Linux 上 wget 用法详解
最近在网上查资料时,发现一个网站里有好多PDF文档,都想下载下来,手动一个一个点有点麻烦,于是就研究了如何用一条命令下载一个网站里所有PDF文件,这里记录下。
linux下使用wget命令可以完成此需求,递归下载一个网站下面,所有pdf文件命令如下:
wget -A pdf -c -np -L -r https://xxxxxxxxxx简单解释下:
-A 后跟下载的文件类型或者格式,如pdf,txt等,多个样式用逗号分隔。
-c 断点续传,当网络环境不好,或者下载的文件比较多,或者下载的文件比较大时,最好加上这个。
-np 不向上递归到父目录
-L 只递归相对链接,不会到其它站点
-r 递归下载
wget是linux下很强大的一个工具,下面我们详细介绍下wget的使用。
目录
一、日志输出相关
1、日志信息输出到文件
2、不输出日志信息
3、不输出下载详情信息
4、输出debug日志信息
二、下载相关参数设置
1、后台下载
2、从文本文件读取url并下载
4、设置重试次数
4、下载时指定下载下来的文件在本地的文件名
5、下载时跳过已存在的文件
6、断点续传
7、文件有更新时下载
8、下载时显示服务器的回应包信息
9、设置超时时间
10、设置重试前等待时间
11、下载限速
三、设置下载目录
1、不根据url生成层级目录
2、下载文件到根据url路径强制生成的目录下
3、下载文件到指定目录下
四、http相关设置
1、设置http用户名密码
2、禁用服务器cache缓存功能
3、其它扩展功能
五、用户代理相关设置
六、https(tls/ssl)相关设置
七、ftp相关设置
八、递归下载参数
1、递归下载url里的所有链接
2、递归下载层级
3、转换相对路径(链接)文件
4、只下载/忽略下载指定类型文件
5、递归下载时不向上搜索到父目录
一、日志输出相关
1、日志信息输出到文件
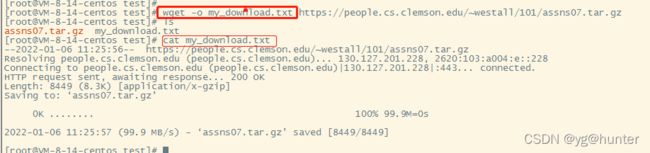
-o, --output-file=FILE log messages to FILE.
-a, --append-output=FILE append messages to FILE.-o my_download.txt 是将日志输出到my_download.txt, 这里是小写字母‘-o’。
-a my_download.txt 是将日志追加到my_download.txt
2、不输出日志信息
-q, --quiet quiet (no output).-q使wget下载处于静默模式。

3、不输出下载详情信息
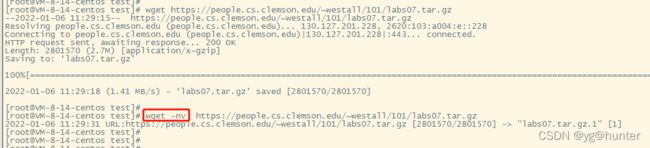
-v, --verbose be verbose (this is the default).
-nv, --no-verbose turn off verboseness, without being quiet.
