一网打尽Flink中的时间、窗口和流Join
点击上方蓝色字体,选择“设为星标”
回复”面试“获取更多惊喜
![]()
首先,我们会学习如何定义时间属性,时间戳和水位线。然后我们将会学习底层操作process function,它可以让我们访问时间戳和水位线,以及注册定时器事件。接下来,我们将会使用Flink的window API,它提供了通常使用的各种窗口类型的内置实现。我们将会学到如何进行用户自定义窗口操作符,以及窗口的核心功能:assigners(分配器)、triggers(触发器)和evictors(清理器)。最后,我们将讨论如何基于时间来做流的联结查询,以及处理迟到事件的策略。
时间操作
1 设置时间属性
如果我们想要在分布式流处理应用程序中定义有关时间的操作,彻底理解时间的语义是非常重要的。当我们指定了一个窗口去收集某1分钟内的数据时,这个长度为1分钟的桶中,到底应该包含哪些数据?在DataStream API中,我们将使用时间属性来告诉Flink:当我们创建窗口时,我们如何定义时间。时间属性是StreamExecutionEnvironment的一个属性,有以下值:
ProcessingTime
机器时间在分布式系统中又叫做“墙上时钟”。
当操作符执行时,此操作符看到的时间是操作符所在机器的机器时间。Processing-time window的触发取决于机器时间,窗口包含的元素也是那个机器时间段内到达的元素。通常情况下,窗口操作符使用processing time会导致不确定的结果,因为基于机器时间的窗口中收集的元素取决于元素到达的速度快慢。使用processing time会为程序提供极低的延迟,因为无需等待水位线的到达。
如果要追求极限的低延迟,请使用processing time。
EventTime
当操作符执行时,操作符看的当前时间是由流中元素所携带的信息决定的。流中的每一个元素都必须包含时间戳信息。而系统的逻辑时钟由水位线(Watermark)定义。我们之前学习过,时间戳要么在事件进入流处理程序之前已经存在,要么就需要在程序的数据源(source)处进行分配。当水位线宣布特定时间段的数据都已经到达,事件时间窗口将会被触发计算。即使数据到达的顺序是乱序的,事件时间窗口的计算结果也将是确定性的。窗口的计算结果并不取决于元素到达的快与慢。
当水位线超过事件时间窗口的结束时间时,窗口将会闭合,不再接收数据,并触发计算。
IngestionTime
当事件进入source操作符时,source操作符所在机器的机器时间,就是此事件的“摄入时间”(IngestionTime),并同时产生水位线。IngestionTime相当于EventTime和ProcessingTime的混合体。一个事件的IngestionTime其实就是它进入流处理器中的时间。
IngestionTime没什么价值,既有EventTime的执行效率(比较低),有没有EventTime计算结果的准确性。
下面的例子展示了如何设置事件时间。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment;
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream sensorData = env.addSource(...);
如果要使用processing time,将TimeCharacteristic.EventTime替换为TimeCharacteristic.ProcessingTIme就可以了。
1.1 指定时间戳和产生水位线
如果使用事件时间,那么流中的事件必须包含这个事件真正发生的时间。使用了事件时间的流必须携带水位线。
时间戳和水位线的单位是毫秒,记时从1970-01-01T00:00:00Z开始。到达某个操作符的水位线就会告知这个操作符:小于等于水位线中携带的时间戳的事件都已经到达这个操作符了。时间戳和水位线可以由SourceFunction产生,或者由用户自定义的时间戳分配器和水位线产生器来生成。
Flink暴露了TimestampAssigner接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳。一般来说,时间戳分配器需要在source操作符后马上进行调用。
因为时间戳分配器看到的元素的顺序应该和source操作符产生数据的顺序是一样的,否则就乱了。这就是为什么我们经常将source操作符的并行度设置为1的原因。
也就是说,任何分区操作都会将元素的顺序打乱,例如:并行度改变,keyBy()操作等等。
所以最佳实践是:在尽量接近数据源source操作符的地方分配时间戳和产生水位线,甚至最好在SourceFunction中分配时间戳和产生水位线。当然在分配时间戳和产生水位线之前可以对流进行map和filter操作是没问题的,也就是说必须是窄依赖。
以下这种写法是可以的。
DataStream stream = env
.addSource(...)
.map(...)
.filter(...)
.assignTimestampsAndWatermarks(...)
下面的例子展示了首先filter流,然后再分配时间戳和水位线。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment;
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream readings = env
.addSource(new SensorSource)
.filter(r -> r.temperature > 25)
.assignTimestampsAndWatermarks(new MyAssigner());
MyAssigner有两种类型
AssignerWithPeriodicWatermarks
AssignerWithPunctuatedWatermarks
以上两个接口都继承自TimestampAssigner。
1.2 周期性的生成水位线
周期性的生成水位线:系统会周期性的将水位线插入到流中(水位线也是一种特殊的事件!)。默认周期是200毫秒,也就是说,系统会每隔200毫秒就往流中插入一次水位线。
这里的200毫秒是机器时间!
可以使用ExecutionConfig.setAutoWatermarkInterval()方法进行设置。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 每隔5秒产生一个水位线
env.getConfig.setAutoWatermarkInterval(5000)
上面的例子产生水位线的逻辑:每隔5秒钟,Flink会调用AssignerWithPeriodicWatermarks中的getCurrentWatermark()方法。如果方法返回的时间戳大于之前水位线的时间戳,新的水位线会被插入到流中。这个检查保证了水位线是单调递增的。如果方法返回的时间戳小于等于之前水位线的时间戳,则不会产生新的水位线。
例子,自定义一个周期性的时间戳抽取
scala version
class PeriodicAssigner extends AssignerWithPeriodicWatermarks[SensorReading] {
val bound = 60 * 1000 // 延时为1分钟
var maxTs = Long.MinValue + bound + 1 // 观察到的最大时间戳
override def getCurrentWatermark: Watermark {
new Watermark(maxTs - bound - 1)
}
override def extractTimestamp(r: SensorReading, previousTS: Long) {
maxTs = maxTs.max(r.timestamp)
r.timestamp
}
}
java version
.assignTimestampsAndWatermarks(
// generate periodic watermarks
new AssignerWithPeriodicWatermarks[(String, Long)] {
val bound = 10 * 1000L // 最大延迟时间
var maxTs = Long.MinValue + bound + 1 // 当前观察到的最大时间戳
// 用来生成水位线
// 默认200ms调用一次
override def getCurrentWatermark: Watermark = {
println("generate watermark!!!" + (maxTs - bound - 1) + "ms")
new Watermark(maxTs - bound - 1)
}
// 每来一条数据都会调用一次
override def extractTimestamp(t: (String, Long), l: Long): Long = {
println("extract timestamp!!!")
maxTs = maxTs.max(t._2) // 更新观察到的最大事件时间
t._2 // 抽取时间戳
}
}
)
如果我们事先得知数据流的时间戳是单调递增的,也就是说没有乱序。我们可以使用assignAscendingTimestamps,方法会直接使用数据的时间戳生成水位线。
scala version
val stream = ...
