Zookeeper集群消息同步及leader选举
一、Zookeeper集群成员
1.leader:领导者(一个集群只有一个leader节点)
负责处理写请求、负责发起投票和决议(不负责处理读请求)
2.follower:跟随者
负责处理读请求、进行投票选举。当收到写请求后,会将写请求转给leader,leader收到后会发起投票并决议处理结果。当leader挂了,follower负责投票选举出新的leader
3.observer:观察者(介绍observer很好的文章:https://www.cnblogs.com/hongdada/p/8117677.html)
负责处理读请求,不负责投票及选举。observer存在的目的就是为了协助处理读请求,因为如果集群只有leader和follower,每次节点变化都需要leader发起投票、follower进行投票,这个过程需要耗费一定的时间,有了observer,可以保证集群发生投票时也能保持读取的高吞吐量
注意:
zookeeper集群必须有过半的节点存活才能提供服务(为了保证少数服从多数),那么5台的集群只能挂2台,6台的集群也只能挂2台(挂了3台投票不能过半,无法提供服务),这里说的集群不包括包括observer,所以通常集群的个数为奇数,省台服务器。

二、Zookeeper集群如何实现数据一致性(Zab协议----Paxos算法的变体,核心:过半)
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议(Paxos算法的变体),Zab协议有两种模式:1.恢复模式(选主)2.广播模式(同步)。当集群启动或者leader崩溃(多数follower连接不到leader)后,Zookeeper集群就进入了恢复模式,当leader被选举出来,且大多数的follower和leader完成了数据状态同步,恢复和同步模式就结束了。同步模式还体现在处理写请求时的消息同步
三、Zookeeper处理写请求时消息同步
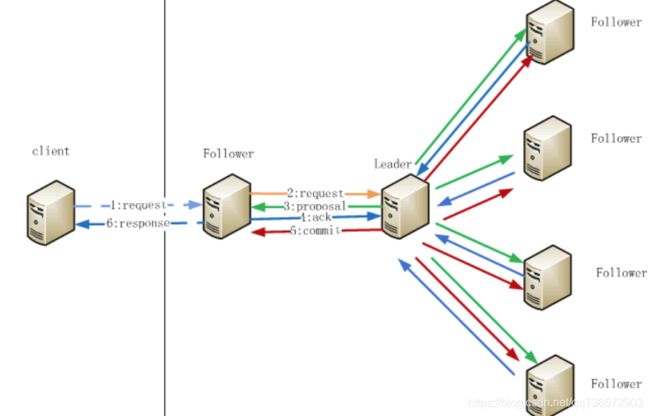
1.follower收到客户端发出的写请求
2.follower觉得自己做不了主,把写请求转给leader
3.leader收到后为了体现民主,给所有follower发出提案(proposal),提案内容为是否执行写操作
4.follwer把自己的意见告诉leader
5.leader收到follower的意见后,统计下票数,少数服从多数,决定是否执行写操作。如果决定执行,leader执行写操作并发出commit告诉所有follower,follower同步更新本地信息,并且发送inform信息给observer,observer同步更新本地信息
6.follower将结果响应给客户端
疑问:
1.同步信息时,leader为什么发送commit信息给follower,发送inform信息给observer
答:
四、Zookeeper的leader选举(默认FastLeaderELection选举算法)
1.先来了解几个概念
①ServerId:服务器ID
比如有三台zk服务器,编号分别为1,2,3,编号越大在选举中占的权重越大
②Zxid:事务ID(自增)
zk服务器中存放的最新的事务ID,Zxid越大说明该服务器存储的数据越新,在选举中占的权重越大
③Logicalclock:逻辑时钟
同一轮投票过程中的Logicalclock是相同的,选举一次,自增一次
④Server状态
- LOOKING,竞选状态
- FOLLOWING,随从状态
- LEADER,领导者状态
- OBSERVER,观察者状态
每次投票的关键信息为(ServerId,Zxid),先比较Zxid,再比较ServerId,取大的

server.ServerId=服务器ip:端口号:监听端口号,该配置在zoo.cfg中(集群需要配置)
2.选举leader第一种情况:Zookeeper集群初始化启动(配置文件已经知道集群有3台zk服务器),3台服务器依次启动(Server1、Server2、Server3)
Server1启动时,无法单独进行和完成leader选举,当Server2启动时,两台服务器可以互相通信,开始进行选举:
①每个Server发出一个投票。由于刚初始化,Server1和Server2都会推荐自己当leader,此时无Zxid值,Server1投票(1,0),Server2投票(2,0),然后将各自的投票发送给集群里的其他机器,此时Server1和Server2的状态均为LOOKING(竞选状态)
②接收来自各个服务器的投票。每台服务器收到投票后,首先判断该投票的有效性,如检查是否本轮投票(Logicalclock、检查票是不是过期了)、是否来自LOOKING状态的服务器。
③处理投票。针对每一次投票,服务器都需要将别人的投票和自己的投票进行比较,规则如下
- 优先检查Zxid。优先投票给Zxid比较大的服务器
- 如果Zxid相同,就比较ServerId,优先投票给ServerId比较大的服务器
对于Server1来说,它的投票是(1,0),接收Server2的投票为(2,0),首先比较Zxid,均为0,再比较ServerId,此时Server2的最大,于是Server1更新自己的投票为(2,0),并将投票信息发送给Server2
④统计投票。每次投票后,服务器都会统计投票信息,判断是否有过半服务器投了相同的票,此时Server2投票过半,于是选出Server2作为leader
⑤改变服务器状态。一旦确定了leader,非observer服务器会更新自己的状态,Server2更新状态为LEADING,Server1更新状态为FOLLOWING
当Server3启动时,发现已经有leader了,不再选举,直接将状态从LOOKING改为FOLLOWING
至此,启动完成
3.选举leader第二种情况:集群运行中,Server1和Server2(leader)挂了,此时需要重新选举leader
举个例子:Zookeeper集群由5台服务器组成,ServerId分别为1、2、3、4、5,Zxid分别为9、9、9、8、8。
Server2为leader,某一时刻,Server1、Server2同时挂了,触发重新选举,流程和上面类似

上面梳理的选举流程是一个大概流程,还有很多细节的东西没写(选举过程的网络通信等),等我理解了再补充
4.选举完成,开始同步消息
①当通过上面流程选出leader以后,leader的数据一定是集群中最新最完整的数据。由于所有Znode的变更都需要通过leader,所以leader会给所有follower和observer创建learnhandle线程用于接收同步数据请求
②当follower和observer收到leader发来的信息,比较Zxid的大小,如果该节点的Zxid小于leader的Zxid,说明该节点的数据有点旧,就把该节点Zxid发给leader,告诉leader自己的数据
③leader收到其他节点发的Zxid后,会把大于Zxid的所有数据同步到该节点,同步完成后,就可以接受客户端的请求了