【ZooKeeper】Curator 简单介绍以及连接zookeeper 重连策略的简单使用
Curator简单介绍
Curator是Netflix公司开源的一套zookeeper客户端框架,解决了很多Zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册Watcher和NodeExistsException异常等等,现在是Apache的开源项目。
Curator封装了很多功能(分布式锁、leader选举、分布式队列、共享计数器等等),更加简单易用。
Curator对比zookeeper原生API
- 原生API的超时重连,需要手动操作,而Curator封装了很多重连策略,自动重连
- 原生API不支持递归创建节点,Curator可以递归创建节点
- 是对原生API的进一步封装,功能更多,更容易使用
- Curator 是Fluent的API风格
Fluent风格API是一种面向对象的 API,其设计广泛依赖于方法链。它的目标是通过创建领域特定语言(DSL),来提高代码的易读性。该术语由Eric Evans和Martin Fowler于 2005 年创造
Curator提供的组件:
(马虎翻译,哈哈哈哈,大家凑合下)
| GroupID/Org | ArtifactID/Name | Description |
|---|---|---|
| org.apache.curator | curator-recipes | 所有的 recipes. 依赖于client 和framework。Maven会自动拉取这些依赖项 |
| org.apache.curator | curator-async | Asynchronous DSL with O/R modeling, migrations 和许多其他特性. |
| org.apache.curator | curator-framework | Curator 的高级API, 建立在 client组件之上 |
| org.apache.curator | curator-client | Curator Client - 替换 ZooKeeper 的原生ZooKeeper类(在原生客户端中使用此类可对zookeeper server进行一系列操作) |
| org.apache.curator | curator-test | 包含TestingServer, TestingCluster 和一些其他的测试工具 |
| org.apache.curator | curator-examples | 各种curator 特性的示例用法。 |
| org.apache.curator | curator-x-discovery | curator上的服务发现的实现。 |
| org.apache.curator | curator-x-discovery-server | 可以与curator discovery一起使用的RESTful服务器。 |
POM文件引入依赖
直接引入curator,好像仓库里面找不到,直接引入这个就可以使用很多东西了
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.0</version>
</dependency>
在我手动从官网下载的apache-curator-5.2.0 包中,他的pom.xml文件有如下代码,但是我部署的zookeeper服务是3.7.0的(最新版),可能curator还没适配好3.7.0的zookeeper,原生的zookeeper API已经到了3.7.0。我这里先使用curator-5.2.0做尝试。
<zookeeper-version>3.6.3</zookeeper-version>
RetryPolicy相关(重试连接)
在zookeeper 原生Java API 中,客户端与服务端的连接是没有提供连接重试机制的。如果客户端需要重连,就只能将上一次连接的Session ID与Session Password发送给服务端进行重连。而Curator框架提供了客户端与服务端的连接重试机制。
重试机制主要定义在RetryPolicy里面。
RetryPolicy接口的关系图如下图所示:
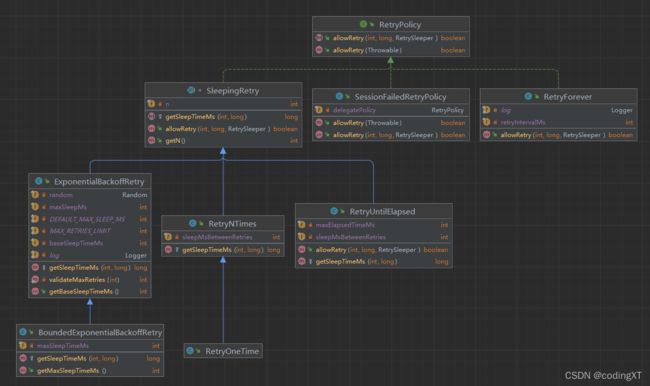
RetryPolicy接口是重试策略的抽象接口,allowRetry方法用来判断是否允许重试。
//重试策略的接口
public interface RetryPolicy
{
/**
* 当操作由于某种原因失败时调用,此方法应返回true以进行另一次尝试
* retryCount – 到目前为止重试的次数(第一次为0)
* elapsedTimeMs – 自尝试操作以来经过的时间(以毫秒为单位)
* sleeper – 使用它来睡眠,不要调用Thread.sleep
*/
boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper);
/**
*
* 当操作因特定异常而失败时调用,此方法应返回true以进行另一次尝试
*/
default boolean allowRetry(Throwable exception)
{
if ( exception instanceof KeeperException)
{
final int rc = ((KeeperException) exception).code().intValue();
return (rc == KeeperException.Code.CONNECTIONLOSS.intValue()) ||
(rc == KeeperException.Code.OPERATIONTIMEOUT.intValue()) ||
(rc == KeeperException.Code.SESSIONMOVED.intValue()) ||
(rc == KeeperException.Code.SESSIONEXPIRED.intValue());
}
return false;
}
}
SleepingRetry抽象类
(实现了RetryPolicy接口,除开RetryForever和SessionFailedRetryPolicy是另外实现的RetryPolicy接口,其他的重试类都是继承的此类)
重试n次(有次数限制),重试之前先进行睡眠,睡眠时间由getSleepTimeMs方法得到(抽象方法)。如果程序运行时出现了InterruptedException,就中断当前线程
