Unity Shader入门
文章目录
- 前言
- 环境
- Unity的帧调试器
- Unity Shader 概述
- 详解基于Unity编写的Blinn-Phong Shader
- 纹理
-
- 纹理面板与属性解析
- 代码使用纹理
- 凹凸映射
- 渐变纹理
- 遮罩纹理
- 透明效果
-
- alpha test与alpha blending
- 渲染顺序的重要性
- 渲染队列
- 开启深度写入的半透明效果
- 双面渲染的透明效果
-
- 透明度测试的双面渲染
- 透明度混合的双面渲染
前言
本文对应《Unity Shader入门精要》一书的初级篇,为自己的学习笔记与思考补充。
书籍配套源码:
https://github.com/candycat1992/Unity_Shaders_Book
配套插图:
http://candycat1992.github.io/unity_shaders_book/unity_shaders_book_images.html
环境
Unity版本:2020.1.6f1c1
编写shader:VS2019+ShaderlabVS
其中ShaderlabVS为VS的一个插件,安装地址:
https://marketplace.visualstudio.com/items?itemName=ShaderlabVS2019.ShaderlabVS
Unity的帧调试器
位置:Window->Analysis->Frame Debugger
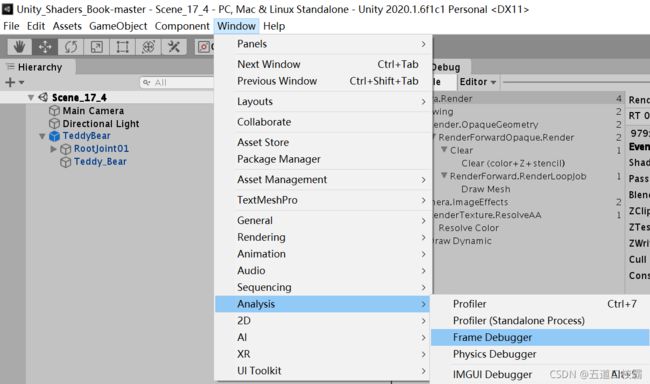
以书的资源Scene_17_4为例,打开Frame Debugger,可以看到如下画面:
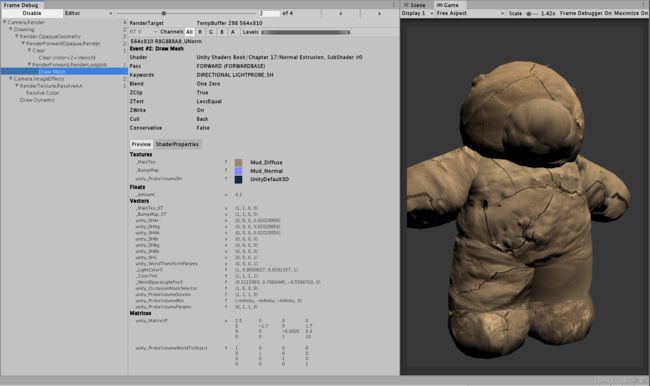
帧调试器可以用于查看渲染该帧时进行的各种渲染事件(event),这些事件包含了Draw Call序列,也包括了类似清空帧缓存等操作。
在Frame Debug所显示的所有事件的树状图中,每个叶子节点就是一个事件,右边不带数字;而每个父节点右侧带数字,代表该节点下的事件数目。
比如图中的Camera.ImageEffects右侧显示数字为2,表示其中包含两个事件,分别是Resolve Color与Draw Dynamic
以Draw开头的事件通常是一个Draw Call;当单机某个事件的时候(如上图点击了Draw Mesh)右侧的窗口中就会显示出该事件的细节(比如图中告诉了使用了哪个shader、剔除方式是背面剔除之类的),同时在Game窗口里也可以看到对应的效果。
值得一提的是,帧调试器实际上并没有实现一个真正的帧拾取(frame capture)的功能,而是仅仅使用停止渲染的方法来查看渲染事件的结果,所以得到的信息也就相对有限。所以有时还需要一些外部工具来辅助使用,比如RenderDoc
Unity Shader 概述
Unity中的材质需要结合一个GameObject的Mesh或者Particle Systems组件来工作,而shader则必须要和材质结合起来才能工作。
一个常见的流程:
- 创建一个材质
- 创建一个Unity Shader,并把它赋给上一步中创建的材质
- 把材质赋给要渲染的对象
- 在材质面板中调整Unity Shader的属性,以达到满意的效果
这里我们讲的Unity Shader指的是硬盘上的 .shader 文件。实际上Unity Shader != 真正的shader,而是用Unity自己定义的shaderlab语言去写的,其实际上就是对整个渲染过程的一层抽象,开发者只需要和Unity Shader也就是ShaderLab语言去打交道,Unity会在背后根据所使用的平台来把你所编写的 .shader 文件编译成真正的代码和 Shader 文件。
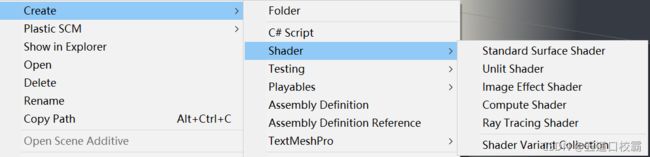
如上图,Unity提供了五种Unity Shader 模板,Standard Surface Shader会产生一个包含了标准光照模型(使用了PBR)的表面着色器模板,Unlit Shader则会产生一个不包含光照(但包含雾效)的基本的顶点/片元着色器,Image Effect Shader则为我们实现各种屏幕后处理效果提供了一个基本模板,Compute Shader旨在利用GPU的并行性来进行一些与常规渲染流水线无关的计算,详可见官方手册:https://docs.unity.cn/cn/current/Manual/class-ComputeShader.html,最后顾名思义为Ray Tracing Shader。
比如官方提供的一个Unlit Shader模板:
Shader "Unlit/NewUnlitShader"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
}
SubShader
{
Tags { "RenderType"="Opaque" }
LOD 100
Pass
{
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
// make fog work
#pragma multi_compile_fog
#include "UnityCG.cginc"
struct appdata
{
float4 vertex : POSITION;
float2 uv : TEXCOORD0;
};
struct v2f
{
float2 uv : TEXCOORD0;
UNITY_FOG_COORDS(1)
float4 vertex : SV_POSITION;
};
sampler2D _MainTex;
float4 _MainTex_ST;
v2f vert (appdata v)
{
v2f o;
o.vertex = UnityObjectToClipPos(v.vertex);
o.uv = TRANSFORM_TEX(v.uv, _MainTex);
UNITY_TRANSFER_FOG(o,o.vertex);
return o;
}
fixed4 frag (v2f i) : SV_Target
{
// sample the texture
fixed4 col = tex2D(_MainTex, i.uv);
// apply fog
UNITY_APPLY_FOG(i.fogCoord, col);
return col;
}
ENDCG
}
}
}
详解基于Unity编写的Blinn-Phong Shader
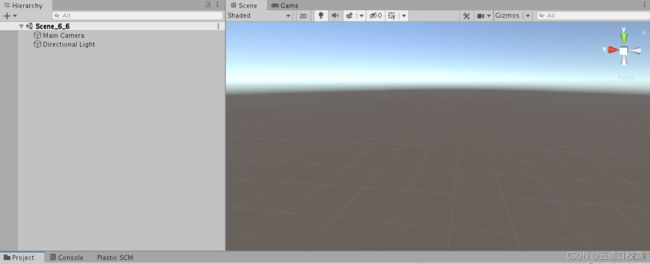
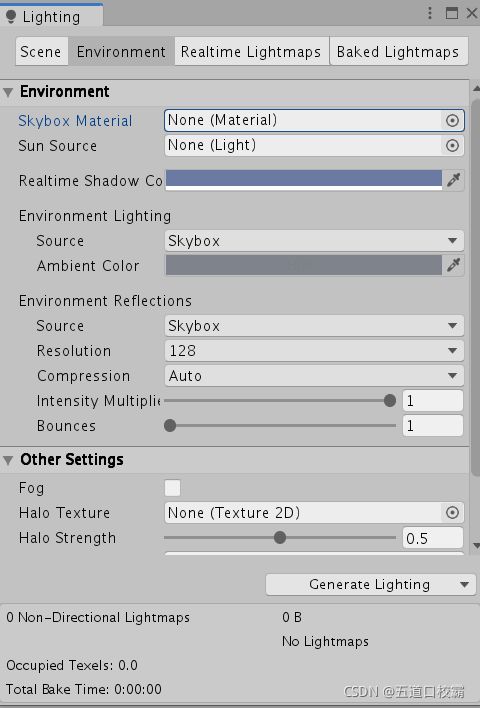
新建一个场景,可以看到场景中默认包含一个摄像机、一个平行光。而且场景背景不是纯色,而是一个天空盒子(Skybox)。
为了得到更加原始的效果,我们选择去掉这个天空盒。我们在Window->Rendering->Lighting中把Skybox Material选为None即可。

然后我们编写shader代码如下:
Shader "Unity Shader Learn/test/Blinn-Phong Use Built-in Functions"
{
Properties
{
_Diffuse ("Diffuse", Color) = (1, 1, 1, 1)
_Specular ("Specular", Color) = (1, 1, 1, 1)
_Gloss ("Gloss", Range(1.0, 500)) = 20
}
SubShader
{
Pass
{
Tags { "LightMode"="ForwardBase" }
CGPROGRAM
#pragma vertex vert
#pragma fragment frag
#include "Lighting.cginc"
fixed4 _Diffuse;
fixed4 _Specular;
float _Gloss;
struct appdata
{
float4 vertex : POSITION;
float3 normal : NORMAL;
};
struct v2f
{
float4 pos : SV_POSITION;
float3 worldNormal : TEXCOORD0;
float4 worldPos : TEXCOORD1;
};
v2f vert(appdata v)
{
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
// Use the build-in funtion to compute the normal in world space
o.worldNormal = UnityObjectToWorldNormal(v.normal);
o.worldPos = mul(unity_ObjectToWorld, v.vertex);
return o;
}
fixed4 frag(v2f i) : SV_Target
{
fixed3 ambient = UNITY_LIGHTMODEL_AMBIENT.xyz;
fixed3 worldNormal = normalize(i.worldNormal);
// Use the build-in funtion to compute the light direction in world space