val withTimestampsAndWatermarks = stream.assignAscendingTimestamps(e => e.timestamp)
java version
.assignTimestampsAndWatermarks(
WatermarkStrategy
.forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner() {
@Override
public long extractTimestamp(SensorReading r, long l) {
return r.timestamp;
}
})
)
如果我们能大致估算出数据流中的事件的最大延迟时间,可以使用如下代码:
最大延迟时间就是当前到达的事件的事件时间和之前所有到达的事件中最大时间戳的差。
scala version
.assignTimestampsAndWatermarks(
// 水位线策略;默认200ms的机器时间插入一次水位线
// 水位线 = 当前观察到的事件所携带的最大时间戳 - 最大延迟时间
WatermarkStrategy
// 最大延迟时间设置为5s
.forBoundedOutOfOrderness[(String, Long)](Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner[(String, Long)] {
// 告诉系统第二个字段是时间戳,时间戳的单位是毫秒
override def extractTimestamp(element: (String, Long), recordTimestamp: Long): Long = element._2
})
)
java version
.assignTimestampsAndWatermarks(
WatermarkStrategy
.>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 element, long recordTimestamp) {
return element.f1;
}
})
)
以上代码设置了最大延迟时间为5秒。
1.3 如何产生不规则的水位线
有时候输入流中会包含一些用于指示系统进度的特殊元组或标记。Flink为此类情形以及可根据输入元素生成水位线的情形提供了AssignerWithPunctuatedWatermarks接口。该接口中的checkAndGetNextWatermark()方法会在针对每个事件的extractTimestamp()方法后立即调用。它可以决定是否生成一个新的水位线。如果该方法返回一个非空、且大于之前值的水位线,算子就会将这个新水位线发出。
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[SensorReading] {
val bound = 60 * 1000
// 每来一条数据就调用一次
// 紧跟`extractTimestamp`函数调用
override def checkAndGetNextWatermark(r: SensorReading, extractedTS: Long) {
if (r.id == "sensor_1") {
// 抽取的时间戳 - 最大延迟时间
new Watermark(extractedTS - bound)
} else {
null
}
}
// 每来一条数据就调用一次
override def extractTimestamp(r: SensorReading, previousTS: Long) {
r.timestamp
}
}
现在我们已经知道如何使用 TimestampAssigner 来产生水位线了。现在我们要讨论一下水位线会对我们的程序产生什么样的影响。
水位线用来平衡延迟和计算结果的正确性。水位线告诉我们,在触发计算(例如关闭窗口并触发窗口计算)之前,我们需要等待事件多长时间。基于事件时间的操作符根据水位线来衡量系统的逻辑时间的进度。
完美的水位线永远不会错:时间戳小于水位线的事件不会再出现。在特殊情况下(例如非乱序事件流),最近一次事件的时间戳就可能是完美的水位线。启发式水位线则相反,它只估计时间,因此有可能出错,即迟到的事件(其时间戳小于水位线标记时间)晚于水位线出现。针对启发式水位线,Flink提供了处理迟到元素的机制。
设定水位线通常需要用到领域知识。举例来说,如果知道事件的迟到时间不会超过5秒,就可以将水位线标记时间设为收到的最大时间戳减去5秒。另一种做法是,采用一个Flink作业监控事件流,学习事件的迟到规律,并以此构建水位线生成模型。
如果最大延迟时间设置的很大,计算出的结果会更精确,但收到计算结果的速度会很慢,同时系统会缓存大量的数据,并对系统造成比较大的压力。如果最大延迟时间设置的很小,那么收到计算结果的速度会很快,但可能收到错误的计算结果。不过Flink处理迟到数据的机制可以解决这个问题。上述问题看起来很复杂,但是恰恰符合现实世界的规律:大部分真实的事件流都是乱序的,并且通常无法了解它们的乱序程度(因为理论上不能预见未来)。水位线是唯一让我们直面乱序事件流并保证正确性的机制; 否则只能选择忽视事实,假装错误的结果是正确的。
思考题一:实时程序,要求实时性非常高,并且结果并不一定要求非常准确,那么应该怎么办?
回答:直接使用处理时间。
思考题二:如果要进行时间旅行,也就是要还原以前的数据集当时的流的状态,应该怎么办?
回答:使用事件时间。使用Hive将数据集先按照时间戳升序排列,再将最大延迟时间设置为0。
2 处理函数
我们之前学习的转换算子是无法访问事件的时间戳信息和水位线信息的。而这在一些应用场景下,极为重要。例如MapFunction这样的map转换算子就无法访问时间戳或者当前事件的事件时间。
基于此,DataStream API提供了一系列的Low-Level转换算子。可以访问时间戳、水位线以及注册定时事件。还可以输出特定的一些事件,例如超时事件等。Process Function用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的window函数和转换算子无法实现)。例如,Flink-SQL就是使用Process Function实现的。
Flink提供了8个Process Function:
ProcessFunction
KeyedProcessFunction
CoProcessFunction
ProcessJoinFunction
BroadcastProcessFunction
KeyedBroadcastProcessFunction
ProcessWindowFunction
ProcessAllWindowFunction
我们这里详细介绍一下KeyedProcessFunction。
KeyedProcessFunction用来操作KeyedStream。KeyedProcessFunction会处理流的每一个元素,输出为0个、1个或者多个元素。所有的Process Function都继承自RichFunction接口,所以都有open()、close()和getRuntimeContext()等方法。而KeyedProcessFunction[KEY, IN, OUT]还额外提供了两个方法:
processElement(v: IN, ctx: Context, out: Collector[OUT]), 流中的每一个元素都会调用这个方法,调用结果将会放在Collector数据类型中输出。Context可以访问元素的时间戳,元素的key,以及TimerService时间服务。Context还可以将结果输出到别的流(side outputs)。
onTimer(timestamp: Long, ctx: OnTimerContext, out: Collector[OUT])是一个回调函数。当之前注册的定时器触发时调用。参数timestamp为定时器所设定的触发的时间戳。Collector为输出结果的集合。OnTimerContext和processElement的Context参数一样,提供了上下文的一些信息,例如firing trigger的时间信息(事件时间或者处理时间)。
2.1 时间服务和定时器
Context和OnTimerContext所持有的TimerService对象拥有以下方法:
currentProcessingTime(): Long 返回当前处理时间
currentWatermark(): Long 返回当前水位线的时间戳
registerProcessingTimeTimer(timestamp: Long): Unit 会注册当前key的processing time的timer。当processing time到达定时时间时,触发timer。
registerEventTimeTimer(timestamp: Long): Unit 会注册当前key的event time timer。当水位线大于等于定时器注册的时间时,触发定时器执行回调函数。
deleteProcessingTimeTimer(timestamp: Long): Unit 删除之前注册处理时间定时器。如果没有这个时间戳的定时器,则不执行。
deleteEventTimeTimer(timestamp: Long): Unit 删除之前注册的事件时间定时器,如果没有此时间戳的定时器,则不执行。
当定时器timer触发时,执行回调函数onTimer()。processElement()方法和onTimer()方法是同步(不是异步)方法,这样可以避免并发访问和操作状态。
针对每一个key和timestamp,只能注册一个定期器。也就是说,每一个key可以注册多个定时器,但在每一个时间戳只能注册一个定时器。KeyedProcessFunction默认将所有定时器的时间戳放在一个优先队列中。在Flink做检查点操作时,定时器也会被保存到状态后端中。
举个例子说明KeyedProcessFunction如何操作KeyedStream。
下面的程序展示了如何监控温度传感器的温度值,如果温度值在一秒钟之内(processing time)连续上升,报警。
scala version
val warnings = readings
.keyBy(r => r.id)
.process(new TempIncreaseAlertFunction)
class TempIncrease extends KeyedProcessFunction[String, SensorReading, String] {
// 懒加载;
// 状态变量会在检查点操作时进行持久化,例如hdfs
// 只会初始化一次,单例模式
// 在当机重启程序时,首先去持久化设备寻找名为`last-temp`的状态变量,如果存在,则直接读取。不存在,则初始化。
// 用来保存最近一次温度
// 默认值是0.0
lazy val lastTemp: ValueState[Double] = getRuntimeContext.getState(
new ValueStateDescriptor[Double]("last-temp", Types.of[Double])
)
// 默认值是0L
lazy val timer: ValueState[Long] = getRuntimeContext.getState(
new ValueStateDescriptor[Long]("timer", Types.of[Long])
)
override def processElement(value: SensorReading, ctx: KeyedProcessFunction[String, SensorReading, String]#Context, out: Collector[String]): Unit = {
// 使用`.value()`方法取出最近一次温度值,如果来的温度是第一条温度,则prevTemp为0.0
val prevTemp = lastTemp.value()
// 将到来的这条温度值存入状态变量中
lastTemp.update(value.temperature)
// 如果timer中有定时器的时间戳,则读取
val ts = timer.value()
if (prevTemp == 0.0 || value.temperature < prevTemp) {
ctx.timerService().deleteProcessingTimeTimer(ts)
timer.clear()
} else if (value.temperature > prevTemp && ts == 0) {
val oneSecondLater = ctx.timerService().currentProcessingTime() + 1000L
ctx.timerService().registerProcessingTimeTimer(oneSecondLater)
timer.update(oneSecondLater)
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, SensorReading, String]#OnTimerContext, out: Collector[String]): Unit = {
out.collect("传感器ID是 " + ctx.getCurrentKey + " 的传感器的温度连续1s上升了!")
