
qq_27787701的博客
12-06  7399
7399
Elasticsearch新手入门教程(已经是最简洁版)
Elasticsearch新手教程(已经是最简洁版)
ElasticSearch:智能搜索,分布式的搜索引擎
是ELK的一个组成,是一个产品,而且是非常完善的产品,ELK代表的是:E就是ElasticSearch,L就是Logstach,K就是kibana
E:EalsticSearch 搜索和分析的功能
L:Logstach 搜集数据的功能,类似于flume(使用方法几乎跟flume一模一样),是日志收集系统
K:Kibana 数据可视化(分析),可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
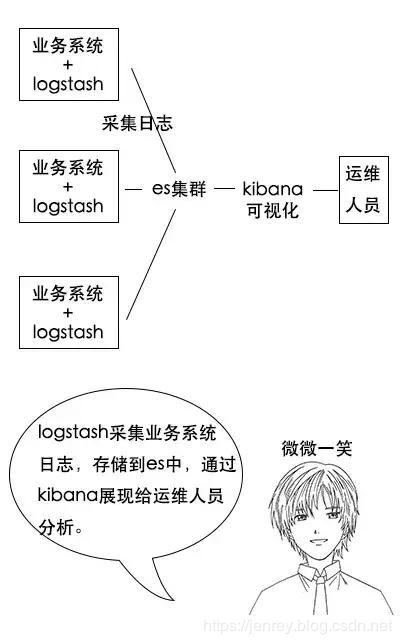
分析日志的用处:假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,是不是非常麻烦?
但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
这都依赖ES强大的反向索引功能,这样我们根据关键字就能查询到关键的错误日志了。
什么是搜索?
1)百度,谷歌,必应。我们可以通过他们去搜索我们需要的东西。但是我们的搜索不只是包含这些,还有京东站内搜索啊。
2)互联网的搜索:电商网站。招聘网站。新闻网站。各种APP(百度外卖,美团等等)
3)windows系统的搜索,OA软件,淘宝SSM网站,前后台的搜索功能
总结:搜索无处不在。通过一些关键字,给我们查询出来跟这些关键字相关的信息
什么是全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
什么是倒排索引
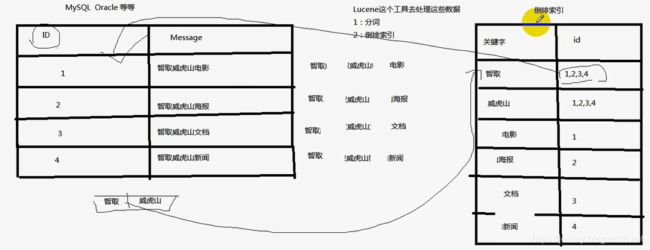
以前是根据ID查内容,倒排索引之后是根据内容查ID,然后再拿着ID去查询出来真正需要的东西。
什么是Lucene
Lucene就是一个jar包,里面包含了各种建立倒排索引的方法,java开发的时候只需要导入这个jar包就可以开发了。
Lucene的介绍及使用
典型的用空间换时间。
ES 和 Lucene的区别
Lucene不是分布式的。
ES的底层就是Lucene,ES是分布式的
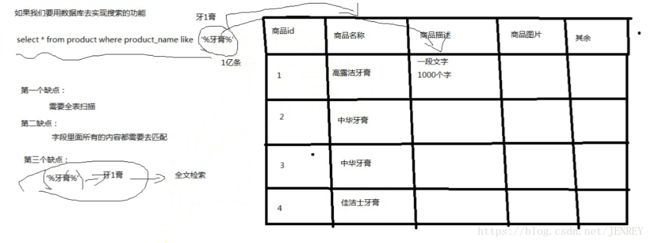
为什么不用数据库去实现搜索功能?
我们用搜索“牙膏”商品为例

如果用我们平时数据库来实现搜索的功能在性能上就很差。
ES的官网
ES官网点我
简单使用如下图,可以切换成中文的文档
或者使用spark的中文网站,也有ES的文档,传送门在下面
ES中文文档
ES的由来
因为Lucene有两个难以解决的问题,
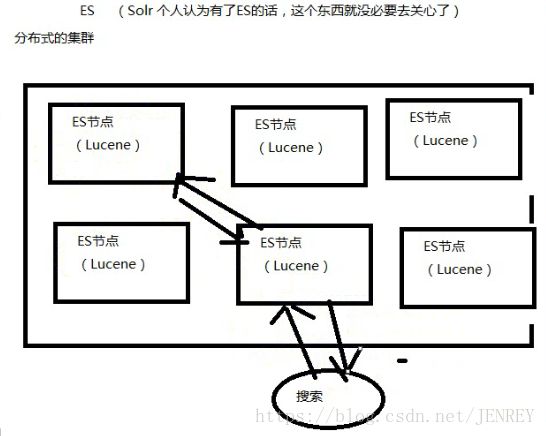
1)数据越大,存不下来,那我就需要多台服务器存数据,那么我的Lucene不支持分布式的,那就需要安装多个Lucene然后通过代码来合并搜索结果。这样很不好
2)数据要考虑安全性,一台服务器挂了,那么上面的数据不就消失了。
ES就是分布式的集群,每一个节点其实就是Lucene,当用户搜索的时候,会随机挑一台,然后这台机器自己知道数据在哪,不用我们管这些底层、
ES的优点
1.分布式的功能
2、数据高可用,集群高可用
3.API更简单
4.API更高级。
5.支持的语言很多
6.支持PB级别的数据
7.完成搜索的功能和分析功能
基于Lucene,隐藏了Lucene的复杂性,提供简单的API
ES的性能比HBase高,咱们的竞价引擎最后还是要存到ES中的。
搜索引擎原理
ES支持的语言
Curl、java、c#、python、JavaScript、php、perl、ruby
Curl 'www.baidu.com' 就是linux的shell命令。可以访问百度,返回的是百度的网页代码
ES的作用
1)全文检索:
类似 select * from product where product_name like '%牙膏%'
类似百度效果(电商搜索的效果)
2)结构化搜索:
类似 select * from product where product_id = '1'
3)数据分析
类似 select count (*) from product
ES的安装
直接解压就能用(针对中小型项目),大型项目还是要调一调参数的