// Remember to normalize the result
fixed3 worldLightDir = normalize(UnityWorldSpaceLightDir(i.worldPos));
fixed3 diffuse = _LightColor0.rgb * _Diffuse.rgb * max(0, dot(worldNormal, worldLightDir));
// Use the build-in funtion to compute the view direction in world space
// Remember to normalize the result
fixed3 viewDir = normalize(UnityWorldSpaceViewDir(i.worldPos));
fixed3 halfDir = normalize(worldLightDir + viewDir);
fixed3 specular = _LightColor0.rgb * _Specular.rgb * pow(max(0, dot(worldNormal, halfDir)), _Gloss);
return fixed4(ambient + diffuse + specular, 1.0);
}
ENDCG
}
}
FallBack "Specular"
}
接下来进行逐行拆解:
每个Unity Shader第一行都需要通过一个字符串去定义这个shader的名字,反斜杠是为了控制在材质面板中的位置,比如这里:
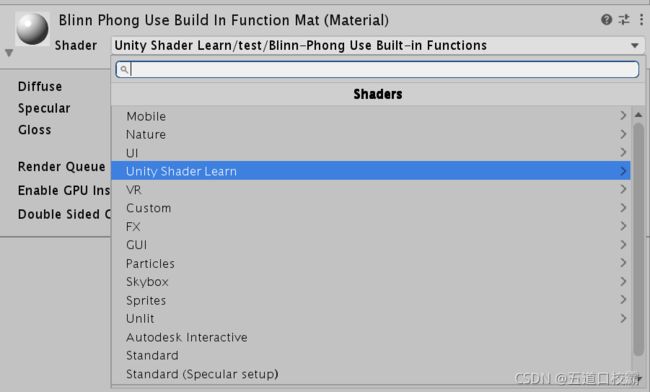
之后的Properties则是声明一系列属性以在材质面板中显示调整,比如这里我的_Diffuse 、_Specular 、_Gloss,就可以在材质面板进行调整:

分别对应Blinn-Phong中的diffuse材质的漫反射颜色、specular材质的高光反射颜色、gloss材质的反光度(用于控制高光区域的“亮点”有多宽)。
为了使用这些属性(在Cg代码中访问它),在后面我们仍需在 SubShader 的pass块中定义出来:
fixed4 _Diffuse;
fixed4 _Specular;
float _Gloss;
这里变量的名称和类型必须与Properties语义块中的属性定义相匹配。
比如这里颜色我们常用fixed4,控制高光区域大小的gloss我们用float。
接着往下,我们到了SubShader语义块。每一个Unity Shader文件可以包含多个SubShader语义块,但至少要有一个。
当Unity需要加载这个Unity Shader时,就会去扫描所有的SubShader语义块,然后选择第一个能够在目标平台运行的SubShader。如果都不支持的话就会去使用Fallback语义指定的Unity Shader。
因此可以知道,这里的FallBack就是为了“留一条后路”。
事实上FallBack还会影响阴影的投射。为每个Unity Shader正确设置Fallback是非常重要的。
FallBack "Specular"
再往下到了pass块。SubShader也可以定义标签Tags、LOD、渲染状态RenderSetup,当然也可以不定义。而一个pass则对应一次完整的渲染流程。
因此SubShader定义的标签是描述其内所有pass的,比如渲染顺序Queue,而pass中的标签则是对应这一趟渲染流程的,比如LightMode。
再往下,我们写了 CGPROGRAM 与结尾的 ENDCG,顶点/片元着色器代码需要定义在这之间,表明这之间的代码使用CG/HLSL去编写的。
这两行是为了用#pragma指令来告诉Unity我们定义的顶点着色器和片元着色器叫什么名字:
#pragma vertex vert
#pragma fragment frag
#include “Lighting.cginc” 是Unity的内置文件,这些内置文件的后缀都是 .cginc ,常见的还有 UnityCG.cginc, 是为了使用一些非常有用的变量和帮助函数。
之后的:
struct appdata
{
float4 vertex : POSITION;
float3 normal : NORMAL;
};
struct v2f
{
float4 pos : SV_POSITION;
float3 worldNormal : TEXCOORD0;
float4 worldPos : TEXCOORD1;
};
