97、Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields
简介
论文地址

使用扩散模型来推断文本相关图像作为内容先验,并使用单目深度估计方法来提供几何先验,并引入了一种渐进的场景绘制和更新策略,保证不同视图之间纹理和几何的一致性
实现流程

简单而言:
文本-图片扩散模型生成一张初始图片 I 0 I_0 I0,将 I 0 I_0 I0扭曲,得到同一z平面的多个图片,也就是 Support set S 0 S_0 S0,注意,这里的 S 0 S_0 S0是由 I 0 I_0 I0扭曲得到,所以存在很多空白,但是我们可以根据 S 0 S_0 S0重建初始的NeRF模型。
利用初始NeRF模型渲染新视角图片,这是残缺的,但是可以通过扩散模型来补全,注意,为了保持场景的一致性,视角从 I 0 I_0 I0旁边小幅度的偏移,让扩散模型尽量多的从 I 0 I_0 I0中获取信息,然后就可以更新NeRF模型了。
由于图像扭曲的影响,必然导致图像尺度差距和距离差距(体现在空间点深度在不同视角存在差异的情况)。为此,采用了深度对齐策略。
Support Set
采用了 DIBR(Depth-image-based rendering (dibr), compression, and transmission for a new approach on 3d-tv) 方法生成 S 0 S_0 S0
具体而言为:
从扩散模型中获得初始图片 I 0 I_0 I0 ,再通过深度预测网络获得深度 D 0 D_0 D0,对于 I − 0 I-0 I−0的每个像素q 和其深度 z,利用下述公式进行转换,得到 S 0 S_0 S0。

K K K 和 P i P_i Pi 是视图 i 中的固有矩阵和相机姿态。
为了在大视野范围内生成3D场景,将相机位置设置在辐射场内部,并使相机向外看,但是该方法不能像其他设置相机查看内部的方法那样生成单独的3D对象。
以当前摄像机位置 P 0 P_0 P0 为中心,对其半径为 r 的环绕圆,生成有相同的 z 坐标,统一采样 n 点作为摄像机位置,并使用与当前视图相同的摄像机方向来生成支持集中的翘曲视图,一般 r=0.2,n=8,偏移方向一般为 上、下、左、右、上左、下左、上右和下右。
这时候就可以开始重建初始三维模型了。
Text-Driven Inpainting
除了初始视图 I 0 I_0 I0 之外的渲染结果不可避免地会有内容缺,这时候就可以使利用基于预训练扩散模型的文本驱动的补图方法了。
首先,渲染一个新视角 P 1 P_1 P1 图像 I k R I^R_k IkR,通过对比 I 0 I_0 I0扭曲到 P 1 P_1 P1后的图像和 I k R I^R_k IkR,我们得到了掩膜 M k M_k Mk。然后就丢给扩散模型,这样就扩展了场景信息。
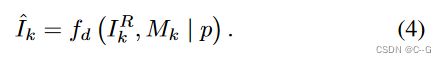
但是呢,扩散模型的生成质量不一定很好,因此采用多次绘制过程,通过CLIP的图像编码器评估,比较补全的图像与初始图像的差距,选出最优的。论文采用30个候选。
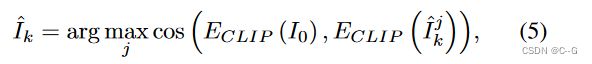
Depth Alignment
补全的图片与初始的图片在重叠部分会存在深度冲突。体现为:
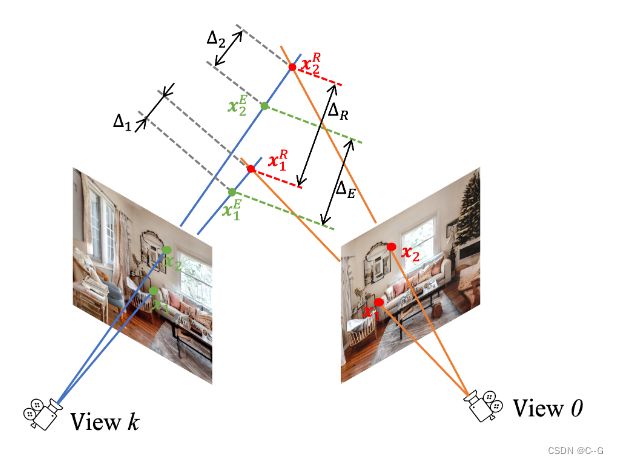
尺度差距: 图像中沙发和墙壁对应的空间点的距离应该是唯一的,但是在不同视图可能存在差异
距离差距: 不同视图拟合的空间点不一致
论文通过补偿平均比例尺和距离差异来全局对齐这两个深度图
对应渲染图像 和补全的图像,表示为 { ( x j R , x j E ) } j = 1 M \{(x^R_j,x^E_j)\}^M_{j=1} {(xjR,xjE)}j=1M,计算平均尺度分数 s 和深度偏移 δ 来近似平均尺度和距离差异

缩放后的点 x ^ j E = s ⋅ x j E \hat{x}^E_j = s \cdot x^E_j x^jE=s⋅xjE ,z(x) 表示预测深度
这里定义全局深度 D k g l o b a l = s ⋅ D k E + δ D^{global}_k = s \cdot D^E_k + \delta Dkglobal=s⋅DkE+δ,最小化渲染深度接近全局深度
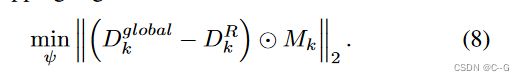
Progressive Inpainting and Updating

为了保证场景绘制过程中视图的一致性,避免几何和外观的模糊性,采用逐视图更新亮度场的渐进式绘制和更新策略
在每次补全后更新亮度场。这意味着之前绘制的内容将在后续的效果图中反映出来,这些部分将被视为已知区域,不会在其他视图中再次绘制
受(Zeroshot text-guided object generation with dream fields)启发,设计了一个深度感知透射损失 L T L_T LT,以促使NeRF网络在相机光线到达预期深度之前产生空密度

m(t)是一个掩膜,当 t< z ^ \hat{z} z^ 时,m(t) = 1,否则为0, z ^ \hat{z} z^是对齐深度图 D ^ \hat{D} D^ 中逐像素深度值,T (T)为累积透过率
效果

