Redis实战篇笔记——优惠券秒杀业务
Redis实战篇笔记(三)
文章目录
- Redis实战篇笔记(三)
- 前言
-
- 优惠券秒杀业务
-
- 全局唯一ID
- 添加秒杀优惠券
- 实现优惠券秒杀的下单功能
- 超卖问题
- 实现一人一单
- 集群下的并发安全问题
- 总结
前言
本系列文章是针对于黑马的Redis教学视频中的实战篇,本篇文章是实战篇的第二部分——优惠券秒杀业务
优惠券秒杀业务
全局唯一ID
为什么订单的id不使用自增呢?
- id的规律性太明显(用户会根据id的规律猜测到信息)
- 受单表数据量的限制
- 当使用分布式系统,表进行拆分,id可能会重复
**全局 id 处理器:是一种在分布式系统下用来生产全局唯一ID的工具,一般满足下列特征:
- 唯一性
- 高可用 (用户任何时候来生成 id,都要可以生成 id )
- 高性能
- 递增性
- 安全性
用Redis来实现全局 id 处理器
- 递增性,唯一性(Redis中的string有一个increase命令,可保证唯一)
- 高可用(Redis的集群方案,主从方案,哨兵方案)
- 高性能(Redis的性能比数据库好很多)
- 安全性(可以不使用Redis自增的数值,可以拼接一些其他的信息)
**全局 ID的组成部分
- 符号位:1 bit,永远为0
- 时间戳:31 bit,以秒为单位,可以使用69年(雪花算法是以毫秒为单位,41bit位也是用69年,毫秒和秒是1000的进制,1000相当于1024,就是10个 bit)
- 序列号:32 bit,秒内的计数器,可以支持每秒产生 2^32个不同ID
**看到这里,可能很多朋友会感觉与雪花算法比较像,确实大致上是比较像的,但是还是有很多不同,具体的大家可以看这篇文章 **https://zhuanlan.zhihu.com/p/85837641
package com.hmdp.utils;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.time.LocalDateTime;
import java.time.ZoneOffset;
import java.time.format.DateTimeFormatter;
@Component
public class RedisIdWorker {
/**
* 开始的时间戳(2022年1月1日0时0分0秒)
*/
@Resource
private StringRedisTemplate stringRedisTemplate;
private static final long BEGIN_TIMESTAMP=1640995200;
private static final int COUNT_BITS=32;
//不同的业务,用不同的自增策略
public long nextId(String keyPrefix){
// 1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowSecond - BEGIN_TIMESTAMP;
// 2.生成序列号,
// 2.1 获取当前日期,精确到天,如果按月的话,yyyy:MM:dd就好了,redis的key可以按冒号自动分层
String date = now.format(DateTimeFormatter.ofPattern("yyy:MM:dd"));
// 不会出现null,因为 increment命令当key不存在时,会自动创建
long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
// 3.拼接并返回
// 时间戳向左移动32位,为序列号留出32位,然后留出来的32位都是0,然后进行或运算,
// 与0做或运算就相当于把这个数本身保留下来了(梦回计算机导论)
return timestamp << COUNT_BITS | count;
}
// 生成一个任意时间的时间戳,然后ID
public static void main(String[] args) {
LocalDateTime time = LocalDateTime.of(2022, 1, 1, 0, 0, 0);
long second = time.toEpochSecond(ZoneOffset.UTC);
System.out.println(second);
}
}
测试 ID 生成器(虽然只是给测试方法,但里面还是提到了很多并发操作的知识)
@Test
void testId() throws InterruptedException {
// 倒计时锁存器
CountDownLatch latch = new CountDownLatch(300);
Runnable task=()->{
for (int i=0;i<100;i++){
long id = redisIdWorker.nextId("order");
System.out.println("id="+id);
}
// 完成业务后,让线程计数器减一
latch.countDown();
};