timer.clear()
}
}
java version
DataStream warings = readings
.keyBy(r -> r.id)
.process(new TempIncreaseAlertFunction());
看一下TempIncreaseAlertFunction如何实现, 程序中使用了ValueState这样一个状态变量, 后面会详细讲解。
public static class TempIncreaseAlertFunction extends KeyedProcessFunction {
private ValueState lastTemp;
private ValueState currentTimer;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
lastTemp = getRuntimeContext().getState(
new ValueStateDescriptor<>("last-temp", Types.DOUBLE)
);
currentTimer = getRuntimeContext().getState(
new ValueStateDescriptor<>("current-timer", Types.LONG)
);
}
@Override
public void processElement(SensorReading r, Context ctx, Collector out) throws Exception {
// 取出上一次的温度
Double prevTemp = 0.0;
if (lastTemp.value() != null) {
prevTemp = lastTemp.value();
}
// 将当前温度更新到上一次的温度这个变量中
lastTemp.update(r.temperature);
Long curTimerTimestamp = 0L;
if (currentTimer.value() != null) {
curTimerTimestamp = currentTimer.value();
}
if (prevTemp == 0.0 || r.temperature < prevTemp) {
// 温度下降或者是第一个温度值,删除定时器
ctx.timerService().deleteProcessingTimeTimer(curTimerTimestamp);
// 清空状态变量
currentTimer.clear();
} else if (r.temperature > prevTemp && curTimerTimestamp == 0) {
// 温度上升且我们并没有设置定时器
long timerTs = ctx.timerService().currentProcessingTime() + 1000L;
ctx.timerService().registerProcessingTimeTimer(timerTs);
// 保存定时器时间戳
currentTimer.update(timerTs);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
super.onTimer(timestamp, ctx, out);
out.collect("传感器id为: "
+ ctx.getCurrentKey()
+ "的传感器温度值已经连续1s上升了。");
currentTimer.clear();
}
}
2.2 将事件发送到侧输出
大部分的DataStream API的算子的输出是单一输出,也就是某种数据类型的流。除了split算子,可以将一条流分成多条流,这些流的数据类型也都相同。process function的side outputs功能可以产生多条流,并且这些流的数据类型可以不一样。一个side output可以定义为OutputTag[X]对象,X是输出流的数据类型。process function可以通过Context对象发射一个事件到一个或者多个side outputs。
例子
scala version
object SideOutputExample {
val output = new OutputTag[String]("side-output")
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource)
val warnings = stream
.process(new FreezingAlarm)
warnings.print() // 打印主流
warnings.getSideOutput(output).print() // 打印侧输出流
env.execute()
}
class FreezingAlarm extends ProcessFunction[SensorReading, SensorReading] {
override def processElement(value: SensorReading, ctx: ProcessFunction[SensorReading, SensorReading]#Context, out: Collector[SensorReading]): Unit = {
if (value.temperature < 32.0) {
ctx.output(output, "传感器ID为:" + value.id + "的传感器温度小于32度!")
}
out.collect(value)
}
}
}
java version
public class SideOutputExample {
private static OutputTag output = new OutputTag("side-output"){};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream stream = env.addSource(new SensorSource());
SingleOutputStreamOperator warnings = stream
.process(new ProcessFunction() {
@Override
public void processElement(SensorReading value, Context ctx, Collector out) throws Exception {
if (value.temperature < 32) {
ctx.output(output, "温度小于32度!");
}
out.collect(value);
}
});
warnings.print();
warnings.getSideOutput(output).print();
env.execute();
}
}
2.3 CoProcessFunction
对于两条输入流,DataStream API提供了CoProcessFunction这样的low-level操作。CoProcessFunction提供了操作每一个输入流的方法: processElement1()和processElement2()。类似于ProcessFunction,这两种方法都通过Context对象来调用。这个Context对象可以访问事件数据,定时器时间戳,TimerService,以及side outputs。CoProcessFunction也提供了onTimer()回调函数。下面的例子展示了如何使用CoProcessFunction来合并两条流。
scala version
object SensorSwitch {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.addSource(new SensorSource).keyBy(r => r.id)
val switches = env.fromElements(("sensor_2", 10 * 1000L)).keyBy(r => r._1)
stream
.connect(switches)
.process(new SwitchProcess)
.print()
env.execute()
}
class SwitchProcess extends CoProcessFunction[SensorReading, (String, Long), SensorReading] {
lazy val forwardSwitch = getRuntimeContext.getState(
new ValueStateDescriptor[Boolean]("switch", Types.of[Boolean])
)
override def processElement1(value: SensorReading, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = {
if (forwardSwitch.value()) {
out.collect(value)
}
}
override def processElement2(value: (String, Long), ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#Context, out: Collector[SensorReading]): Unit = {
forwardSwitch.update(true)
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + value._2)
}
override def onTimer(timestamp: Long, ctx: CoProcessFunction[SensorReading, (String, Long), SensorReading]#OnTimerContext, out: Collector[SensorReading]): Unit = {
forwardSwitch.clear()
}
}
}
java version
public class SensorSwitch {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
KeyedStream stream = env
.addSource(new SensorSource())
.keyBy(r -> r.id);
KeyedStream, String> switches = env
.fromElements(Tuple2.of("sensor_2", 10 * 1000L))
.keyBy(r -> r.f0);
stream
.connect(switches)
.process(new SwitchProcess())
.print();
env.execute();
}
public static class SwitchProcess extends CoProcessFunction, SensorReading> {
private ValueState forwardingEnabled;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
forwardingEnabled = getRuntimeContext().getState(
new ValueStateDescriptor<>("filterSwitch", Types.BOOLEAN)
);
}
@Override
public void processElement1(SensorReading value, Context ctx, Collector out) throws Exception {
if (forwardingEnabled.value() != null && forwardingEnabled.value()) {
out.collect(value);
}
}
@Override
public void processElement2(Tuple2 value, Context ctx, Collector out) throws Exception {
forwardingEnabled.update(true);
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + value.f1);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
super.onTimer(timestamp, ctx, out);
forwardingEnabled.clear();
}
}
}
窗口操作
1 窗口操作符
窗口操作是流处理程序中很常见的操作。窗口操作允许我们在无限流上的一段有界区间上面做聚合之类的操作。而我们使用基于时间的逻辑来定义区间。窗口操作符提供了一种将数据放进一个桶,并根据桶中的数据做计算的方法。例如,我们可以将事件放进5分钟的滚动窗口中,然后计数。
无限流转化成有限数据的方法:使用窗口。
1.1 定义窗口操作符
Window算子可以在keyed stream或者nokeyed stream上面使用。
创建一个Window算子,需要指定两个部分:
window assigner定义了流的元素如何分配到window中。window assigner将会产生一条WindowedStream(或者AllWindowedStream,如果是nonkeyed DataStream的话)
window function用来处理WindowedStream(AllWindowedStream)中的元素。
下面的代码说明了如何使用窗口操作符。
stream
.keyBy(...)
.window(...) // 指定window assigner
.reduce/aggregate/process(...) // 指定window function
stream
.windowAll(...) // 指定window assigner
.reduce/aggregate/process(...) // 指定window function
我们的学习重点是Keyed WindowedStream。
1.2 内置的窗口分配器
窗口分配器将会根据事件的事件时间或者处理时间来将事件分配到对应的窗口中去。窗口包含开始时间和结束时间这两个时间戳。
所有的窗口分配器都包含一个默认的触发器:
对于事件时间:当水位线超过窗口结束时间,触发窗口的求值操作。
对于处理时间:当机器时间超过窗口结束时间,触发窗口的求值操作。
需要注意的是:当处于某个窗口的第一个事件到达的时候,这个窗口才会被创建。Flink不会对空窗口求值。
Flink创建的窗口类型是TimeWindow,包含开始时间和结束时间,区间是左闭右开的,也就是说包含开始时间戳,不包含结束时间戳。
滚动窗口(tumbling windows)

DataStream sensorData = ...