定义了两个结构体,分别表示从应用层输入到顶点着色器 和 从顶点着色器输入到片元着色器的结构体,v2f表示vertex to fragment,这里的命名我都是去模仿unity官方提供的模板的,同样的模仿还有大括号风格。
这里的POSITION、NORMAL、SV_POSITION等都是Cg/HLSL中的语义(semantics),它们是不可省略的,这些语义将告诉系统用户需要哪些输入值,以及用户的输出是什么。这样渲染器就知道用户的输入输出是什么,以便后续的插值等操作。
比如这里的POSITION表示要把模型的顶点坐标填充到参数vertex中,法线向量填充到normal 中,SV_POSITION则告诉Unity顶点着色器输出的是裁剪空间中的顶点坐标,之后渲染引擎就会把SV_POSITION修饰的变量经过光栅化后显示到屏幕上,因此这些语义描述的变量不可随便赋值。这里SV表示system-value,即系统语义。后面片元着色器的SV_Target也是HLSL中的一个系统语义,是为了告诉渲染器要把用户的输出颜色存储到一个渲染目标(render target)中,这里将输出到默认的帧缓存中。
接着来看顶点着色器:
v2f vert(appdata v)
{
v2f o;
o.pos = UnityObjectToClipPos(v.vertex);
// Use the build-in funtion to compute the normal in world space
o.worldNormal = UnityObjectToWorldNormal(v.normal);
o.worldPos = mul(unity_ObjectToWorld, v.vertex);
return o;
}
首先定义要输出的结构体 v2f o,接着把输入的模型坐标用unity内置函数UnityObjectToClipPos作用转换到裁剪空间坐标(以前是mul(UNITY_MATRIX_MVP,*)),并赋值给o.pos;接着是法线的变换,使用内置函数UnityObjectToWorldNormal;世界空间下的顶点坐标则是unity_ObjectToWorld与v.vertex相乘,即从模型空间转换到世界空间。
接着看片元着色器:
fixed4 frag(v2f i) : SV_Target
{
fixed3 ambient = UNITY_LIGHTMODEL_AMBIENT.xyz;
fixed3 worldNormal = normalize(i.worldNormal);
// Use the build-in funtion to compute the light direction in world space
// Remember to normalize the result
fixed3 worldLightDir = normalize(UnityWorldSpaceLightDir(i.worldPos));
fixed3 diffuse = _LightColor0.rgb * _Diffuse.rgb * max(0, dot(worldNormal, worldLightDir));
// Use the build-in funtion to compute the view direction in world space
// Remember to normalize the result
fixed3 viewDir = normalize(UnityWorldSpaceViewDir(i.worldPos));
fixed3 halfDir = normalize(worldLightDir + viewDir);
fixed3 specular = _LightColor0.rgb * _Specular.rgb * pow(max(0, dot(worldNormal, halfDir)), _Gloss);
return fixed4(ambient + diffuse + specular, 1.0);
}
环境光ambient使用了UNITY的内置变量UNITY_LIGHTMODEL_AMBIENT,worldNormal世界坐标的法向量则是把传进来的参数标准化一下,worldLightDir世界坐标下的光线方向则是用UnityWorldSpaceLightDir实现的,UnityWorldSpaceLightDir仅可用于前向渲染中,这个函数的输入是一个世界空间中的顶点位置(比如这里为i.worldPos),输出为世界空间中该点到光源的光照方向。没有被归一化,所以这里还用了normalize归一化了一下。
接着计算diffuse,为了防止法线和光源方向点乘结果为负(防止物体被后面来的光源照亮),这里我们与0取了max,接着乘以光源颜色和漫反射颜色。