package org.apache.curator.retry;
import org.apache.curator.RetryPolicy;
import org.apache.curator.RetrySleeper;
import java.util.concurrent.TimeUnit;
abstract class SleepingRetry implements RetryPolicy
{
private final int n;
protected SleepingRetry(int n)
{
this.n = n;
}
public int getN()
{
return n;
}
public boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper)
{
if ( retryCount < n )
{
try
{
sleeper.sleepFor(getSleepTimeMs(retryCount, elapsedTimeMs), TimeUnit.MILLISECONDS);
}
catch ( InterruptedException e )
{
Thread.currentThread().interrupt();
return false;
}
return true;
}
return false;
}
protected abstract long getSleepTimeMs(int retryCount, long elapsedTimeMs);
}
SessionFailedRetryPolicy类
(实现了RetryPolicy接口,增加了对SessionExpiredException这种异常的判断,如果是这种异常,返回false,不再进行重试连接)
package org.apache.curator;
import org.apache.zookeeper.KeeperException;
/**
* Session过期导致操作失败时的重连策略
*/
public class SessionFailedRetryPolicy implements RetryPolicy
{
private final RetryPolicy delegatePolicy;
public SessionFailedRetryPolicy(RetryPolicy delegatePolicy)
{
this.delegatePolicy = delegatePolicy;
}
@Override
public boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper)
{
return delegatePolicy.allowRetry(retryCount, elapsedTimeMs, sleeper);
}
@Override
public boolean allowRetry(Throwable exception)
{
if ( exception instanceof KeeperException.SessionExpiredException )
{
return false;
}
else
{
return delegatePolicy.allowRetry(exception);
}
}
}
当遇到Session过期异常时,不再进行重连,即返回false。而其他的所有业务全部委托给delegatePolicy实例。RetryPolicy接口的allowRetry(Throwable exception)方法有默认实现,所以除开此类异常,还是会继续进行重试连接的。SessionFailedRetryPolicy类是针对此类异常进行了预先处理:
default boolean allowRetry(Throwable exception)
{
if ( exception instanceof KeeperException)
{
final int rc = ((KeeperException) exception).code().intValue();
return (rc == KeeperException.Code.CONNECTIONLOSS.intValue()) ||
(rc == KeeperException.Code.OPERATIONTIMEOUT.intValue()) ||
(rc == KeeperException.Code.SESSIONMOVED.intValue()) ||
(rc == KeeperException.Code.SESSIONEXPIRED.intValue());
}
return false;
}
RetryForever类
(实现了RetryPolicy接口,重试没有次数限制。)
package org.apache.curator.retry;
import org.apache.curator.RetryPolicy;
import org.apache.curator.RetrySleeper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.concurrent.TimeUnit;
import static com.google.common.base.Preconditions.checkArgument;
/**
* 始终允许重试
*/
public class RetryForever implements RetryPolicy
{
private static final Logger log = LoggerFactory.getLogger(RetryForever.class);
// 重试间隔时间,单位毫秒
private final int retryIntervalMs;
public RetryForever(int retryIntervalMs)
{
checkArgument(retryIntervalMs > 0);
this.retryIntervalMs = retryIntervalMs;
}
@Override
public boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper)
{
try
{
sleeper.sleepFor(retryIntervalMs, TimeUnit.MILLISECONDS);
}
catch (InterruptedException e)
{
Thread.currentThread().interrupt();