long begin = System.currentTimeMillis();
for (int i = 0; i < 300; i++) {
es.submit(task);
}
// 如果不加latch.await(),直接获取时间,因为上面这个for循环只是将300的任务提交到线程池了,
// 但是提交完后,线程还没有做完,就直接获取时间,得到的是提交消耗的时间
// latch.await()是会阻塞线程,直到执行了n次countDown才会释放线程。
latch.await();
long end = System.currentTimeMillis();
System.out.println("time="+(end-begin));
}
关于具体的 await 和 countDown 操作大家可以看这篇文章
https://blog.csdn.net/u011441473/article/details/103072449
添加秒杀优惠券
其实这个接口黑马给的代码里面直接有了,业务也不复杂,是常见的业务,在这里就不细说了
唯一一个要注意的点就是这个添加秒杀优惠券前端没有实现,可以通过接口文档或者 postman 进行实现
下面是一个秒杀优惠券的例子,大家要把时间设置为在你当前时间的后面,要不然前端是不会显示的
{
"shopId":1,
"title":"100元代金券",
"subTitle":"周一至周五均可使用",
"rules":"全场通用\\n无需预约\\n可无限叠加\\不兑现、不找零\\n仅限堂食",
"payValue":8000,
"actualValue":10000,
"type":1,
"stock":100,
"beginTime":"2022-11-13T22:09:17",
"endTime":"2022-11-16T12:09:04"
}
实现优惠券秒杀的下单功能
下单前需要判断两点
- 秒杀是否开始或结束,如果尚未开始或已经结束则无法下单
- 库存是否充足,不足无法下单

这个下单还只是正常的业务,难的再后面
@Resource
private ISeckillVoucherService seckillVoucherService;
@Resource
private RedisIdWorker redisIdWorker;
@Transactional(rollbackFor = Exception.class)
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
return Result.fail("秒杀尚未开始");
}
// 3.判断秒杀是否结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
return Result.fail("秒杀已经结束");
}
// 4.判断库存是否充足
if (voucher.getStock()<1) {
return Result.fail("库存不足");
}
// 5.扣除库存
boolean success = seckillVoucherService.update()
.setSql("stock=stock-1").eq("voucher_id", voucherId).update();
if(!success){
return Result.fail("库存不足");
}
// 6.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
long orderId = redisIdWorker.nextId("order");
// 添加订单id
voucherOrder.setId(orderId);
// 添加用户id
Long userId = UserHolder.getUser().getId();
voucherOrder.setUserId(userId);
// 添加优惠券id
voucherOrder.setVoucherId(voucherId);
this.save(voucherOrder);
return Result.ok(orderId);
}
超卖问题
基于上面的代码,我们模拟两百个用户来抢购这个优惠券(这个接口请求前要求登录,所以我们要在请求头中加上token)

最后的结果我们去数据库看一下
![]()
这个秒杀券的库存编程了 -9,订单数也变成了 109,奇怪我们明明在代码中判断了,为什么最后库存还会出现负数呢?。其实我们我们的代码是有问题的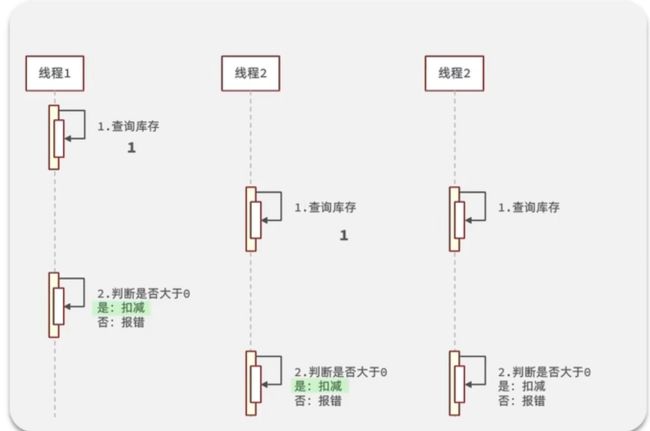
当线程1来查库存的时候,它查到库存是 1 ,就在这时候线程2来查库存,它查到的也是1,线程2查完后,线程1拿它刚查到的库存进行判断,大于0进行扣减。线程1 扣减完,线程2也根据它查到的库存进行判断,也大于0进行扣减,所以这时候库存就变为了-1。
为了解决这种问题,我们要去加锁。锁有两种:悲观锁和乐观锁
悲观锁:
- 认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行
- Synchronized,Lock都属于悲观锁
