HTTP协议发展史
简介
Hyper Text Transfer Protocol(超文本传输协议),是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。是互联网上应用最为广泛的一种网络协议。所有的 WWW 文件都必须遵守这个标准。
超文本传输 协议(HTTP)是用于传输诸如 HTML 的超媒体文档的应用层协议。它被设计用于 Web 浏览器和 Web 服务器之间的通信,但它也可以用于其他目的。 HTTP 是一个基于 TCP/IP 通信协议来传递数据(HTML 文件, 图片文件, 查询结果等)。也要通过三次握手,四次挥手。
HTTP 是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于 1990 年提出,经过几年的使用与发展,得到不断地完善和扩展。
HTTP 协议工作于客户端-服务端架构为上。浏览器作为 HTTP 客户端通过 URL 向 HTTP 服务端即 WEB 服务器发送所有请求。Web 服务器根据接收到的请求后,向客户端发送响应信息。
HTTP 协议版本
大致版本可以分为以下四个:
- HTTP/0.9(初始诞生)
- HTTP/1.0
- HTTP/1.1
- HTTP/2
- HTTP/3
发展的历史如下:

HTTP/0.9
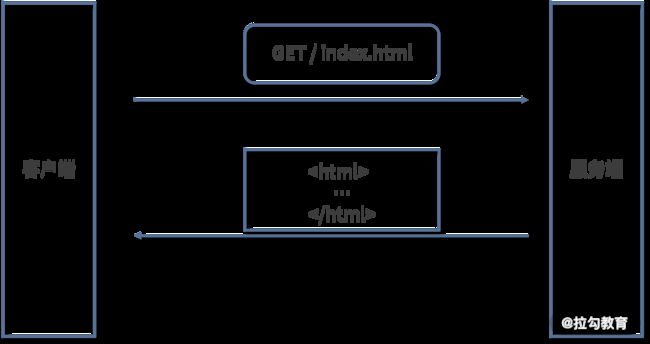
HTTP 是基于 TCP/IP 协议的应用层协议。它不涉及数据包(packet)传输,主要规定了客户端和服务器之间的通信格式,默认使用 80 端口。 最早版本是 1991 年发布的 0.9 版。该版本极其简单,只有一个命令 GET。
GET /index.html
注意:HTTP 当前运行在 TCP 上,但也可以运行在任何面向连接的服务上。
上面命令表示,TCP 连接(connection)建立后,客户端向服务器请求(request)网页 index.html。
协议规定,服务端收到请求后返回一个以 ASCII 字符流编码的 HTML 文档,不能回应别的格式。
Hello World
服务器发送完毕,就关闭 TCP 连接。
HTTP/0.9 虽然简单,但是它充分验证了 Web 服务的可行性:
把简单的系统变复杂,要比把复杂的系统变简单容易得多。
HTTP/1.0 出现
随着互联网的发展以及浏览器的出现,单纯的文本内容已经无法满足用户需求了,浏览器希望通过 HTTP 来传输脚本、样式、图片、音频和视频等不同类型的文件,所以在 1996 年 HTTP 更新的 1.0 版本中引入了如下特性:
- 增加了 HEAD、POST 等新方法
- 增加了响应状态码,如果处理失败,则可以用它了解发生了哪种错误;
- 引入了协议版本号概念
- 引入了 HTTP Header(头部)的概念,让 HTTP 处理请求和响应更加灵活
- 传输的数据不再局限于文本
相对于 HTTP/0.9 大致增加了如下几点:
- 首先,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础。
- 其次,除了 GET 命令,还引入了 POST 命令和 HEAD 命令,丰富了浏览器与服务器的互动手段。
- 再次,HTTP 请求和回应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
- 其他的新增功能还包括状态码**(status code)、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)**等。
其中最核心的改变是增加了头部设定,头部内容以键值对的形式设置。请求头部通过 Accept 字段来告诉服务端可以接收的文件类型,响应头部再通过 Content-Type 字段来告诉浏览器返回文件的类型。
头部字段不仅用于解决不同类型文件传输的问题,也可以实现其他很多功能如缓存、认证信息等,这些更新内使得它逐渐发展成一种可扩展且灵活的通用协议
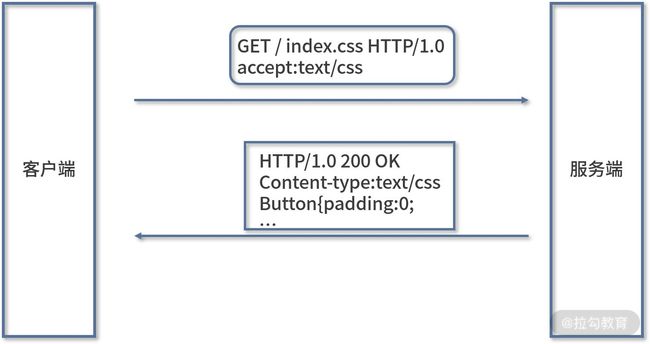
Http0.9当时存在一些别的问题如下:
- HTTP/1.0 版的主要缺点是,每个 TCP 连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
- TCP 连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(slow start)。
TCP 连接需要三个请求才能建立连接,四个请求可以完全关闭
人们创建了一个“连接”标头来解决这个问题。客户端发送带有“connection:keep-alive”标头的请求,以表明意图为后续请求保持 TCP 连接的打开状态。如果服务器理解此标头并同意遵守该标头,则其响应还将包含“connection:keep-alive”标头。
这样,双方都保持 TCP 通道打开并使用它进行后续通信,直到任何一方决定关闭它为止。随着 SSL/TLS 加密技术的发展,这一点变得更加重要,因为协商加密算法和交换加密密钥需要在每个连接上增加一个请求/响应周期。
单个 TCP 连接可以通过“connection:keep-alive”标头重用于多个请求
当时,许多 HTTP 改进都是自发出现的。当流行的浏览器或服务器应用程序需要新的 HTTP 功能时,它们会自己实现该功能,并希望其他各方也能效仿。具有讽刺意味的是,去中心化的 Web 需要一个中心化的管理机构来避免碎片化造成的不兼容问题。
该协议的最初创建者蒂姆·伯纳斯·李(TimBerners-Lee)意识到了这种危险,并于 1994 年成立了万维网联盟(W3C),该联盟与互联网工程任务组(IETF)一起致力于规范互联网的技术栈。作为为已有环境带来更多规范的第一步,他们记录了当时 HTTP 中最常用的一些功能,并将其命名为 HTTP/1.0 协议。
但是,由于这种“规范”描述的是多种多样的,通常在“实践”中用法不一致的技术,因此它从未获得过标准地位。相比之下,关于 HTTP 协议新版本的工作已经开始了。
HTTP/1.1
随着互联网的迅速发展,HTTP/1.0 也已经无法满足需求,最核心的就是连接问题。
具体来说就是 HTTP/1.0 每进行一次通信,都需要经历建立连接、传输数据和断开连接三个阶段。当一个页面引用了较多的外部文件时,这个建立连接和断开连接的过程就会增加大量网络开销。
1997 年 1 月,HTTP/1.1 版本发布,只比 1.0 版本晚了半年。它进一步完善了 HTTP 协议,一直用到了 20 年后的今天,直到现在还是最流行的版本。
为了解决 HTTP/1.0 的问题,1999 年推出的 HTTP/1.1 有以下特点:
HTTP/1.1的新特性
- 支持长连接(Connection:keep-alive):引入了 TCP 连接复用,即一个 TCP 默认不关闭,可以被多个请求复用
- 并发连接:对一个域名的请求允许分配多个长连接(缓解了长连接中的「队头阻塞」问题)
- 引入管道机制,一个 TCP 连接,可以同时发送多个请求。(响应的顺序必须和请求的顺序一致,因此不常用)
- 增加了 PUT、DELETE、OPTIONS、PATCH 等新的方法
- 新增缓存字段(cache-control E-tag),用于缓存管理和控制
- 请求头中引入了 range 字段,支持断点续传
- 允许响应数据分块(chunked),利于传输大文件
- 强制要求 Host 头,让互联网主机托管称为可能
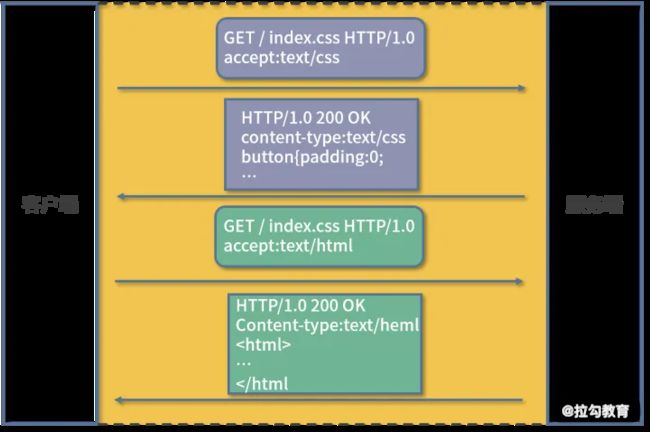
相对于 HTTP/1.0 版本 做了一些优化大致如下:
-
长连接: HTTP 1.1 支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个 TCP 连接上可以传送多个 HTTP 请求和响应,减少了建立和关闭连接的消耗和延迟,在 HTTP1.1 中默认开启 Connection: keep-alive,一定程度上弥补了 HTTP1.0 每次请求都要创建连接的缺点。
-
**缓存处理:**在 HTTP1.0 中主要使用 header 里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1 则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
-
