【spark on kubernetes】spark operator部署安装 v1beta2-1.2.0-3.0.0
最近开始研究spark on kubernetes,经过调研,spark on kubernetes有两种方案,一种是官方的spark提供的原生支持按照spark-submit方式提交任务,第二种是google基于kubernetes提供的spark operator方案,还是按照kubernetes声明式语法提交任务。
一. spark on kubernetes区别
spark on k8s |
spark on k8s operator |
|
| 社区支持 | spark社区 | GoogleCloudPlatform非官方支持 |
| 版本要求 | spark>=2.3,Kubernetes>=1.6 | spark>2.3,Kubernetes>=1.13 |
| 安装 | 按照官网安装,需要k8s pod的create list edit delete权限,且需要自己编译源码进行镜像的构建,构建过程繁琐 | 需要k8s admin安装incubator/sparkoperator,需要pod create list edit delete的权限 |
| 使用 | 直接spark submit提交,支持client和cluster模式 | 通过yaml配置文件形式提交,支持client和cluster模式 |
| 优点 | 符合sparker的方式进行任务提交,对于习惯了spark的使用者来说,使用起来更顺手 | k8s配置文件方式提交任务,复用性强 |
| 缺点 | 运行完后driver的资源不会自动释放 | 运行完后driver的资源不会自动释放 |
经过了对比,选择spark operator方案。
https://github.com/GoogleCloudPlatform/spark-on-k8s-operator https://github.com/GoogleCloudPlatform/spark-on-k8s-operator
https://github.com/GoogleCloudPlatform/spark-on-k8s-operator
二. spark operator安装部署
spark operator的安装部署有两种方式,一种是使用helm插件来使用chart的方式部署,官方文档就是这种方式。首选了这种方式,但是在部署过程中出现了不少问题,决定放弃。第二种方式是按照传统的yaml方式部署,使用了这种方式。
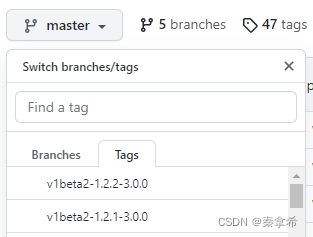
1. 下载spark operator安装包,下载时不要下载master分支,下载v1beta2-1.2.0-3.0.0稳定版本
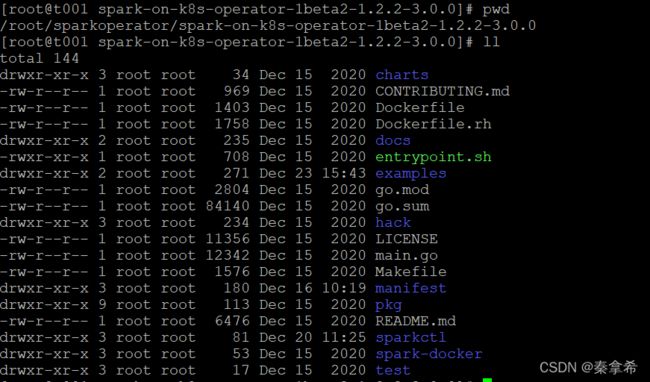
2. 把安装包上传到服务器,解压目录如下
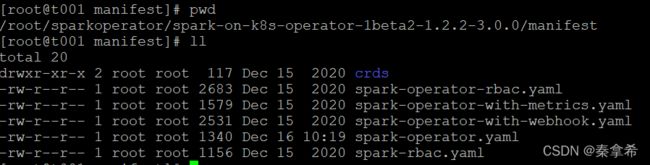
主要部署文件在manifest文件夹下
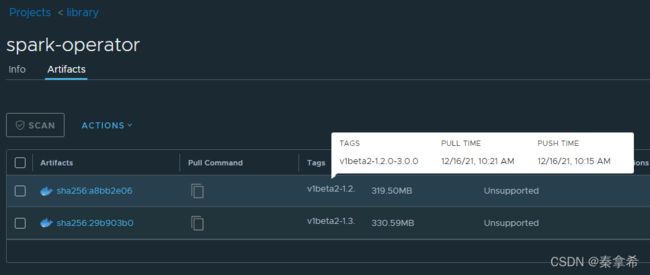
3. spark-operator镜像
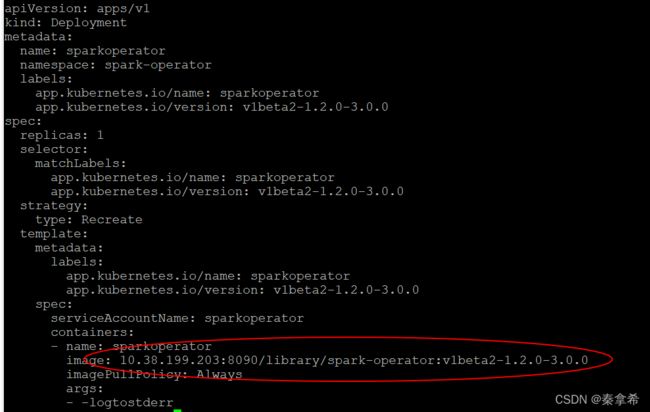
在spark-operator.yaml文件种有一个gcr.io/spark-operator/spark-operator:v1beta2-1.2.0-3.0.0的镜像,这个就是google开发的spark-operator插件,这个镜像在国内是无法拉取到的,但是我的网络是可以访问google的所以直接拉取到了,拉取之后将它制作成本地镜像,上传到本地的harbor,并且修改spark-operator.yaml种的镜像地址