乐观锁:
- 认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其他线程对数据做了修改
- 如果没有修改则认为是安全的,自己更新数据
- 如果已经被其他线程修改说明发送了安全问题,此时可以重试或抛出异常
乐观锁的解决方案
- 版本号法

- 版本号法 就是在原来的表中加入一个 version字段来控制版本,每次扣减的时候不仅要更新库存,还要更新版本,并且还要判断版本是否和先前查询的版本号是否一致,一致才可以更新。但这个方法还增加额外的内存消耗,其实我们也可以直接用 stock 当做版本号来使用,由此我们也来到了第二个方案 (CAS方案)
- CAS方案(Compare And Set)
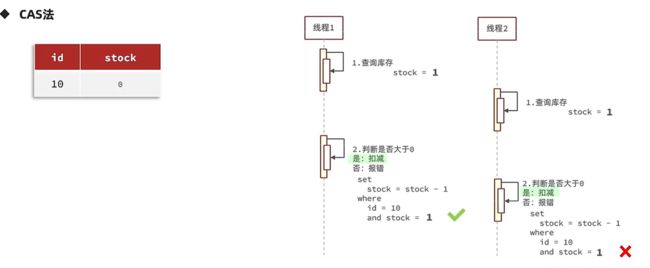
- 其实这个方案的思想跟第一个方案的思想是一致的,无非就是把库存变成了版本号而已。
其实代码修改很简单:![]()
改成这样就可以了。但是这样会有一个问题,当100个线程同时来抢库存,第一个库存抢完后,修改了库存,但是其他的线程判断发现此时的库存跟他们刚才查到的不一样了,于是他们都放弃了更新。
这就是问题所在,错误率太高,其实我们更新的时候只要判断库存大于0就可以了,即使来了200个线程一起来抢,当抢完后,就会发现库存为0了,就会放弃。更改的代码如下
boolean success = seckillVoucherService.update()
.setSql("stock=stock-1").eq("voucher_id", voucherId).gt("stock",0).update();

结果可以看到200个线程,异常率为50%,说明100个线程成功了。![]()
数据库的数据也能对上了。
实现一人一单
因为秒杀优惠券是一个比较重要的商品,他不可能让一个人买100份,所以针对重要物品,要实现一人一单的功能,第一个版本就是简单的再增加一个判断。
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if(count>0){
return Result.fail("用户已经购买过一次");
}
但是这样写,不用猜就知道肯定有问题,我们来看一下数据库

我们可以看到库存变成了90,订单表新增了10条数据,这个跟超卖问题差不多吧,就是那个同一时间,多个线程在判断,判断成功后,都去执行操作了,这样肯定不行,所以我们要给他加锁。
但是,我们这里要先想一下,还能用乐观锁吗?乐观锁是当数据发生不一致的时候再加锁,而我们这对于一人一单就没有做更新操作,我们就是获取数据,然后判断数据。我们的问题是,有多个线程同时获取数据,他们不可以同时获取数据。所以乐观锁不是很好使,我们只好用悲观锁了。
// ctrl+alt+m,实现将代码块快速封装为一个函数
//我们现在把 synchronized 加在了方法上,那锁的是this,也就是对当前对象加锁,但是这每个线程肯定要
//创建不同的对象,所以synchronized加在这里不是很合适
private synchronized Result getResult(Long voucherId) {
Long userId = UserHolder.getUser().getId();
// 判断一人一单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if(count>0){
return Result.fail("用户已经购买过一次");
}
// 5.扣除库存
boolean success = seckillVoucherService.update()
.setSql("stock=stock-1").eq("voucher_id", voucherId).gt("stock",0).update();
if(!success){
return Result.fail("库存不足");
}
// 6.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
long orderId = redisIdWorker.nextId("order");
// 添加订单id
voucherOrder.setId(orderId);
// 添加用户id
voucherOrder.setUserId(userId);
// 添加优惠券id
voucherOrder.setVoucherId(voucherId);
this.save(voucherOrder);
return Result.ok(orderId);
}
那我们是就要减小锁的范围,要对同一个用户加锁,可以对用户 id 加锁
@Transactional
// ctrl+alt+m,实现将代码块快速封装为一个函数
public Result getResult(Long voucherId) {
Long userId = UserHolder.getUser().getId();
//我们对userId加锁,把他用toString转成一个字符串来进行加锁。但是这样就可以了吗?