带宽优化及网络连接的使用,HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了range 头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
错误通知的管理,在 HTTP1.1 中新增了24 个错误状态响应码,如 409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
-
Host 头处理,在 HTTP1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此,请求消息中的 URL 并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个 IP 地址。HTTP1.1 的请求消息和响应消息都应支持 Host 头域,且请求消息中如果没有 Host 头域会报告一个错误(400 Bad Request)。
HTTP/1.1 修复了 HTTP/1.0 的不一致之处,并调整了协议,使其在新的 Web 生态系统中具备更好的性能表现。新版引入的两个最关键的更改是默认使用持久 TCP 连接(保持活动状态)和 HTTP 管线化。
HTTP 管线化的意思就是客户端无需在发送后续 HTTP 请求之前等待服务器响应请求。此功能可以更有效地利用带宽并减少延迟,但它的改进空间甚至更大。HTTP 管线化仍要求服务器按照接收到的请求顺序进行响应,因此,如果管线化中的单个请求执行得很慢,则对客户端的所有后续响应都将相应地延迟下去。这个问题被称为线头阻塞。
HTTP/1.1 与 HTTP/1.0 的一个重要区别是:
HTTP/1.1 是一个“正式的标准”
此后互联网上所有的浏览器、服务器、网关、代理等,只要用到 HTTP 协议,就必须严格遵守这个标准。
HTTP1.1的问题
存在一些问题如下:
- 虽然 1.1 版允许复用 TCP 连接,但是同一个 TCP 连接里面,所有的数据通信是按次序进行的。一个连接中同一时刻只能处理一个请求,如果前面的回应特别慢,后面就会有许多请求排队等着。这称为"队头堵塞"(Head-of-line blocking)。
- 浏览器为了减轻服务器的压力,限制了同一个域名下的 HTTP 连接数,即 6 ~ 8 个
- HTTP1.x 在传输数据时,所有传输的内容都是明文,客户端和服1务器端都无法验证对方的身份,这在一定程度上无法保证数据的安全性。
- HTTP1.x 在使用时,header 里携带的内容过大,在一定程度上增加了传输的成本,并且每次请求 header 基本不怎么变化,尤其在移动端增加用户流量。
- 虽然 HTTP1.x 支持了 keep-alive,来弥补多次创建连接产生的延迟,但是 keep-alive 使用多了同样会给服务端带来大量的性能压力,并且对于单个文件被不断请求的服务(例如图片存放网站),keep-alive 可能会极大的影响性能,因为它在文件被请求之后还保持了不必要的连接很长时间。
SPDY 和 HTTP/2
SPDY 协议
2009 年,谷歌公开了自行研发的 SPDY 协议,主要解决 HTTP/1.1 效率不高的问题。 这个协议在 Chrome 浏览器上证明可行以后,就被当作 HTTP/2 的基础,主要特性都在 HTTP/2 之中得到继承。SPDY 可以说是综合了 HTTPS 和 HTTP 两者有点于一体的传输协议,主要解决:
- 降低延迟,针对 HTTP 高延迟的问题,SPDY 优雅的采取了多路复用(multiplexing)。多路复用通过多个请求 stream 共享一个 tcp 连接的方式,解决了 HOL blocking 的问题,降低了延迟同时提高了带宽的利用率。
- 请求优先级(request prioritization)。多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY 允许给每个 request 设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的 html 内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
