“ new Regex(…) ”,其中…表示应用于定义...的属性的字符串。该对象。 实际上,在创建Lists,Ints和Doubles时,已经做了很多工作,但是同样,对于这些核心类型,Scala提供了特殊的语法来简化其创建和使用。
好的,但是当可以使用“ a + b +”。r进行相同的操作时,为什么还要使用新的Regex(“ a + b +”)呢? 原因如下:后者需要提供完整的字符串,但是前者可以由多个String变量构建。 例如,假设您想要一个正则表达式,其匹配形式为“ the / a dog / cat / mouse / bird chased / ate the / a dog / cat / mouse / bird ”的字符串,例如“ the dog chaused the cat ”和“ 猫追了那只鸟 。” 以下可能是第一次尝试。
scala> val Transitive = "(a|the) (dog|cat|mouse|bird) (chased|ate) (a|the) (dog|cat|mouse|bird)".r
Transitive: scala.util.matching.Regex = (a|the) (dog|cat|mouse|bird) (chased|ate) (a|the) (dog|cat|mouse|bird)这是可行的,但我们也可以通过使用包含定义正则表达式(但不是 Regex对象本身)的String的变量并使用它构建正则表达式,而无需重复两次相同的表达式来构建它。
scala> val nounPhrase = "(a|the) (dog|cat|mouse|bird)"
nounPhrase: java.lang.String = (a|the) (dog|cat|mouse|bird)
scala> val Transitive = new Regex(nounPhrase + " (chased|ate) " + nounPhrase)
Transitive: scala.util.matching.Regex = (a|the) (dog|cat|mouse|bird) (chased|ate) (a|the) (dog|cat|mouse|bird)下一个教程将展示如何使用scala.util.matching包API与正则表达式进行更广泛的匹配,例如查找多个匹配项并执行替换。
参考: Scala入门的第一步,是我们的JCG合作伙伴 Jason Baldridge在Bcomposes博客上的第5部分 。
相关文章 :
- Scala教程– Scala REPL,表达式,变量,基本类型,简单函数,保存和运行程序,注释
- Scala教程–元组,列表,列表和字符串上的方法
- Scala教程–使用if-else块和匹配条件执行
- Scala教程–迭代,用于表达式,产量,图,过滤器,计数
- Scala教程–使用scala.util.matching API进行正则表达式,匹配和替换
- Scala教程–地图,集,groupBy,选项,展平,flatMap
- Scala教程– scala.io.Source,访问文件,flatMap,可变地图
- Scala教程–对象,类,继承,特征,具有多个相关类型的列表,适用
- Scala教程–脚本编写,编译,主要方法,函数的返回值
- Scala教程– SBT,scalabha,软件包,构建系统
- Scala教程–代码块,编码样式,闭包,scala文档项目
- Scala中功能组合的乐趣
- Scala如何改变了我对Java代码的思考方式
- 用Scala测试
- 每个程序员都应该知道的事情
翻译自: https://www.javacodegeeks.com/2011/10/scala-tutorial-regular-expressions.html