log.warn("Error occurred while sleeping", e);
return false;
}
return true;
}
}
上面介绍了三个主要的类:抽象类SleepingRetry,RetryPolicy接口直接实现类SessionFailedRetryPolicy和RetryForever
抽象类SleepingRetry的继承实现子类
然后下面主要是介绍抽象类SleepingRetry的继承实现子类,下图可以看见他们的层次关系
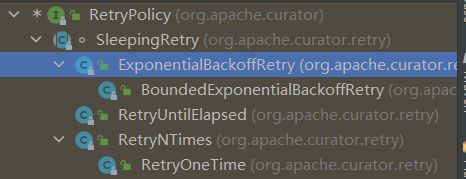
ExponentialBackoffRetry类
(继承了SleepingRetry抽象类)
我们从以下代码可以看出代码的设计就在于扩展(高度可重用的代码(功能)来做父类,然后向下扩展衍生,改写,生成具体场景和功能所使用的子类)
public class ExponentialBackoffRetry extends SleepingRetry
{
private static final Logger log = LoggerFactory.getLogger(ExponentialBackoffRetry.class);
private static final int MAX_RETRIES_LIMIT = 29;
private static final int DEFAULT_MAX_SLEEP_MS = Integer.MAX_VALUE;
private final Random random = new Random();
private final int baseSleepTimeMs;
private final int maxSleepMs;
/**
* baseSleepTimeMs – 重试之间等待的初始时间
* maxRetries – 最大重试次数
*/
public ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries)
{
this(baseSleepTimeMs, maxRetries, DEFAULT_MAX_SLEEP_MS);
}
/**
* baseSleepTimeMs – 重试之间等待的初始时间
* maxRetries – 最大重试次数
* maxSleepMs – 每次重试时休眠的最长时间(以毫秒为单位)
*/
public ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries, int maxSleepMs)
{
super(validateMaxRetries(maxRetries));
this.baseSleepTimeMs = baseSleepTimeMs;
this.maxSleepMs = maxSleepMs;
}
@VisibleForTesting
public int getBaseSleepTimeMs()
{
return baseSleepTimeMs;
}
@Override
protected long getSleepTimeMs(int retryCount, long elapsedTimeMs)
{
long sleepMs = baseSleepTimeMs * Math.max(1, random.nextInt(1 << (retryCount + 1)));
if ( sleepMs > maxSleepMs )
{
log.warn(String.format("Sleep extension too large (%d). Pinning to %d", sleepMs, maxSleepMs));
sleepMs = maxSleepMs;
}
return sleepMs;
}
private static int validateMaxRetries(int maxRetries)
{
if ( maxRetries > MAX_RETRIES_LIMIT )
{
log.warn(String.format("maxRetries too large (%d). Pinning to %d", maxRetries, MAX_RETRIES_LIMIT));
maxRetries = MAX_RETRIES_LIMIT;
}
return maxRetries;
}
}
重试maxRetries次,maxRetries如果大于最大重试次数限制(MAX_RETRIES_LIMIT,程序里面写死了是29),maxRetries就会被MAX_RETRIES_LIMIT覆盖,否则不改变maxRetries的大小。
getSleepTimeMs方法获取的重试之间的睡眠时间并不是不变的,而是通过如下形式,随着重试次数的增加,睡眠时间的随机范围不断扩大(右边界不断扩大),如果随机得到的睡眠时间超过maxSleepMs(如果没有被指定,默认为DEFAULT_MAX_SLEEP_MS, 即 Integer.MAX_VALUE),会被maxSleepMs覆盖。然后我们可以看见这个代码是从Hadoop 的代码文件copy过来的,所以很多东西是需要相互借鉴的。
protected long getSleepTimeMs(int retryCount, long elapsedTimeMs)
{
// copied from Hadoop's RetryPolicies.java
long sleepMs = baseSleepTimeMs * Math.max(1, random.nextInt(1 << (retryCount + 1)));
if ( sleepMs > maxSleepMs )
{
log.warn(String.format("Sleep extension too large (%d). Pinning to %d", sleepMs, maxSleepMs));
sleepMs = maxSleepMs;
}
return sleepMs;
}
BoundedExponentialBackoffRetry(ExponentialBackoffRetry的子类)
我们可以看见,这个类增加了一个字段maxSleepTimeMs(由我们调用的时候传入),然后重写了getSleepTimeMs方法,目的就是要给SleepTimeMs设限制,不能超过我们传入的maxSleepTimeMs值(比如说5000ms,那么SleepTimeMs就不能超过5000ms)
