目标检测:SSD数据增强层解读
SSD 的数据增强对ssd网络识别小物体效果明显(原文Fig6),而且他使用的方法有点特别,所以在此解析一下他的源码。python代码
补充一下data augment翻译:叫“数据增广”更好,中科院自动化所的师兄的翻译更准确
(一) ssd_pascal.py
/examples/ssd/ssd_pascal.py
在此源码中有几个点是涉及到数据预处理的,在此列举如下:
#第93行,变量batch_sampler
93 batch_sampler = [……这是原文中所提到的(小节2.2)数据增强所用到的jaccard overlap和其他两个策略,在代码中的参数设置。
#第179行,train_transform_param
train_transform_param = {……
#第216行,test_transform_param这儿设置了一些图像变换的方法,比如resize转换大小,distort颜色变化,还有后面两个不太明白,先及下来。
//TODO:expand,emit这些参数都去哪儿了呢,在后面创建*.prototxt的时候用到了
#第435行,CreateAnnotatedDataLayer()函数
net.data, net.label = CreateAnnotatedDataLayer(
#此函数在/python/caffe/model_libs.py中。
#在第208行,batch_sampler被赋值给了annotated_data_param
#第196/201以及214,transform_param被赋值给了transform_param(二)train.prototxt
然后去找所创建的prototxt文件,在jobs/VGGNet/Voc0712/ssd_300/train.prototxt中,可以找到字典transform_param和annotated_data_param。
然后根据这两个参数去找调用他们的cpp代码
//对于batch_sampler的解释:(train.prototxt)
batch_sampler {
sampler {
min_scale: 0.3 #scale是patch随机框和原图的面积比
max_scale: 1.0
min_aspect_ratio: 0.5 #长宽比
max_aspect_ratio: 2.0
}
sample_constraint {
min_jaccard_overlap: 0.3 #随机框和原ground truth的jaccard overlap
}
max_sample: 1
max_trials: 50 #迭代次数
}(三)annotated_data_layer.hpp/.cpp
1)transform
a.) 灰度/颜色扭曲DistortImage()函数(在第157行)
this->data_transformer_->DistortImage(anno_datum.datum(),
distort_datum.mutable_datum());b.) ExpandImage()(在第161/168行)
this->data_transformer_->ExpandImage(distort_datum, expand_datum);这两个函数都是调用了this指针,在该annotated.hpp头文件中可以看到没有这两个函数,但她继承了BasePrefetchingDataLayer文件,在里面可以找到data_transformer_是类DataTransformer的指针,至此可以找到DistortImage了,同样的ExpandImage。
这两个函数的功能
1. ExpandImage是缩小图片,达到zoom out的效果:先做一个比原图大的画布,然后随机找一个放原图的位置将原图镶嵌进去,像天安门上挂了一个画像。这在SSD原文中提到的zoom out缩小16倍(4×4,3.6节)来获得小对象的方法。
而放大图像必然会导致需要填充一些数据,原文(SSD,3.6节)提到是使用mean值填充,在data_transforme.cpp中,使用了如下的代码:
if (has_mean_values) {
transformed_data[top_index] =
(datum_element - mean_values_[c]) * scale;//c是channel,在prototxt中有三个值,分别对应三个波段104,117,123。
} - distortImage使用了opencv的函数(DataTransformer.cpp),但我没找到该函数的实现。
// Distort the image.
cv::Mat distort_img = ApplyDistort(cv_img, param_.distort_param());
annotated_data_param/batch_samplers的处理c.) 随机裁剪
batch_samplers是生产随机样本patch的方法,在该cpp的第178行调用了函数GenerateBatchSamples()函数原型定义为:
// Generate samples from AnnotatedDatum using the BatchSampler.
// All sampled bboxes which satisfy the constraints defined in BatchSampler
// is stored in sampled_bboxes.
void GenerateBatchSamples(const AnnotatedDatum& anno_datum,
const vector然后调用到了函数GenerateSamples/SampleBBox
其方法是随机生产width和height,但是长宽的生成是相关的;然后在随机生成左上角坐标(之前见到的是先随机生成左上角坐标,然后用固定size去裁剪)
void SampleBBox(const Sampler& sampler, NormalizedBBox* sampled_bbox) {
// Get random scale.
CHECK_GE(sampler.max_scale(), sampler.min_scale());//scale是prototxt中参数
CHECK_GT(sampler.min_scale(), 0.);//检查这些参数符合逻辑
CHECK_LE(sampler.max_scale(), 1.);
float scale;
caffe_rng_uniform(1, sampler.min_scale(), sampler.max_scale(), &scale);//自定义的生成随机数的方法,在区间内生成float数,类似于random.random()
// Get random aspect ratio.
