测试技能提升HM-python编程
pycharm工具基本使用及python基本
python简介
Python是一种跨平台、简单易学、面向对象的编程语言一门计算机语言
自动化测试—通过代码取代手工测试
市场自动化语言:python 、 java
企业市场占比:7:3 Python占比高
偏向学习python:上手简单,代码简洁,同时很多支撑(python内库和第三方库)
内库:python底层封装好的模块 比如:unittest 、 os
第三方库:不是python底层封装好的模块 比如:pytest openpyxl htmltestrunner
同一需求 = python 10行 =100 java代码
问题:Python自动化脚本是否能测试 非python语言的项目? 是可以
Python自动化脚本==基于python搭建多套自动化框架(自己写工具)
工具postman jmeter ---->测试各种语言开发的项目
基于python搭建多套自动化框架(自己写工具)----》测试各种语言开发的项目(接口+web+app)
python版本
python2 ----》python2.x python2.5 python2.6
python2.7 2020年官方停止维护
Python3 企业都在python3
注意:python2与python3语法很大区别,Python版本强制用Python3
查看版本:运行-cmd-python
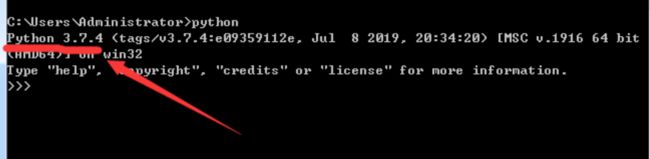
解析器:python.exe ----->python代码翻译成电脑识别并执行
pip.exe
pip3.exe 实现安装第三方库 pip install 第三方库
代码编辑器—》集成开发环境IDE
python常用集成开发工具:
1)Python自带集成开发工具 IDLE 开始-所有程序-python3.7 一般不用
pycharm 程序员(码农) 友好
高亮提示 快捷操作 调试工具 …界面美观
比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制
本地环境及虚拟环境
本地环境:python安装环境
项目-----》迁移其他电脑 其他电脑端 再次安装第三方库
虚拟环境:项目—》迁移其他电脑 项目代码解析通过
项目—》很多第三方库 安装第三方库
Python自动化框架(工程)- ----》迁移项目(不需要安装第三方库)----》顺利执行项目
||
Python内库+python第三方库(本地环境)
||
完成测试各种工作(编辑用例,执行用例,生成测试报告…)
问:虚拟环境 python代码是通过哪个解析器执行呢?
本地环境 Python代码又是哪一个呢?
pycharm工具的使用
1、创建工程
2、Directory /python package / python file

Directory 目录/文件夹 一般用例管理css样式文件/图片文件
python package 包 一般情况下用python package去管理多
个Python文件(.py文件),同时创建一个__ init __.py的文件
项目:
目录/包名1(testcases)
很多python文件 —》python file 用来写代码 (模块)
目录2
很多python文件
目录3
很多python文件
3、基本设置

python基本语法及常见数据类型
基本语法
1)编码
默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是
unicode 字符串
指定其他编码格式,如下:
#-* - coding: cp-1252 -*-
2)标识符
什么标识符:整个项目中,所有的名称(变量名、项目名、文件名)都
是标识符
标识符命名规则:
1、第一个字符必须是字母或下划线 _ 。
2、其他的部分字符由字母、数字和下划线组成。
3、标识符对大小写敏感。(区分大小写)
在 Python 3 中,可以用中文作为变量名,非 ASCII 标识符也是允许的了
注意:标识符不能是python的关键字
Python关键字有哪些?
[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘async’, ‘await’, ‘break’,‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’,‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’,‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
语法报错:

缩进
缩进报错:

注释
注释作用:提高代码可读性和可维护性
python注释有哪些?
1、单行注释 # 快捷键 ctrl+/
2、多行注释 选择多行+快捷键 ctrl+/ 或者 “”“”“” 或者 ‘’‘’‘’
5)多行语句
Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反
斜杠()来实现多行语句
6)print函数默认会换行,并且可以输出多个内容
不换行输出怎么办? end=" "
print(“cn”,“czj”,“此行路远…”,end=" ")
score=80
print("恭喜获取本期奖学金")
print("受到惩罚")
print("assssssssssssssssssss")
item_one=10
item_two=20
item_three=30
item_4=30
item_5=30
item_6=30
total = item_one +\
item_two +\
item_three+\
item_4+\
item_5+\
item_6
print(total);print("hello world");print("hello world");print("hello world")
print("hello world")
print("hello world")
Python基本数据类型
1、什么是变量
变量:存储数据
Python中的变量不需要声明,每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
2、Python3中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典) --》dict
六大数据类型又可以划分为:
不可变数据(3个):number、string、tuple
可变数据(3个):list、dictionary、set
number数据类型 ----》数值类型
1、Python3 支持四种不同数值类型 int、float、bool、complex(复数)。
bool类型:0 ==False 1 ==True
2、常用的数值函数
abs(x)取得数字的绝对值
ceil(x)返回数字的上入整数
floor(x)返回数字的下舍整数
random.random()返回随机生成的一个实数,它在[0,1)范围内。
random.randint(a,b)返回随机生成一个整数,在a~b之间的整数
import math
# 随机生成数值类型
import random
# 定义number类型
num1=1
num2=2.1
num3=False
print(num1)
# 打印数据类型
print(type(num1),type(num2),type(num3))
print(num1**2)
print(9/2)
# //获取得到与除数类型是一致,不会进行四舍五入,/返回值类型为float
print(9//2.0)
print(abs(num1))
print(" floor(x)返回数字的下舍整数:",math.floor(4.0))
print(" ceil(x)返回数字的上入整数",math.ceil(5.1))
print(" random.random()返回随机生成的一个实数,它在[0,1)范围内:", random.random())
# random.randint(a,b)返回随机生成一个整数,在a~b之间的整数")
print("random.randint(a,b)返回随机生成一个整数,在a~b之间的整数:", random.randint(100, 200))
# 进行四舍五入
print(round(4.7),round(4.78,1))
# 去掉整数部分 math.trunc
print(math.trunc(4.7))
运算符

/ 或者//
** a**b= a的b次幂
% 取余
注意://获取得到与除数类型是一致,不会进行四舍五入
/返回值类型为float
string类型
1、定义
字符串是 Python 中最常用的数据类型。Python中的字符串用单引
号 ‘ 或双引号 “或者’’’括起来
2、字符串切片
"""
语法格式:变量[start:end:step] 特别注意规则: 含头不含尾 左闭右开
start:开始索引值 索引值从左到右 从0开始 索引值从右到左,从‐1开始
end:结束索引值
step:步长 默认是1
"""
str_num="123456789"
# 取单字符 字符串中第二个字符
print(str_num[1])
# 取单字符 字符串中倒数第二个字符
print("字符串中倒数第二个字符:",str_num[‐2])
# 取多个字符 从开始位置截图长度为3对应的字符串 h e l 0:3
print(" 从开始位置截图长度为3对应的字符串:",str_num[0:3])