- header 压缩。前面提到 HTTP1.x 的 header 很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。
- 基于 HTTPS 的加密协议传输,大大提高了传输数据的可靠性。
- 服务端推送(server push),采用了 SPDY 的网页,例如我的网页有一个 sytle.css 的请求,在客户端收到 sytle.css 数据的同时,服务端会将 sytle.js 的文件推送给客户端,当客户端再次尝试获取 sytle.js 时就可以直接从缓存中获取到,不用再发请求了。
SPDY 构成图:

谷歌在 2008 年发布了 Chrome 浏览器,这种浏览器因其快速和创新而迅速流行。它使谷歌在互联网技术问题上获得了强大的话语权。在 2010 年代初期,谷歌在 Chrome 中增加了对其 Web 协议 SPDY 的支持。
HTTP2
HTTP/2 标准基于 SPDY,并进行了一些改进。HTTP/2 通过在单个打开的 TCP 连接上多路复用 HTTP 请求,解决了线头阻塞问题。这允许服务器以任何顺序响应请求,然后客户端可以在接收到响应时重新组合响应,从而在单个连接中加快整个交换的速度。
HTTP/2 可以说是 SPDY 的升级版(其实原本也是基于 SPDY 设计的),但是,HTTP2.0 跟 SPDY 仍有不同的地方,主要是以下两点:
- HTTP2.0 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS
- HTTP2.0 消息头的压缩算法采用 HPACK,而非 SPDY 采用的 DEFLATE
HTTP/2 的新特性:
- 二进制分帧协议:HTTP/2 的所有帧都采用二进制编码,数据通过二进制协议传输,不再是纯文本
- 多路复用 (Multiplexing):可发起多个请求,废弃了 1.1 里的管道
- 请求优先级通过设置数据帧的优先级,让服务器优先处理某些请求
- header 压缩:使用专用算法压缩头部,减少数据传输量
- 服务端推送:允许服务器主动向客户端推送数据
- 头部字段全部改为小写;引入了伪头部的概念,出现在头部字段之前,以冒号开头
- 增强了安全性,“事实上”要求加密通信
二进制分帧:HTTP/2 的所有帧都采用二进制编码
先理解几个概念:
- 帧:客户端与服务器通过交换帧来通信,帧是基于这个新协议通信的最小单位。
- 消息:是指逻辑上的 HTTP 消息,比如请求、响应等,由一或多个帧组成。
- 流:流是连接中的一个虚拟信道,可以承载双向的消息;每个流都有一个唯一的整数标识符(1、2…N);
HTTP/2 采用二进制格式传输数据,而非 HTTP 1.x 的文本格式,二进制协议解析起来更高效。 HTTP / 1 的请求和响应报文,都是由起始行,首部和实体正文(可选)组成,各部分之间以文本换行符分隔。HTTP/2 将请求和响应数据分割为更小的帧,并且它们采用二进制编码。

帧、流、消息的关系
每个数据流都以消息的形式发送,而消息又由一个或多个帧组成。 帧是流中的数据单位。一个数据报的 header 帧可以分成多个 header 帧,data 帧可以分成多个 data 帧。
多路复用 (Multiplexing)
多路复用允许同时通过单一的 HTTP/2 连接发起多重的请求-响应消息。即连接共享,即每一个 request 都是是用作连接共享机制的。一个 request 对应一个 id,这样一个连接上可以有多个 request,每个连接的 request 可以随机的混杂在一起,接收方可以根据 request 的 id 将 request 再归属到各自不同的服务端请求里面。 多路复用原理图:

请求优先级
- 把 HTTP 消息分解为很多独立的帧之后,就可以通过优化这些帧的交错和传输顺序,每个流都可以带有一个 31 比特的优先值:0 表示最高优先级;2 的 31 次方-1 表示最低优先级。
- 服务器可以根据流的优先级,控制资源分配(CPU、内存、带宽),而在响应数据准备好之后,优先将最高优先级的帧发送给客户端。
- HTTP 2.0 一举解决了所有这些低效的问题:浏览器可以在发现资源时立即分派请求,指定每个流的优先级,让服务器决定最优的响应次序。这样请求就不必排队了,既节省了时间,也最大限度地利用了每个连接。
