【数据库】数据库原理
1、事务
概念:事务是满足ACID特性的一组操作
- 原子性(Atomic):一组操作要么都执行,要么都不执行
执行失败的事务,通过回滚将已执行的操作进行撤销。回滚通过回滚日志(Undo Log)来实现,它记录着事务执行所作的操作,反向执行就可以恢复事务前的状态 - 一致性(Consistency):数据库在事务执行前或后都保持一致性状态
就是说在事务执行之前或执行之后,所有其他事务对同一个数据的读取结果是相同的,不存在你读是一个值,另一个操作读又是另一个值的情况 - 隔离性(Isolation):一个事务所作的修改,在提交之前,对其他事务是不可见的
- 持久性(Durability):事务一旦提交,它所做的修改将永久地保存在数据库中,即使系统崩溃也不能丢失
系统发生崩溃可以用重做日志(Redo Log)进行恢复,从而实现持久性。与回滚日志记录数据的逻辑修改不同,重做日志记录的是数据页的物理修改
undo log 和 redo log
- undo log记录的是逻辑修改,并不是真实的对数据库的修改,当事务回滚时,将逻辑恢复为原来的样子
- 用途:事务的回滚,MVCC
- 分类:
insert undo log 是插入数据产生的undo log,只对本条事务可见,所以事务提交后可以删除
update undo log是删除或修改时产生的undo log,可能提供MVCC,所以事务提交后不可删除- redo log主要应对系统崩溃的情况,记录的是数据页的物理变化,当数据库崩溃的时候,将数据库恢复为原来的样子
- 组成:redo log buffer 和 redo log file,分别存在内存和磁盘中
- 记录时机:内存中数据——内存中redo——磁盘redo——磁盘数据
2、并发一致性问题
并发环境下,很难保证事务之间的隔离性,因此会发生很多一致性问题
- 丢失修改:一个事务的更新操作被另一个事务的更新操作覆盖了
- 脏读:一个事务读到了另一个事务未提交的数据,如果那个事务后面回滚了,读到的就是一个无效的脏数据
- 不可重复读:同一个事务内,前后读同一个数据,读到的值不一致
- 幻读:一个事务内两次读一个范围的数据,之间有另一个事务往这个范围内插入了新数据,导致这两次都读的结果不一样,本质上也属于不可重复读
通过并发控制可以解决并发一致性问题,一个途径是加锁,但是如果让开发人员控制加锁太复杂了,数据库管理系统提供了事务间的隔离级别,来简化这个过程
3、隔离级别
- 读未提交:事务可以读到其他事务还没提交的数据
- 读已提交:事务只能读到其他事务已经提交的数据,也就是说,一个事务在提交之前,它所做的修改对于其他的事务来说是不可见的
- 可重复读:保证在同一个事务中多次读取同一数据的结果是一样的
- 可串行化:事务串行化执行,这样互不干扰,就不会产生一致性问题。这个隔离级别需要加锁实现

4、MVCC
多版本并发控制是MySql的InnoDB引擎实现隔离级别的一种具体方式
主要实现了读已提交和可重复读两种隔离级别,默认的隔离级别是可重复读
读未提交每次都读最新的数据,无需MVCC
可串行化需要加锁,光靠MVCC做不到
- 行格式
行格式就是InnoDB 在保存每一行的数据的时候,究竟是以什么样的格式来保存这行数据的

真实数据列部分中,列1…列N是我们存储的正常数据,除此之外
DB_ROW_ID是行id,用来唯一标识一行数据