本地如何拉取镜像,可以参考下面的文章,使用阿里云的镜像服务
Spark on k8s Operator 部署安装_u010318804的博客-CSDN博客Spark on k8s Operator 部署安装1. 背景受限于公司内网环境,无法构建梯子及部分网络策略,不能使用网络资源直接部署,需要手动编译安装2. 环境准备centos 7Kubernetes > 1.18helm > 3KubeSphere > 3.0githarborgolang(第4步可选)3. 镜像编译受限于内网网络环境及大陆网络情况,采用阿里云容器镜像服务-------海外机器构建镜像并拉取到本地,上传harbor1) 编写spark基础镜像https://blog.csdn.net/u010318804/article/details/118306990?utm_medium=distribute.pc_feed_404.none-task-blog-2~default~OPENSEARCH~default-7.control404&depth_1-utm_source=distribute.pc_feed_404.none-task-blog-2~default~OPENSEARCH~default-7.control40
4. spark镜像
拉取了spark-operator镜像,还需要拉取另外一个spark程序启动的镜像gcr.io/spark-operator/spark:v3.0.0,以同样的方式拉取并上传到本地harbor
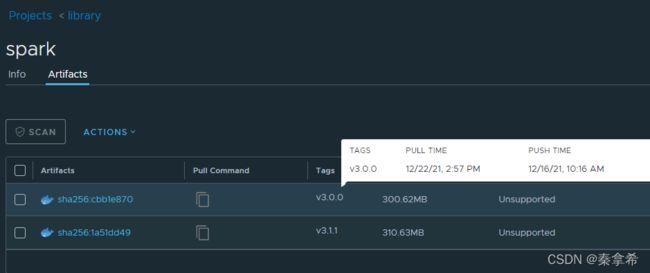
5. 部署spark-operator
修改spark-operator.yaml里面的镜像
部署以下几个文件,会创建namespace,serviceaccount,role等角色
kubectl apply -f spark-rbac.yaml
kubectl apply -f spark-operator-rbac.yaml
kubectl apply -f spark-operator.yaml部署完成,使用命令查看
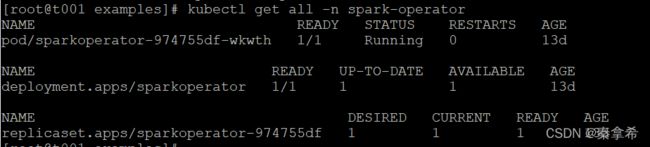
部署之后会生成一个自定义的资源SparkApplication,可以查看,目前还没有运行案例,所以没有

三. 运行案例
下面运行案例,进入examples目录,里面有多个案例,我们来运行spark-pi.yaml案例
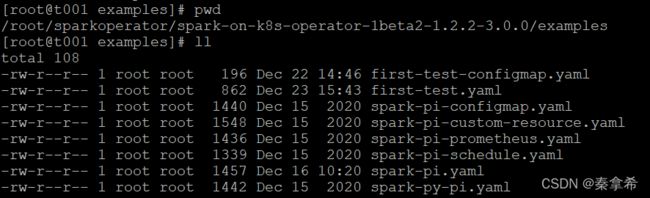
修改spark-pi.yaml里面的spark镜像 
修改完后执行命令
kubectl apply -f spark-pi.yaml查看组件,可以看到,在default的namespace下,生成了一个spark-pi-driver的pod和一个spark-pi-excutor的pod,分别是spark运行任务的driver和excutor。并且生成了spark-pi-driver的service和spark-pi-ui的service。

等待一段时间,程序运行结束,excutor的pod会销毁,并且driver变成了comleted状态
![]()
查看driver的log,kubectl logs spark-pi-driver,里面会有一段Pi is roughly 3.1406557032785165 的文字,说明程序执行成功!