ES直接解压不需要配置就可以使用,在hadoop1上解压一个ES,在hadoop2上解压了一个ES,接下来把这两个ES启动起来。他们就构成了一个集群。
在ES里面默认有一个配置,clustername 默认值就是ElasticSearch,如果这个值是一样的就属于同一个集群,不一样的值就是不一样的集群。
我们为什么使用ES?因为想把数据存进去,然后再查询出来。
我们在使用Mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。
其实ES功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
ES中的索引非传统索引的含义,ES中的索引是存放数据的地方,是ES中的一个概念词汇
index类似于我们Mysql里面的一个数据库 create database user; 好比就是一个索引库
类型是用来定义数据结构的
在每一个index下面,可以有一个或者多个type,好比数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
文档就是最终的数据了,可以认为一个文档就是一条记录。
是ES里面最小的数据单元,就好比表里面的一条数据
好比关系型数据库中列的概念,一个document有一个或者多个field组成。
例如:
朝阳区:一个Mysql数据库
房子:create database chaoyaninfo
房间:create table people
一台服务器,无法存储大量的数据,ES把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
kafka:为什么支持分布式的功能,因为里面是有topic,支持分区的概念。所以topic A可以存在不同的节点上面。就可以支持海量数据和高并发,提升性能和吞吐量
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的shard发生故障,无法提供正常服务。
我们为了保证数据的安全,我们引入了replica的概念,跟hdfs里面的概念是一个意思。
可以保证我们数据的安全。
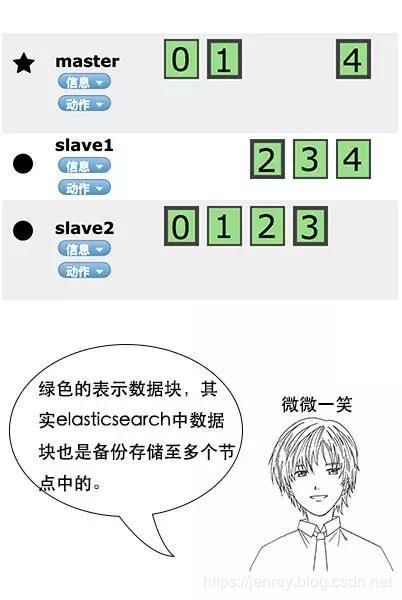
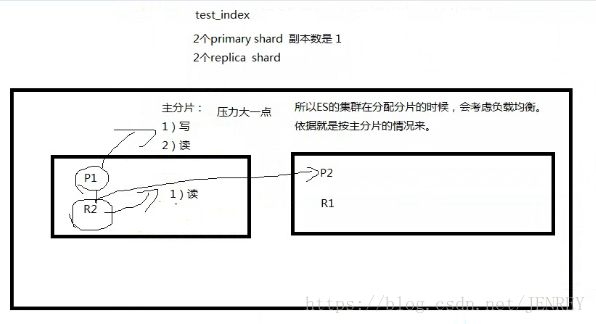
在ES集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
在默认情况下,我们创建一个库的时候,默认会帮我们创建5个主分片(primary shrad)和5个副分片(replica shard),所以说正常情况下是有10个分片的。
同一个节点上面,副本和主分片是一定不会在一台机器上面的,就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES会自动的给你在新机器上创建一个之前分片的副本。

3.10 举例
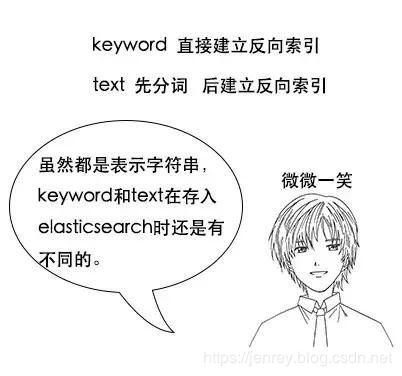
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。
比如诗题、作者、朝代都是 Keyword 类型,诗内容是 Text 类型,而字数是 Integer 类型,最后就是把数据组织成 Json 格式存放进去了。

Keyword 类型是不会分词的,直接根据字符串内容建立反向索引,Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引。
点击上面的官网传送门,点击downloads
下载ES点我

关于ES的版本,现在大多数网上和书写的都是ES 2.x系列的书,有部分比较新的讲的是ES 5的
没有3,4一说。是这样的,ELK 产品是一个非常完善的系统,跟大数据没什么关系,后来我们发现可以处理一些大数据的东西。可以和hadoop和spark整合。因为ELK三个产品是不同的公司出的。有一天一个人想把它们整合在一起,发现E发展到了2的版本,L发展到了3的版本,K发展到了4的版本。这样会有一个问题,什么样的hive和hbase配合什么样的hadoop,这样引发了一个匹配不匹配的问题。三个厂家就决定,从下一代产品我们一起升级就从5版本开始,所以如果你E用5.6,L也应该用5.6,K也应该用5.6,这样就进行了匹配。
这里我们下载安装目前最新版本的6.3.2的ES,注意需要安装好JDK,因为是由java开发的。
直接解压即可,进入bin目录,本文为 G:\myProgram\ElasticSearch\elasticsearch-6.3.2\bin 下进入cmd,
输入elasticsearch

验证ES是否启动成功
在浏览器中输入 http://localhost:9200 看到如下所示图片即为成功
Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因和 HDFS 是一样的,都是为了保证分布式环境下的高可用。
在 Elasticsearch 中,是master-slave架构。节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。

这样写入性能会不会很低???注意,只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
为了方便我们去操作ES,如果不安装去操作ES很麻烦,需要通过shell命令的方式。
下载Kibana
直接解压即可,进入bin目录下,本文为G:\myProgram\kibana\kibana-6.3.2-windows-x86_64\bin 的cmd,执行kibana

不需要配置任何参数,自动识别localhost
在浏览器中输入 http://localhost:5601

然后在左侧找到Dev Tools,在这里就可以进行操作了

输入GET _cat/health 查看集群的健康状况
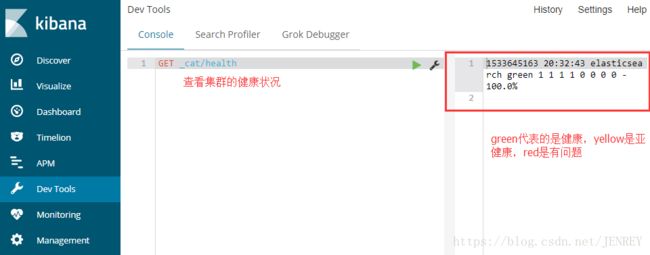
green:每个索引的primary shard和replica shard 都处于active的状态。
下图是一个ES集群有两个节点。主分片是支撑用户的读写。副只支持读数据。这样就造成主分片压力会大一点,所以ES集群在分配分片的时候会考虑负载均衡,依据就是按照主分片的情况来。
yellow:每个索引的primary shard是active的状态,但是部分replica shard不是active的状态,处于不可用的状态。
使用GET _cat/indices 命令查询ES中所有的index

