UNET-RKNN分割眼底血管
前言
最近找到一个比较好玩的Unet分割项目,Unet的出现就是为了在医学上进行分割(比如细胞或者血管),这里进行眼底血管的分割,用的backbone是VGG16,结构如下如所示(项目里面的图片,借用的!借用标记出处,尊重别人的知识产权),模型比较小,但是效果感觉还不错的。
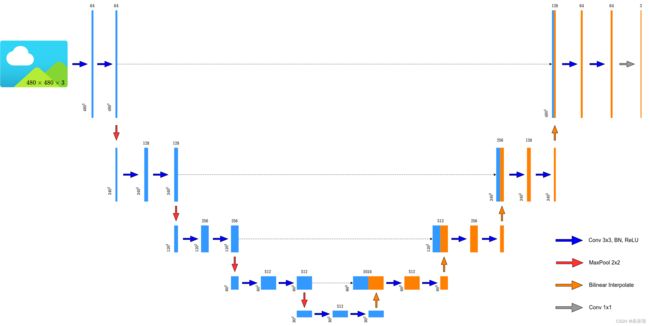
相关的算法发介绍就不写了接下来从PYTORCH、ONNX、rknn三个方面看看效果
全部代码地址: https://pan.baidu.com/s/1QkOz5tvRSF-UkJhmpI__lA 提取码: 8twv
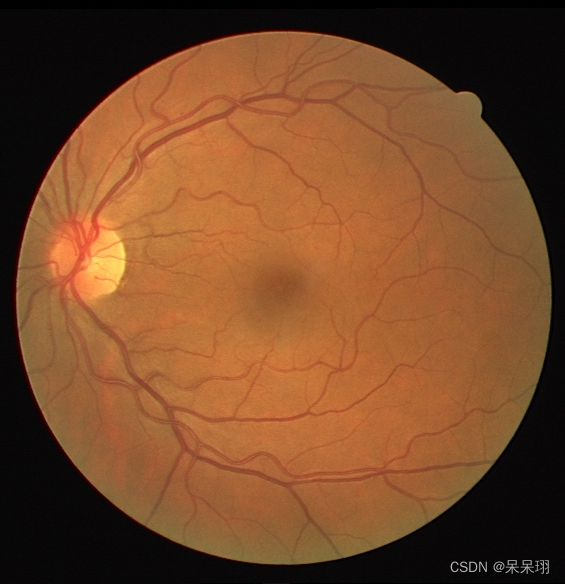
检测原图
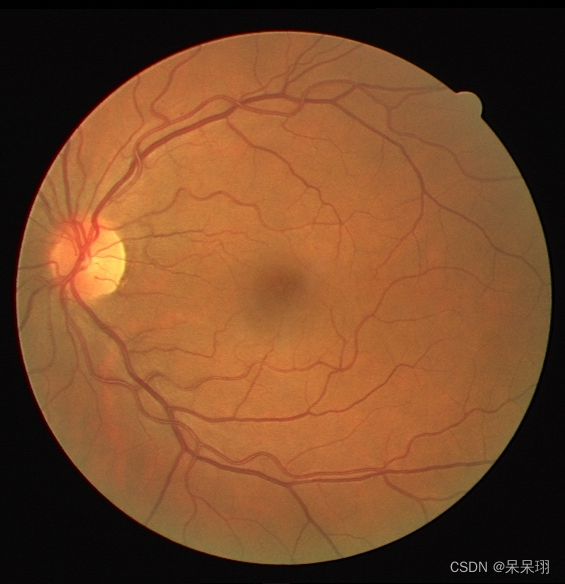
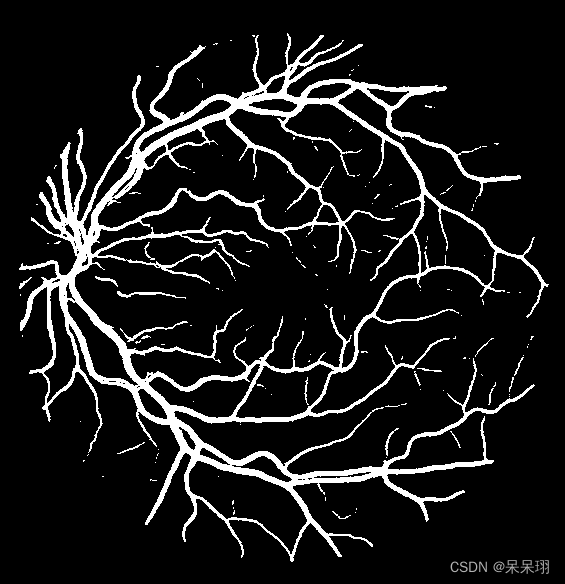
1. Pytroch推理代码
gpu_test文件夹
├── predict.py:推理代码
├── test_result_cuda.png: 检测结果
├── save_weights:模型文件夹
├── images:图片文件夹
├── src:相关库文件夹
└── mask:mask图片文件夹
import os
import time
import torch
from torchvision import transforms
import numpy as np
from PIL import Image
from src import UNet
def time_synchronized():
torch.cuda.synchronize() if torch.cuda.is_available() else None
return time.time()
def main():
classes = 1 # exclude background
# 模型路径
weights_path = "./save_weights/best_model.pth"
# 检测图片路径
img_path = "./images/01_test.tif"
# mask图片路径
roi_mask_path = "./mask/01_test_mask.gif"
assert os.path.exists(weights_path), f"weights {weights_path} not found."