# 取从第三个字符开始,截取后面所有字符
print("取从第三个字符开始,截取后面所有字符:",str_num[2:])
# 截取前六个字符
print("截取前六个字符:",str_num[0:6])
print("截取前六个字符:",str_num[:6])
# 步长为1
print(str_num[::2])
# 字符串反转 从右到左
print("字符串反转:",str_num[::‐1])
3、字符串是不可变数据类型,字符串更新,不能对某个字符更新,
只能通过拼接更新
4、特殊符号处理
![]()
print("1111\n2222")
# 原符号输出 前面\(转义) 特殊符号
print("1111\\n\"\'2222\\")
print(r"1111\n'\"2222")
print(R"1111\n'\"2222")
print(r"E:\VIP\PPT\Python基础")
print(R"E:\VIP\PPT\Python基础")
# 特殊符号 进行特定场景输出
# print("1111\n2222")
5、格式化
"""
字符串格式化
"""
# 字符串格式表示方式一
print("%s[%s期,工作年限:%d],欢迎来到码尚学院VIP课堂"%("大雨","M211",3))
# 字符串格式表示方式二
print("{1}[{0}期,工作年限:{2}],欢迎来到码尚学院VIP课堂".format("大雨","M211",3))
# 字符串格式表示方式三 f 字面量格式化
name="大雨"
q="M211"
year="2"
print(f"{name}[{q}期,工作年限:{year}],欢迎来到码尚学院VIP课堂")
字符串常见函数
重点:
join:通过分隔符合并一个新的字符
split:通过分隔符截图多个字符,存储在列表中
replace
index
count
# join(seq)
# 以指定的分隔符把seq中的元素合并成一个新字符串 join 加入‐‐‐某个规则符号+合并
join_str="helloworld"
new_str="‐".join(join_str)
print(new_str)
# split()
# 通过分隔符截取字符串 通过分隔符,返回列表数据
names="hefan;大雨;志大叔"
namel=names.split(";")
print(namel,type(namel))
# replace(原字符, 新字符)
# 替换字符串
str_old="1234567"
new_str=str_old.replace("123","000")
print(new_str)
# find(查找字符, 开始索引,结束索引值)查找字符串,找到返回开始索引值,没有找到返回‐1
ss_str="12345678"
print(ss_str.find("8"))
# index ‐‐>find区别在于,index如果没有找到则报错
ss_str="12345678888"
print(ss_str.index("8"))
# count(查询字符, 开始索引,结束索引值) 返回某个字符在指定范围出现次数
print(ss_str.count("0"))
# startswith(匹配字符, 开始索引,结束索引值) 判断是否以某个字符开头
print(ss_str.startswith("123"))
# endswith(匹配字符, 开始索引,结束索引值) 判断是否以某个字符结尾
print(ss_str.endswith("123"))
元组
tuple(元组)是不可变数据类型,元组写在()里,元素之间用,隔开,各元素类型
可以不相同。
创建空元组tup1=();
创建只包含一个元素的元组,元素后面加逗号 tup1=(12,)
元组跟字符串一样可以支持切片
元组中的元素是不允许修改,但是可以对元组进行连接
删除元组用del
元组运算符(+,*,in/not in)
# 定义元组,元组可以存储多个数据
tup1=(1,2,"abc",2.0)
print(type(tup1))
print(tup1)
# 创建空元组
tup2=()
print(type(tup2))
print(tup2)
# 只有一个元素的元组 1
tup3=(1,)
print(type(tup3))
# 获取元组中某个数据的值或者多个数据的值 ‐‐‐‐‐>切片
print(tup1[0],tup1[:‐1])
print(tup1[::‐1])
new_tup=tup1+tup3
print(new_tup)
del new_tup
# 元组运算符 + * 重复 in 存在 not in 不存在
new_tup=tup3*3
print(new_tup)
tup4=(1,2,3,4,5,6)
if 1 in tup3:
print("存在")
else:
print("不存在")
good="棒!"
print(good*10)
字典类型
"""
dict字典数据类型(可变数据类型): 可以存储多个元素,元素表示形式键值对方式 key:value
元素与元素之间通过,隔开
表示符 { key1:value1,key2:value2,....}
注意:1、key不可以重复的,否则取最后的值 key唯一值
2、key必须是不可变数据类型(number,string,tuple)
"""
info={"name":"修习人生","class":"M211期"}
# 字典中某个元素值 ---->字典不能通过索引位置值来进行取值 取值:变量名[key]
print(info["name"],info["class"])
print(info.get("name"))
# 修改元素的值 --->value
info["class"]="M212期"
info["adree"]="深圳"
print(info)
# 删除元素
del info["adree"]
print(info)
info1=info.copy()
info.clear()
print(info)
print(info1)
# 创建一个字典,key确定,值不太确定,设置value-->默认值null
keys=["name","class","adress","xz"]
info2=dict.fromkeys(keys,"null")
print(info2)
# 需要循环读取到字典中所有的数据key,value
for x,y in info1.items():
print(x,y)
# 字典合并 --->更新字典
print(info1)
add={"xz":18000,"qwxz":25000}
info1.update(add)
print(info1)
# 删除
print(info1)
# info1.pop("class") #根据key进行删除
# print(info1)
info1.popitem() # 默认删除最后一个元素
print(info1)
info1.clear()
print(info1)
del info1
list类型
"""
不可变数据
string:"" '' "
number:
元组:()
---可变数据----
列表:通过[],也可以存储多个数据,数据类型可以不一样,并且可以支持多种类型,
元素与元素之间也是通过,隔开
"""
list1=[1,2,3,4,"baby",[1,2,3],(1,2,3)]
print(list1)
print(type(list1))
# 获取列表中最后一个元素 某个位置元素 或者部分元素 -----》切片 变量名[开始索引:结束索引:步长]
print(list1[-1])
print(list1[:4])
del list1[0]
print(list1)
# 列表也是可以支持运算 + * in/not in
list1=list1+["hefan","dingdong"]
print(list1)
print(list1*3)
"""
list常见内置函数
操作:添加/删除/查找、修改 元素
"""
# 操作:添加元素append()
list2=[1,2,3,4,5]
list2.append(6) #做增加操作
print(list2)
# 增加0,最前面 insert(index,object)指定位置插入值
list2.insert(0,"大雨")
print(list2)
# 需要批量添加多个值到列表中 6,7,8,9,10
list2.extend([6,7,8,9,10])
print(list2)
# 删除
# list2.pop() #不传入索引值,则删除最后一个,否则删除指定索引值的元素 pop()返回删除的值
print(list2)
del_value=list2.pop(0)
print(del_value)
print(list2)
list2.clear() #清空列表
print(list2)
list3=[20,9,1,2,3,4,5,6]
copy_list=list3.copy()
print(copy_list)
list3.remove(6) #remove与pop区别? remove--根据值进行删除 pop---》根据索引删除
print(list3)
# 查找
print(list3.index(2) ) #查找到返回值的索引值,否则抛出异常
# 查找某个元素在列表中出现的次数
print(list3.count(1))
# 列表进行排序
list3.sort()
print(list3)
# 列表反转
list3.reverse()
print(list3)
set类型
"""
集合set类型:表示符{}--》字典{}?相同表示怎么区分?