//还不行,因为,Long类型的toString底层是new 了一个String的,等于说还是比较对象的地址,那不行
//所以我们要用一个方法 intern(),获取字符串的值,这样每次来比较的就是比较值了,我们可以给他加上
synchronized (userId.toString()) {
// 判断一人一单
int count = query().eq("user_id", userId).eq("voucher_id", voucherId).count();
if (count > 0) {
return Result.fail("用户已经购买过一次");
}
// 5.扣除库存
boolean success = seckillVoucherService.update()
.setSql("stock=stock-1").eq("voucher_id", voucherId).gt("stock", 0).update();
if (!success) {
return Result.fail("库存不足");
}
// 6.创建订单
VoucherOrder voucherOrder = new VoucherOrder();
long orderId = redisIdWorker.nextId("order");
// 添加订单id
voucherOrder.setId(orderId);
// 添加用户id
voucherOrder.setUserId(userId);
// 添加优惠券id
voucherOrder.setVoucherId(voucherId);
this.save(voucherOrder);
return Result.ok(orderId);
}
}
但是上面的代码就解决问题了吗?还没有,因为我们 getResult 上面有@Transactional事务注解,当我们这个操作都完成了,但是这个 getResult这个方法没结束,那数据还是没提交到数据库中,那此时如果再有一个线程进入的话,那还是会出现并发问题,也就是 synchronized 锁小了,要锁这个方法。
// 这个是seckillVoucher方法的后面的部分,我们把synchronized 加在了方法上,而事务是在
// 方法上的,那只要进来这个synchronized的,那数据库的数据一定是提交过的。
Long userId = UserHolder.getUser().getId();
synchronized (userId.toString().intern()) {
return getResult(voucherId);
}
以为到这里就结束了吗?还没有,我们是把 @Transactional加到了 getResult上了,但是没有加到seckillVoucher这个方法上,但是外部是调这个函数的,那 getResult上的@Transactional就会失效,这是事务注解失效的一个最常见场景,这里就要提到 @Transactional的原理和源码了,我这块也学的不好,建议大家看下面这篇文章,这篇文章讲的很好,跟踪源码讲的,能力强的小伙伴也可以自己去试着跟踪源码看一下
https://blog.csdn.net/hollis_chuang/article/details/115713374
(这里还是推荐大家自己跟踪一下源码,我看了2遍没看懂,还得是跟踪源码)
简单来说就是:VoucherOrderServiceImpl这个 bean上只要有一个方法有 @Transaction,那么Spring就会为其创建代理对象(整个事务的开始和结束都由代理对象来调用),但是创建了代理对象也不一定会代理方法。
然后还需要找一个方法上的@Transactional注解信息,没有的话就不执行代理@Transactional对应的代理逻辑,直接执行方法。没有了@Transactional注解代理逻辑,就无法开启事务。
这里说的挺懵的,还是打断点追踪源码吧