但是可能查询的不全,我们使用下面的命令
GET _all
但是可能会质疑,我们刚搭建好什么数据也没插入,为什么会有数据查出来。
下面这段话讲的是5.6.3版本。

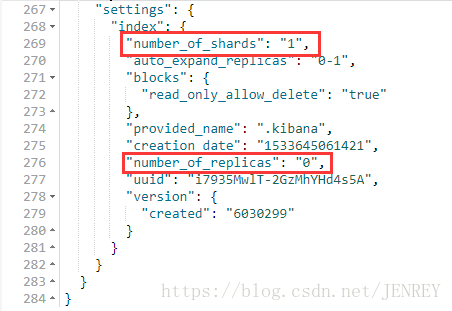
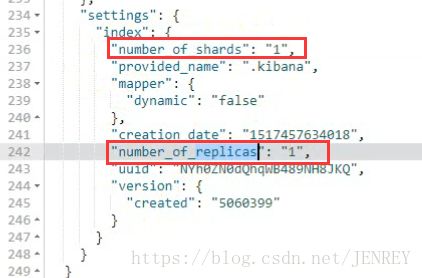
我们通过启动Kibana进行对接的ES,默认自动在ES上创建了一个index库,这个库有个特点,这个库有一个主分片primary shard,有一个replica shard 副分片
如下图所示,我们目前windows的状况是启动了一个ES的集群,这个集群里面只有一个ES的节点。
然后我们启动了一个kibana
kibana识别到了这个ES节点,kibana默认在上面创建了一个index,这个index的分片情况是 1 primary shard 和1 replica shard

但是可能咱们现在用的这个版本有了一些优化可能就跟上面说的不一样了。我们现在ES的状态是green
如何把集群的状态由yellow变成green?
我再启动一个节点(换个路径再次解压ES的压缩包在启动起来),让之前的那个有地方放置就好了。
再次执行查询健康的命令,效果图如下

red:不是所有的primary shard 都是active的状态,这时候是危险的,至少我们不能保证写数据是安全的。
这里的效果图是没有搭建第二个ES的节点的(因为电脑空间不太够了)
GET _cat/health 查看集群的健康状况
GET _all
PUT 类似于SQL中的增
DELETE 类似于SQL中的删
POST 类似于SQL中的改
GET 类似于SQL中的查
index的操作:
PUT /aura_index 增加一个aura_index的index库

GET _cat/indices 命令查询ES中所有的index索引库

5:代表的是 primary shard的个数
1:代表的是replica shard的个数是5,因为副本数为1代表有5个副分片,注意这个地方说的1是不包括自己本身的,我们的HDFS block3代表的是包括自己本身的
DELETE /aura_index 删除一个aura_index的index库

通过演示一个电商的例子,感受到ES的语法特点
1)插入一条商品数据

注意:我们插入数据的时候,如果我们的语句中指明了index和type,如果ES里面不存在,默认帮我们自动创建
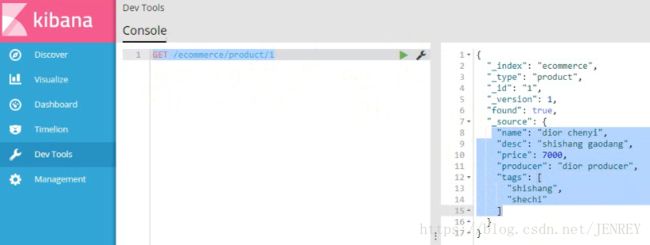
2)查询商品数据
使用这种语法: GET /index/type/id
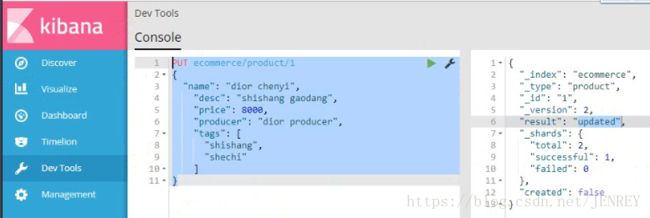
3)修改商品数据
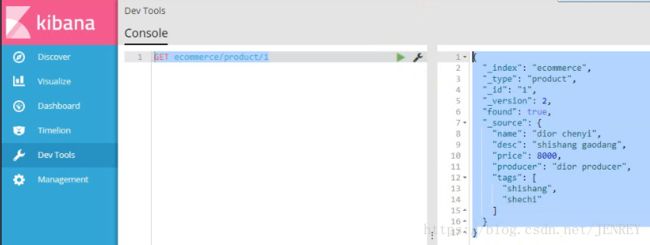
使用POST来修改数据,其实使用PUT也可以实现修改数据,原理和hbase比较像。POST的修改数据的方法在第4条中
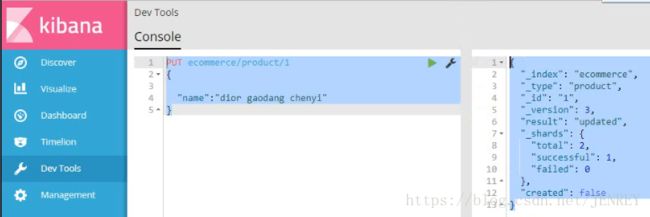
换个方式,下面这种操作也是成功的,会丢数据,是全局的修改

4)删除商品数据
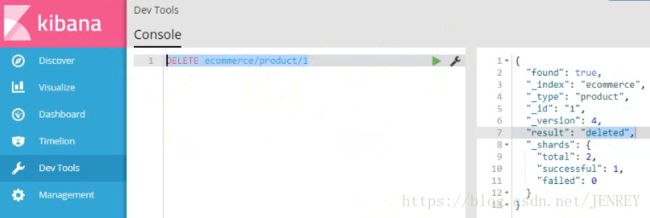
再次插入之前的数据,发现version是5,这就说明跟hbase是类似的,不会立刻删除,会在合适的时机进行删除。
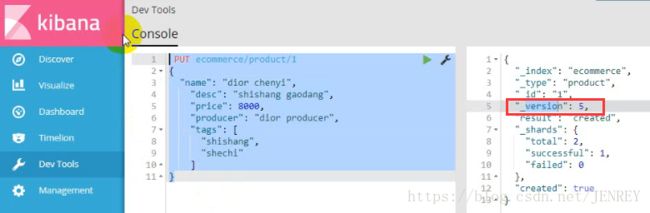
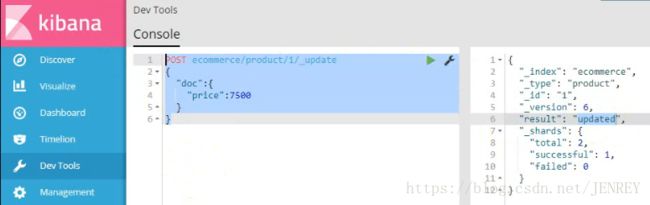
这次我们使用POST的方式进行修改数据,POST是局部更新数据,别的数据不动。PUT是全局更新
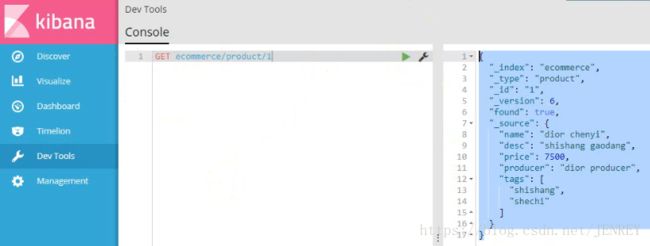
5)接着插入两条数据
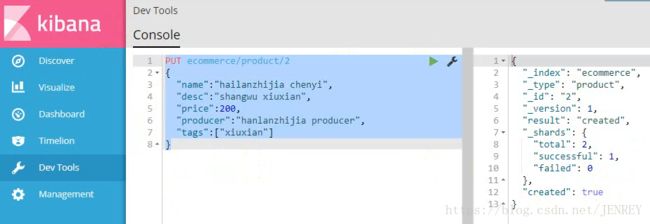