++ id -u
+ myuid=185
++ id -g
+ mygid=0
+ set +e
++ getent passwd 185
+ uidentry=
+ set -e
+ '[' -z '' ']'
+ '[' -w /etc/passwd ']'
+ echo '185:x:185:0:anonymous uid:/opt/spark:/bin/false'
+ SPARK_CLASSPATH=':/opt/spark/jars/*'
+ env
+ grep SPARK_JAVA_OPT_
+ sort -t_ -k4 -n
+ sed 's/[^=]*=\(.*\)/\1/g'
+ readarray -t SPARK_EXECUTOR_JAVA_OPTS
+ '[' -n '' ']'
+ '[' '' == 2 ']'
+ '[' '' == 3 ']'
+ '[' -n '' ']'
+ '[' -z ']'
+ case "$1" in
+ shift 1
+ CMD=("$SPARK_HOME/bin/spark-submit" --conf "spark.driver.bindAddress=$SPARK_DRIVER_BIND_ADDRESS" --deploy-mode client "$@")
+ exec /usr/bin/tini -s -- /opt/spark/bin/spark-submit --conf spark.driver.bindAddress=10.42.4.176 --deploy-mode client --properties-file /opt/spark/conf/spark.properties --class org.apache.spark.examples.SparkPi local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0.jar
21/12/29 08:45:46 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
21/12/29 08:45:46 INFO SparkContext: Running Spark version 3.0.0
21/12/29 08:45:46 INFO ResourceUtils: ==============================================================
21/12/29 08:45:46 INFO ResourceUtils: Resources for spark.driver:
21/12/29 08:45:46 INFO ResourceUtils: ==============================================================
21/12/29 08:45:46 INFO SparkContext: Submitted application: Spark Pi
21/12/29 08:45:46 INFO SecurityManager: Changing view acls to: 185,root
21/12/29 08:45:46 INFO SecurityManager: Changing modify acls to: 185,root
21/12/29 08:45:46 INFO SecurityManager: Changing view acls groups to:
21/12/29 08:45:46 INFO SecurityManager: Changing modify acls groups to:
21/12/29 08:45:46 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(185, root); groups with view permissions: Set(); users with modify permissions: Set(185, root); groups with modify permissions: Set()
21/12/29 08:45:47 INFO Utils: Successfully started service 'sparkDriver' on port 7078.
21/12/29 08:45:47 INFO SparkEnv: Registering MapOutputTracker
21/12/29 08:45:47 INFO SparkEnv: Registering BlockManagerMaster
21/12/29 08:45:47 INFO BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
21/12/29 08:45:47 INFO BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
21/12/29 08:45:47 INFO SparkEnv: Registering BlockManagerMasterHeartbeat
21/12/29 08:45:47 INFO DiskBlockManager: Created local directory at /var/data/spark-567e8ed3-e9a1-42b8-b8d6-4e848483d3e9/blockmgr-a8e4c6ab-2c48-448a-b2ba-1d2710f066c4
21/12/29 08:45:47 INFO MemoryStore: MemoryStore started with capacity 117.0 MiB
21/12/29 08:45:47 INFO SparkEnv: Registering OutputCommitCoordinator
21/12/29 08:45:48 INFO Utils: Successfully started service 'SparkUI' on port 4040.
21/12/29 08:45:48 INFO SparkUI: Bound SparkUI to 0.0.0.0, and started at http://spark-pi-b336d67e055dca94-driver-svc.default.svc:4040
21/12/29 08:45:48 INFO SparkContext: Added JAR local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0.jar at file:/opt/spark/examples/jars/spark-examples_2.12-3.0.0.jar with timestamp 1640767548482
21/12/29 08:45:48 WARN SparkContext: The jar local:///opt/spark/examples/jars/spark-examples_2.12-3.0.0.jar has been added already. Overwriting of added jars is not supported in the current version.
21/12/29 08:45:48 INFO SparkKubernetesClientFactory: Auto-configuring K8S client using current context from users K8S config file
21/12/29 08:45:50 INFO ExecutorPodsAllocator: Going to request 1 executors from Kubernetes.
21/12/29 08:45:50 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 7079.