功能也写的不多,这样的代码自己在外面自己的代码里面也可以自己写,但是他却封装了出来(要不就是这个很常用,要不就是有其他考量,我们需要从中学习,思考他为什么要这么设计)
public class BoundedExponentialBackoffRetry extends ExponentialBackoffRetry
{
private final int maxSleepTimeMs;
/**
* baseSleepTimeMs – 重试之间等待的初始时间
* maxSleepTimeMs – 重试之间等待的最长时间
* maxRetries – 重试的最大次数
*/
public BoundedExponentialBackoffRetry(int baseSleepTimeMs, int maxSleepTimeMs, int maxRetries)
{
super(baseSleepTimeMs, maxRetries);
this.maxSleepTimeMs = maxSleepTimeMs;
}
@VisibleForTesting
public int getMaxSleepTimeMs()
{
return maxSleepTimeMs;
}
@Override
protected long getSleepTimeMs(int retryCount, long elapsedTimeMs)
{
return Math.min(maxSleepTimeMs, super.getSleepTimeMs(retryCount, elapsedTimeMs));
}
}
RetryNTimes类:
继承了SleepingRetry抽象类,没有重写allowRetry方法,因此也是重试n次,重写实现了getSleepTimeMs方法,该方法返回重试之间的睡眠时间sleepMsBetweenRetries(sleepMsBetweenRetries也是从外面传入)。
public class RetryNTimes extends SleepingRetry
{
private final int sleepMsBetweenRetries;
public RetryNTimes(int n, int sleepMsBetweenRetries)
{
super(n);
this.sleepMsBetweenRetries = sleepMsBetweenRetries;
}
@Override
protected long getSleepTimeMs(int retryCount, long elapsedTimeMs)
{
return sleepMsBetweenRetries;
}
}
RetryOneTime类(继承了RetryNTimes类):
简单的封装,只重试一次的重试策略(也可以说是特殊的RetryNTimes类,但就是进一步封装了出来(通过构造函数),使得结构更加清晰,而开发人员也很容易根据类的名称知晓他的作用)。
public class RetryOneTime extends RetryNTimes
{
public RetryOneTime(int sleepMsBetweenRetry)
{
super(1, sleepMsBetweenRetry);
}
}
RetryUntilElapsed类
重试,直到给定的时间结束
可以看见,重试的次数为Integer.MAX_VALUE,从外面调用的地方传入maxElapsedTimeMs和sleepMsBetweenRetries,由开发人员自己定义(只要在maxElapsedTimeMs就可以进行重试)
public class RetryUntilElapsed extends SleepingRetry
{
private final int maxElapsedTimeMs;
private final int sleepMsBetweenRetries;
public RetryUntilElapsed(int maxElapsedTimeMs, int sleepMsBetweenRetries)
{
super(Integer.MAX_VALUE);
this.maxElapsedTimeMs = maxElapsedTimeMs;
this.sleepMsBetweenRetries = sleepMsBetweenRetries;
}
@Override
public boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper)
{
return super.allowRetry(retryCount, elapsedTimeMs, sleeper) && (elapsedTimeMs < maxElapsedTimeMs);
}
@Override
protected long getSleepTimeMs(int retryCount, long elapsedTimeMs)
{
return sleepMsBetweenRetries;
}
}
实验代码:
public class CuratorConnect {
//连接zookeeper server
public CuratorFramework client = null;
//日志 我这里暂时懒得用了,直接System.out.println()打印控制台还看得更清楚
static final Logger log = LoggerFactory.getLogger(CuratorConnect.class);
//server列表,以逗号分割,我这里是使用docker-compose 搭建的单机zookeeper集群
static final String ZK_SERVER_CLUSTER = "81.68.82.48:2181,81.68.82.48:2182,81.68.82.48:2183";
//连接的超时时间,单位ms
private static final Integer SESSION_TIMEOUT = 30000;
public boolean connect() {
/**
* 实例化zookeeper 客户端
* 重试之间的睡眠时间随着重试的次数增加而增加
* curator链接zookeeper的策略:ExponentialBackoffRetry
* baseSleepTimeMs:重试之间的初始等待时间
* maxRetries:最大重试次数
* maxSleepMs:最大重试时间
*/
RetryPolicy retryPolicy1 = new ExponentialBackoffRetry(1000, 5,2000);