DB_TRX_ID是事务id,表示了当前行是被哪个事务修改的。当一个事务开启的时候,会分配到一个事务id,这个id是严格单调递增且唯一的
DB_ROLL_PTR是回滚指针,它指向一条undo log的地址,通过这条undo log,可以使这行数据恢复到上一个版本
- MVCC
核心思想: 保存数据库行的历史版本,通过对数据行的多个版本进行管理来实现对数据库的版本控制,换句话说,每个数据库行是有多个历史版本的
精髓在下图,绿色箭头相当于undo log,可以恢复出数据行的历史版本
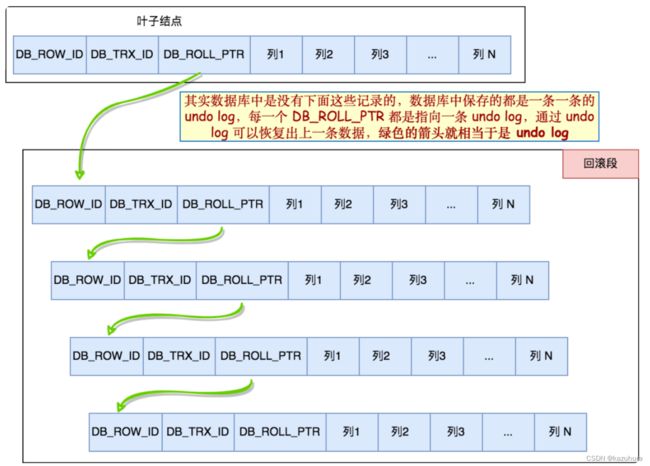
接下来结合两个隔离级别来说明这个图
1、可重复读
当我们开启一个事务的时候,会申请到一个事务id,同时在事务开启的一瞬间会生成一个数组,这个数组记录了此时活跃的事务id,也就是已开启还未提交的事务
当当前事务想要去查看某一行数据的时候,会先看那行数据的DB_TRX_ID:
- 如果
DB_TRX_ID等于当前事务id:说明这行数据就是当前事务修改的,数据可见- 如果
DB_TRX_ID小于数组的最小值:说明在当前事务开启之前,这条数据已经提交了,那数据就是可见的- 如果
DB_TRX_ID大于数组的最大值:说明修改这条数据的事务是在当前事务开启后才开启的,那数据就不可见- 如果
DB_TRX_ID的值在数组最大值和最小值之间,但不在数组中:说明这条数据是被和当前事务同时活跃的,但是提交的早的事务修改的,所以数据可见- 如果
DB_TRX_ID的值在数组最大值和最小值之间,但不在数组中:说明修改数据的事务还没提交,数据不可见
当数据不可见的时候,就沿着undo log恢复上一个版本,进行上面的判断
2、读已提交
和可重复读是类似的,只是它会在执行每一个语句前生成这个数组,也就是一致性视图
3、MVCC的注意点
注意MVCC不是完全不加锁,只是避免了select操作时的加锁
读的时候使用了快照读和上面的一致性视图,
写的时候使用的是当前读,而不是快照读,这样也避免了丢失修改
在一定程度上实现了读写并发控制,读写互不阻塞
5、Next-Key Locks
MVCC 不能解决幻影读问题,Next-Key Locks 就是为了解决这个问题而存在的。在可重复读(REPEATABLE READ)隔离级别下,使用 MVCC + Next-Key Locks 可以解决幻读问题
Record Locks
锁定一个记录上的索引,而不是记录本身
Gap Locks
锁定索引之间的间隙,但是不包含索引本身。例如当一个事务执行以下语句,其它事务就不能在 t.c 中插入 15
SELECT c FROM t WHERE c BETWEEN 10 and 20 FOR UPDATE;
Next-Key Locks
它是 Record Locks 和 Gap Locks 的结合,不仅锁定一个记录上的索引,也锁定索引之间的间隙。它锁定一个前开后闭区间,例如一个索引包含以下值:10, 11, 13, and 20,那么就需要锁定以下区间
(-∞, 10]
(10, 11]
(11, 13]
(13, 20]
(20, +∞)
6、关系数据库设计理论
1. 第一范式 (1NF)
属性不可分
2. 第二范式 (2NF)
每个非主属性完全函数依赖于键码
消除部分依赖
可以通过分解来满足
3. 第三范式 (3NF)
非主属性不传递函数依赖于键码
消除传递依赖
可以通过分解来满足