DataStream avgTemp = sensorData
.keyBy(r -> r.id)
// group readings in 1s event-time windows
.window(TumblingEventTimeWindows.of(Time.seconds(1)))
.process(new TemperatureAverager);
DataStream avgTemp = sensorData
.keyBy(r -> r.id)
// group readings in 1s processing-time windows
.window(TumblingProcessingTimeWindows.of(Time.seconds(1)))
.process(new TemperatureAverager);
// 其实就是之前的
// shortcut for window.(TumblingEventTimeWindows.of(size))
DataStream avgTemp = sensorData
.keyBy(r -> r.id)
.timeWindow(Time.seconds(1))
.process(new TemperatureAverager);
默认情况下,滚动窗口会和1970-01-01-00:00:00.000对齐,例如一个1小时的滚动窗口将会定义以下开始时间的窗口:00:00:00,01:00:00,02:00:00,等等。
滑动窗口(sliding window)
对于滑动窗口,我们需要指定窗口的大小和滑动的步长。当滑动步长小于窗口大小时,窗口将会出现重叠,而元素会被分配到不止一个窗口中去。当滑动步长大于窗口大小时,一些元素可能不会被分配到任何窗口中去,会被直接丢弃。
下面的代码定义了窗口大小为1小时,滑动步长为15分钟的窗口。每一个元素将被分配到4个窗口中去。
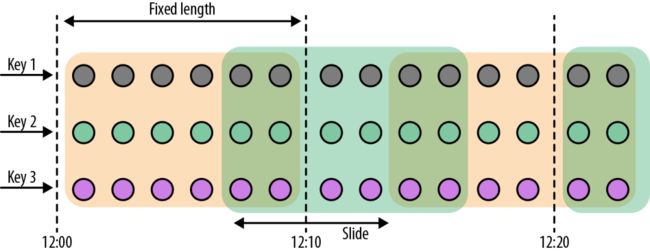
DataStream slidingAvgTemp = sensorData
.keyBy(r -> r.id)
.window(
SlidingEventTimeWindows.of(Time.hours(1), Time.minutes(15))
)
.process(new TemperatureAverager);
DataStream slidingAvgTemp = sensorData
.keyBy(r -> r.id)
.window(
SlidingProcessingTimeWindows.of(Time.hours(1), Time.minutes(15))
)
.process(new TemperatureAverager);
DataStream slidingAvgTemp = sensorData
.keyBy(r -> r.id)
.timeWindow(Time.hours(1), Time.minutes(15))
.process(new TemperatureAverager);
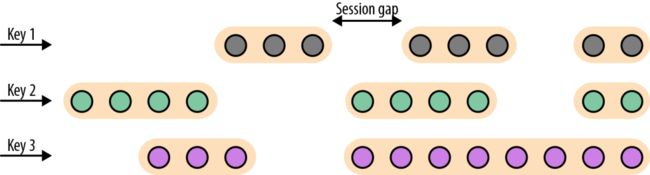
会话窗口(session windows)
会话窗口不可能重叠,并且会话窗口的大小也不是固定的。不活跃的时间长度定义了会话窗口的界限。不活跃的时间是指这段时间没有元素到达。下图展示了元素如何被分配到会话窗口。
DataStream sessionWindows = sensorData
.keyBy(r -> r.id)
.window(EventTimeSessionWindows.withGap(Time.minutes(15)))
.process(...);
DataStream sessionWindows = sensorData
.keyBy(r -> r.id)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(15)))
.process(...);
由于会话窗口的开始时间和结束时间取决于接收到的元素,所以窗口分配器无法立即将所有的元素分配到正确的窗口中去。相反,会话窗口分配器最开始时先将每一个元素分配到它自己独有的窗口中去,窗口开始时间是这个元素的时间戳,窗口大小是session gap的大小。接下来,会话窗口分配器会将出现重叠的窗口合并成一个窗口。
1.3 调用窗口计算函数
window functions定义了窗口中数据的计算逻辑。有两种计算逻辑:
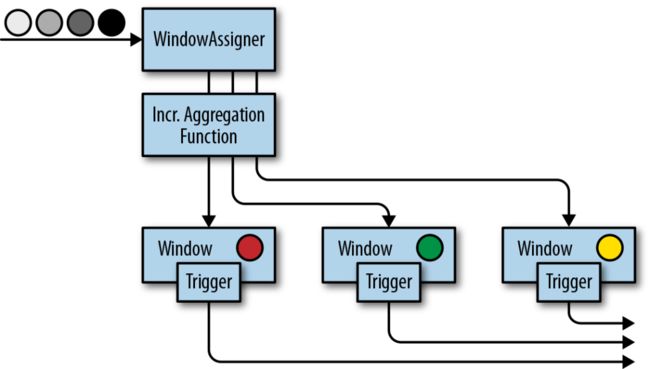
增量聚合函数(Incremental aggregation functions):当一个事件被添加到窗口时,触发函数计算,并且更新window的状态(单个值)。最终聚合的结果将作为输出。ReduceFunction和AggregateFunction是增量聚合函数。
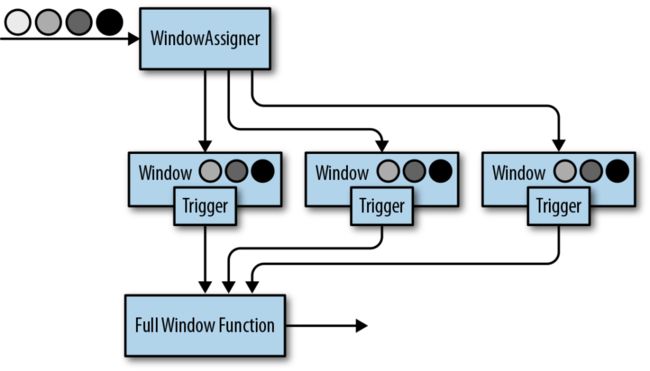
全窗口函数(Full window functions):这个函数将会收集窗口中所有的元素,可以做一些复杂计算。ProcessWindowFunction是window function。
ReduceFunction
例子: 计算每个传感器15s窗口中的温度最小值
scala version
val minTempPerWindow = sensorData
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
java version
DataStream> minTempPerwindow = sensorData
.map(new MapFunction>() {
@Override
public Tuple2 map(SensorReading value) throws Exception {
return Tuple2.of(value.id, value.temperature);
}
})
.keyBy(r -> r.f0)
.timeWindow(Time.seconds(5))
.reduce(new ReduceFunction>() {
@Override
public Tuple2 reduce(Tuple2 value1, Tuple2 value2) throws Exception {
if (value1.f1 < value2.f1) {
return value1;
} else {
return value2;
}
}
})
AggregateFunction
先来看接口定义
public interface AggregateFunction
extends Function, Serializable {
// create a new accumulator to start a new aggregate
ACC createAccumulator();
// add an input element to the accumulator and return the accumulator
ACC add(IN value, ACC accumulator);
// compute the result from the accumulator and return it.
OUT getResult(ACC accumulator);
// merge two accumulators and return the result.
ACC merge(ACC a, ACC b);
}
IN是输入元素的类型,ACC是累加器的类型,OUT是输出元素的类型。
例子
val avgTempPerWindow: DataStream[(String, Double)] = sensorData
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.aggregate(new AvgTempFunction)
// An AggregateFunction to compute the average temperature per sensor.
// The accumulator holds the sum of temperatures and an event count.
class AvgTempFunction
extends AggregateFunction[(String, Double),
(String, Double, Int), (String, Double)] {
override def createAccumulator() = {
("", 0.0, 0)
}
override def add(in: (String, Double), acc: (String, Double, Int)) = {
(in._1, in._2 + acc._2, 1 + acc._3)
}
override def getResult(acc: (String, Double, Int)) = {
(acc._1, acc._2 / acc._3)
}
override def merge(acc1: (String, Double, Int),
acc2: (String, Double, Int)) = {
(acc1._1, acc1._2 + acc2._2, acc1._3 + acc2._3)
}
}
ProcessWindowFunction
一些业务场景,我们需要收集窗口内所有的数据进行计算,例如计算窗口数据的中位数,或者计算窗口数据中出现频率最高的值。这样的需求,使用ReduceFunction和AggregateFunction就无法实现了。这个时候就需要ProcessWindowFunction了。
先来看接口定义
public abstract class ProcessWindowFunction
extends AbstractRichFunction {
// Evaluates the window
void process(KEY key, Context ctx, Iterable vals, Collector out)
throws Exception;
// Deletes any custom per-window state when the window is purged
public void clear(Context ctx) throws Exception {}
// The context holding window metadata
public abstract class Context implements Serializable {
// Returns the metadata of the window
public abstract W window();
// Returns the current processing time
public abstract long currentProcessingTime();
// Returns the current event-time watermark
public abstract long currentWatermark();
// State accessor for per-window state
public abstract KeyedStateStore windowState();
// State accessor for per-key global state
public abstract KeyedStateStore globalState();
// Emits a record to the side output identified by the OutputTag.