/**
* curator链接zookeeper的策略:BoundedExponentialBackoffRetry
* baseSleepTimeMs : 重试之间的初始等待时间
* maxSleepTimeMs : 重试之间的最大等待时间
* maxRetries : 重试的最大次数
* 继承于 ExponentialBackoffRetry 类
* 给SleepTimeMs 设限,不能超过传入的 maxSleepTimeMs
*/
RetryPolicy retryPolicy2 = new BoundedExponentialBackoffRetry(1000,3000,3);
/**
* curator链接zookeeper的策略:RetryNTimes
* n:重试的次数
* sleepMsBetweenRetries:每次重试间隔的时间
*/
RetryPolicy retryPolicy3 = new RetryNTimes(3, 5000);
/**
* curator链接zookeeper的策略:RetryOneTime
* 特殊的RetryNTimes,其实内部还是调用的RetryNTimes的构造函数,只是重试次数设置为1
* sleepMsBetweenRetry:每次重试间隔的时间
*/
RetryPolicy retryPolicy4 = new RetryOneTime(3000);
/**
* curator链接zookeeper的策略:RetryUntilElapsed
* maxElapsedTimeMs:最大重试时间
* sleepMsBetweenRetries:每次重试间隔
* 重试时间超过maxElapsedTimeMs后,就不再重试
*/
RetryPolicy retryPolicy5 = new RetryUntilElapsed(2000, 3000);
/**
* curator链接zookeeper的策略:RetryForever
* retryIntervalMs:重试间隔时间
* 永远重试,不推荐使用
*/
RetryPolicy retryPolicy6 = new RetryForever(1000);
/**
* curator链接zookeeper的策略:SessionFailedRetryPolicy
* delegatePolicy: 代理策略实例
* 在注入的其他策略的实例上面,预先判断Session有没有过期,过期了就不允许再进行重试,感觉类似于代理模式
*/
RetryPolicy retryPolicy7 = new SessionFailedRetryPolicy(retryPolicy1);
try{
//fluent 样式的API风格
client = CuratorFrameworkFactory.builder()
.connectString(ZK_SERVER_CLUSTER)
.sessionTimeoutMs(SESSION_TIMEOUT)
.retryPolicy(retryPolicy1)
.namespace("workspaceXT")
.connectionTimeoutMs(SESSION_TIMEOUT)
.build();
client.start();
} catch (Exception e) {
e.printStackTrace();
}
if(client.getState().equals(CuratorFrameworkState.STARTED)){
return true;
}else{
return false;
}
}
/**
* @Description: 关闭zk客户端连接
*/
public boolean closeZKClient() {
try {
this.client.close();
} catch (Exception e) {
e.printStackTrace();
}
if (client.getState().equals(CuratorFrameworkState.STOPPED)) {
return true;
}else{
return false;
}
}
public static void main(String[] args) throws Exception {
CuratorConnect curatorConnect = new CuratorConnect();
//连接
System.out.println("当前客户端的状态:" + (curatorConnect.connect() ? "连接成功" : "连接失败"));
//断开连接
System.out.println("当前客户的状态:" + (curatorConnect.closeZKClient()? "已关闭" : "关闭失败"));
}
}
connectString:ZooKeeper服务端的地址。
sessionTimeoutMs:Session超时时间。
retryPolicy:重试策略。
namespace:命名空间,类似chroot的功能,之后在该客户端上的操作,都是基于该命名空间,起到资源隔离的作用。
connectionTimeoutMs:连接超时时间。
Fluent风格的API的简单探讨:
//fluent 样式的API风格
client = CuratorFrameworkFactory.builder()
.connectString(ZK_SERVER_CLUSTER)
.sessionTimeoutMs(SESSION_TIMEOUT)
.retryPolicy(retryPolicy1)
.namespace("workspaceXT")
.connectionTimeoutMs(SESSION_TIMEOUT)
.build();
client.start();
CuratorFramework是ZooKeeper Client更高的抽象API
CuratorFrameworkFactory类是CuratorFramework的工厂类
CuratorFrameworkFactory类提供了两个方法, 一个工厂方法newClient, 一个构建方法build. 使用工厂方法newClient可以创建一个默认的实例, 而build构建方法可以对实例进行定制. 当CuratorFramework实例构建完成, 紧接着调用start()方法, 在应用结束的时候, 需要调用close()方法. CuratorFramework是线程安全的. 在一个应用中可以共享同一个zk集群的CuratorFramework.