assert os.path.exists(img_path), f"image {img_path} not found."
assert os.path.exists(roi_mask_path), f"image {roi_mask_path} not found."
mean = (0.709, 0.381, 0.224)
std = (0.127, 0.079, 0.043)
# get devices
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 用cpu推理
# device = "cpu"
print("using {} device.".format(device))
# create model
model = UNet(in_channels=3, num_classes=classes+1, base_c=32)
# load weights
model.load_state_dict(torch.load(weights_path, map_location='cpu')['model'])
model.to(device)
# dummy_input = torch.randn(1, 3, 584, 565)
# torch.onnx.export(model, dummy_input, 'eyes_unet.onnx', verbose=True, opset_version=11)
# load roi mask
roi_img = Image.open(roi_mask_path).convert('L')
roi_img = np.array(roi_img)
# load image
original_img = Image.open(img_path).convert('RGB')
# from pil image to tensor and normalize
data_transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std)])
img = data_transform(original_img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
model.eval() # 进入验证模式
with torch.no_grad():
# init model
img_height, img_width = img.shape[-2:]
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
output = model(img.to(device))
print(output["out"].shape)
t_end = time_synchronized()
print("inference time: {}".format(t_end - t_start))
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
# np.save("cuda_unet.npy", prediction)
print(prediction.shape)
# 将前景对应的像素值改成255(白色)
prediction[prediction == 1] = 255
# 将不敢兴趣的区域像素设置成0(黑色)
prediction[roi_img == 0] = 0
mask = Image.fromarray(prediction)
mask.save("test_result_cuda.png")
if __name__ == '__main__':
main()检测结果
2. ONNX代码推理
onnx_test文件夹
├── images : 检测图片文件夹
├── test_result_onnx.png: 检测结果
├── predict_onnx.py:推理代码
├── mask:mask图片文件夹
└── eyes_unet-sim.onnx :模型文件
import os
import time
from torchvision import transforms
import numpy as np
from PIL import Image
import onnxruntime as rt
def main():
# classes = 1 # exclude background
img_path = "./images/01_test.tif"
roi_mask_path = "./mask/01_test_mask.gif"
assert os.path.exists(img_path), f"image {img_path} not found."
assert os.path.exists(roi_mask_path), f"image {roi_mask_path} not found."
mean = (0.709, 0.381, 0.224)
std = (0.127, 0.079, 0.043)
# load roi mask
roi_img = Image.open(roi_mask_path).convert('L')
roi_img = np.array(roi_img)
# load image
original_img = Image.open(img_path).convert('RGB')
# from pil image to tensor and normalize
data_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)])
img = data_transform(original_img)
# expand batch dimension
img = img.numpy()
img = img[np.newaxis, :]
t_start = time.time()
sess = rt.InferenceSession('./eyes_unet-sim.onnx')
# 模型的输入和输出节点名,可以通过netron查看
input_name = 'input.1'
outputs_name = ['437']