public abstract void output(OutputTag outputTag, X value);
}
}
process()方法接受的参数为:
window的key
Iterable迭代器包含窗口的所有元素
Collector用于输出结果流。
Context参数和别的process方法一样。而ProcessWindowFunction的Context对象还可以访问window的元数据(窗口开始和结束时间),当前处理时间和水位线,per-window state和per-key global state,side outputs。
per-window state: 用于保存一些信息,这些信息可以被process()访问,只要process所处理的元素属于这个窗口。
per-key global state: 同一个key,也就是在一条KeyedStream上,不同的window可以访问per-key global state保存的值。
例子:计算5s滚动窗口中的最低和最高的温度。输出的元素包含了(流的Key, 最低温度, 最高温度, 窗口结束时间)。
val minMaxTempPerWindow: DataStream[MinMaxTemp] = sensorData
.keyBy(_.id)
.timeWindow(Time.seconds(5))
.process(new HighAndLowTempProcessFunction)
case class MinMaxTemp(id: String, min: Double, max: Double, endTs: Long)
class HighAndLowTempProcessFunction
extends ProcessWindowFunction[SensorReading,
MinMaxTemp, String, TimeWindow] {
override def process(key: String,
ctx: Context,
vals: Iterable[SensorReading],
out: Collector[MinMaxTemp]): Unit = {
val temps = vals.map(_.temperature)
val windowEnd = ctx.window.getEnd
out.collect(MinMaxTemp(key, temps.min, temps.max, windowEnd))
}
}
我们还可以将ReduceFunction/AggregateFunction和ProcessWindowFunction结合起来使用。ReduceFunction/AggregateFunction做增量聚合,ProcessWindowFunction提供更多的对数据流的访问权限。如果只使用ProcessWindowFunction(底层的实现为将事件都保存在ListState中),将会非常占用空间。分配到某个窗口的元素将被提前聚合,而当窗口的trigger触发时,也就是窗口收集完数据关闭时,将会把聚合结果发送到ProcessWindowFunction中,这时Iterable参数将会只有一个值,就是前面聚合的值。
例子
input
.keyBy(...)
.timeWindow(...)
.reduce(
incrAggregator: ReduceFunction[IN],
function: ProcessWindowFunction[IN, OUT, K, W])
input
.keyBy(...)
.timeWindow(...)
.aggregate(
incrAggregator: AggregateFunction[IN, ACC, V],
windowFunction: ProcessWindowFunction[V, OUT, K, W])
我们把之前的需求重新使用以上两种方法实现一下。
case class MinMaxTemp(id: String, min: Double, max: Double, endTs: Long)
val minMaxTempPerWindow2: DataStream[MinMaxTemp] = sensorData
.map(r => (r.id, r.temperature, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.reduce(
(r1: (String, Double, Double), r2: (String, Double, Double)) => {
(r1._1, r1._2.min(r2._2), r1._3.max(r2._3))
},
new AssignWindowEndProcessFunction
)
class AssignWindowEndProcessFunction
extends ProcessWindowFunction[(String, Double, Double),
MinMaxTemp, String, TimeWindow] {
override def process(key: String,
ctx: Context,
minMaxIt: Iterable[(String, Double, Double)],
out: Collector[MinMaxTemp]): Unit = {
val minMax = minMaxIt.head
val windowEnd = ctx.window.getEnd
out.collect(MinMaxTemp(key, minMax._2, minMax._3, windowEnd))
}
}
1.4 自定义窗口操作符
Flink内置的window operators分配器已经已经足够应付大多数应用场景。尽管如此,如果我们需要实现一些复杂的窗口逻辑,例如:可以发射早到的事件或者碰到迟到的事件就更新窗口的结果,或者窗口的开始和结束决定于特定事件的接收。
DataStream API暴露了接口和方法来自定义窗口操作符。
自定义窗口分配器
自定义窗口计算触发器(trigger)
自定义窗口数据清理功能(evictor)
当一个事件来到窗口操作符,首先将会传给WindowAssigner来处理。WindowAssigner决定了事件将被分配到哪些窗口。如果窗口不存在,WindowAssigner将会创建一个新的窗口。
如果一个window operator接受了一个增量聚合函数作为参数,例如ReduceFunction或者AggregateFunction,新到的元素将会立即被聚合,而聚合结果result将存储在window中。如果window operator没有使用增量聚合函数,那么新元素将被添加到ListState中,ListState中保存了所有分配给窗口的元素。
新元素被添加到窗口时,这个新元素同时也被传给了window的trigger。trigger定义了window何时准备好求值,何时window被清空。trigger可以基于window被分配的元素和注册的定时器来对窗口的所有元素求值或者在特定事件清空window中所有的元素。
当window operator只接收一个增量聚合函数作为参数时:
当window operator只接收一个全窗口函数作为参数时:
当window operator接收一个增量聚合函数和一个全窗口函数作为参数时:
evictor是一个可选的组件,可以被注入到ProcessWindowFunction之前或者之后调用。evictor可以清除掉window中收集的元素。由于evictor需要迭代所有的元素,所以evictor只能使用在没有增量聚合函数作为参数的情况下。
下面的代码说明了如果使用自定义的trigger和evictor定义一个window operator:
stream
.keyBy(...)
.window(...)
[.trigger(...)]
[.evictor(...)]
.reduce/aggregate/process(...)
注意:每个WindowAssigner都有一个默认的trigger。
窗口生命周期
当WindowAssigner分配某个窗口的第一个元素时,这个窗口才会被创建。所以不存在没有元素的窗口。
一个窗口包含了如下状态:
Window content
分配到这个窗口的元素 增量聚合的结果(如果window operator接收了ReduceFunction或者AggregateFunction作为参数)。
Window object
WindowAssigner返回0个,1个或者多个window object。window operator根据返回的window object来聚合元素。每一个window object包含一个windowEnd时间戳,来区别于其他窗口。
触发器的定时器:一个触发器可以注册定时事件,到了定时的时间可以执行相应的回调函数,例如:对窗口进行求值或者清空窗口。
触发器中的自定义状态:触发器可以定义和使用自定义的、per-window或者per-key状态。这个状态完全被触发器所控制。而不是被window operator控制。
当窗口结束时间来到,window operator将删掉这个窗口。窗口结束时间是由window object的end timestamp所定义的。无论是使用processing time还是event time,窗口结束时间是什么类型可以调用WindowAssigner.isEventTime()方法获得。
窗口分配器(window assigners)
WindowAssigner将会把元素分配到0个,1个或者多个窗口中去。我们看一下WindowAssigner接口:
public abstract class WindowAssigner
implements Serializable {
public abstract Collection assignWindows(
T element,
long timestamp,
WindowAssignerContext context);
public abstract Trigger getDefaultTriger(
StreamExecutionEnvironment env);
public abstract TypeSerializer getWindowSerializer(
ExecutionConfig executionConfig);
public abstract boolean isEventTime();
public abstract static class WindowAssignerContext {
public abstract long getCurrentProcessingTime();
}
}
WindowAssigner有两个泛型参数:
T: 事件的数据类型
W: 窗口的类型
下面的代码创建了一个自定义窗口分配器,是一个30秒的滚动事件时间窗口。
class ThirtySecondsWindows
extends WindowAssigner[Object, TimeWindow] {
val windowSize: Long = 30 * 1000L
override def assignWindows(
o: Object,
ts: Long,
ctx: WindowAssigner.WindowAssignerContext
): java.util.List[TimeWindow] = {
val startTime = ts - (ts % windowSize)
val endTime = startTime + windowSize
Collections.singletonList(new TimeWindow(startTime, endTime))
}
override def getDefaultTrigger(
env: environment.StreamExecutionEnvironment
): Trigger[Object, TimeWindow] = {
EventTimeTrigger.create()
}
override def getWindowSerializer(
executionConfig: ExecutionConfig
): TypeSerializer[TimeWindow] = {
new TimeWindow.Serializer
}
override def isEventTime = true
}
增量聚合示意图
全窗口聚合示意图
增量聚合和全窗口聚合结合使用的示意图

触发器(Triggers)
触发器定义了window何时会被求值以及何时发送求值结果。触发器可以到了特定的时间触发也可以碰到特定的事件触发。例如:观察到事件数量符合一定条件或者观察到了特定的事件。
默认的触发器将会在两种情况下触发
处理时间:机器时间到达处理时间
事件时间:水位线超过了窗口的结束时间
触发器可以访问流的时间属性以及定时器,还可以对state状态编程。所以触发器和process function一样强大。
例如我们可以实现一个触发逻辑:当窗口接收到一定数量的元素时,触发器触发。再比如当窗口接收到一个特定元素时,触发器触发。还有就是当窗口接收到的元素里面包含特定模式(5秒钟内接收到了两个同样类型的事件),触发器也可以触发。在一个事件时间的窗口中,一个自定义的触发器可以提前(在水位线没过窗口结束时间之前)计算和发射计算结果。这是一个常见的低延迟计算策略,尽管计算不完全,但不像默认的那样需要等待水位线没过窗口结束时间。
每次调用触发器都会产生一个TriggerResult来决定窗口接下来发生什么。TriggerResult可以取以下结果:
CONTINUE:什么都不做
FIRE:如果window operator有ProcessWindowFunction这个参数,将会调用这个ProcessWindowFunction。如果窗口仅有增量聚合函数(ReduceFunction或者AggregateFunction)作为参数,那么当前的聚合结果将会被发送。窗口的state不变。
PURGE:窗口所有内容包括窗口的元数据都将被丢弃。
FIRE_AND_PURGE:先对窗口进行求值,再将窗口中的内容丢弃。
TriggerResult可能的取值使得我们可以实现很复杂的窗口逻辑。一个自定义触发器可以触发多次,可以计算或者更新结果,可以在发送结果之前清空窗口。