header 压缩
HTTP1.x 的 header 带有大量信息,而且每次都要重复发送,HTTP/2 使用 encoder 来减少需要传输的 header 大小,通讯双方各自cache 一份 header fields 表,既避免了重复 header 的传输,又减小了需要传输的大小。 为了减少这块的资源消耗并提升性能, HTTP/2 对这些首部采取了压缩策略:
- HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,不再重复发送 header
- 首部表在 HTTP/2 的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
- 每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值
两次请求不相同的 header,传说的 header 如下图所示:

服务端推送
Server Push 即服务端能通过 push 的方式将客户端需要的内容预先推送过去,也叫“cache push”。 服务器可以对一个客户端请求发送多个响应。服务器向客户端推送资源无需客户端明确地请求,服务端可以提前给客户端推送必要的资源,这样可以减少请求延迟时间,例如服务端可以主动把 JS 和 CSS 文件推送给客户端,而不是等到 HTML 解析到资源时发送请求,大致过程如下图所示:

注意: 所有推送的资源都遵守同源策略。 服务器必须遵循请求- 响应的循环,只能借着对请求的响应推送资源。

HTTP/2.0 虽然已经发布了 6 年,不过由于 HTTP/1.1 实在太过经典和强势,目前 HTTP/2.0 的普及率还比较低,仍然有很多网站使用的是 HTTP/1.1 版本。
实际上,使用 HTTP/2 服务器甚至可以在请求之前就将资源提供给客户端!举个例子,如果服务器知道客户端很可能需要样式表来显示 HTML 页面,它可以将 CSS“推”到客户端,而无需等待相应的请求。虽然这从理论上讲是有益的,但此功能在实践中很少见,因为它需要服务器了解其服务的 HTML 结构,但这种情况很少发生。
除了请求正文以外,HTTP/2 还允许压缩请求标头,这进一步减少了通过网络传输的数据量。
HTTP/2 解决了 Web 上的许多问题,但不是全部。在 TCP 协议级别上仍然存在类似类型的线头问题,而 TCP 仍然是 Web 的基础构建块。当 TCP 数据包在传输过程中丢失时,在服务器重新发送丢失的数据包之前,接收方无法确认传入的数据包。由于 TCP 在设计上不遵循 HTTP 之类的高级协议,因此单个丢失的数据包将阻塞所有进行中的 HTTP 请求的流,直到重新发送丢失的数据为止。这个问题在不可靠的连接上尤为突出,这在无处不在的移动设备时代并不罕见。
HTTP/3 革命
在 HTTP/2 还处于草案之时,Google 又发明了一个新的协议,叫做 QUIC,继续在 Chrome 和自家服务器里应用,依托它的庞大用户量和数据量,持续地推动 QUIC 协议成为互联网上的标准。
在 2018 年,互联网标准化组织 IETF 提议将“HTTP over QUIC”更名 为“HTTP/3”并获得批准,HTTP/3 正式进入了标准化制订阶段,也许两三年后就会正式发布,到时候我们很可能会跳过 HTTP/2 直接进入 HTTP/3。
由于 HTTP/2 的问题不能仅靠应用程序层来解决,因此协议的新迭代必须更新传输层。但是,创建新的传输层协议并非易事。传输协议需要硬件供应商的支持,并且需要大多数网络运营商的部署才能普及。由于此事涉及的成本和工作量,运营商们不愿进行更新。以 IPv6 为例:它是 24 年前推出的,但如今距离获得普遍支持还有很远的距离。
幸运的是还有另一种选择。UDP 协议与 TCP 一样得到广泛支持,但前者足够简单,可以作为在其之上运行的自定义协议的基础。UDP 数据包是一劳永逸的:没有握手、持久连接或错误校正。HTTP3 背后的主要思想是放弃 TCP,转而使用基于 UDP 的 QUIC 协议。QUIC 以对 Web 环境有意义的方式添加了许多必要的功能(包括以前由 TCP 提供的功能,以及更多功能)。