# 模型推理:模型输出节点名,模型输入节点名,输入数据(注意节点名的格式!!!!!)
output = sess.run(outputs_name, {input_name: img})
output = np.array(output).reshape(1, 2, 584, 565)
t_end = time.time()
print("inference time: {}".format(t_end - t_start))
prediction = np.squeeze(np.argmax(output, axis=1))
print(prediction.shape)
prediction = prediction.astype(np.uint8)
# 将前景对应的像素值改成255(白色)
prediction[prediction == 1] = 255
# 将不敢兴趣的区域像素设置成0(黑色)
prediction[roi_img == 0] = 0
mask = Image.fromarray(prediction)
mask.save("test_result_onnx.png")
if __name__ == '__main__':
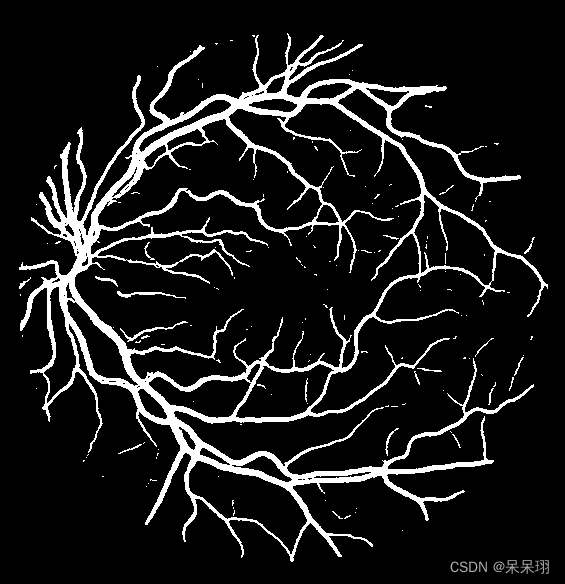
main()检测结果

3. RKNN模型转化
rknn_trans_1808_3588文件夹
├── dataset.txt: 量化数据集路径
├── images :量化数据集
├── trans_1808.py :适用1808的rknn模型
├── trans_3588.py :适用3588的rknn模型
├── mask:没用到
└── eyes_unet-sim.onnx:原始onnx模型
这个没什么好说的,装好环境,直接在相应的环境里面转就好啦,大家应该都会的(不会就拉出去,或者收藏留言,嘿嘿,我看看,出不出教程呢)
4. RKNN模型推理
4.1 rk1808_test文件夹
├── 01_test_mask.gif:mask图片
├── eyes_unet-sim-1808.rknn:rk1808适用模型
├── predict_rknn_1808.py:推理代码
├── test_result_1808.png :检测结果
└── 01_test.tif:检测图片
import os
import time
import numpy as np
from PIL import Image
from rknn.api import RKNN
def main():
# classes = 1 # exclude background
RKNN_MODEL = "./eyes_unet-sim-1808.rknn"
img_path = "./01_test.tif"
roi_mask_path = "./01_test_mask.gif"
assert os.path.exists(img_path), f"image {img_path} not found."
assert os.path.exists(roi_mask_path), f"image {roi_mask_path} not found."
# load roi mask
roi_img = Image.open(roi_mask_path).convert('L')
roi_img = np.array(roi_img)
# load image
original_img = Image.open(img_path).convert('RGB')
# from pil image to tensor and normalize
# data_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)])
# img = data_transform(original_img)
# expand batch dimension
img = np.array(original_img)
img = img[np.newaxis, :]
# Create RKNN object
rknn = RKNN(verbose=False)
ret = rknn.load_rknn(RKNN_MODEL)
# Init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime(target='rk1808')
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
t_start = time.time()
output = rknn.inference(inputs=[img])
t_end = time.time()
print("inference time: {}".format(t_end - t_start))
output = np.array(output).reshape(1, 2, 584, 565)
prediction = np.squeeze(np.argmax(output, axis=1))
print(prediction.shape)
prediction = prediction.astype(np.uint8)
# 将前景对应的像素值改成255(白色)
prediction[prediction == 1] = 255
# 将不敢兴趣的区域像素设置成0(黑色)
prediction[roi_img == 0] = 0
mask = Image.fromarray(prediction)
mask.save("test_result_1808.png")
rknn.release()
if __name__ == '__main__':
main()检测结果
4.2 rk3588_test文件夹
├── 01_test_mask.gif:mask图片
├── test_result_3588.png:检测结果
├── eyes_unet-sim-3588.rknn:rk1808适用模型
├── 01_test.tif:检测图片
└── predict_3588.py:推理代码
import os
import time
import numpy as np
from PIL import Image
from rknnlite.api import RKNNLite
def main():
# classes = 1 # exclude background
RKNN_MODEL = "./eyes_unet-sim.rknn"
img_path = "./01_test.tif"
roi_mask_path = "./01_test_mask.gif"
assert os.path.exists(img_path), f"image {img_path} not found."
assert os.path.exists(roi_mask_path), f"image {roi_mask_path} not found."