CHECK_GE(sampler.max_aspect_ratio(), sampler.min_aspect_ratio());
CHECK_GT(sampler.min_aspect_ratio(), 0.);
CHECK_LT(sampler.max_aspect_ratio(), FLT_MAX);//同样检查超参
float aspect_ratio;
caffe_rng_uniform(1, sampler.min_aspect_ratio(), sampler.max_aspect_ratio(),
&aspect_ratio);//随机数
aspect_ratio = std::max<float>(aspect_ratio, std::pow(scale, 2.));//做了些调整
aspect_ratio = std::min<float>(aspect_ratio, 1 / std::pow(scale, 2.));
// Figure out bbox dimension.
float bbox_width = scale * sqrt(aspect_ratio);//长宽
float bbox_height = scale / sqrt(aspect_ratio);
// Figure out top left coordinates.
float w_off, h_off;
caffe_rng_uniform(1, 0.f, 1 - bbox_width, &w_off);//左上坐标
caffe_rng_uniform(1, 0.f, 1 - bbox_height, &h_off);
sampled_bbox->set_xmin(w_off);
sampled_bbox->set_ymin(h_off);
sampled_bbox->set_xmax(w_off + bbox_width);
sampled_bbox->set_ymax(h_off + bbox_height);
}将随机产生的框(超参数给出迭代次数为max_trials: 50,会产生一些有效的符合要求的框boxes,不一定是50)存入一个容器中,然后再这这个容器中随机选择一个来裁剪图片和标注数据。
// Generate sampled bboxes from expand_datum.
vector用到了这几个数据的处理关系如下: 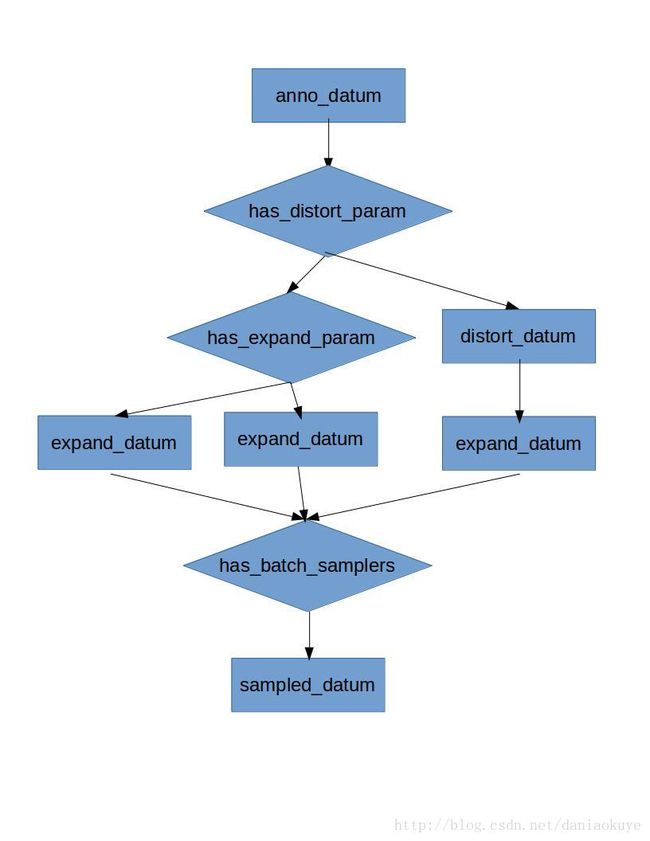
之所以要贴出来,是因为多种transform方法组合在一起的时候,必然会带来排列组合的问题,源码中使用了一些组合方式,而不是生成一堆图像。(有人在blog中提到不同类别样本的数目问题,不均衡肯定是不好的,带来一些训练偏好)
上面并没有提及的是图片的长和宽,除了ExpandImage中会得到固定的size 的裁剪图片,其他的地方没有特别强调图片长宽不同,特别是sampled随机裁剪图片时,长和宽是用同样的随机数得到的,如果要被裁剪的图片长宽不同,那最终就不能保证aspect ratio(宽/长)了。
我们继续分析源码,annotateDataLayer层重新实现了DataLayerSetUp()函数,该函数是BaseDataLayer的一个虚函数,里面的。而BasePrefetchingDataLayer类的LayerSerup()调用了BaseDataLayer::LayerSetUp(bottom, top);函数将数据存入了prefetch_中,而所获取的数据被重新的reshape()了。
// Reshape top[0] and prefetch_data according to the batch_size.
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {//AnnotatedDataLayer::DataLayerSetUp() ---line60
this->prefetch_[i].data_.Reshape(top_shape);//其中,data_经过多层继承,最终是Blob的一个对象
}在这个层(annotateDataLayer)被调用的时候,它已经将输入数据resize了。
git代码(python)https://github.com/daniaokuye/SSD_data_augment.git