现在查看所有数据,类似于全表扫描
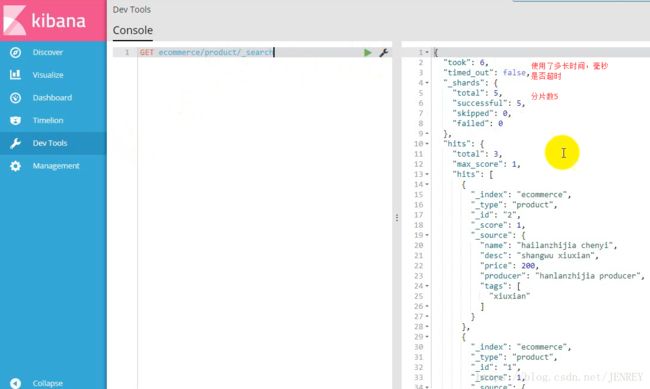
took:耗费了6毫秒
shards:分片的情况
hits:获取到的数据的情况
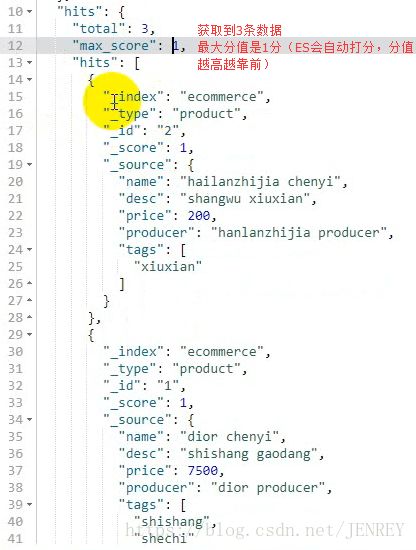
total:3 总的数据条数
max_score:1 所有数据里面打分最高的分数
_index:"ecommerce" index名称
_type:"product" type的名称
_id:"2" id号
_score:1 分数,这个分数越大越靠前出来,百度也是这样。除非是花钱。否则匹配度越高越靠前

ES最主要是用来做搜索和分析的。所以DSL还是对于ES很重要的
下面我们写的代码都是RESTful风格
query DSL:domain Specialed Lanaguage 在特定领域的语言
案例:我们要进行全表扫描使用DSL语言,查询所有的商品

使用match_all 可以查询到所有文档,是没有查询条件下的默认语句。
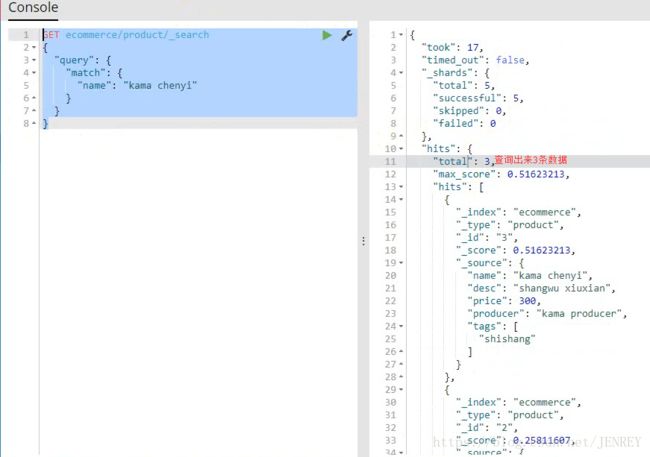
案例:查询所有名称里面包含chenyi的商品,同时按价格进行降序排序
如上图所示,name为dior chenyi的数据会在ES中进行倒排索引分词的操作,这样的数据也会被查询出来。