与 HTTP2 在技术上允许未加密的通信不同,QUIC 严格要求加密后才能建立连接。此外,加密不仅适用于 HTTP 负载,还适用于流经连接的所有数据,从而避免了一大堆安全问题。建立持久连接、协商加密协议,甚至发送第一批数据都被合并到 QUIC 中的单个请求/响应周期中,从而大大减少了连接等待时间。如果客户端具有本地缓存的密码参数,则可以通过简化的握手(0-RTT)重新建立与已知主机的连接。
为了解决传输级别的线头阻塞问题,通过 QUIC 连接传输的数据被分为一些流。流是持久性 QUIC 连接中短暂、独立的“子连接”。每个流都处理自己的错误纠正和传递保证,但使用连接全局压缩和加密属性。每个客户端发起的 HTTP 请求都在单独的流上运行,因此丢失数据包不会影响其他流/请求的数据传输。

UDP 是一种无状态协议(持久连接只是其之上的抽象),使 QUIC 能够支持一些很大程度上忽略了数据包传递复杂性的功能。例如,从理论上讲,客户端更改其 IP 地址中间连接(例如智能手机从移动网络跳转到家庭 wifi)时不应中断连接,因为该协议允许在不同 IP 地址之间迁移而无需重新连接。
QUIC 协议的所有现有实现当前都在用户空间,而不是 OS 内核中运行。由于客户端(例如浏览器)和服务器的更新通常比操作系统内核更新的频率更高,因此人们希望可以藉此更快地采用新功能。
HTTP/3 存在的问题
TCP 协议已经存在了很长时间,对于路由器来说很容易理解。它具有清晰的未加密标记(用于建立和关闭连接),可用于跟踪和控制现有会话。在网络硬件学会了解新协议之前,它将把 QUIC 流量简单地看作独立的 UDP 数据包流,这将使网络配置更加棘手。
从客户端缓存“恢复”连接的能力使该协议很容易遭受重播攻击:在某些情况下,恶意攻击者可以重新发送以前捕获的数据包,这些数据包将被服务器解释为有效的,来自受害者的。像那些提供静态内容的 Web 服务器一样,许多 Web 服务器不会受到此类攻击的伤害。对于身处易受攻击环境的应用程序来说,必须要记住禁用 0-RTT 功能。
这就是 HTTP 到今天为止的故事。我认为 HTTP/3 是向前迈出的一大步,并且当然希望 HTTP/3 在不久的将来会被广泛采用。
原文链接:The Long Road to HTTP/3 · Scorpil
总结
- HTTP 协议始于三十年前蒂姆·伯纳斯 - 李的一篇论文
- HTTP/0.9 是个简单的文本协议,只能获取文本资源
- HTTP/1.0 确立了大部分现在使用的技术,但它不是正式标准
- HTTP/1.1 是目前互联网上使用广泛的协议,功能也非常完善
- HTTP/2 基于 Google 的 SPDY 协议,注重性能改善,但还未普及
- HTTP/3 基于 Google 的 QUIC 协议,是将来的发展方向
| 协议版本 | 解决的核心问题 | 解决方式 |
|---|---|---|
| 0.9 | HTML 文件传输 | 确立了客户端请求、服务端响应的通信流程 |
| 1.0 | 不同类型文件传输 | 设立头部字段 |
| 1.1 | 创建/断开 TCP 连接开销大 | 建立长连接进行复用 |
| 2 | 并发数有限 | 二进制分帧 |
| 3 | TCP 丢包阻塞 | 采用 UDP 协议 |
主要特点:
- HTTP 1.0: GET + 请求的文件路径,服务端收到请求后返回一个以 ASCII 字符流编码的 HTML 文档。
- HTTP 1.0:支持最基本的 GET、POST 方法、引入 header、传输的数据不局限于纯文本
- HTTP 1.1:增减缓存策略、支持长连接、支持断点续传,状态码 206、支持新的方法 PUT,DELETE 等,可用于 Restful API
- HTTP 2.0:数据通过二进制协议传输、支持压缩 header,减少体积、多路复用,一次 TCP 连接中可以多个 HTTP 并行请求、服务端推送
- HTTP 3 :基于 Google 的 QUIC 协议,是将来的发展方向
参考文章:
Http系列(-) Http发展历史 - 掘金
从HTTP到HTTP/3的发展简史_文化 & 方法_Scorpil_InfoQ精选文章
HTTP 发展史 - 知乎