接着计算高光反射,为了使用Blinn-Phong模型,我们用UnityWorldSpaceViewDir得到该顶点到观察方向的向量viewDir(世界坐标下),用worldLightDir和viewDir相加得到半程向量,然后用公式
c s p e c u l a r = ( c l i g h t ⋅ m s p e c u l a r ) m a x ( 0 , v ⃗ ⋅ c ⃗ ) m g l o s s c_{specular} = (c_{light} \cdot m_{specular}) max(0, \vec{v} \cdot \vec{c})^{m_{gloss}} cspecular=(clight⋅mspecular)max(0,v⋅c)mgloss
去计算高光反射部分的颜色和强度。
fixed3 specular = _LightColor0.rgb * _Specular.rgb * pow(max(0, dot(worldNormal, halfDir)), _Gloss);
最后返回像素的颜色值:
return fixed4(ambient + diffuse + specular, 1.0);
注:
Blinn-Phong光照模型和Phong光照模型(没有使用半程向量)都是经验模型,没有谁比谁更好一说。这种模型有很多局限性,比如无法表现菲涅尔反射(Fresnel reflection)等重要的物理现象。
其次Blinn-Phong模型是各项同性(isotropic)的,即固定视角和光源方向旋转这个表面时,反射不会发生任何改变。但是比如拉丝金属和毛发等就是各项异性(anisotropic)的。
纹理
纹理面板与属性解析
如图,Wrap Mode有几种模式可以选择,决定了当纹理坐标超过[0, 1]范围后将会如何被平铺:
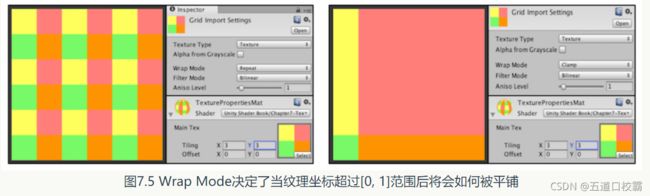
Repeat模式会不断重复,Clamp模式则是截取到0到1之间,如果纹理坐标大于1则为1,小于0则截取到0。
这里还展示了平铺(Tiling)属性,如上图为(3,3),而为(1,1)即原纹理则如下:

Filter Mode则决定了当纹理由于变换而产生拉伸时将会采用哪种滤波模式。可以选
Point:no filter,放大或缩小时采样的像素数目只有一个,呈现一种像素风格的效果。
Bilinear:双线性插值
Trilinear:三线性插值,还会在不同的Mipmap层次间作插值。
既然说到Mipmap,一般我们纹理都是用2的幂大小,Format决定Unity内部使用哪种格式来存储纹理。Advanced内可以选择:
![]()
来开启多级渐进纹理技术,通常这会使纹理占用空间多33%,比如不开启多级渐进纹理技术纹理的占用空间:
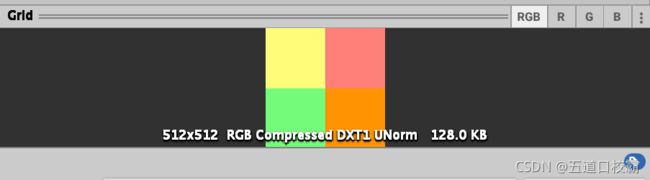
开启后占用空间:
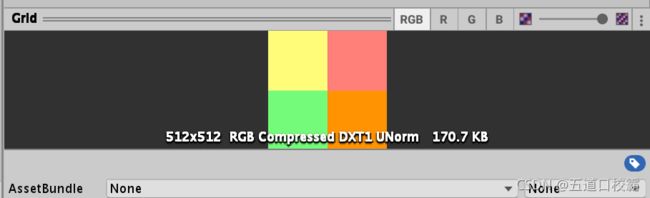
170.7 / 128 − 1 ≈ 33.3 % 170.7 / 128 - 1 \approx 33.3\% 170.7/128−1≈33.3%
原因其实是:
1 4 + ( 1 4 ) 2 + ( 1 4 ) 3 + . . . = 1 3 \frac{1}{4} + (\frac{1}{4})^{2} + (\frac{1}{4})^{3} + ... = \frac{1}{3} 41+(41)2+(41)3+...=31
代码使用纹理
Properties中声明:
_MainTex (“Main Tex”, 2D) = “white” {}
这里纹理的名字也可以改变,比如法线纹理可以声明为:
_BumpMap (“Normal Map”, 2D) = “bump” {}
white和bump都是Unity的内置纹理,前者为内置的纯白纹理,后者为内置的法线纹理。2D则是纹理属性的声明方式。
之后的pass中则需要声明:
sampler2D _MainTex;
float4 _MainTex_ST;
与之前的Properties内的属性不同,这里我们还声明了_MainTex_ST,_MainTex_ST不是随便起的,Unity中使用纹理名_ST的方式来声明某个纹理的属性。ST表示scale和translation,即缩放和平移。_MainTex_ST.xy存储缩放值,_MainTex_ST.zw存储偏移值。
比如之后我们可以在顶点着色器中写代码:
o.uv = TRANSFORM_TEX(v.texcoord, _MainTex);
这一行等效于:
o.uv = v.texcoord.xy * _MainTex_ST.xy + _MainTex_ST.zw;