可以存储多个元素,只支持不可变数据类型string,number,tuple
注意:
1、如何区分集合{}---》字典话,表示形式不一样的
2、元素类型 只支持不可变数据类型string,number,tuple,不支持可变数据类型(dict,set,list)
"""
set1={1,2,3,4,(1,2,3)}
print(set1)
print(type(set1))
# 创建空集合
null=set()
print(null)
print(type(null))
# # 获取集合某个元素或者多个元素 ?????
# print(set1)
# 运算
# 交集 A & B 取两个集合的相同元素
A={1,2,3,4,5}
B={6,7,8,9,10,5,4}
print(A,B)
new=A&B
print(new)
print("交集:",A.intersection(B))
# 并集 | 合并A、B集合,返回集合既包含A集合所有元素也会包含B集合的所有元素
new1=A|B
print(new1)
print("并集",A.union(B))
# 差集 A-B 返回A集合的所有元素,但是不会包含B中的元素
print(A-B)
print("差集",A.difference(B))
# 异或 ^ A^B 返回两个集合相同元素之外的其他元素的集合
print(A^B)
print("异或",A.symmetric_difference(B))
#
son={6,10}
print(son.issubset(A))
# 8、把元组(1,2,3,4,5,6)元素格式化成字符串
tupl=(1,2,3,4,5,6)
new=f"{tupl}"
new1="{0}".format(tupl)
print(new)
print(type(new))
python流程控制IF&循环语句
python常见运算符
Python语言支持以下类型的运算符:
1、算术运算符:+、-、、/、//、%、**
2、比较(关系)运算符:= =、!=、>、>=、<=
3、赋值运算符:=、+=、-=、=、%=、**=、//=
4、逻辑运算符:and or not
5、位运算符:
&
位与:参与运算的两个值,如果两个相应位都为1,则结果1,否则为0
|
位或:只要对应的二个二进位有一个为1,结果位为1
^
位异或:当两对应的二进位相异,结果为1
~
位取反:对数据的每个二进制位取反
<<
左移动:各二进位全部左移若干位,高位丢弃,低位补0
(> >)
右移动:各二进位全部右移若干位,
6、成员运算符:in 、not in
7、 in 判断值是否在序列中,在返回true,否则返回false,not in正好相反
8、身份运算符 :is、is not
is 判断是否引用同一个对象,x is y 类似id(x)=id(y) 与is not相反
if判断语句
1、if语句的语法格式:
If 条件1:
代码块1
else:
代码块2
score=float(input("请输入你的成绩:"))
if score>=60:
print("恭喜你")
else:
print("继续加油!")
多重if&if嵌套
Python中if语句的一般形式如下所示:
if 条件1:
代码块1
elif 条件2:
代码块2
…
else:
代码块N
score=float(input("请输入你的成绩:"))
if score<60:
print("不及格")
elif score>=85: #优秀生 A B C
if score>95:
print("A")
elif score>90:
print("B")
else:
print("C")
elif score>=75:
print("中等生")
else:
print("一般")
循环
1、while循环
while 语法格式:
执行语句
循环:重复做某件事情
三大要素:
循环变量—》while循环体改变循环变量
循环条件—》符合什么样条件,执行循环体,否则跳出循环体
循环体—》重复执行的操作+改变循环变量
num=1
while num<=100:
print(f"记住{num}知识点")
num+=1
else:
print("脑子浆糊了")
# 求和:1+2+3+4+4+...+100
# 循环变量:加数 1‐‐‐>100
# 循环条件:加数不能大于100 i<=100
i=1
sum=0
while i<=100 :
# 循环体:加法运算
# sum=sum+i
sum+=i
#改变循环体变量
i+=1
else:
print("循环结束了,1+2+3+4+4+...+100=",sum)
for循环
语法结构:
for 变量 in 序列:
执行语句1
else:
执行语句2
运行逻辑:
遍历序列(元组,列表,字典,字符串)中所有元素,每次遍历都会执行语句1
# 求和:1+2+3+4+4+...+100 ‐‐‐》for 1+2+3...+10
# range(n,m) 返回n~m整数列表,含头不含尾返回列表中包含n,不会包含m
sum=0
for x in range(1,101):
# sum=sum+x
sum+=x
print("1+2+3+....+100=",sum)
Python函数(必需参数&不定长参数&关键字参数&默认参数)
if条件语法结构
if 条件:
代码段1
else:
代码段2
if 条件1:
代码段1
elif 条件2:
代码段2
elif 条件3:
代码段3
…
else:
代码段3
循环语句
第一个循环语句:while循环
while 条件:
循环语句
else:
代码块1
第一个循环语句:for循环
for 循环变量 in 序列:
循环体语句
嵌套循环
都是支持的 for 嵌套while while嵌套for/while for 嵌套
for/while
跳出循环体 break
跳出本次循环 continune
pass 空语句 占位语句 作用确保程序结构的完整性
for x in range(1,11):
if x<=5:
continue #跳出本次循环
print(x)
#break #跳出整个循环
函数
1、什么是函数
函数是组织好的,可重复使用的,用来实现单一,
或相关联功能的代码段。—》实现代码封装的一种方式
2、函数定义
def 函数名(参数1,参数2,…):
函数体
return 返回值
3、函数调用 ----》执行函数体代码
函数名(参数值1,参数值2)
def hello():
print("hello zhidashu")
# 执行函数体代码‐‐‐》调用函数
hello()
def hello(name):
print("hello ",name)
hello("九头蛇")
函数类型
函数四种基本类型:无返回值返回None,否则返回值
有参数
无参数
有返回 函数体中 return 返回值
无返回 return或者没有return
1、无参数无返回
2、无参数有返回
3、有参数无返回
4、有参数有返回
参数传递
参数:
可变数据类型参数 list dict set 通过参数传递,可以改变参数值
不可变数据类型参数 string number tuple通过参数传递,
不可以改变参数值
# 不可变数据类型参数 list dict set 通过参数传递,不可以改变参数值
old=2
print(id(old))
def change(old):
old=10
print(id(old))
return old
change(2)
print(old)
print(id(old))
# 可变数据类型参数 list dict set 通过参数传递,可以改变参数值
def change_list(mylist):
mylist=mylist.append(10)
mylist=[1,2,3,4,5]
change_list(mylist)
print(mylist)
参数基本类型分为:
1必需参数
调用函数,传入参数必需与你定义函数参数个数及类型一致
2关键字参数
3默认参数
4不定长参数
# 必需参数
def info1(name,age):
print(f"欢迎{name}来到码尚学院VIP课堂,姓名:{name},年龄:{age}")
# 调用函数
name="Dong"
age=18
info1(name,age) #必需参数
def info2(name:str,age:int,classname,adress,score):
print(f"欢迎{name}来到码尚学院VIP课堂,姓名:{name},"
f"年龄:{age},其他信息({classname},{adress}{score})")
classname="M211"
adress="深圳"
score="100"
info2(name,age,classname,adress,score) #必需参数 按照定义顺序定义参数个数
# 关键字参数 不按顺序传参
# 允许函数调用时参数顺序与声明不一致
info2(adress="北京",age=19,classname="M210",name="九头蛇",score="60")
# 默认参数 定义+调用函数
# 定义函数时进行默认值赋值
def info3(name:str,age:int,adress,score,classname="M211"):