我们这里使用builder来new一个我们定制化的实例
CuratorFrameworkFactory.builder()
builder是一个静态方法,返回一个Builder实例
public class CuratorFrameworkFactory
{
/**
* Return a new builder that builds a CuratorFramework
*
* @return new builder
*/
public static Builder builder()
{
return new Builder();
}
}
Builder是CuratorFrameworkFactory的静态内部类
里面封装了很多属性和方法(我删掉了很多代码,怕太长)
public static class Builder
{
private EnsembleProvider ensembleProvider;
private int sessionTimeoutMs = DEFAULT_SESSION_TIMEOUT_MS;
private int connectionTimeoutMs = DEFAULT_CONNECTION_TIMEOUT_MS;
private int maxCloseWaitMs = DEFAULT_CLOSE_WAIT_MS;
private RetryPolicy retryPolicy;
private ThreadFactory threadFactory = null;
private String namespace;
private List<AuthInfo> authInfos = null;
private byte[] defaultData = LOCAL_ADDRESS;
/**
* Add connection authorization. The supplied authInfos are appended to those added via call to
* {@link #authorization(java.lang.String, byte[])} for backward compatibility.
*
* Subsequent calls to this method overwrite the prior calls.
*
* @param authInfos list of {@link AuthInfo} objects with scheme and auth
* @return this
*/
public Builder authorization(List<AuthInfo> authInfos)
{
this.authInfos = ImmutableList.copyOf(authInfos);
return this;
}
/**
* Set the list of servers to connect to. IMPORTANT: use either this or {@link #ensembleProvider(EnsembleProvider)}
* but not both.
*
* @param connectString list of servers to connect to
* @return this
*/
public Builder connectString(String connectString)
{
ensembleProvider = new FixedEnsembleProvider(connectString);
return this;
}
/**
* As ZooKeeper is a shared space, users of a given cluster should stay within
* a pre-defined namespace. If a namespace is set here, all paths will get pre-pended
* with the namespace
*
* @param namespace the namespace
* @return this
*/
public Builder namespace(String namespace)
{
this.namespace = namespace;
return this;
}
/**
* @param sessionTimeoutMs session timeout
* @return this
*/
public Builder sessionTimeoutMs(int sessionTimeoutMs)
{
this.sessionTimeoutMs = sessionTimeoutMs;
return this;
}
/**
* @param connectionTimeoutMs connection timeout
* @return this
*/
public Builder connectionTimeoutMs(int connectionTimeoutMs)
{
this.connectionTimeoutMs = connectionTimeoutMs;
return this;
}
/**
* @param retryPolicy retry policy to use
* @return this
*/
public Builder retryPolicy(RetryPolicy retryPolicy)
{
this.retryPolicy = retryPolicy;
return this;
}
/**
* @param threadFactory thread factory used to create Executor Services
* @return this
*/
public Builder threadFactory(ThreadFactory threadFactory)
{
this.threadFactory = threadFactory;
return this;
}
/**
* @param compressionProvider the compression provider
* @return this
*/
public Builder compressionProvider(CompressionProvider compressionProvider)
{
this.compressionProvider = compressionProvider;
return this;
}
/**
* @param zookeeperFactory the zookeeper factory to use
* @return this
*/
public Builder zookeeperFactory(ZookeeperFactory zookeeperFactory)
{
this.zookeeperFactory = zookeeperFactory;
return this;
}
/**
* @param aclProvider a provider for ACLs
* @return this
*/
public Builder aclProvider(ACLProvider aclProvider)
{
this.aclProvider = aclProvider;
return this;
}
private Builder()
{
}
}
我们可以看到,Fluent风格的API调用其实,就是通过调用方法来给实例里面的属性进行注入填充,所以可以做到链式调用的Fluent风格
public Builder retryPolicy(RetryPolicy retryPolicy)
{
this.retryPolicy = retryPolicy;
return this;
}
最后调用build方法,返回一个CuratorFrameworkImpl实例
/**
* Apply the current values and build a new CuratorFramework
*
* @return new CuratorFramework
*/
public CuratorFramework build()
{
return new CuratorFrameworkImpl(this);
}
这样就能很清晰的给实例设置我们想要的属性值
References:
- https://kaven.blog.csdn.net/article/details/121548596
- https://www.jianshu.com/p/db65b64f38aa
- https://colobu.com/2014/12/16/zookeeper-recipes-by-example-9/
- https://curator.apache.org/getting-started.html
- https://coding.imooc.com/class/201.html
(写博客主要是对自己学习的归纳整理,资料大部分来源于书籍、网络资料和自己的实践,整理不易,但是难免有不足之处,如有错误,请大家评论区批评指正。同时感谢广大博主和广大作者辛苦整理出来的资源和分享的知识。)