这样才能正确使用面板中的Tilling和Offset
凹凸映射
纹理的另一常见应用是凹凸映射(bump mapping)。有两种主要方法:
- 使用一张高度纹理(height map)来模拟表面位移(displacement),然后得到一个修改后的法线值。
高度纹理常使用灰度图,颜色越浅则表面越向外凸,越深则越向里凹。这种方法导致实时计算要得到表面法线计算较困难。因此我们常使用第二种方法: - 使用一张法线纹理(normal map)来直接存储表面法线,这种方法又被称为法线映射(normal mapping)。一般我们把凹凸映射和法线映射作等同。
由于法线分量范围[-1, 1]而像素分量范围[0, 1],因此会做一个映射。
法线纹理还分模型空间下和切线空间下,如图:

模型空间中的法线纹理,每个顶点对应的法线都是在同一坐标空间——模型空间中的,因此每个点所存的法线方向是各异的,因此看起来五颜六色;
切线空间的z轴是顶点的法线方向,x轴为切线方向,y轴为二者作叉积得到(y轴也被称为副切线bitangent或副法线),因此每个顶点都有自身的切线空间,而实际上切线空间下的法线纹理所存的是一个法线的扰动方向。要是一个点的法线方向不变,那么对应在切线空间就是(0, 0, 1),映射后所存的就是(0.5,0.5,1),就是浅蓝色。因此看上去会有大片蓝色,其实就是说明顶点的大部分法线和模型本身法线是一样的,不需要改变(偏移)。
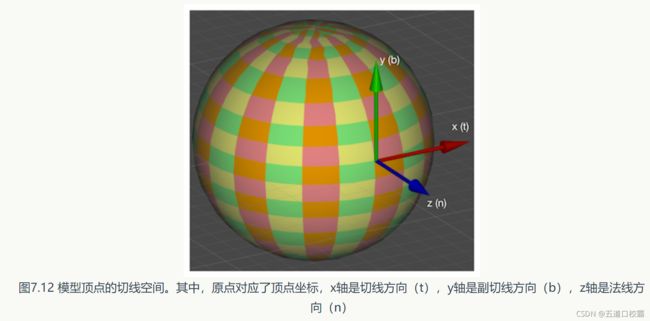
由于法线是单位向量,且切线空间下法线的z分量始终为正,即法线纹理的第三个通道的值可以由前两个通道推导出来,因此法线可以进行如DXT5nm格式去压缩。使用时再针对不同的压缩格式去对法线纹理进行正确的采样(Unity内置UnpackNormal函数)。
使用切线空间下的法线纹理有如下优点:
- 自由度高。因为模型空间存法线纹理记录的是绝对法线信息,仅可用于创建它的那个模型。而切线空间则存的是相对法线信息。
- 可进行UV动画。由于存的是相对法线信息,所以可以简单地移动一个纹理的UV坐标来实现一个凹凸移动的效果。
- 可以重用法线纹理。
- 可以压缩
实际上,法线本身可以存储在任意坐标系,得到法线是为了后续的光照计算。在这里我们采用切线空间,在光照计算中则有两种手法:
- 在切线空间下计算光照模型:
在片元着色器中通过纹理采样得到切线空间下的法线,然后再与切线空间下的视角方向、光照方向等进行计算,得到最终的光照结果。 - 在世界空间下计算光照模型:
在顶点着色器中计算从切线空间到世界空间的变换矩阵,并传递给片元着色器。最后在片元着色器中把法线纹理的法线方向从切线空间变换到世界空间下即可。
注意:这里涉及坐标系变换,从效率而言第一种手法优于第二种,但是从通用性而言第二种更好(因为我们有时需要在世界空间下进行一些计算)。
并且这里的坐标系变换,我们只需要把光线向量、视线向量等做出变换,因此并不需要坐标系平移使原点对齐,只要把三个轴旋转对齐即可。
渐变纹理
使用一张纹理(渐变纹理)去控制漫反射光照的结果。

比如这里我们使用半兰伯特模型,根据法线方向和光照方向计算出halfLambert值并映射到[0, 1]之后,我们把这个计算出来的值当作UV坐标(u和v此时相同)去在渐变纹理种进行采样。然后把这个采样出来的结果和材质颜色相乘以当作最终的漫反射颜色。
需要注意的是,这里我们需要把渐变纹理的Wrap Mode设置为Clamp模式,以防止对纹理进行采样时由于浮点数精度而造成的问题。

遮罩纹理
mask texture
什么是遮罩(mask)呢?简言之,遮罩允许我们可以保护某些区域,使他们免于某些修改。
使用遮罩纹理的一般流程是:通过采样得到遮罩纹理的纹素值,然后使用其中某个或某几个通道的值(比如texel.r)来与某种表面属性进行相乘,这样在该通道值为0的时候就可以保护表面不受该属性的影响。
注:
- 代码实现中,我们为主纹理_MainTex、法线纹理_BumpMap和遮罩纹理_SpecularMask定义了它们共同使用的纹理属性变量_MainTex_ST,这意味着在材质面板中修改主纹理的平铺系数和偏移系数会同时影响3个纹理的采样。
使用这种方式可以让我们节省需要存储的纹理坐标数目,因为顶点着色器可以使用的插值寄存器是有限的。 - 真实的游戏制作过程中,遮罩纹理已经不止限于保护某些区域使它们免于某些修改,而是可以存储任何我们希望逐像素控制的表面属性。通常我们会充分利用一张纹理的RGBA四个通道,用于存储不同的属性。
透明效果
alpha test与alpha blending
在unity中有两种方法来实现透明效果:
- 透明度测试(alpha test):
只要一个片元的透明度不满足条件(通常是小于某个阈值)就舍弃它。