# load roi mask
roi_img = Image.open(roi_mask_path).convert('L')
roi_img = np.array(roi_img)
# load image
original_img = Image.open(img_path).convert('RGB')
# from pil image to tensor and normalize
# data_transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(mean=mean, std=std)])
# img = data_transform(original_img)
# expand batch dimension
img = np.array(original_img)
img = img[np.newaxis, :]
# Create RKNN object
rknn_lite = RKNNLite(verbose=False)
ret = rknn_lite.load_rknn(RKNN_MODEL)
# Init runtime environment
print('--> Init runtime environment')
ret = rknn_lite.init_runtime(core_mask=RKNNLite.NPU_CORE_AUTO)
if ret != 0:
print('Init runtime environment failed!')
exit(ret)
print('done')
t_start = time.time()
output = rknn_lite.inference(inputs=[img])
t_end = time.time()
print("inference time: {}".format(t_end - t_start))
output = np.array(output).reshape(1, 2, 584, 565)
prediction = np.squeeze(np.argmax(output, axis=1))
print(prediction.shape)
prediction = prediction.astype(np.uint8)
np.save("int8_unet.npy", prediction)
# 将前景对应的像素值改成255(白色)
prediction[prediction == 1] = 255
# 将不敢兴趣的区域像素设置成0(黑色)
prediction[roi_img == 0] = 0
mask = Image.fromarray(prediction)
mask.save("test_result_3588.png")
rknn_lite.release()
if __name__ == '__main__':
main()检测结果
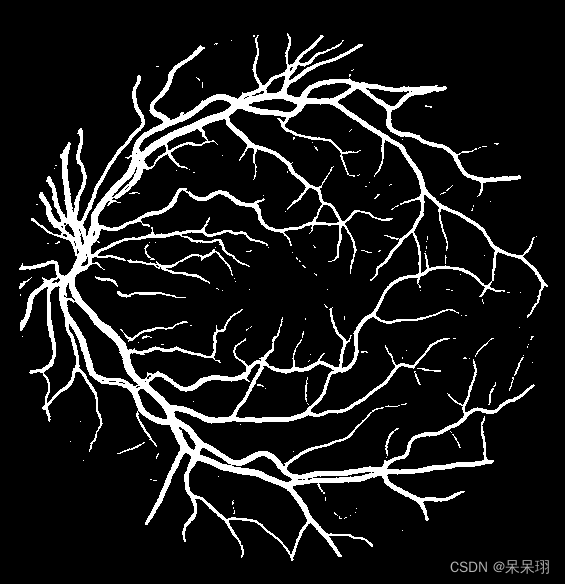
5. 所有结果对比
|
原图 |
GPU/ONNX |
RK1808 |
RK3588 |


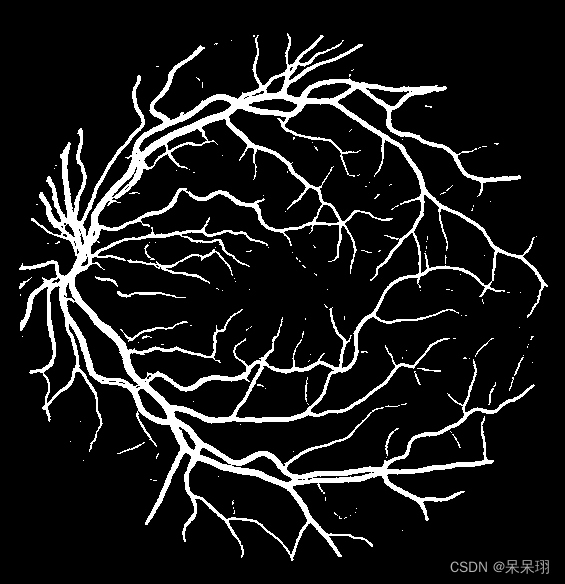
其实比对了一下数据,量化的效果还不错,精度在99.5%左右,还是蛮好的!!!