--report-speed=TYPE Output bandwidth as TYPE. TYPE can be bits.wget默认是打印下载详细日志,可以使用wget -nv关闭该功能。
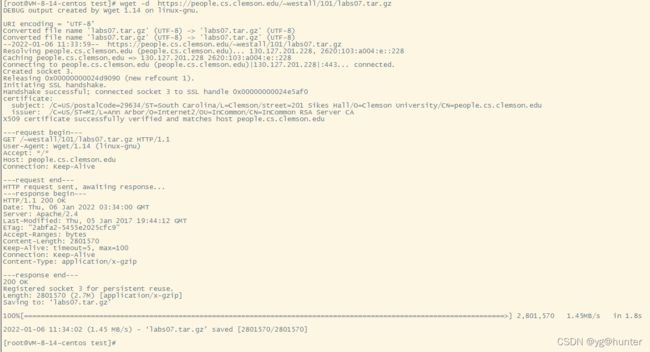
4、输出debug日志信息
wget -d会打印出wget的debug日志,输出的内容比较详细。
二、下载相关参数设置
1、后台下载
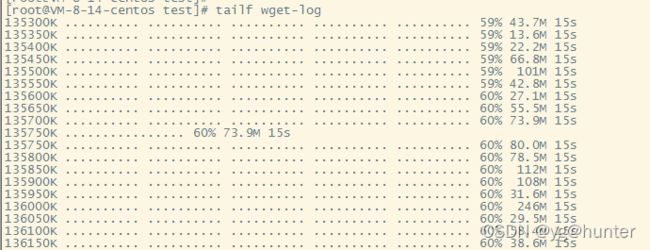
-b, --background go to background after startup.比如下面我下载了个210MB的tar文件:

wget -b url之后,wget会至于后台执行,可以通过wget-log文件查看下载进度:
2、从文本文件读取url并下载
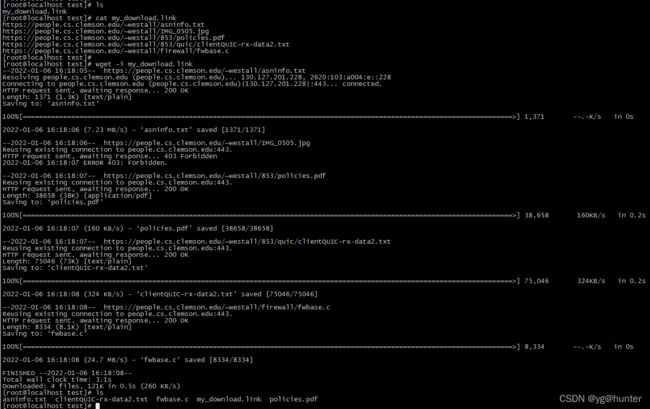
-i, --input-file=FILE download URLs found in local or external FILE.预先将要下载的文件链接写入文本文件中,每个链接一行,然后使用wget -i download.link来批量下载文件:
4、设置重试次数
-t, --tries=NUMBER set number of retries to NUMBER (0 unlimits).
--retry-connrefused retry even if connection is refused.wget -t num可以设置当下载失败时重试的次数,0表示无限次重试,当网络环境不好的时候,可以设置重试次数,特别是下载大文件或者文件在国外网站时。
4、下载时指定下载下来的文件在本地的文件名
-O, --output-document=FILE write documents to FILE.wget -O new_name url 将wget下载下来的文件重命名为新名称。
注:这里的wget参数-O是大写的字母'O'。

5、下载时跳过已存在的文件
-nc, --no-clobber skip downloads that would download to
existing files (overwriting them).
6、断点续传
-c, --continue resume getting a partially-downloaded file.
--progress=TYPE select progress gauge type.在下载大文件时,最好加上-c参数,避免下载的文件不完整。

7、文件有更新时下载
-N, --timestamping don't re-retrieve files unless newer than
local.比较本地该文件时间戳跟服务器上该文件时间戳,只有当服务器该文件时间戳较新时,才下载该文件。
8、下载时显示服务器的回应包信息
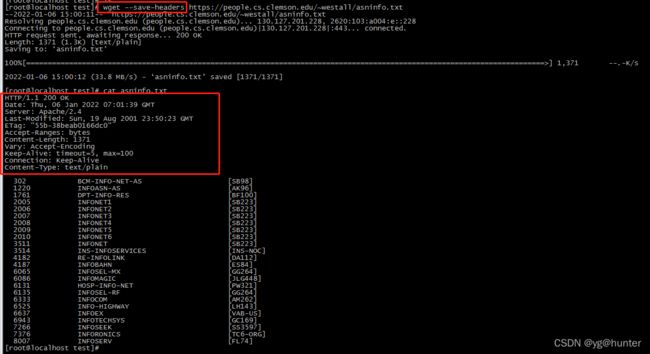
-S, --server-response print server response.