match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
下面我们按照价格进行排序:因为不属于查询的范围了。所以要写一个 逗号
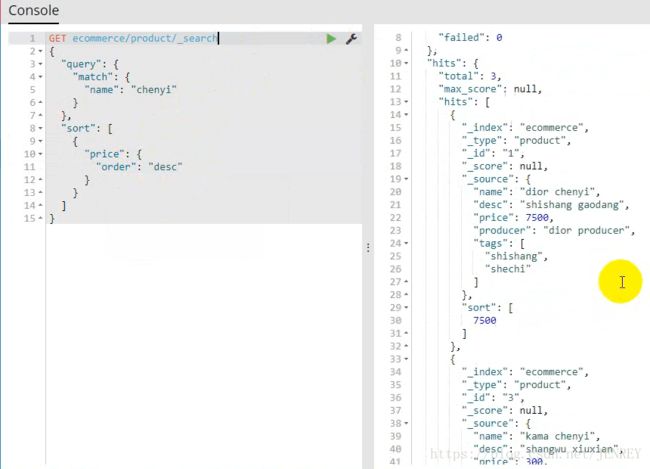
这样我们的排序就完成了
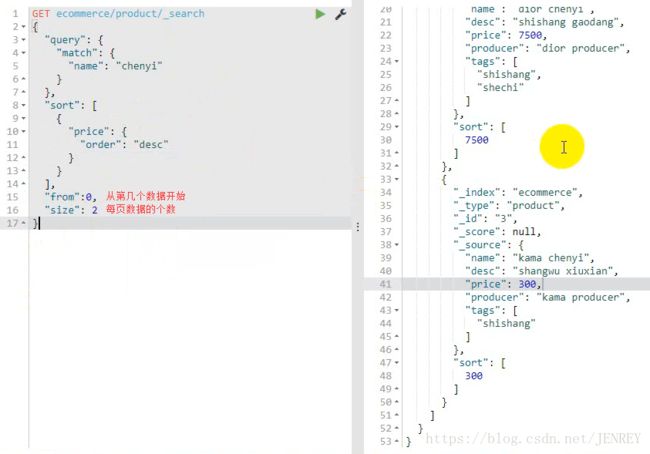
案例:实现分页查询
条件:根据查询结果(包含chenyi的商品),再进行每页展示2个商品
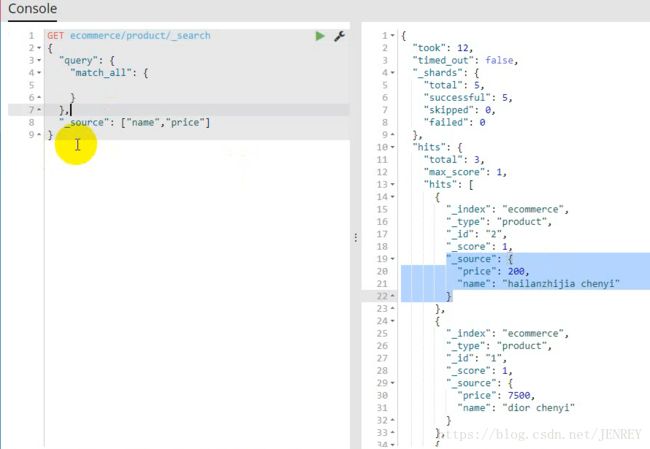
案例:进行全表扫面,但返回指定字段的数据
现在的情况是把所有的数据都返回了,但是我们想返回指定字段的数据内容就需要下面的方法了
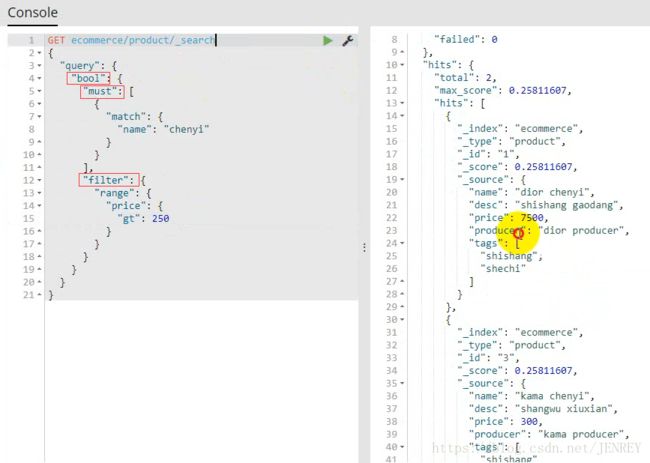
案例:搜索名称里面包含chenyi的,并且价格大于250元的商品
相当于 select * form product where name like %chenyi% and price >250;
因为有两个查询条件,我们就需要使用下面的查询方式
如果需要多个查询条件拼接在一起就需要使用bool
bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含以下操作符:
must :: 多个查询条件的完全匹配,相当于 and。
must_not :: 多个查询条件的相反匹配,相当于 not。
should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组
案例:展示一个全文检索的效果
首先查询条件也会进行分词
kama
chenyi
并集
案例:不要把条件分词,要精确匹配
但是我们现有有一种需求我就是想查询kama chenyi不要分词,要精确匹配到

百度就类似于这样
案例:把查询结果进行高亮展示

kama这个标签是默认的标签,是可以自定义的进行替换的,比如我们可以替换成kama,把这个输出到网页上,自然而然就是红色的了。
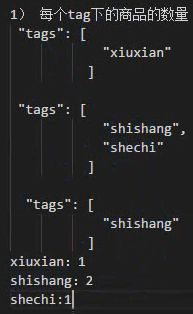
案例:计算每个标签tag下商品的数量
按标签进行分组类似于 select count(*) from product group by tag;
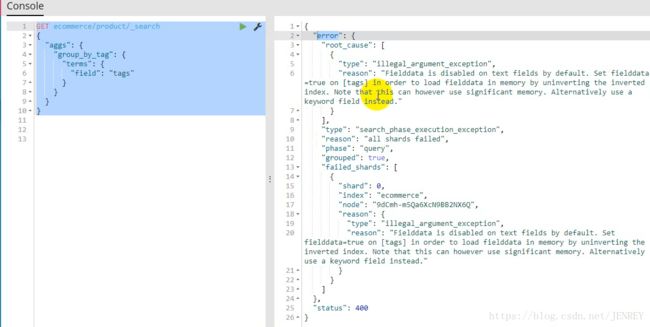
terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配
error是报错,但是这个语句是对的,这个报错在ES2之前是没有的,在ES5以后才有的,在5中fielddata=true 默认是false,以前都是true
group_by_tag是个名字随意取
所以我们需要先执行下面的代码进行一下设置的修改:
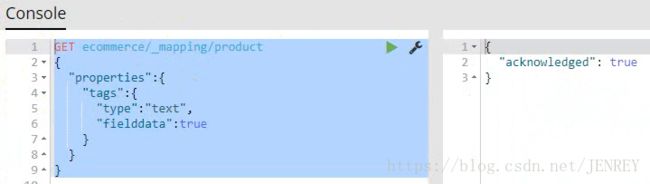
再次执行一次
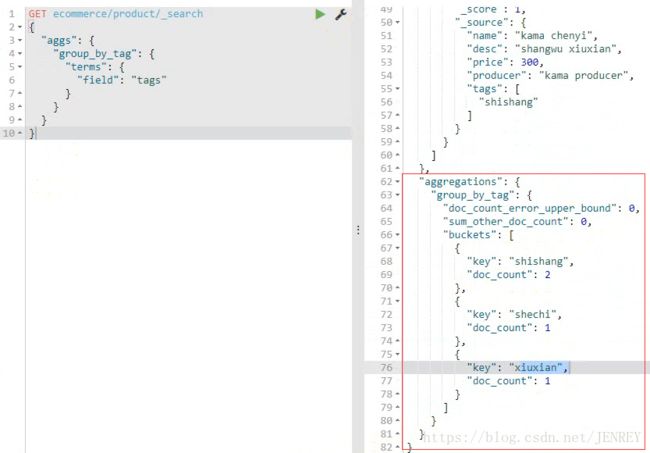
案例:对商品名称里面包含chenyi的,计算每个tag下商品的数量

案例:查询商品名称里面包含chenyi的数据,并且按照tag进行分组,计算每个分组下的平均价格

案例:查询商品名称里面包含chenyi的数据,并且按照tag进行分组,计算每个分组下的平均价格,按照平均价格进行降序排序

注意写的位置
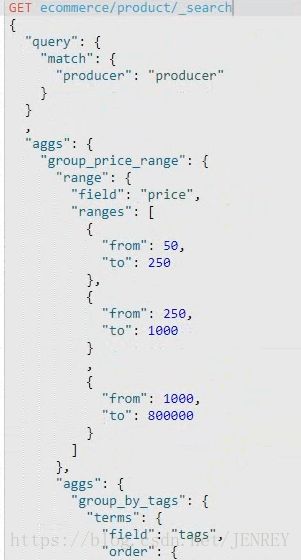
案例:查询出producer里面包含producer的数据,按照指定的价格区间进行分组,在每个组内再按tag进行分组,分完组以后再求每个组的平均价格,并且按照降序进行排序
range过滤允许我们按照指定范围查找一批数据