21/12/29 08:45:50 INFO NettyBlockTransferService: Server created on spark-pi-b336d67e055dca94-driver-svc.default.svc:7079
21/12/29 08:45:50 INFO BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
21/12/29 08:45:50 INFO BlockManagerMaster: Registering BlockManager BlockManagerId(driver, spark-pi-b336d67e055dca94-driver-svc.default.svc, 7079, None)
21/12/29 08:45:50 INFO BlockManagerMasterEndpoint: Registering block manager spark-pi-b336d67e055dca94-driver-svc.default.svc:7079 with 117.0 MiB RAM, BlockManagerId(driver, spark-pi-b336d67e055dca94-driver-svc.default.svc, 7079, None)
21/12/29 08:45:50 INFO BlockManagerMaster: Registered BlockManager BlockManagerId(driver, spark-pi-b336d67e055dca94-driver-svc.default.svc, 7079, None)
21/12/29 08:45:50 INFO BlockManager: Initialized BlockManager: BlockManagerId(driver, spark-pi-b336d67e055dca94-driver-svc.default.svc, 7079, None)
21/12/29 08:45:55 INFO ResourceProfile: Default ResourceProfile created, executor resources: Map(cores -> name: cores, amount: 1, script: , vendor: , memory -> name: memory, amount: 512, script: , vendor: ), task resources: Map(cpus -> name: cpus, amount: 1.0)
21/12/29 08:45:56 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (10.42.11.79:41112) with ID 1
21/12/29 08:45:56 INFO KubernetesClusterSchedulerBackend: SchedulerBackend is ready for scheduling beginning after reached minRegisteredResourcesRatio: 0.8
21/12/29 08:45:56 INFO BlockManagerMasterEndpoint: Registering block manager 10.42.11.79:36999 with 117.0 MiB RAM, BlockManagerId(1, 10.42.11.79, 36999, None)
21/12/29 08:45:57 INFO SparkContext: Starting job: reduce at SparkPi.scala:38
21/12/29 08:45:57 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 2 output partitions
21/12/29 08:45:57 INFO DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
21/12/29 08:45:57 INFO DAGScheduler: Parents of final stage: List()
21/12/29 08:45:57 INFO DAGScheduler: Missing parents: List()
21/12/29 08:45:57 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
21/12/29 08:45:57 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.1 KiB, free 117.0 MiB)
21/12/29 08:45:58 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1816.0 B, free 117.0 MiB)
21/12/29 08:45:58 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on spark-pi-b336d67e055dca94-driver-svc.default.svc:7079 (size: 1816.0 B, free: 117.0 MiB)
21/12/29 08:45:58 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1200
21/12/29 08:45:58 INFO DAGScheduler: Submitting 2 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1))
21/12/29 08:45:58 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
21/12/29 08:45:58 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 10.42.11.79, executor 1, partition 0, PROCESS_LOCAL, 7412 bytes)
21/12/29 08:45:58 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 10.42.11.79:36999 (size: 1816.0 B, free: 117.0 MiB)
21/12/29 08:45:59 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 10.42.11.79, executor 1, partition 1, PROCESS_LOCAL, 7412 bytes)
21/12/29 08:45:59 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1112 ms on 10.42.11.79 (executor 1) (1/2)
21/12/29 08:45:59 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 37 ms on 10.42.11.79 (executor 1) (2/2)
21/12/29 08:45:59 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
21/12/29 08:45:59 INFO DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 1.578 s
21/12/29 08:45:59 INFO DAGScheduler: Job 0 is finished. Cancelling potential speculative or zombie tasks for this job
21/12/29 08:45:59 INFO TaskSchedulerImpl: Killing all running tasks in stage 0: Stage finished
21/12/29 08:45:59 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 1.761649 s
Pi is roughly 3.1406557032785165
21/12/29 08:45:59 INFO SparkUI: Stopped Spark web UI at http://spark-pi-b336d67e055dca94-driver-svc.default.svc:4040
21/12/29 08:45:59 INFO KubernetesClusterSchedulerBackend: Shutting down all executors
21/12/29 08:45:59 INFO KubernetesClusterSchedulerBackend$KubernetesDriverEndpoint: Asking each executor to shut down
21/12/29 08:45:59 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed (this is expected if the application is shutting down.)
21/12/29 08:45:59 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
21/12/29 08:45:59 INFO MemoryStore: MemoryStore cleared
21/12/29 08:45:59 INFO BlockManager: BlockManager stopped
21/12/29 08:45:59 INFO BlockManagerMaster: BlockManagerMaster stopped
21/12/29 08:45:59 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
21/12/29 08:45:59 INFO SparkContext: Successfully stopped SparkContext
21/12/29 08:45:59 INFO ShutdownHookManager: Shutdown hook called
21/12/29 08:45:59 INFO ShutdownHookManager: Deleting directory /var/data/spark-567e8ed3-e9a1-42b8-b8d6-4e848483d3e9/spark-015e0e85-2336-414d-a815-dd6d961c4b78
21/12/29 08:45:59 INFO ShutdownHookManager: Deleting directory /tmp/spark-67d9bc57-d16f-4cd3-a860-bd753e95c40c