--spider don't download anything.注:这里是大写字母S。
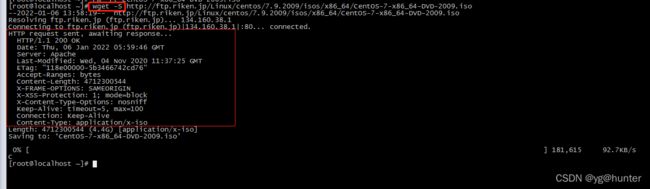
--spider 参数不实际下载文件,探测链接,能正常下载的话,会返回http会回应200:

9、设置超时时间
-T, --timeout=SECONDS set all timeout values to SECONDS.
--dns-timeout=SECS set the DNS lookup timeout to SECS.
--connect-timeout=SECS set the connect timeout to SECS.
--read-timeout=SECS set the read timeout to SECS.-T是设置所有的超时时间;
--dns-timeout=xxx 设置dns域名解析超时时间;
--connect-timeout=xxx 设置连接超时时间;
--read-timeout=xxx 设置读超时时间;
10、设置重试前等待时间
-w, --wait=SECONDS wait SECONDS between retrievals.
--waitretry=SECONDS wait 1..SECONDS between retries of a retrieval.
--random-wait wait from 0.5*WAIT...1.5*WAIT secs between retrievals.
--no-proxy explicitly turn off proxy.11、下载限速
--limit-rate=amount
限制下载速率(b/s,kb/s,mb/s),这里amount必须是十进制整数(不能用小数)
--limit-rate=512
--limit-rate=20k
--limit-rate=2m三、设置下载目录
1、不根据url生成层级目录
-nd, --no-directories don't create directories.递归下载时,不按url路径生成各级目录,将所有文件都放当前目录下,跟下面的-x命令功能刚好相反。
-nH, --no-host-directories don't create host directories.
--protocol-directories use protocol name in directories.
-P, --directory-prefix=PREFIX save files to PREFIX/...
No options -> ftp.xemacs.org/pub/xemacs/
-nH -> pub/xemacs/
-nH --cut-dirs=1 -> xemacs/
-nH --cut-dirs=2 -> .
2、下载文件到根据url路径强制生成的目录下
-x, --force-directories force creation of directories.注:这里x是小写字母。
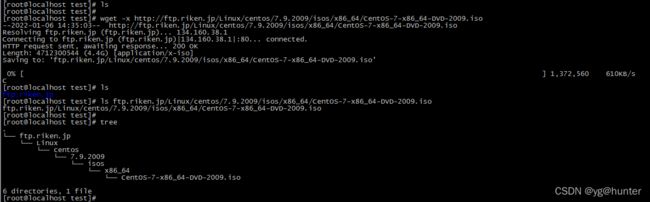
3、下载文件到指定目录下
-P, --directory-prefix=PREFIX save files to PREFIX/...
--cut-dirs=NUMBER ignore NUMBER remote directory components.-P,大写的P,将下载的文件存放在-P参数指定的目录中:

四、http相关设置
1、设置http用户名密码
--http-user=USER set http user to USER.
--http-password=PASS set http password to PASS.2、禁用服务器cache缓存功能
--no-cache disallow server-cached data.wget --no-cache url,下载不从服务器缓存中拿数据
3、其它扩展功能
-E, --adjust-extension save HTML/CSS documents with proper extensions.
--ignore-length ignore `Content-Length' header field.
--header=STRING insert STRING among the headers.
--max-redirect maximum redirections allowed per page.
--proxy-user=USER set USER as proxy username.
--proxy-password=PASS set PASS as proxy password.