ES是一个分布式的系统,里面我们在使用的时候隐藏了复杂的分布式的机制
1)分片机制
插入数据的时候不是根据负载均衡来插入的,是根据一定的路由规则,比如我们就取哈希值取模,
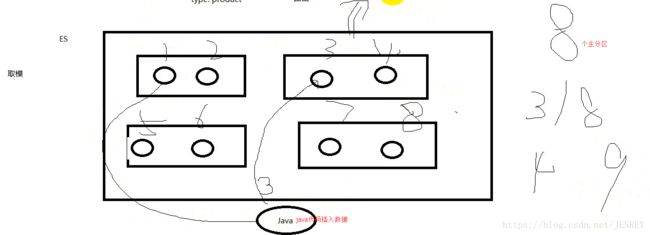
我们在创建一个index库的时候,我们可以指定primary shard的数量,也可以指定replica的数量,如果不指定,那么默认primary shard=5 replica=1 所以 replica shard=5,过了一段时间发现数据量很大,我们primary shard不够用了,那么这个时候想修改shard 的个数,能不能改成20个?答案:不能!!原来本应该插入到8的位置,结果插入到了9的位置,这样计算查询规则就错了。所以主分片个数是不能修改的,但是副分片的个数是可以进行修改的。具体怎么完成的那是ES内部的事情,我们先不用考虑。我们写了段java的代码插入数据到主分片里面去了。具体怎么插入的,插入到哪个主分片里面是不需要我们来管的。所以就是把这些功能给隐藏起来了。
如果真的遇见了这样的事,再建一个库,那个库的分片是20,用代码查询出来再导入到这个库中,只能用这个方法
总结:我们操作的时候很轻松的就把数据存入到我们的ES里面了。存入的时候我们并不关心,数据存到哪个分片里面去。
2)集群的发现机制
我们做过一个实验,一开始我们只启动了一个ES的节点,这个时候这个ES的状态是yellow,后来我们又启动了一个ES节点,发现颜色变成了green,这说明,我们后面启动的这个节点,也自动加入了这个集群。那么这个机制就是集群的发现机制。对于我们也是隐藏起来了。我们没必要知道
3)shard 会进行负载均衡
Hbase中如果你新加入了一个Hbase节点,不会自动的进行负载均衡,需要执行一个命令
但是ES不一样。只要你加入了一个节点,会自动帮你进行负载均衡
扩容分为:垂直和水平扩容
我们之前的大数据技术都是分布式的部署在集群上面的。如果我们的资源不够用了,这个时候就涉及到了扩容,我们是垂直扩容还是水平扩容呢?
假设我们每个节点能存储1T的数据,现在我们要存储5T的数据,
垂直扩容就是把其中的一台换了,换成性能更强的节点。有可能一台节点就能存5T。
水平扩容就是新加服务器直到能存下来5T的数据,我们一般都是用水平扩容,比如1T是1万。5台5万,但是单台5T的价钱可能是50万。所以我们几乎不太可能用这种方式。
但是可能那么namenode节点可能是采用垂直扩容
在分布式的技术里面。我们大多都是主从式架构
ES是对等式的架构。ES里面也有master节点一说。但是我们不太关心。只需要在配置文件中指定一下让哪几个节点有机会成为主节点。
ES中master的作用
1)管理集群的元数据,比如说索引的创建,和删除等等
2)集群里面master也是自动选举的。
看到这里有个疑问这不也是主从式架构么?为什么叫对等式架构呢?
HDFS是主从式架构,有namenode和datanode,我们无论是上传数据也好还是下载数据也好都要跟namenode进行交互,交互完才能到datanode中,但是我们的ES无论上传和下载数据也好,我们不需要跟master进行交互。节点之间的关系都是对等的,每个节点都可以进行接收请求和响应请求。
在ES中,我们开发好了java代码要跟ES进行交互。他会随意找一台节点,但是这台节点不一定有我们要查询的数据,但是我们不知道,ES节点是知道的,每个ES里面都知道其他的数据存在哪,ES的节点会自动帮你把请求发到要查询数据的节点上。这样就真的查询出来了。而我们随意找的这个节点叫做协调节点,真正数据存放的节点会把数据返回给协调节点。协调节点再给我们java的代码
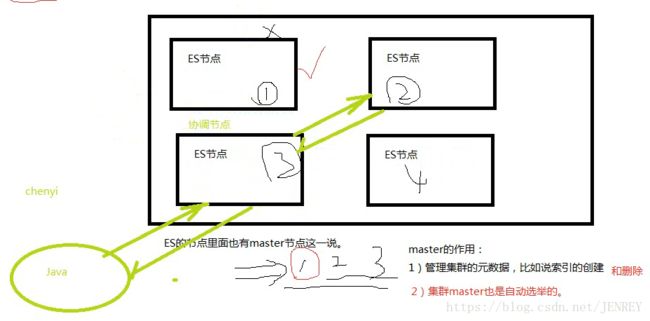
每一个节点都可以接受和相应请求。如果随机找的刚好是数据所在的节点,那么这个节点即是协调节点又是响应节点。
1)index可以包含多个type,同样一个index下面也可以有多个shard
2)在ES里面每个shard就是最小的一个工作单元,承载了部分数据
3)如果在ES集群里面增加或减少节点,shard会自动的实现负载均衡
4)primary shard乐意进行读和写,replica shard负责读
5)primary shard在创建index的时候就固定了,不能修改了。
6)默认创建一个index的时候,primary shard的数量是5,replica的数量是1,也就是说默认情况下有10个shard,其中有5个primary shard,5个是replica shard
7)primary shard和自己的replica shard是不能在同一台服务器上的。
1)master的选举
2)replica的容错
3)数据恢复