print(f"欢迎{name}来到码尚学院VIP课堂,姓名:{name},"
f"年龄:{age},其他信息({classname},{adress}{score})")
# 调用
# 设置默认值函数 是否可以通过关键字参数进行调用或者必需参数调用 可以
#默认参数函数 默认参数可以不赋值 则取默认值
info3(name,age,adress,score)
# 默认参数能否赋值 可以 调用方式 基于必需参数 关键字参数
info2(adress="北京",age=19,classname="M21O",name="笑褒",score="100")
# 不定长参数:你可能需要一个函数能处理比当初生命是更多的参数,
# 这些参数叫做不定长参数
# 有这么几种形式
# *参数‐‐‐‐》把多个参数基于元组方式进行存储
# **参数‐‐‐‐》把多个参数基于字典方式进行存储
# *单独出现 后面的参数通过关键字传参
# 实现求几个数的和 几个数? ‐‐‐没法确定
def sum(a,b):
return a+b
# 求和方法 2/3,4,5,6...个数之和
def sum(*num):
print(num) #num元素就是每个参数值
print(type(num)) #元组
# 求和操作
sum=0
for x in num:
sum+=x
print(sum)
return sum
# pass #空语句
sum(2,3)
sum(2,3,4,5,7,65,90)
def sum2(**num):
print(num)
print(type(num))
sum2(a=1,b=2,c=3,d=4,e=5)
def sum3(num1,num2,*,num3):
return num2+num1+num3
print(sum3(1,2,num3=3))
函数嵌套&递归函数&文件操作
函数嵌套
1)调用嵌套
2)定义嵌套
匿名函数
格式:
lambda 参数1,参数2,…:表达式
递归函数
递归函数:重复进行调用某个函数,直到不符合某个条件,结束调用
文件操作
Python open() 方法用于打开一个文件,并返回文件对象,在对文
件进行处理过程都需要
使用到这个函数
格式:open(file_name,access_mode,buffering)
file_name:文件路径。
access_mode:打开文件的模式。只读,写入,追加等,默认文件
访问模式为只读®。
文件访问模式:
r(read) rb rb+ r+
w(write) wb wb+ w+
a(add追加) a a+ ab+
b(binary 二进制)
r 以只读方式打开文件。文件的指针将在文件开头。这是默认模式。
rb 以二进制格式打开一个文件用于只读。一般用于非文本文件如图片等
r+ 打开一个文件用于读写(文件的指针将在文件开头)
w 打开一个文件只用于写入,如果文件存在,删除重新编辑,否则新建
wb 以二进制格式打开一个文件只用于写入
w+ 打开一个文件用于读写。如果文件存在,删除重新编辑,否则新建写入
a 打开文件追加内容,存在文件,在文件原内容后增加,否则新建写入
a+ 打开一个文件用于读写。存在文件,在文件原内容后增加,否则新建用于读写
ab 以二进制格式打开一个文件用于追加,存在文件,在文件原内容后增加,否则新建写入
ab+ 以二进制格式打开一个文件用于读写。存在文件,在文件原内容后增加否则新建用于读写
注意:一定记得关闭文件流对象
str1="""
python全栈自动化测试
Python基础
接口自动化
web自动化
app自动化
.....
"""
file=open("20210419_01.txt","w+",encoding="utf‐8")
file.writelines(str1)
时间日期模块&异常处理
OS模块
总结:
os模块----》对文件目录进行操作 -----》实现对文件目录操作与管理
1、创建删除修改重命名文件目录
2、获取项目目录路径
常用四个函数:
os.getcwd()
os.path.dirname(path)
os.path.join(path1,path2)
os.path.split(path1)
3、获取文件目录属性
4、修改查询文件权限
os.chmod(path_A, stat.S_IROTH)
文件权限有哪些?

# os.getcwd() 获取当前.py文件所在的项目路径‐‐‐》os.getcwd()
3 file_path=os.getcwd()
4 # 获取file_path上一级路径 ‐‐‐‐》os.path.dirname(path)
5 dirname=os.path.dirname(file_path)
6 print("目录路径:",dirname)
7 print("获取当前项目路径",file_path)
8 # 05时间模块异常处理‐‐>创建文件A 路径拼接 os.path.join(path1,path2)
9 path_A=os.path.join(file_path,"A")
10 print(path_A)
11 # os.mkdir(path_A)
12 # 路径拆分 目录+文件 ‐‐‐》os.path.split(path1)
13 path1="E:\VIP\M211\Code\class08\os模块应用.py"
14 new=os.path.split(path1)
15 print(new)
16
17 # 获取目录或者文件的访问权限
18 # Mode:os. F_OK(是否存在)、os.R_OK(可读 )、os.W_OK(可写)、os.X_OK(可执
行)
19 value=os.access(path_A,os.F_OK)
20 isread=os.access(path_A,os.R_OK)
21 iswrite=os.access(path_A,os.W_OK)
22 print(value,isread,iswrite)
23 # OTH 其他用户 GRP 用户组 USR拥有者 R 可读 X 可执行 W 可写
24 os.chmod(path_A, stat.S_IROTH)
time模块
Python编程中经常会用到time和datatime来处理日期和时间
时间戳:是指格林威治时间1970年01月01日00时00分00秒(北京时间
1970年01月01日08时00分00秒)起至现在的总秒数。
时间戳:1970年01月01日00时00分00秒到现在的总秒数
t = (2018,6,24,16,56,45,0,0,0)
#(年、月、日、时、分、秒、一周的第几日、一年的第几日、夏令时
<1(夏令时)、0(不是夏令时)、-1(未知),默认 -1>)
总结:time ----》处理时间
时间戳 获取总秒数
时间元组—》9个元组 年月日…
常用函数:
获取时间元组 time.localtime()
获取时间戳 time.time()
把时间元组转化成时间戳:time.mktime(时间元组)
把时间戳转化时间元组:time.localtime(时间戳)
字符串与时间元组相互转化
时间元组-》字符串:time.strftime()
字符串–》时间元组:time.strptime()
1 # 获取获取现在的时间戳
2 zs=time.time()
3 print(zs)
4 # 1619010965.6694999
5 # 1619010991.0435
6 # 获取现在的时间元组
7 time_tuple=time.localtime()
8 print("获取现在的时间元组:",time_tuple)
9 # 获取当前月份 多少号 星期几 ?
10 month=time_tuple.tm_mon
11 day=time_tuple.tm_mday
12 weekday=time_tuple.tm_wday
13 print(month,day,weekday)
14 # 周日 6 周六 5 周五 4 周四 3 周三 2 周二 1 周一 0
15 # Wed Apr 21 21:23:08 2021
16 print(time.asctime())
17 # 1619010965 转时间元组
18 ttup1=time.localtime(1587546210)
19 print(ttup1)
20 # 时间元组转化时间戳
21 secs=time.mktime(ttup1)
22 print("时间元组转化为时间戳time.mktime:",secs)
23 #字符串与时间元组相互转化
24 # 时间元组‐‐‐‐》字符串
25 timestr=time.strftime("%Y/%m/%d %H:%M:%S",time.localtime())
26 print(timestr,type(timestr))
27 # 输出日志 报告 文件名称后面时间
28 filepath=f'log_{time.strftime("%Y_%m_%d_%H_%M_%S",time.localtime())}'
29 with open(filepath,"w+",encoding="utf‐8") as file:
30 file.write("笑褒 九头蛇")
31 # 时间格式字符串 2021/04/21 21:36:41 ‐‐‐‐‐》时间?