比如HLSL中用clip,GLSL中用discard,一段伪代码:
if (texColor.a < 0.1)
{
discard;
}
而实际上,对于Cg中的函数clip等同于如下伪代码:
void clip(float4 x)
{
if (any(x < 0))
discard;
}
透明度测试不需要关闭深度写入(即仍然可以把深度值更新到深度缓冲中)。和其他不透明物体最大的不同就是会根据透明度来舍弃一些片元。因此产生的效果要么完全透明(即看不到),要么完全不透明。
通常,使用alpha test的shader都应该在subshader中设置这三个标签:

分别表示渲染队列为AlphaTest、不受投影器(Projectors)的影响、把这个Shader归入到提前定义的TransparentCutout组以指明该shader是一个使用了透明度测试的shader(RenderType标签通常被用于着色器替换功能)。
在片元着色器中我们开启透明度测试:
clip (texColor.a - _Cutoff);
// Equal to
// if ((texColor.a - _Cutoff) < 0.0) {
// discard;
// }
这里_Cutoff是我们定义在Properties的参数:
_Cutoff ("Alpha Cutoff", Range(0, 1)) = 0.5
最后的回调:
FallBack "Transparent/Cutout/VertexLit"
这保证了使用透明度测试的物体可以正确地向其他物体投射阴影。
测试结果:
透明效果很“极端”:要么全透明要么完全不透明。而且得到的透明效果在边缘处参差不齐,有锯齿,这是因为在边界处纹理的透明度的变化精度问题。
为了得到更柔滑的透明效果,就可以使用透明度混合。
- 透明度混合(alpha blending):
这种方法可以得到真正的半透明效果。
它会使用当前片元的透明度作为混合因子,与已经存储在颜色缓冲区的颜色值进行混合,得到新的颜色。但是需要关闭深入写入(即不会把深度值更新到深度缓冲中,否则还怎么透明,当然不透明物体是要进行深度写入的),不过并不会关闭深度测试(即仍然会比较当前片元的深度值和当前深度缓冲中的深度值)。
即对于透明度混合来说,深度缓冲是只读的。
混合是一个逐片元的操作,它不是可编程的,但却是高度可配置的。
为了进行混合,我们需要使用unity提供的混合命令——Blend。
ShaderLab的Blend命令:
- Blend Off
- Blend SrcFactor DstFactor
- Blend SrcFactor DstFactor, SrcFactorA DstFactorA
- BlendOp BlendOperation
详细描述可见书的P169.
通常,使用alpha blending的shader都应该在subshader中设置这三个标签:
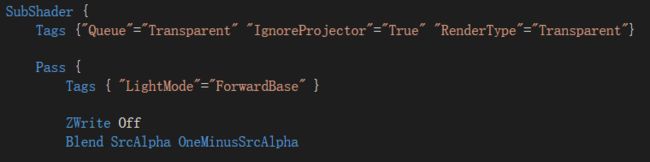
并且可以看到,Pass中我们还把深度写入ZWrite设置为关闭状态Off,然后开启并设置了该Pass的混合模式。
这里我们使用Blend SrcFactor DstFactor来进行混合,这个命令在设置混合因子的同时也开启了混合模式。而只有使用Blend命令打开混合后,我们在这里设置透明通道才有意义,否则这些透明度并不会对片元的透明效果有任何影响。
Blend SrcFactor DstFactor:我们会把源颜色(该片元产生的颜色)乘以SrcFactor,而目标颜色(已经存在于颜色缓存的颜色)会乘以DstFactor。
Blend SrcAlpha OneMinusSrcAlpha 这一句其实内含了把DstFactor设为OneMinusSrcAlpha,这意味着混合后新的颜色是:
D s t C o l o r n e w = S r c A l p h a × S r c C o l o r + ( 1 − S r c A l p h a ) × D s t C o l o r o l d DstColor_{new} = SrcAlpha \times SrcColor + (1 - SrcAlpha) \times DstColor_{old} DstColornew=SrcAlpha×SrcColor+(1−SrcAlpha)×DstColorold
而对于Blend SrcFactor DstFactor, SrcFactorA DstFactorA,其实就是区分了RGB通道的混合因子和Alpha通道的混合因子,这里SrcFactor、DstFactor为RGB通道的混合因子,而SrcFactorA 、DstFactorA为Alpha通道的混合因子。