下图是指定ID号的方式

下图是自动生成ID号
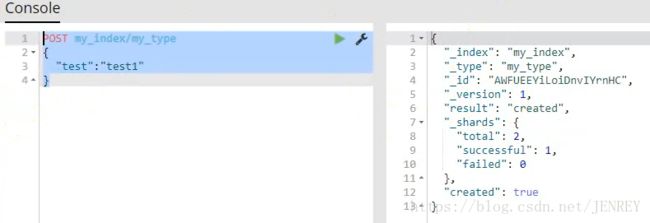

悲观锁:很悲观,自己操作的时候别的线程就不能进行操作。所以在电商的情况下体验性很不好,但是不容易出错
乐观锁:很乐观,因为现在剩3件了,假设version号是5,A,B线程同时进行访问操作,AB线程拿到的都是3件,version都是5,A线程先购买了一件就是3-1=2 ,然后A线程拿着2和version号5去更新数据,发现version是5就把3件更新为2件,同时version变成了6;然后B线程买了一件就是3-1=2 然后拿着2和version号5去更新,发现version号不匹配,此时重新获取一下version号和仅剩的件数2,然后2-1=1,然后拿着1和version号6去更新数据,发现version对上了。此时更新成功。
package com.aura.utils;
import com.aura.dao.Dao;
import org.elasticsearch.action.admin.indices.create.CreateIndexResponse;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexResponse;
import org.elasticsearch.action.admin.indices.mapping.put.PutMappingResponse;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.IndicesAdminClient;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import org.junit.Test;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import static org.elasticsearch.common.xcontent.XContentFactory.jsonBuilder;
public class EsUtils {
//ES client
private static TransportClient client;//获取一个ES的客户端对象叫client
private static final String CLUSTER_NAME="elasticsearch";
private static final String HOST_IP="127.0.0.1";
private static final int TCP_PORT=9300;
static Settings sttings=Settings.builder()
.put("cluster.name",CLUSTER_NAME)//集群名字CLUSTER_NAME
.build();
/**
* 获取client对象
*/
public static TransportClient getCLient(){
if(client == null){
synchronized (TransportClient.class){
try {
client=new PreBuiltTransportClient(sttings)
.addTransportAddress(
new InetSocketTransportAddress(InetAddress.getByName(HOST_IP),TCP_PORT)#ES的master的主机名和端口号默认9300
);
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
}
System.out.println("连接成功"+client.toString());
return client;
}
/**
* 通过ES的客户端对象,获取索引管理对象
* 获取index admin 对象
*/
public static IndicesAdminClient getIndicesAdminClient(){
return getCLient().admin().indices();
}
/**
* 创建一个 index 库
* 注意:es里面索引库的名称 都需要小写
*/
public static boolean createIndex(String indexName){
CreateIndexResponse response = getIndicesAdminClient()
.prepareCreate(indexName.toLowerCase())#通过索引管理对象创建索引
.setSettings(
Settings.builder()
.put("index.number_of_shards", 3)#分片个数
.put("index.number_of_replicas", 2)#副分片个数
).execute().actionGet();
return response.isShardsAcked();//返回boolean值,是否创建成功
}
/**
* 创建index,对上面方法的优化
* @param indexName
* @param numberShards
* @param numberreplicas
* @return
*/
public static boolean createIndex(String indexName,int numberShards,int numberreplicas){
CreateIndexResponse response = getIndicesAdminClient()
.prepareCreate(indexName.toLowerCase())
.setSettings(
Settings.builder()
.put("index.number_of_shards", numberShards)
.put("index.number_of_replicas", numberreplicas)
).execute().actionGet();
return response.isShardsAcked();
}
/**
* 删除index
*
*/
public static boolean deleteIndex(String indexName){
DeleteIndexResponse response = getIndicesAdminClient()
.prepareDelete(indexName.toLowerCase())
.execute().actionGet();
return response.isAcknowledged();
}
/**
* 设置mapping 建表语句
* @param indexName
* @param typeName
* @param mappingStr
* @return
*/
public static boolean setIndexMapping(String indexName,String typeName,XContentBuilder mappingStr){
IndicesAdminClient indicesAdminClient = getIndicesAdminClient();
PutMappingResponse putMappingResponse = indicesAdminClient.preparePutMapping(indexName.toLowerCase())
.setType(typeName)
.setSource(mappingStr)
.execute()
.actionGet();
return putMappingResponse.isAcknowledged();
}
@Test
public void test1(){
/**
* PUT my_index/_mapping/type_1709x
{
"properties": {
"user":{
"type": "text"
},
"postDate":{
"type": "date"
},
"message":{
"type": "text"
}
}
}
*
*/
try {
XContentBuilder xContentBuilder = jsonBuilder().startObject()
.startObject("properties")
.startObject("user")
.field("type", "text")
.endObject()
.startObject("postDate")
.field("type", "date")
.endObject()
.startObject("message")
.field("type", "text")
.endObject()
.endObject()
.endObject();
setIndexMapping("my_index","type_1709x",xContentBuilder);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 往type里面添加一条数据
*/
@Test
public void test4(){
String json="{\n" +
" \"user\":\"malaoshi\",\n" +
" \"postdate\":\"2018-11-11\",\n" +
" \"message\":\"haokaixin\"\n" +
"}";
TransportClient client = getCLient();
IndexResponse indexResponse = client.prepareIndex("my_index", "type_1709x", "1")
.setSource(json, XContentType.JSON)
.get();
System.out.println( indexResponse.status().getStatus());
}
/**
* 往type里面添加一条数据
*/
@Test
public void test5(){
HashMap json = new HashMap();
json.put("user","Xiao li");
json.put("postdate","2017-12-12");
json.put("message","Xiao li trying out ES");
TransportClient client = getCLient();
IndexResponse indexResponse = client.prepareIndex("my_index", "type_1709x", "2")
.setSource(json, XContentType.JSON)
.get();
System.out.println(indexResponse.status().getStatus());
}
/**
* 查询数据
*/
@Test
public void test6(){
TransportClient client = getCLient();
GetResponse getFields = client.prepareGet("my_index", "type_1709x", "2").execute().actionGet();
//{"postdate":"2017-12-12","message":"Xiao li trying out ES","user":"Xiao li"}
System.out.println(getFields.getSourceAsString());
//{postdate=2017-12-12, message=Xiao li trying out ES, user=Xiao li}
System.out.println(getFields.getSourceAsMap());
}
/**
* 修改数据
*/
@Test
public void test7(){
HashMap json = new HashMap();
json.put("user","xiao li");
json.put("postdate","2017-11-11");
json.put("message","xiao li trying out elasticsearch");
TransportClient client = getCLient();
UpdateResponse updateResponse = client.prepareUpdate("my_index", "type_1709x", "2")
.setDoc(json)
.execute().actionGet();
System.out.println(updateResponse.status().getStatus());
}
/**
* 删除
*/
@Test
public void test8(){
TransportClient client = getCLient();
DeleteResponse deleteResponse = client.prepareDelete("my_index", "type_1709x", "2").execute().actionGet();
System.out.println(deleteResponse.status().getStatus());
}
/**
* 具有条件的查询
*/
@Test
public void test9(){
TransportClient client = getCLient();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("user", "malaoshi");
SearchResponse searchResponse = client.prepareSearch("my_index")
.setTypes("type_1709x")
.setQuery(termQueryBuilder)
.execute().actionGet();
SearchHits hits = searchResponse.getHits();
System.out.println(hits.totalHits);
for(SearchHit hit:hits){
System.out.println(hit.getScore());
System.out.println(hit.getSourceAsString());
}
}
public static void setMapping(){
try {
XContentBuilder xContentBuilder1 = jsonBuilder().startObject()
.startObject("properties")
.startObject("id")
.field("type", "long")
.endObject()
.startObject("title")
.field("type", "text")
.field("analyzer", "ik_max_word")
.field("search_analyzer", "ik_max_word")
.endObject()
.startObject("content")
.field("type", "text")
.field("analyzer", "ik_max_word")
.field("search_analyzer", "ik_max_word")
.endObject()
.startObject("url")
.field("type", "keyword")
.endObject()
.startObject("reply")
.field("type", "long")
.endObject()
.startObject("source")
.field("type", "keyword")
.endObject()
.startObject("postDate")
.field("type", "date")
.field("format", "yyyy-MM-dd HH:mm:ss")
.endObject()
.endObject()
.endObject();
setIndexMapping("sportnews","news",xContentBuilder1);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
// createIndex("my_index",3,2);
// deleteIndex("test1709");
/**
* 第一步:创建Index 库
*/
// createIndex("sportnews",3,1);
/**
* 第二步:创建表
* 设置mapping
*/
// setMapping();
/**
* 第三步:
* 从MySQL导入数据到ES
*/
// Dao dao = new Dao();
// dao.getConnection();
// dao.mysqlToEs();
}
}
模仿百度文库的效果。