32 ttup2=time.strptime(timestr,"%Y/%m/%d %H:%M:%S")
33 print("字符串转化时间元组time.strptime(string,format):",ttup2)
datetime模块
时间元组表示
dt=datetime.datetime(2018,6,24,16,56,45,13) #(年、月、日、时、
分、秒、微秒) #以时间元祖创建
dt=datetime.datetime.today() #获得当前时间datetime
dt=datetime.datetime.now() #获得当前时间datetime
把datetime转换成时间戳
datetime.datetime.now().timestamp()
把时间戳转换成datetime
datetime.datetime.fromtimestamp(时间戳)
按datetime转换成字符串:
dt.strftime(“%Y-%m-%d”)
dt.strftime(“%Y-%m-%d %H:%M:%S”)
把字符串转换成datetime
datetime.datetime.strptime(‘2015-6-1 18:19:59.10’, ‘%Y-%m-%d
%H:%M:%S.%f’)
截取时间元组中的部分:
dt.year #年
dt.month #月
dt.day #日
dt.date() #日期
dt.time() #时间
dt.weekday() #星期
dt.isoweekday() #星期
异常处理
异常处理:可以使用try except语句来捕获所有异常
语法格式1:
try:
执行代码
except:
发生异常执行的代码
else:
没有异常执行的代码
语法格式2:------》指定异常类别,捕获异常
try:
file1=open(‘2.txt’)
s=file1.readline()
i=int(s)
excep ValueError as err2:
print(‘ValueError:{0}’.format(err2))
except OSError as err:
print(‘OSError:’.format(err))
except:
print(‘unexcept error’, sys.exc_info())
语法格式3:---------》try-finally 语句无论是否发生异常都将执行最
后的代码。
try:
执行代码
except:
发生异常执行的代码
else:
没有异常执行的代码
finally:
不管有没有异常都会执行的代码
try:
2 uername=input("请你输入你的账号!")
3 passwd=input("请你输入你的密码!")
4 if uername=="admin" and passwd=="123456":
5 print("登录成功")
6 else:
7 print("登录失败")
8 money=int(input("请输入取款金额"))
9 except:
10 print("有异常")
11 else:
12 print("请执行下一步")
13
14 try:
15 uername=input("请你输入你的账号!")
16 passwd=input("请你输入你的密码!")
17 if uername=="admin" and passwd=="123456":
18 print("登录成功")
19 else:
20 print("登录失败")
21 money=int(input("请输入取款金额"))
22 except Exception as error:
23 print("类型。。。。",str(error))
24 else:
25 print("无异常继续执行取款的下一步操作......")
抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise语法格式如下:
raise [Exception [, args [, traceback]]]
x=10
2 if x > 5:
3 raise Exception('x 不能大于 5。x 的值为: {}'.format(x))
4 print("其他业务代码执行")
面向对象编程(类&对象&属性&方法)
面向对象概念
Python是一门面向对象编程的语言
封装:提高代码复用性,便于维护 —》 函数 类
面向对象编程,最常见的表现就是基于类来表现
1、什么是类( class)
人类:中国人 美国人 日本人 集合(一群对象)
动物类:
…类
类:类用来描述具有相同属性和方法对象的集合
类抽取一群对象中的相同属性+相同行为
类=属性+行为
属性:特征(姓名 头 …)
方法:行为(吃 睡 说话…)
什么对象
世间万物都可以为对象,对象是类的实例
什么是类
类:类用来描述具有相同属性和方法对象的集合
构造方法
类有一个名为 _ _ init_ _() 的特殊方法(构造方法),该方法在类实例
化时会自动调用。
类的属性
1、类属性
类属性:相当于全局变量,实例对象共有的属性
2、实例属性:实例对象自己私有。
3、内置属性:
类名._ dict __ : 类的属性(包含一个字典,由类的数据属性组
成)
类名._ doc__ :类的文档字符串
类名.__ name__: 类名
类名.__ module__: 类定义所在的模块(类的全名
是’__ main__.className’,如果类位于一个导入模块mymod中,那么
className.__ module__ 等于 mymod)
类名.__ bases__ : 类的所有父类构成元素(包含了一个由所有
父类组成的元组)
class people:
2 """描述一个中国人类"""
3 fuse="yellow" #类属性1
4 language = "chain" # 类属性2
5
6 # 构造方法‐‐‐》名字特殊 __init__ 调用特殊:实例化时调用
7 # 什么时候会重构构造方法‐‐‐》初始化数据
8 def __init__(self,name,classname):
9 print(f"实例化了一个对象,她的名称{name},班级{classname}")
10 self.name=name #实例属性:实例对象自己私有。‐‐‐》self.name self.classname
11 self.classname=classname
12
13
14 # 定义行为? 说话 睡觉
15 def speak(self):
16 print(self,type(self))
17 print("我说就是中国话")
18
19 # DD 类的实例化‐‐‐》对象
20 # 初始化数据 名称:DD 班级:211
21 DD=people("DD","211")
22 DD.speak()
23 print("获取DD同学的特征",DD.language,DD.fuse)
24
25 # hefan 对象
26 hefan=people("hefan","210")
27 # 初始化数据 名称:hefan 班级:210
28 hefan.speak()
29 print("获取hefan同学的特征",hefan.language,hefan.fuse)
30 # 类属性: fuse="yellow" #类属性1
31 # language = "chain" # 类属性2
32 print("类属性可以通过对象或类来获取:",people.fuse,DD.fuse)
33 print("类属性可以通过对象或类来获取:",people.language,hefan.fuse)
34 # 实例属性
35 print("实例属性只能通过对象来调用:",hefan.name)
36 # print("实例属性不同通过类去获取:",people.name)
37 # 内置属性 底层每个类都有的这些数据,不同的内置属性存储不同的数据
38 print(people.__doc__)
39 print(people.__name__)
40 print(people.__module__)
方法
1、实例方法:使用 def 关键字来定义一个方法,与一般函数定义
不同,类方法必须包含参数 self,
且为第一个参数,self 代表的是类的实例。实例方法只能被实例对
象调用
2、静态方法:由@staticmethod装饰的方法,没有self这个参数,
而将这个方法当成一个普通的函数使用。
可以被类或类的实例对象调用
3、内置方法
指定的方法名,去执行特定业务
方法名有规则:方法名前后有双下划线
比如:__ init __
4、私有方法
class people:
3 """描述一个中国人类"""
4 fuse="yellow" #类属性1
5 language = "chain" # 类属性2
6
7 # 构造方法‐‐‐》名字特殊 __init__ 调用特殊:实例化时调用
8 # 什么时候会重构构造方法‐‐‐》初始化数据