--referer=URL include `Referer: URL' header in HTTP request.
--save-headers save the HTTP headers to file.--ignore-length 忽略头部Content-Length域;
--header=STRING 在http头部插入字符串;
--max-redirect 允许网页最大重定向次数;
--proxy-user=USER
--proxy-password=PASS 设置代理用户名及密码;
--referer=URL 在http头部插入Referer域;
--ignore-length 将http头保存到文件中;
五、用户代理相关设置
-U, --user-agent=AGENT identify as AGENT instead of Wget/VERSION.
--no-http-keep-alive disable HTTP keep-alive (persistent connections).
--no-cookies don't use cookies.
--load-cookies=FILE load cookies from FILE before session.
--save-cookies=FILE save cookies to FILE after session.
--keep-session-cookies load and save session (non-permanent) cookies.
--post-data=STRING use the POST method; send STRING as the data.
--post-file=FILE use the POST method; send contents of FILE.
--content-disposition honor the Content-Disposition header when
choosing local file names (EXPERIMENTAL).
--content-on-error output the received content on server errors.
--auth-no-challenge send Basic HTTP authentication information
without first waiting for the server's
challenge.六、https(tls/ssl)相关设置
HTTPS (SSL/TLS) options:
--secure-protocol=PR choose secure protocol, one of auto, SSLv2,
SSLv3, TLSv1, TLSv1_1 and TLSv1_2.
--no-check-certificate don't validate the server's certificate.
--certificate=FILE client certificate file.
--certificate-type=TYPE client certificate type, PEM or DER.
--private-key=FILE private key file.
--private-key-type=TYPE private key type, PEM or DER.
--ca-certificate=FILE file with the bundle of CA's.
--ca-directory=DIR directory where hash list of CA's is stored.
--random-file=FILE file with random data for seeding the SSL PRNG.
--egd-file=FILE file naming the EGD socket with random data.七、ftp相关设置
FTP options:
--ftp-user=USER set ftp user to USER.
--ftp-password=PASS set ftp password to PASS.
--no-remove-listing don't remove `.listing' files.
--no-glob turn off FTP file name globbing.
--no-passive-ftp disable the "passive" transfer mode.
--preserve-permissions preserve remote file permissions.
--retr-symlinks when recursing, get linked-to files (not dir).八、递归下载参数
1、递归下载url里的所有链接
-r, --recursive specify recursive download.递归下载该网址里的所有链接
2、递归下载层级
-l, --level=NUMBER maximum recursion depth (inf or 0 for infinite).
--delete-after delete files locally after downloading them.-l num 设置最大递归到第几层目录
3、转换相对路径(链接)文件
-k, --convert-links make links in downloaded HTML or CSS point to
local files.-k 小写k,将HTML或者CSS中的连接文件指向本地文件
-p, --page-requisites get all images, etc. needed to display HTML page.
--strict-comments turn on strict (SGML) handling of HTML comments.下载所有图片等,可用于显示html网页,在下载网页用于脱机浏览时,一定要加这俩参数。
4、只下载/忽略下载指定类型文件
-A, --accept=LIST comma-separated list of accepted extensions.
-R, --reject=LIST comma-separated list of rejected extensions.
--accept-regex=REGEX regex matching accepted URLs.
--reject-regex=REGEX regex matching rejected URLs.
--regex-type=TYPE regex type (posix|pcre).wget -A 后跟要下载的文件,比如要下载某个url下所有pdf、txt、jpg、zip、doc、mp4等格式文件,可以这样:
wget -A pdf,jpg,zip,doc,mp4,avi,rar,ppt,xls,tar.gz,*.txt download_urlwget -R 跟-A功能刚好相反,比如不下载html、php、asp、js、css等格式的文件:
wget -R html,htm,php,asp,jsp,js,py,css url5、递归下载时不向上搜索到父目录
-np, --no-parent don't ascend to the parent directory.参考:wget手册