然后一直下一步就行了。
配置pom.xml文件为如下所示
4.0.0
jenrey
ES_project
1.0-SNAPSHOT
war
ES_project Maven Webapp
http://www.example.com
UTF-8
1.7
1.7
junit
junit
4.12
test
javax.servlet
javax.servlet-api
3.1.0
provided
mysql
mysql-connector-java
5.1.6
org.elasticsearch.client
transport
6.3.2
ES_project
maven-clean-plugin
3.0.0
maven-resources-plugin
3.0.2
maven-compiler-plugin
3.7.0
maven-surefire-plugin
2.20.1
maven-war-plugin
3.2.0
maven-install-plugin
2.5.2
maven-deploy-plugin
2.8.2
启动项目:




出现上图的No artifacts marked for deployment的警告并出现如下几张图所示的效果。


这时候不要慌!!!按照下图所示进行操作,再次打开配置菜单



添加xxxxxxx:war exploded
Tomcat部署中war与war exploded区别
war模式:即发布模式,将Web工程以war包的形式上传到服务器。war exploded模式:将Web工程以当前文件夹的位置关系上传到服务器。 【注】
然后保存,然后再按照下图修改,应用,确定

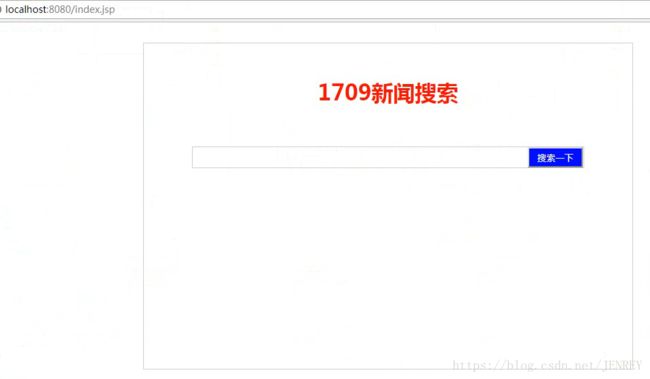
index.jsp代码
<%@ page contentType="text/html; charset=UTF-8" language="java" %>
新闻搜索
1709新闻搜索&llt;/h1>
上述代码写完的网页前端效果如下

result.jsp页面代码
<%@ page import="java.util.ArrayList" %>
<%@ page import="java.util.Map" %>
<%@ page import="java.util.Iterator" %><%--
Created by IntelliJ IDEA.
User: Administrator
Date: 2018/2/2
Time: 10:10
To change this template use File | Settings | File Templates.
--%>
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
结果页面
<%
String queryback=(String)request.getAttribute("queryback");
ArrayList> newslist=(ArrayList>)request.getAttribute("newsist");
String count=(String)request.getAttribute("count");
int pages=Integer.parseInt(count)/10 +1;
pages=pages>10?10:pages;
%>
共搜索到1111条结果,耗时11秒
<%
if(newslist.size() > 0){
Iterator> iterator = newslist.iterator();
while (iterator.hasNext()){
Map news = iterator.next();
Object url = news.get("url");
String title = (String) news.get("title");
String content =(String) news.get("content");
content=content.length()>300?content.substring(0,300)+"...":content;
%>
<%=title%>
<%=content%>
<%
}
}
%>
<%
for ( int i=1;i<=pages;i++){
%>
- 第<%=i%>页
<%
}
%>
- 共<%=pages%>页
上面是终极代码,初级代码的效果图如下
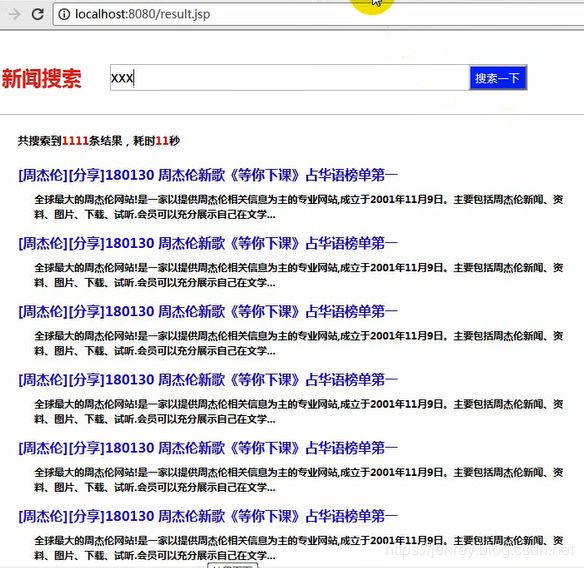
3)导maven包

 点赞 58
点赞 58  评论 26
评论 26  分享
分享
海报分享
扫一扫,分享海报

 收藏 130
收藏 130  手机看
手机看
分享到微信朋友圈
x扫一扫,手机阅读

关注
qq_27787701的博客
12-06 7399


qianlia的博客
03-25 14万+
lauyiran的博客
01-16 3万+
程序员吴小胖
07-15 987
weixin_42207486的博客
09-14 7620
weixin_34168700的博客
11-19 1615
zsvole的博客
01-18 1万+
weixin_41126842的博客
07-09 4264
Java新生代
04-07 6万+