9 def __init__(self,name,classname):
10 print(f"实例化了一个对象,她的名称{name},班级{classname}")
11 self.name=name #实例属性:实例对象自己私有。‐‐‐》self.name self.classname
12 self.classname=classname
13
14 #静态方法‐‐‐》公共方法:类和对象公用
15 @staticmethod
16 def static_method():
17 print("这是一个静态方法")
18
19 # 类方法‐‐‐‐》公共方法:类和对象公用
20 @classmethod
21 def class_method(cls):
22 print(cls,type(cls))
23 print("这是一个类方法")
24
25 # 定义行为? 说话 睡觉 ‐‐‐‐》实例方法
26 def speak(self):
27 print(self,type(self))
28 print("我说就是中国话")
29
30 def __str__(self):
31 return "欢迎来到码尚学院VIP‐211期"
32
33 def __getattribute__(self, item):
34 if item=="name":
35 return "名称"
36
37 # def __del__(self):
38 # print("调用del方法,释放对象的内存地址")
39
40 # people.static_method()
41 DD=people("DD","211")
42 print(DD.name)
43 # # DD.static_method()
44 # people.class_method()
45 # DD.class_method()
私有属性及私有方法
1、私有属性
必须以爽下划线开头,只能类内部进行访问
2、私有方法
必须以爽双下划线开头,只能类内部进行调用
私有属性+私有方法
属性名:__ 私有属性名
私有方法:__ 私有方法名
class people:
3 """描述一个中国人类"""
4 fuse="yellow" #类属性1
5 language = "chain" # 类属性2
6 __weight=90
7
8 # 构造方法‐‐‐》名字特殊 __init__ 调用特殊:实例化时调用
9 # 什么时候会重构构造方法‐‐‐》初始化数据
10 def __init__(self,name,classname):
11 print(f"实例化了一个对象,她的名称{name},班级{classname}")
12 self.name=name #实例属性:实例对象自己私有。‐‐‐》self.name self.classname
13 self.classname=classname
14
15 def __speakmimi(self):
16 print("这是一个私有方法")
17
18
19 # 定义行为? 说话 睡觉
20 def speak(self):
21 print(self,type(self))
22 print("我说就是中国话")
23 print("告诉一个秘密,我的体重是:", self.__weight)
24 self.__speakmimi()
25
26 xingji=people("xingji","M211")
27 # print(xingji.__weight)
28 xingji.speak()
29 # print(xingji.__weight)
30 # xingji.__speakmimi
31
32 print("私有属性及私有方法只能类内部使用,实例对象或类不可以在外部使用,"
33 "但是可以通过此种格式调用:对象._类名+私有属性/私有方法")
34
35 print("1外部获取私有属性",xingji._people__weight)
36 print("2外部获取私有方法:")
37 xingji._people__speakmimi()
模块导包
from 模块 import 方法
from 上级模块 import 下一级模块
import 模块
main()main函数是调试代码的入口函数
也就是执行当前模块会执行,其他模块调用不会执行
面向对象特征:封装
封装:面向对象编程的第一步 将属性和方法封装到一个抽象的类中,外界使用类创建对象,然后让对象调用方法,对象方法的细节都被封装在类的内部
"""
2 需求:小明爱跑步
3 1.小明体重75.0公斤 属性 ‐‐>
4 2.每次跑步会减肥0.5公斤 行为
5 3.每次吃东西体重会增加1公斤 行为
6 4.小美的体重是45.0公斤 属性
7 """
8 # 定义一个类来进行表示 小明 小美
9 class julebu:
10
11 def __init__(self,name,weight):
12 self.name=name
13 self.weight=weight
14
15 def eat(self):
16 self.weight +=1
17 print(f"每次吃东西体重会增加1公斤,你现在的体重{self.weight}")
18 pass
19
20 def pao(self):
21 self.weight‐=0.5
22 print("每次跑步会减肥0.5公斤,现在体重",self.weight)
23
24
25 xming=julebu("小明",75)
26 xming.pao()
27 xming.eat()
28 print(xming.weight)
29 xmei=julebu("小美",45)
30 xmei.pao()
31 xmei.pao()
32 xmei.eat()
33 print(xmei.weight)
34 c=julebu("cc",120)
35 c.pao()
c.eat()
37 c.eat()
38 print(c.weight)
39
40 # 一、
41 # # 1、摆放家具
42 # # 需求:
43 # # 1)房子有户型,总面积和家具名称列表 房子‐‐‐》 属性 面积和家具名称列表
44 # # ?? ?新房子没有任何的家具 初始化时候特征
45 # # 2)家具有名字和占地面积,其中 家具对象 ‐‐‐‐》属性:名字和占地面积
46 # # ?? ?床:占4平米 ‐ 床 属性:面积
47 # # ?? ?衣柜:占2平面 衣柜 属性:面积
48 # # ?? ?餐桌:占1.5平米
49 # # 3)将以上三件家具添加到房子中 行为
50 # # 4)打印房子时,要求输出:户型,总面积,剩余面积,家具名称列表 ‐‐‐》 获取属性
51
52 # 分析对象相同属性及行为 及这些对象存在逻辑关系
面向对象特征之二:继承
继承:实现代码的重用,相同的代码不需要重复的写,子类继承父类及父类的父类的属性和
方法
基类:父类
派生类:子类
继承:分为单继承和多继承
1、单继承
class 类名(父类):
类主体
#单继承
2 class Anmail:
3 #属性
4 def __init__(self,name,age):
5 self.name=name
6 self.age=age
7 #方法
8 def eat(self):
9 print('父类方法:吃')
10
11 def sleep(self):
12 print('父类方法:睡')
13
14 def speak(self):
15 print('父类方法speak()')
16
17 def __private(self):
18 print('这是一个私有方法')
19
20
21 class Cat(Anmail):
22 pass
23
24 # 重写父类的方法
25 def speak(self):
26 # 调用父类的方法,并且还需要进行扩展
27 Anmail.speak(self)
28 #子类扩展
29 print('子类扩展')
30
31 class Dog(Anmail):
32 pass
33
34 miao1=Cat('jiafeimiao',5)
35 dog1=Dog('hh',2)
36 miao1.eat()
37 miao1.speak()
38 # jiafeimiao.__private()
39 # 判断某个实例是否是某个类的实例
40 print(isinstance(miao1,Cat))
41 print(isinstance(dog1,Cat))
42 # 判断参数1是否为参数2的子类
43 print(issubclass(Cat,Anmail))
多继承
class 类名(父类1,父类2,父类3):
类主体
注意:多继承,采用就近原则,从左到右
#多继承
3 class Anmail:
4 #属性
5 def __init__(self,name,age):
6 self.name=name