当设置混合状态时,我们实际上设置的是混合等式(即从源颜色和目标颜色得到输出颜色的等式)的操作和因子,而一般操作都是默认加操作,否则可以用混合操作命令 BlendOp BlendOperation 改为其他操作。因此很多时候我们只需要设置混合因子即可。
一个例子:
Blend SrcAlpha OneMinusSrcAlpha, One Zero
关于混合操作和混合因子的更多设定可以看书本P174,这里仅放一个结果:
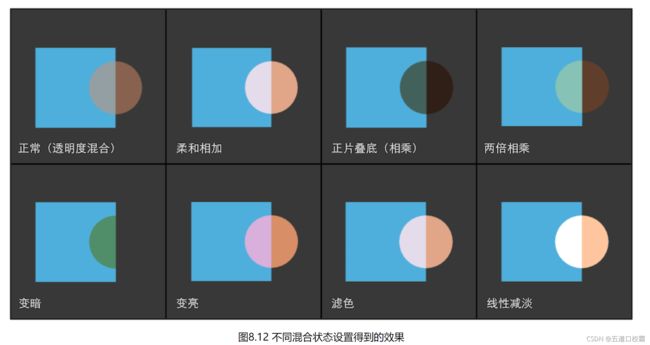
渲染顺序的重要性
由于半透明物体关闭了深度写入,也就破坏了深度缓冲的机制,这是一个非常糟糕的事情。关闭深度写入也使得渲染顺序变得无比重要。
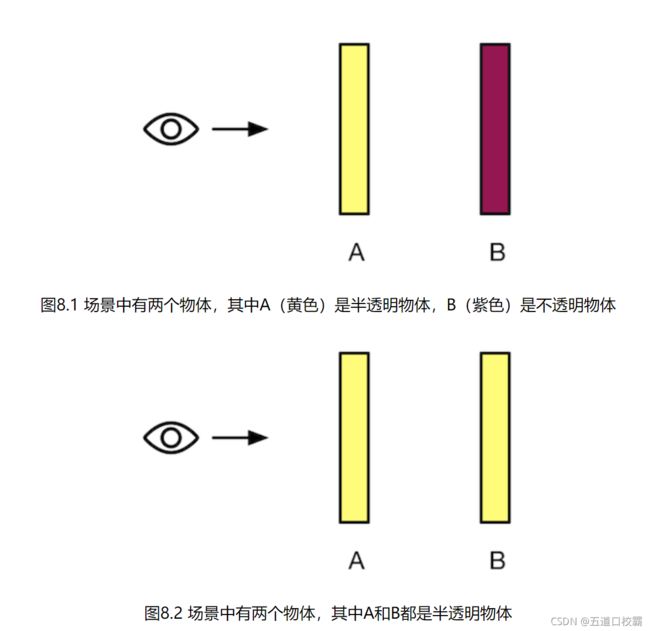
比如上图的两个场景,我们都需要先渲染在后面的B物体,再渲染在前面的半透明的A物体,否则就会出错。
因此渲染引擎一般都会先对物体排序再渲染,常用的方法是:
- 先渲染所有不透明物体,并开启深度测试和深度写入。
- 把半透明物体按它们距离摄像机的远近进行排序,然后按照从后往前的顺序渲染这些半透明物体,并开启它们的深度测试,但关闭深度写入。
然而即使是这样,仍然会有情况发生错误,比如下图:
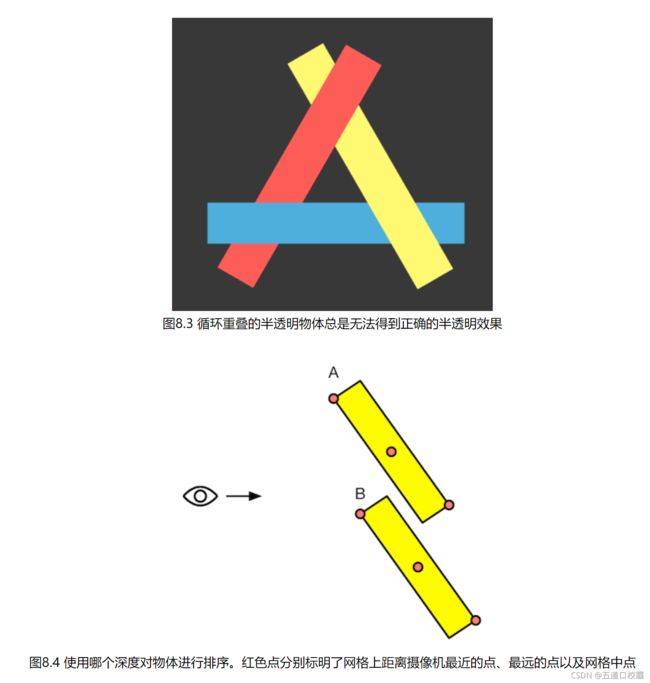
图8.4,无论物体的深度排序是离摄像机最近的点、中心点还是离摄像机最远的点,图8.4中A始终在B之前,但是B的的确确遮挡了A。这就会造成错误。
这种问题的解决方法通常是分割网格。为了减少错误排序的方法,我们可以尽可能让模型是凸面体,并且尽量考虑将复杂的模型拆分成可以独立排序的多个子模型等。其实就算排序错误结果有时也不会非常糟糕,如果不想分割网格,还可以试着让透明通道更加柔和,使穿插看起来并不是那么明显。我们也可以使用开启了深度写入的半透明效果来近似模拟物体的半透明。
渲染队列
unity为了解决渲染顺序问题提供了渲染队列(render queue)这一解决方案。可以用ySubShader的Queue标签来决定我们的模型将归于哪个渲染队列。这一部分在书的165页。
官方文档:
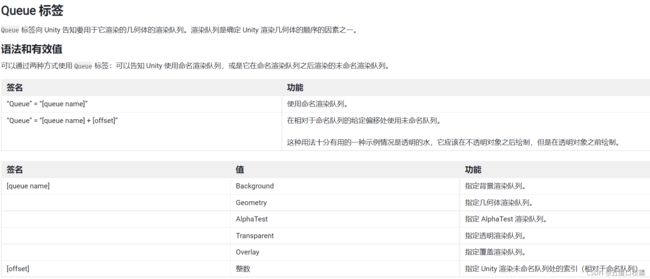
https://docs.unity.cn/cn/current/Manual/SL-SubShaderTags.html
开启深度写入的半透明效果
如之前所述,半透明效果需要Alpha Blending,但是由于不开启深度写入,在半透明对象之间遮挡时可能会出现错误:
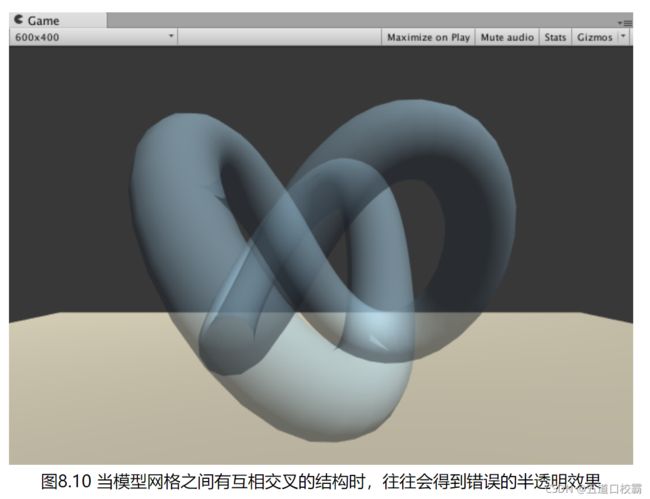
这里我们的解决方法是两趟pass:
第一个Pass开启深度写入,但不输出颜色,它的目的仅仅是把该模型的深度值写入深度缓冲中,代码如下:
Pass
{
ZWrite On
ColorMask 0
}
这里第一行ZWrite On开启了深度写入,第二行ColorMask 0意味着该Pass不写入任何颜色通道,即不会输出任何颜色。因此该Pass仅写入深度缓存。
ColorMask在ShaderLab中用于设置颜色通道的写掩码(write mask),它的语义如下:
ColorMask RGB | A | 0 | 其他任何R、G、B、A的组合
第二个Pass则进行正常的透明度混合即可。
由于第一个Pass已经得到了逐像素的正确的深度信息,第二个Pass就可以按照像素级别的深度排序结果进行透明度渲染。
当然这样做缺点是多了一个Pass,影响性能,但是效果还是不错的:
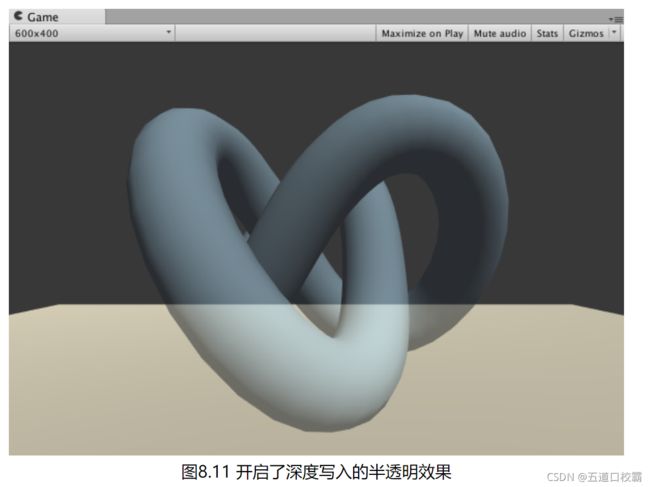
双面渲染的透明效果
由于默认情况下渲染引擎剔除了物体背面(相对于摄像机的方向)的渲染图元,而只渲染了物体的正面。因此如果我们想要得到双面渲染的效果,可以使用Cull指令来控制需要剔除哪个面的渲染图元。
Unity中Cull指令的语法:
Cull Back | Front | Off
透明度测试的双面渲染
只需要在Pass中使用 Cull Off 去掉剔除即可:
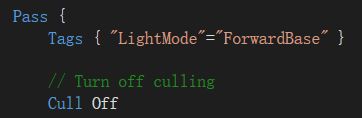
得到效果:

透明度混合的双面渲染
由于此时同一个物体正面和背面还有一个渲染顺序,所以不能简单地Cull Off,我们这里采用两个Pass:
第一个Pass只渲染背面,因此正面剔除,使用代码:
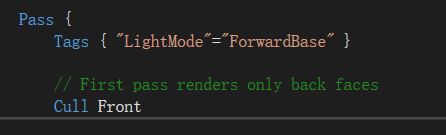
第二个Pass只渲染正面,因此背面剔除,使用代码(事实上由于默认背面剔除,这里不加这行代码也没关系):
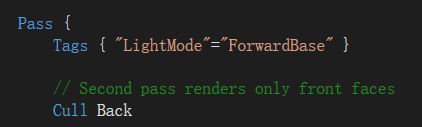
得到效果:
