零基础入门语音识别-食物声音识别 Task2学习笔记
Task1学习笔记——赛题数据介绍与分析
- 了解声音
- 探索数据
-
- 关于音频处理的库
- 观察音频数据
- 查看音频特征
了解声音
声音,其实就是各种声源的振动所发出来的波。它通过空气、水等弹性介质传播到动物的器官中,为动物的听觉神经所感受。
因此,从物理的角度看来声音并不是抽象的。频率、周期、波长、音速、音强、振幅(响度)、声压、波形(音色),把声音“解剖”出来就是以上所列出来的各种特征。而这,就为我们分析声音数据提供了切入点。
探索数据
关于音频处理的库
有两个常用好用的音频处理库,Librosa和PyAudio。其中Librosa通常用于分析音频信号,但更倾向于音乐,它包括用于构建MIR(音乐信息检索)系统的nuts 和 bolts。而PyAudio这个模块则可以使得音频在jupyter notebook进行播放。
import librosa
import librosa.display
import IPython.display as ipd
观察音频数据
对音频文件个数、音频数据类别,占比等进行输出观察。
import os
voice_path = './train_sample'
def look_data():
# 音频类别文件夹个数
print(f'音频文件夹的个数: {len(os.listdir(voice_path))}')
voice_total = 0
single_label = {}
for ind, label_name in enumerate(os.listdir(voice_path)):
file_path = voice_path + '/' + label_name
single_num = len(os.listdir(file_path))
single_label[label_name] = single_num
voice_total += single_num
print(f'音频文件总量: {voice_total}')
print(f'{"序号":<5}{"类别":<15}{"数量":<10}{"占比"}')
for ind, (key, value) in enumerate(single_label.items()):
print(f'{ind:<5}{key:<20}{value:<10}{value / voice_total:.2%}')
look_data()
输出结果:
音频文件夹的个数: 20
音频文件总量: 1000
序号 类别 数量 占比
0 aloe 45 4.50%
1 burger 64 6.40%
2 cabbage 48 4.80%
3 candied_fruits 74 7.40%
4 carrots 49 4.90%
5 chips 57 5.70%
6 chocolate 27 2.70%
7 drinks 27 2.70%
8 fries 57 5.70%
9 grapes 61 6.10%
10 gummies 65 6.50%
11 ice-cream 69 6.90%
12 jelly 43 4.30%
13 noodles 33 3.30%
14 pickles 75 7.50%
15 pizza 55 5.50%
16 ribs 47 4.70%
17 salmon 37 3.70%
18 soup 32 3.20%
19 wings 35 3.50%
食物的音频主要有6.26G的内存,总共20种食物,总共11140个声音。
可以看出各个类别的数量占比并不相同,分布并不是特别平均。
查看音频特征
用前面提到的IPython.display音频输入路径直接播放音频。
# 播放芦荟的声音
ipd.Audio('./train_sample/aloe/24EJ22XBZ5.wav')
使用librosa模块加载音频文件,librosa.load()加载的音频文件,默认采样率(sr)为22050HZ mono。可以通过librosa.load(path,sr=44100)来更改采样频率。
(音频采样率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高声音的还原就越真实越自然。而44100Hz是理论上的CD音质,因此才用librosa进行更改,这可以让我们后续的分析更加顺利。)
data1, sampling_rate1 = librosa.load('./train_sample/aloe/24EJ22XBZ5.wav')
data2, sampling_rate2 = librosa.load('./train_sample/burger/0WF1KDZVPZ.wav')
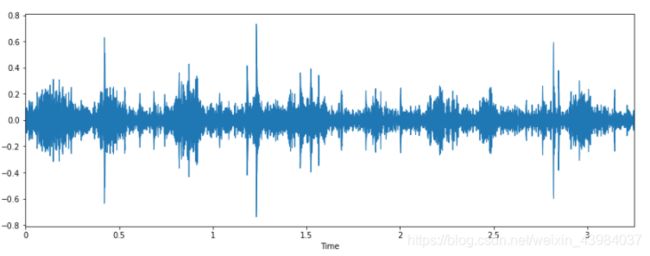
画出波形幅度包络图,以芦荟为例:
# 芦荟的波形幅度包络
plt.figure(figsize=(14, 5))
librosa.display.waveplot(data1,sr=sampling_rate1)
查看声谱图,以汉堡为例:(使用librosa.display.specshow)
# 汉堡的声图谱
plt.figure(figsize=(20, 10))
D = librosa.amplitude_to_db(np.abs(librosa.stft(data2)), ref=np.max)
plt.subplot(4, 2, 1)
librosa.display.specshow(D, y_axis='linear')
plt.colorbar(format='%+2.0f dB')
plt.title('Linear-frequency power spectrogram of burger')
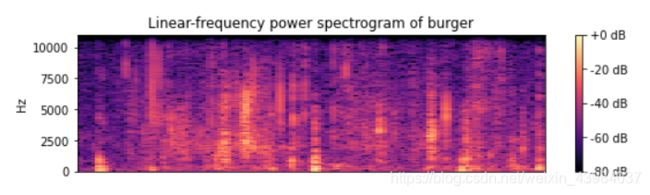
声谱图(spectrogram)是声音或其他信号的频率随时间变化时的频谱(spectrum)的一种直观表示。声谱图有时也称sonographs,voiceprints,或者voicegrams。当数据以三维图形表示时,可称其为瀑布图(waterfalls)。在二维数组中,第一个轴是频率,第二个轴是时间。
参考资料
【1】声音——百度百科
【2】音频采样率——百度百科
【3】Datawhale 开源资料