7 self.age=age
8 #方法
9 def eat(self):
10 print('父类方法:吃')
11
12 def sleep(self):
13 print('父类方法:睡')
14
15 def speak(self):
16 print('父类方法speak()')
17
18 def __private(self):
19 print('这是一个私有方法')
20
21 class Cat:
22 pass
23
24 def speak(self):
25 print('喵喵。。。。')
26
27 class JiaFeiCat(Cat,Anmail):
28 pass
29
30 jiafeicat1=JiaFeiCat('jiafeicat1',2)
31 jiafeicat1.speak()#先回调用Cat类中的speak方法,如果没有再去找下一个父类是否有
次方法
注意:1、子类调用方法,先找自己,然后再去找父类,再找父类的父类,依次类推
2、子类不能继承父类及父类的父类的私有属性及方法
3、能写父类方法
1、覆盖父类方法 子类中重写父类的方法
2、扩展父类方法
父类名.方法名(self) 调用父类的方法
面向对象第三大特征:多态
多态:不同的子类对象调用相同的方法,产生不同的执行结果(呈现出多态的形态)
class zfb:
3 '''支付宝支付'''
4
5 def zhifu(self):
6 print('支付宝支付')
7
8 class yl:
9 '''银联支付'''
10
11 def zhifu(self):
12 print('银联支付')
13
14 def pay(object):
15 object.zhifu()
16
17 # 支付宝支付
18 zfb=zfb()
19 pay(zfb)
20 yl=yl()
21 pay(yl)
配置文件ini及YAML格式文件处理
一、什么是ini文件
后缀名.ini 用于存储项目全局配置变量
比如:接口地址 项目地址…输出文件路径
二、ini文件编写格式
[节点]
选项=选项值
注释前面加;
注意:节点不可以重复
三、ini文件读取
1 import configparser
2
3 config=configparser.ConfigParser()
4 config.read("config.ini",encoding="utf‐8")
5 # 获取ini文件中所有的节点
6 sections=config.sections()
7 # 获取ini文件中某个节点下所有选项
8 options=config.options(section="database")
9 # 获取某个节点下某个选项的选项值
10 value=config.get(section="database",option="username")
11 # 获取某个节点下的所有选项及选项值 ‐‐‐》元组列表
12 values=config.items(section="database")
13 print(sections)
14 print(options)
15 print(values)
16 print(value)
ini文件的编辑(写入或者修改)
1
2 """
3 ini文件编辑:
4 1、写入一个节点
5 2、写入选项及选项值
6 3、删除节点
7 4、删除选项及选项值
8 """
9 # 写入一个节点
10 new_section="userinfo1"
11 if new_section not in sections:
12 config.add_section("userinfo1")
13 # 给某个节点添加选项及选项值
14 config.set(section="userinfo1",option="username",value="hefan")
15 config.set(section="userinfo1",option="passwd",value="hefan")
16 # file=open("config.ini","w+")
17 # config.write(file)
18 # file.close()
19 with open("config.ini","w+") as file:
20 config.write(file)
21
22 # 删除节点
23 del_section="userinfo1"
24 print(sections)
25 if del_section in sections:
26 config.remove_section(section=del_section)
27 with open("config.ini","w+") as file:
28 config.write(file)
29 # 删除选项及选项值
30 config.remove_option(section="userinfo",option="passwd")
31 with open("config.ini","w+") as file:
32 config.write(file)
yaml文件处理
1、什么yaml文件
YAML 是一种灵活的数据格式,支持注释、换行符、多行字符串、裸字符等
在自动化过程中,我们很多地方都需要使用配置文件来储存数据
比如测试环 境,数据库信息、账号信息、日志格式、日志报告名称等。
其中,yaml文件是最常用的配置文件类型之一,相比较ini,conf配置文件
来说,它更加简洁,操作更加简单,同时还可以存放不同类型的数据。
后缀名:.yaml .yml
2、yaml支持哪些数据类型
对象、
数组、
纯量 字符串 数值 bool
3、YAML编写格式语法规则
大小写敏感
使用缩进表示层级关系
缩进用空格,相同的层级元素左对齐即可
#表示注释
yaml文件的读取 反序列化:从文件转换为Python对象
第三方库 PyYAML
import yaml
2
3 with open("yaml_5.yml","r") as file:
4 data= yaml.load(stream=file, Loader=yaml.FullLoader)
5 print(data)
yaml另外一种操作:yaml写入数据
纯量、对象、数组(Python对象) -----》yaml文件 序列化(持久化)
modules=["中文","pytest","unittest","requests","requests"]
2 with open("modules.yaml","w+") as file:
3 yaml.dump(data=modules,stream=file,allow_unicode=True,encoding="utf‐8")
excel文件处理及日志处理
xlrd xlwt pandas openpyxl第三方库
安装第三方库openpyxl:
pip install openpyxl
openpyxl模块
openpyxl模块三大组件:
1、工作簿 包含多个sheet(工作表)
2、工作表 某个数据包含在某个工作表
3、单元格
import openpyxl
2
3 """
4 Excel的处理:
5 1、创建Excel文件
6
7 """
8
9 def createExcel():
10 """
11 创建创建Excel文件,并写入数据
12 :return:
13 """
14 # 创建工作簿
15 wk=openpyxl.Workbook()
16 # 获取当前工作表
17 sheet=wk.active
18 # 写数据到单元格
19 sheet.cell(1,1).value="username"
20 sheet.cell(1, 2).value = "class"
21 sheet.cell(1, 3).value = "adress"
22 wk.save("userinfo.xlsx")
23
24 """
25 2、读取Excel文件
26
27 """
28 def readExcel(filepath):
29 # 获取工作簿
30 wk=openpyxl.load_workbook(filepath)
31 # 方式一:获取工作表
32 # sheet1=wk.get_sheet_by_name("Sheet")
33 # 方式二:获取工作表
34 sheet1=wk["Sheet"]
35 # 获取单元格坐标
36 location=(sheet1.cell(5,1))
37 # 获取单元格值
38 value=sheet1.cell(5,1).value
39 print(location,value)
40 #获取工作表行数及列数
41 rows=sheet1.max_row
42 cols=sheet1.max_column
43 print(f"行数:{rows},列数:{cols}")
44 datalist=[]
45 #读取工作表中所有数据?