那么针对我们这个问题,实际上就是在我们的 bean 刚要加载的时候,spring 会扫描看看哪个类的哪个方法带有 @Transactional注解,在我们这就是 getResult 上面由这个注解,所以 spring 会创建VoucherOrderServiceImpl这个类的代理对象,然后当我们外面调用 seckillVoucher这个方法时,本来是要VoucherOrderServiceImpl的一个对象来调用的,对吧,但是spring已经为我们这个类创建了代理对象了,那么 spring会让这个代理对象来直接调用这个函数吗?根据上面所说,是不会的,spring还要检查一下你调用的这个方法是否有事务注解,如果调用的这个方法上没有事务注解的话,那么spring也是不会让代理对象去执行的。还是让原对象执行,那我们知道,seckillVoucher这个方法里面调用了 getResult这个方法,那么我们也可以知道调用 getResult的就是 this,即也是VoucherOrderServiceImpl这个类的对象。那么为了让他的代理对象来去调用这个方法,我们的代码如下
synchronized (userId.toString().intern()) {
// 获取到当前的代理对象
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
}
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
//暴露代理对象
@EnableAspectJAutoProxy(exposeProxy = true)
兄弟们,这回是真好了
![]()
表也正常,那到这里,一人一单是真的完成了
集群下的并发安全问题
我们这回不先说有什么问题了,我们直接去来两个启动,来模拟一下集群下出现的问题。
- 我们先找到 idea底下的 Services,如果里面什么也没有的话,单价下面图片的那个加号,然后选择这个 Run Configuration Type ,然后选择 springboot。就回看到下面这个图片,但是没有那个第二个
- 然后把鼠标光标放在 HmDianPingApplication:8081,然后 按 ctrl+d,会弹出来一个
- 我们需要做的就是在 VM options中加入 -Dserver.port:8082
- 这就话就是让新开的启动的端口号为 8082,以免发生端口冲突。

刚刚是后端的配置,下面是要设置前端了,我们打开前端文件的 nginx.conf文件,找到下面这段代码,这是修改前的代码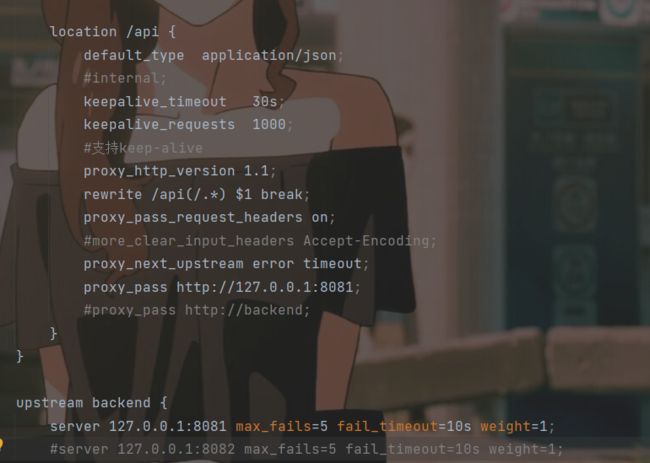
这是修改后的代码,这里相当于是配置反向代理和负载均衡了。当我们访问 8080/api/0这个接口时他就会反向代理到 backend这,然后backend再去实现负载均衡
**然后重启nginx.exe 这是重启命令 **nginx.exe -s reload
之后,我们去调用http://localhost:8080/api/voucher/list/1这个接口,会出来
这个画面,然后反复刷新,再去看后端,会发现8081去查询数据库了,8082也去查询数据库了,没有的再多刷新刷新。
测试好两个启动类后,我们来测试一下在分布式下的并发安全问题。那么我们先检查一下我们的数据库数据先恢复到原来的样子,并且用 postman 等测试工具来测试接口。
我们在这添加两个 post 请求就好,一个秒杀下单,一个秒杀下单2,请求路径都一样,但是后面的秒杀券id,要换成自己的以及请求头也要换成自己的,然后我们在这里打上断点,两个启动都要打上
然后去执行postman
我们会发现,两个都进来了,数据库的数据也变了,这不应该呀,我们不能让一个用户同一时间买到两张呀。那么这就是新发生的安全问题。这个问题是什么呢?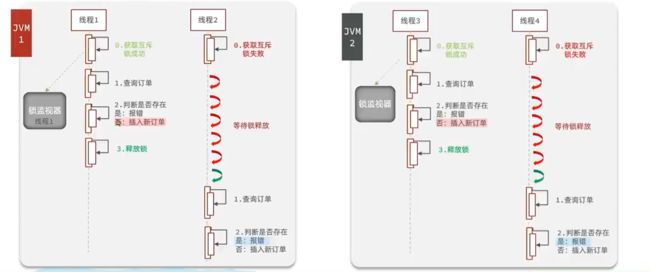
原来呀,这一个启动就是一个新的服务,就相当于我们开了两台服务,那么这两台服务是单独运行,互不影响的,是独立的JVM。那么我们之前加的锁只能针对于一个JVM(锁监视器),所以针对分布式的并发安全问题,我们下次来解决。
总结
本篇内容讲解了优惠券的秒杀业务,通过优惠券的业务与上节的缓存更新策略结合,能提高我们在实现生产中对于数据一致性的认识,但是现在我们都是在单机上讨论,一般能用到缓存的项目大都是分布式项目,而对于分布式的缓存控制,有需要哪些注意的地方?我们下节再聊
最后,我是Mayphyr,从一点点到亿点点,我们下次再见