接下来我们看一下Trigger API:
public abstract class Trigger
implements Serializable {
TriggerResult onElement(
long timestamp,
W window,
TriggerContext ctx);
public abstract TriggerResult onProcessingTime(
long timestamp,
W window,
TriggerContext ctx);
public abstract TriggerResult onEventTime(
long timestamp,
W window,
TriggerContext ctx);
public boolean canMerge();
public void onMerge(W window, OnMergeContext ctx);
public abstract void clear(W window, TriggerContext ctx);
}
public interface TriggerContext {
long getCurrentProcessingTime();
long getCurrentWatermark();
void registerProcessingTimeTimer(long time);
void registerEventTimeTimer(long time);
void deleteProcessingTimeTimer(long time);
void deleteEventTimeTimer(long time);
S getPartitionedState(
StateDescriptor stateDescriptor);
}
public interface OnMergeContext extends TriggerContext {
void mergePartitionedState(
StateDescriptor stateDescriptor
);
}
这里要注意两个地方:清空state和merging合并触发器。
当在触发器中使用per-window state时,这里我们需要保证当窗口被删除时state也要被删除,否则随着时间的推移,window operator将会积累越来越多的数据,最终可能使应用崩溃。
当窗口被删除时,为了清空所有状态,触发器的clear()方法需要需要删掉所有的自定义per-window state,以及使用TriggerContext对象将处理时间和事件时间的定时器都删除。
下面的例子展示了一个触发器在窗口结束时间之前触发。当第一个事件被分配到窗口时,这个触发器注册了一个定时器,定时时间为水位线之前一秒钟。当定时事件执行,将会注册一个新的定时事件,这样,这个触发器每秒钟最多触发一次。
scala version
class OneSecondIntervalTrigger
extends Trigger[SensorReading, TimeWindow] {
override def onElement(
SensorReading r,
timestamp: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext
): TriggerResult = {
val firstSeen: ValueState[Boolean] = ctx
.getPartitionedState(
new ValueStateDescriptor[Boolean](
"firstSeen", classOf[Boolean]
)
)
if (!firstSeen.value()) {
val t = ctx.getCurrentWatermark
+ (1000 - (ctx.getCurrentWatermark % 1000))
ctx.registerEventTimeTimer(t)
ctx.registerEventTimeTimer(window.getEnd)
firstSeen.update(true)
}
TriggerResult.CONTINUE
}
override def onEventTime(
timestamp: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext
): TriggerResult = {
if (timestamp == window.getEnd) {
TriggerResult.FIRE_AND_PURGE
} else {
val t = ctx.getCurrentWatermark
+ (1000 - (ctx.getCurrentWatermark % 1000))
if (t < window.getEnd) {
ctx.registerEventTimeTimer(t)
}
TriggerResult.FIRE
}
}
override def onProcessingTime(
timestamp: Long,
window: TimeWindow,
ctx: Trigger.TriggerContext
): TriggerResult = {
TriggerResult.CONTINUE
}
override def clear(
window: TimeWindow,
ctx: Trigger.TriggerContext
): Unit = {
val firstSeen: ValueState[Boolean] = ctx
.getPartitionedState(
new ValueStateDescriptor[Boolean](
"firstSeen", classOf[Boolean]
)
)
firstSeen.clear()
}
}
java version
public class TriggerExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
env
.socketTextStream("localhost", 9999)
.map(new MapFunction>() {
@Override
public Tuple2 map(String s) throws Exception {
String[] arr = s.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
)
.keyBy(r -> r.f0)
.timeWindow(Time.seconds(5))
.trigger(new OneSecondIntervalTrigger())
.process(new ProcessWindowFunction, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable> iterable, Collector collector) throws Exception {
long count = 0L;
for (Tuple2 i : iterable) count += 1;
collector.collect("窗口中有 " + count + " 条元素");
}
})
.print();
env.execute();
}
public static class OneSecondIntervalTrigger extends Trigger, TimeWindow> {
// 来一条调用一次
@Override
public TriggerResult onElement(Tuple2 r, long l, TimeWindow window, TriggerContext ctx) throws Exception {
ValueState firstSeen = ctx.getPartitionedState(
new ValueStateDescriptor("first-seen", Types.BOOLEAN)
);
if (firstSeen.value() == null) {
// 4999 + (1000 - 4999 % 1000) = 5000
System.out.println("第一条数据来的时候 ctx.getCurrentWatermark() 的值是 " + ctx.getCurrentWatermark());
long t = ctx.getCurrentWatermark() + (1000L - ctx.getCurrentWatermark() % 1000L);
ctx.registerEventTimeTimer(t);
ctx.registerEventTimeTimer(window.getEnd());
firstSeen.update(true);
}
return TriggerResult.CONTINUE;
}
// 定时器逻辑
@Override
public TriggerResult onEventTime(long ts, TimeWindow window, TriggerContext ctx) throws Exception {
if (ts == window.getEnd()) {
return TriggerResult.FIRE_AND_PURGE;
} else {
System.out.println("当前水位线是:" + ctx.getCurrentWatermark());
long t = ctx.getCurrentWatermark() + (1000L - ctx.getCurrentWatermark() % 1000L);
if (t < window.getEnd()) {
ctx.registerEventTimeTimer(t);
}
return TriggerResult.FIRE;
}
}
@Override
public TriggerResult onProcessingTime(long l, TimeWindow timeWindow, TriggerContext triggerContext) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public void clear(TimeWindow timeWindow, TriggerContext ctx) throws Exception {
ValueState firstSeen = ctx.getPartitionedState(
new ValueStateDescriptor("first-seen", Types.BOOLEAN)
);
firstSeen.clear();
}
}
}
清理器(EVICTORS)
evictor可以在window function求值之前或者之后移除窗口中的元素。
我们看一下Evictor的接口定义:
public interface Evictor
extends Serializable {
void evictBefore(
Iterable> elements,
int size,
W window,
EvictorContext evictorContext);
void evictAfter(
Iterable> elements,
int size,
W window,
EvictorContext evictorContext);
interface EvictorContext {
long getCurrentProcessingTime();
long getCurrentWatermark();
}
}
evictBefore()和evictAfter()分别在window function计算之前或者之后调用。Iterable迭代器包含了窗口所有的元素,size为窗口中元素的数量,window object和EvictorContext可以访问当前处理时间和水位线。可以对Iterator调用remove()方法来移除窗口中的元素。
evictor也经常被用在GlobalWindow上,用来清除部分元素,而不是将窗口中的元素全部清空。
数据流操作
1 基于时间的双流Join
数据流操作的另一个常见需求是对两条数据流中的事件进行联结(connect)或Join。Flink DataStream API中内置有两个可以根据时间条件对数据流进行Join的算子:基于间隔的Join和基于窗口的Join。本节我们会对它们进行介绍。
如果Flink内置的Join算子无法表达所需的Join语义,那么你可以通过CoProcessFunction、BroadcastProcessFunction或KeyedBroadcastProcessFunction实现自定义的Join逻辑。
注意,你要设计的Join算子需要具备高效的状态访问模式及有效的状态清理策略。
1.1 基于间隔的Join
基于间隔的Join会对两条流中拥有相同键值以及彼此之间时间戳不超过某一指定间隔的事件进行Join。
下图展示了两条流(A和B)上基于间隔的Join,如果B中事件的时间戳相较于A中事件的时间戳不早于1小时且不晚于15分钟,则会将两个事件Join起来。Join间隔具有对称性,因此上面的条件也可以表示为A中事件的时间戳相较B中事件的时间戳不早于15分钟且不晚于1小时。

基于间隔的Join目前只支持事件时间以及INNER JOIN语义(无法发出未匹配成功的事件)。下面的例子定义了一个基于间隔的Join。
input1
.intervalJoin(input2)
.between(, ) // 相对于input1的上下界
.process(ProcessJoinFunction) // 处理匹配的事件对
Join成功的事件对会发送给ProcessJoinFunction。下界和上界分别由负时间间隔和正时间间隔来定义,例如between(Time.hour(-1), Time.minute(15))。在满足下界值小于上界值的前提下,你可以任意对它们赋值。例如,允许出现B中事件的时间戳相较A中事件的时间戳早1~2小时这样的条件。
基于间隔的Join需要同时对双流的记录进行缓冲。对第一个输入而言,所有时间戳大于当前水位线减去间隔上界的数据都会被缓冲起来;对第二个输入而言,所有时间戳大于当前水位线加上间隔下界的数据都会被缓冲起来。注意,两侧边界值都有可能为负。上图中的Join需要存储数据流A中所有时间戳大于当前水位线减去15分钟的记录,以及数据流B中所有时间戳大于当前水位线减去1小时的记录。不难想象,如果两条流的事件时间不同步,那么Join所需的存储就会显著增加,因为水位线总是由“较慢”的那条流来决定。
例子:每个用户的点击Join这个用户最近10分钟内的浏览
scala version
object IntervalJoinExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
/*
A.intervalJoin(B).between(lowerBound, upperBound)
B.intervalJoin(A).between(-upperBound, -lowerBound)
*/
val stream1 = env
.fromElements(
("user_1", 10 * 60 * 1000L, "click"),
("user_1", 16 * 60 * 1000L, "click")
)
.assignAscendingTimestamps(_._2)
.keyBy(r => r._1)
val stream2 = env
.fromElements(
("user_1", 5 * 60 * 1000L, "browse"),
("user_1", 6 * 60 * 1000L, "browse")
)
.assignAscendingTimestamps(_._2)
.keyBy(r => r._1)
stream1
.intervalJoin(stream2)
.between(Time.minutes(-10), Time.minutes(0))
.process(new ProcessJoinFunction[(String, Long, String), (String, Long, String), String] {
override def processElement(in1: (String, Long, String), in2: (String, Long, String), context: ProcessJoinFunction[(String, Long, String), (String, Long, String), String]#Context, collector: Collector[String]): Unit = {
collector.collect(in1 + " => " + in2)
}
})
.print()
stream2
.intervalJoin(stream1)
.between(Time.minutes(0), Time.minutes(10))
.process(new ProcessJoinFunction[(String, Long, String), (String, Long, String), String] {
override def processElement(in1: (String, Long, String), in2: (String, Long, String), context: ProcessJoinFunction[(String, Long, String), (String, Long, String), String]#Context, collector: Collector[String]): Unit = {
collector.collect(in1 + " => " + in2)
}
})
.print()
env.execute()
}
}
java version
public class IntervalJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
KeyedStream, String> stream1 = env
.fromElements(
Tuple3.of("user_1", 10 * 60 * 1000L, "click")
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple3 stringLongStringTuple3, long l) {
return stringLongStringTuple3.f1;
}
})
)
.keyBy(r -> r.f0);
KeyedStream, String> stream2 = env
.fromElements(
Tuple3.of("user_1", 5 * 60 * 1000L, "browse"),
Tuple3.of("user_1", 6 * 60 * 1000L, "browse")
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple3 stringLongStringTuple3, long l) {
return stringLongStringTuple3.f1;
}
})
)
.keyBy(r -> r.f0);
stream1
.intervalJoin(stream2)
.between(Time.minutes(-10), Time.minutes(0))
.process(new ProcessJoinFunction, Tuple3, String>() {
@Override
public void processElement(Tuple3 stringLongStringTuple3, Tuple3 stringLongStringTuple32, Context context, Collector collector) throws Exception {
collector.collect(stringLongStringTuple3 + " => " + stringLongStringTuple32);
}
})
.print();
env.execute();
}
}
1.2 基于窗口的Join
顾名思义,基于窗口的Join需要用到Flink中的窗口机制。其原理是将两条输入流中的元素分配到公共窗口中并在窗口完成时进行Join(或Cogroup)。
下面的例子展示了如何定义基于窗口的Join。
input1.join(input2)
.where(...) // 为input1指定键值属性
.equalTo(...) // 为input2指定键值属性
.window(...) // 指定WindowAssigner
[.trigger(...)] // 选择性的指定Trigger
[.evictor(...)] // 选择性的指定Evictor
.apply(...) // 指定JoinFunction
下图展示了DataStream API中基于窗口的Join是如何工作的。

两条输入流都会根据各自的键值属性进行分区,公共窗口分配器会将二者的事件映射到公共窗口内(其中同时存储了两条流中的数据)。当窗口的计时器触发时,算子会遍历两个输入中元素的每个组合(叉乘积)去调用JoinFunction。同时你也可以自定义触发器或移除器。由于两条流中的事件会被映射到同一个窗口中,因此该过程中的触发器和移除器与常规窗口算子中的完全相同。
除了对窗口中的两条流进行Join,你还可以对它们进行Cogroup,只需将算子定义开始位置的join改为coGroup()即可。Join和Cogroup的总体逻辑相同,二者的唯一区别是:Join会为两侧输入中的每个事件对调用JoinFunction;而Cogroup中用到的CoGroupFunction会以两个输入的元素遍历器为参数,只在每个窗口中被调用一次。
注意,对划分窗口后的数据流进行Join可能会产生意想不到的语义。例如,假设你为执行Join操作的算子配置了1小时的滚动窗口,那么一旦来自两个输入的元素没有被划分到同一窗口,它们就无法Join在一起,即使二者彼此仅相差1秒钟。
scala version
object TwoWindowJoinExample {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream1 = env
.fromElements(
("a", 1000L),
("a", 2000L)
)
.assignAscendingTimestamps(_._2)
val stream2 = env
.fromElements(
("a", 3000L),
("a", 4000L)
)
.assignAscendingTimestamps(_._2)
stream1
.join(stream2)
// on A.id = B.id
.where(_._1)
.equalTo(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction[(String, Long), (String, Long), String] {
override def join(in1: (String, Long), in2: (String, Long)): String = {
in1 + " => " + in2
}
})
.print()
env.execute()
}
}
java version
public class TwoWindowJoinExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream> stream1 = env
.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
DataStream> stream2 = env
.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
stream1
.join(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction, Tuple2, String>() {
@Override
public String join(Tuple2 stringLongTuple2, Tuple2 stringLongTuple22) throws Exception {
return stringLongTuple2 + " => " + stringLongTuple22;
}
})
.print();
env.execute();
}
}
2 处理迟到的元素
水位线可以用来平衡计算的完整性和延迟两方面。除非我们选择一种非常保守的水位线策略(最大延时设置的非常大,以至于包含了所有的元素,但结果是非常大的延迟),否则我们总需要处理迟到的元素。
迟到的元素是指当这个元素来到时,这个元素所对应的窗口已经计算完毕了(也就是说水位线已经没过窗口结束时间了)。这说明迟到这个特性只针对事件时间。
DataStream API提供了三种策略来处理迟到元素
直接抛弃迟到的元素
将迟到的元素发送到另一条流中去
可以更新窗口已经计算完的结果,并发出计算结果。
2.1 抛弃迟到元素
抛弃迟到的元素是event time window operator的默认行为。也就是说一个迟到的元素不会创建一个新的窗口。
process function可以通过比较迟到元素的时间戳和当前水位线的大小来很轻易的过滤掉迟到元素。
2.2 重定向迟到元素
迟到的元素也可以使用侧输出(side output)特性被重定向到另外的一条流中去。迟到元素所组成的侧输出流可以继续处理或者sink到持久化设施中去。
例子:
scala version
val readings = env
.socketTextStream("localhost", 9999, '\n')
.map(line => {
val arr = line.split(" ")
(arr(0), arr(1).toLong * 1000)
})
.assignAscendingTimestamps(_._2)
val countPer10Secs = readings
.keyBy(_._1)
.timeWindow(Time.seconds(10))
.sideOutputLateData(
new OutputTag[(String, Long)]("late-readings")
)
.process(new CountFunction())
val lateStream = countPer10Secs
.getSideOutput(
new OutputTag[(String, Long)]("late-readings")
)
lateStream.print()
实现CountFunction:
class CountFunction extends ProcessWindowFunction[(String, Long),
String, String, TimeWindow] {
override def process(key: String,
context: Context,
elements: Iterable[(String, Long)],
out: Collector[String]): Unit = {
out.collect("窗口共有" + elements.size + "条数据")
}
}
java version
public class RedirectLateEvent {
private static OutputTag> output = new OutputTag>("late-readings"){};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream> stream = env
.socketTextStream("localhost", 9999)
.map(new MapFunction>() {
@Override
public Tuple2 map(String s) throws Exception {
String[] arr = s.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.
// like scala: assignAscendingTimestamps(_._2)
>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 value, long l) {
return value.f1;
}
})
);
SingleOutputStreamOperator lateReadings = stream
.keyBy(r -> r.f0)
.timeWindow(Time.seconds(5))
.sideOutputLateData(output) // use after keyBy and timeWindow
.process(new ProcessWindowFunction, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable> iterable, Collector collector) throws Exception {
long exactSizeIfKnown = iterable.spliterator().getExactSizeIfKnown();
collector.collect(exactSizeIfKnown + " of elements");
}
});
lateReadings.print();
lateReadings.getSideOutput(output).print();
env.execute();
}
}
下面这个例子展示了ProcessFunction如何过滤掉迟到的元素然后将迟到的元素发送到侧输出流中去。
scala version
val readings: DataStream[SensorReading] = ...
val filteredReadings: DataStream[SensorReading] = readings
.process(new LateReadingsFilter)
// retrieve late readings
val lateReadings: DataStream[SensorReading] = filteredReadings
.getSideOutput(new OutputTag[SensorReading]("late-readings"))
/** A ProcessFunction that filters out late sensor readings and
* re-directs them to a side output */
class LateReadingsFilter
extends ProcessFunction[SensorReading, SensorReading] {
val lateReadingsOut = new OutputTag[SensorReading]("late-readings")
override def processElement(
SensorReading r,
ctx: ProcessFunction[SensorReading, SensorReading]#Context,
out: Collector[SensorReading]): Unit = {
// compare record timestamp with current watermark
if (r.timestamp < ctx.timerService().currentWatermark()) {
// this is a late reading => redirect it to the side output
ctx.output(lateReadingsOut, r)
} else {
out.collect(r)
}
}
}
java version
public class RedirectLateEvent {
private static OutputTag output = new OutputTag("late-readings"){};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator> stream = env
.socketTextStream("localhost", 9999)
.map(new MapFunction>() {
@Override
public Tuple2 map(String s) throws Exception {
String[] arr = s.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.
>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 value, long l) {
return value.f1;
}
})
)
.process(new ProcessFunction, Tuple2>() {
@Override
public void processElement(Tuple2 stringLongTuple2, Context context, Collector> collector) throws Exception {
if (stringLongTuple2.f1 < context.timerService().currentWatermark()) {
context.output(output, "late event is comming!");
} else {
collector.collect(stringLongTuple2);
}
}
});
stream.print();
stream.getSideOutput(output).print();
env.execute();
}
}
2.3 使用迟到元素更新窗口计算结果
由于存在迟到的元素,所以已经计算出的窗口结果是不准确和不完全的。我们可以使用迟到元素更新已经计算完的窗口结果。
如果我们要求一个operator支持重新计算和更新已经发出的结果,就需要在第一次发出结果以后也要保存之前所有的状态。但显然我们不能一直保存所有的状态,肯定会在某一个时间点将状态清空,而一旦状态被清空,结果就再也不能重新计算或者更新了。而迟到的元素只能被抛弃或者发送到侧输出流。
window operator API提供了方法来明确声明我们要等待迟到元素。当使用event-time window,我们可以指定一个时间段叫做allowed lateness。window operator如果设置了allowed lateness,这个window operator在水位线没过窗口结束时间时也将不会删除窗口和窗口中的状态。窗口会在一段时间内(allowed lateness设置的)保留所有的元素。
当迟到元素在allowed lateness时间内到达时,这个迟到元素会被实时处理并发送到触发器(trigger)。当水位线没过了窗口结束时间+allowed lateness时间时,窗口会被删除,并且所有后来的迟到的元素都会被丢弃。
Allowed lateness可以使用allowedLateness()方法来指定,如下所示:
val readings: DataStream[SensorReading] = ...
val countPer10Secs: DataStream[(String, Long, Int, String)] = readings
.keyBy(_.id)
.timeWindow(Time.seconds(10))
// process late readings for 5 additional seconds
.allowedLateness(Time.seconds(5))
// count readings and update results if late readings arrive
.process(new UpdatingWindowCountFunction)
/** A counting WindowProcessFunction that distinguishes between
* first results and updates. */
class UpdatingWindowCountFunction
extends ProcessWindowFunction[SensorReading,
(String, Long, Int, String), String, TimeWindow] {
override def process(
id: String,
ctx: Context,
elements: Iterable[SensorReading],
out: Collector[(String, Long, Int, String)]): Unit = {
// count the number of readings
val cnt = elements.count(_ => true)
// state to check if this is
// the first evaluation of the window or not
val isUpdate = ctx.windowState.getState(
new ValueStateDescriptor[Boolean](
"isUpdate",
Types.of[Boolean]))
if (!isUpdate.value()) {
// first evaluation, emit first result
out.collect((id, ctx.window.getEnd, cnt, "first"))
isUpdate.update(true)
} else {
// not the first evaluation, emit an update
out.collect((id, ctx.window.getEnd, cnt, "update"))
}
}
}
java version
public class UpdateWindowResultWithLateEvent {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource stream = env.socketTextStream("localhost", 9999);
stream
.map(new MapFunction>() {
@Override
public Tuple2 map(String s) throws Exception {
String[] arr = s.split(" ");
return Tuple2.of(arr[0], Long.parseLong(arr[1]) * 1000L);
}
})
.assignTimestampsAndWatermarks(
WatermarkStrategy.>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner>() {
@Override
public long extractTimestamp(Tuple2 stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
})
)
.keyBy(r -> r.f0)
.timeWindow(Time.seconds(5))
.allowedLateness(Time.seconds(5))
.process(new UpdateWindowResult())
.print();
env.execute();
}
public static class UpdateWindowResult extends ProcessWindowFunction, String, String, TimeWindow> {
@Override
public void process(String s, Context context, Iterable> iterable, Collector collector) throws Exception {
long count = 0L;
for (Tuple2 i : iterable) {
count += 1;
}
// 可见范围比getRuntimeContext.getState更小,只对当前key、当前window可见
// 基于窗口的状态变量,只能当前key和当前窗口访问
ValueState isUpdate = context.windowState().getState(
new ValueStateDescriptor("isUpdate", Types.BOOLEAN)
);
// 当水位线超过窗口结束时间时,触发窗口的第一次计算!
if (isUpdate.value() == null) {
collector.collect("窗口第一次触发计算!一共有 " + count + " 条数据!");
isUpdate.update(true);
} else {
collector.collect("窗口更新了!一共有 " + count + " 条数据!");
}
}
}
}

八千里路云和月 | 从零到大数据专家学习路径指南
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解析
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」
你好,我是王知无,一个大数据领域的硬核原创作者。
做过后端架构、数据中间件、数据平台&架构、算法工程化。
专注大数据领域实时动态&技术提升&个人成长&职场进阶,欢迎关注。