46 # 循环excel每一个行
47 for row in range(1,rows+1):
48 #循环列数,并取值
49 for col in range(1,cols+1):
50 value=sheet1.cell(row,col).value
51 datalist.append(value)
52 return datalist
53
54
55 def printDataExcel(filepath):
56 data=readExcel(filepath)
57 print(data)
58
59 """
60 2、编辑Excel文件
61 1、添加一个新的sheet
62 2、修改某个单元格数据
63
64 """
65 def editExcel(filepath):
66 # 加载工作簿
67 wk=openpyxl.load_workbook(filepath)
68 #创建新的工作表
69 mysheet=wk.create_sheet("mysheet")
70 mysheet.cell(1,1).value="username"
71 mysheet.cell(2, 1).value = "DD"
72 # 编辑后记得保存
73 wk.save(filepath)
74
75
76 if __name__ == '__main__':
77 editExcel("userinfo.xlsx")
、日志收集
1、什么是日志
日志跟踪软件运行时事件的方法(跟踪器)
2、日志作用
问题地位
信息查询
数据分析
3、内置模块 logging
logging的四大组件:
1、日志器 Logger —>入口
2、处理器 Handler—》执行者 决定日志在不同端进行输出 ( 日志文件 控制
台)
3、格式器 Formatter—》日志输入的内容
4、过滤器 Filter----》输出感兴趣日志信息,过滤掉不感兴趣的日志信息
关系:1个日志器可以有多个处理器,
每个处理器可以各自的格式器及过滤器
4、logging模块的应用
从低到高日志级别:
debug 调试信息
info 关键事件描述
warning 警告信息
error 错误信息
critical 严重错误信息
# 创建日志器
2 logger = logging.getLogger("logger")
3 # 日志输出当前级别及以上级别的信息,默认日志输出最低级别是warning
4 logger.setLevel(logging.INFO)
5 # 创建控制台处理器‐‐‐‐》输出控制台
6 SH = logging.StreamHandler()
7 # 创建文件处理器‐‐‐‐》输出文件
8 FH = logging.FileHandler("log.txt")
9
10 # 日志包含哪些内容 时间 文件 日志级别 :事件描述/问题描述
11 formatter = logging.Formatter(fmt="[%(asctime)s] [%(filename)s] %(leveln
ame)s :%(message)s",
12 datefmt='%Y/%m/%d %H:%M:%S')
13 logger.addHandler(SH)
14 logger.addHandler(FH)
15 SH.setFormatter(formatter)
16 FH.setFormatter(formatter)
17
18 try:
19 score = int(input("请你输入你的成绩"))
20 if score > 60:
21 print("恭喜你通过")
22 else:
23 print("继续努力")
24 logging.debug("这是一个debug信息")
25 logger.info("你查询成绩成功")
26 logger.warning("这是一个警告信息")
27
28
29 except Exception as error:
30 logger.error("输入不是数字,错误信息:" + str(error))
31 logger.critical("这是一个critical信息")
重复日志输出的原因
调用一次函数 就会重复添加处理器
解决方案:添加日志器和处理器前做判断是否已经存在
import logging
3
4 class FrameLog:
5
6 def getLogger(self):
7
8 # 创建日志器
9 logger = logging.getLogger("logger")
10 # 日志输出当前级别及以上级别的信息,默认日志输出最低级别是warning
11 if not logger.handlers:
12 logger.setLevel(logging.INFO)
13 # 创建控制台处理器‐‐‐‐》输出控制台
14 SH = logging.StreamHandler()
15 # 创建文件处理器‐‐‐‐》输出文件
16 FH = logging.FileHandler("log.txt")
17
18 # 日志包含哪些内容 时间 文件 日志级别 :事件描述/问题描述
19 formatter = logging.Formatter(fmt="[%(asctime)s] [%(filename)s] %(level
name)s :%(message)s",
20 datefmt='%Y/%m/%d %H:%M:%S')
21 logger.addHandler(SH)
22 logger.addHandler(FH)
23 SH.setFormatter(formatter)
24 FH.setFormatter(formatter)
25
26 return logger
27
28 def sum(self,*args):
29 """
30 求多个数之和
31 :param args:
32 :return:
33 """
34 try:
35 sum=0
36 for num in args:
37 sum+=num
38
39 self.getLogger().info(f"计算多个数之和={sum}")
40 return sum
41 except Exception as error:
42 self.getLogger().error("计算多个数之和有异常:\n"+str(error))
43
44
45 def sum_two(self,x,y):
46 """
47 求两个数之和
48 :param args:
49 :return:
50 """
51 try:
52 sum=0
53 sum=x+y
54 self.getLogger().info(f"计算多个数之和={sum}")
55 return sum
56 except Exception as error:
57 self.getLogger().error("计算多个数之和有异常:\n"+str(error))
58
59 def sum_three(self,x,y,z):
60 """
61 求两个数之和
62 :param args:
63 :return:
64 """
65 try:
66 sum=0
67 sum=x+y+z
68 self.getLogger().info(f"计算多个数之和={sum}")
69 return sum
70 except Exception as error:
71 self.getLogger().error("计算多个数之和有异常:\n"+str(error))
72 # 常见一个问题
73 if __name__ == '__main__':
74 # logger添加一个文件处理器和一个控制台处理器
75 FrameLog().sum(1,2,3)
76 # logger添加2个文件处理器和2个控制台处理器
77 FrameLog().sum_two(1, 2)
78 # logger添加3个文件处理器和3个控制台处理器
79 FrameLog().sum_three(1, 2,3)
python操作mysql数据库
操作mysql数据库常见第三方库
mysql-connector
pymysql
实现通过python操作mysql数据库
mysql-connector的基本应用
1、安装mysql-connector
2、mysql-connector的基本应用
mysql-connector操作mysql的步骤:
1、创建连接
2、创建游标实例
3、调用execute(参数1,参数2,参数3)处理数据库的操作
参数1:sql语句
参数2:类型为元组,元素值为sql语句占位符对应的参数
参数3:参数bool类型,第一个参数是不是多sql语句,如果是则传入True,否则传入False
1
2 import mysql.connector
3
4 """
5 mysql.connector基本应用
6
7 数据库:存储项目数据 验证数据‐‐‐》代码取数据库的数据来跟实际结果进行比对
8
9 1、连接数据库
10 2、创建流标实例
11 3、 调用游标实例的excute(sql) excute(sql,(values),bool) sql语句 数据库表常
见操作
12
13 """
14 # 1、连接数据库
15 def connect():
16 conn=mysql.connector.connect(
17 host="localhost",
18 user="root",
19 password="admin"
20 )
21 print(conn)
22 return conn
23
连接某个数据库
1
2 """连接指定某个数据库"""
3 def connect_database(database):
4 """
5 连接指定某个数据库
6 :param database: 数据库名称
7 :return:
8 """
9 conn=mysql.connector.connect(
10 host="localhost",
11 user="root",
12 password="admin",
13 database=database
14 )
15 print(conn)
16 return conn
创建数据库、创建表
def creatdatabase(databasename):
2 conn=mysql.connector.connect(
3 host="localhost",
4 user="root",
5 password="admin"
6 )
7 # 获取游标实例
8 cursor=conn.cursor()
9 sql=f"create database {databasename}"
10 cursor.execute(sql)
11 cursor.execute("show databases")
12 # 展示执行结果
13 for database in cursor:
14 print(database)
15
16 """
17 创建表
18 """
19 def createtable():
20 conn = mysql.connector.connect(
21 host="localhost",
22 user="root",
23 password="admin",
24 database="mashang_211"
25 )
26 # 获取游标实例
27 cursor = conn.cursor()
28 #创建表
29 sql = "create table user(id int auto_increment primary key ,name varcha
r(20),classname varchar(255))"
30 cursor.execute(sql)
插入数据到表
"""插入数据到表"""
2 def insertdata():
3 conn = mysql.connector.connect(
4 host="localhost",
5 user="root",
6 password="admin",
7 database="mashang_211"
8 )
9 # 获取游标实例
10 cursor = conn.cursor()
11 sql="insert into user(name,classname)values(%s,%s)"
12 svalue=("jing","M211")
13 cursor.execute(sql,svalue)
14 #提交
15 conn.commit()
16 rowcount=cursor.rowcount
17 print(f"{rowcount}行记录插入成功!")
18 cursor.execute("select * from user where name='zhangsan' ")
19 #查看返回结果
20 res=cursor.fetchall()
21 print(res)
22 print(type(res))
获取查询的结果数据
常用方法有:
fetchall()获取所有的记录
fetchone()获取第一行记录
fetchmany(size)获取前几行记录
1
2 def select_showall(database,sql):
3 """
4 查询数据,并返回查询结果
5 :param database:
6 :param sql:
7 :return:
8 """
9 conn=connect_database(database)
10 # 获取游标实例
11 cursor = conn.cursor()
12 cursor.execute(sql)
13 # 查看所有返回结果
14 allrows = cursor.fetchall()
15 # 返回第一条记录
16 onerow=cursor.fetchone()
17 # 返回多条记录
18 manyrow=cursor.fetchmany(3)
19 print(allrows)
20 print(type(allrows))
批量插入数据
executemany()方法,实现批量插入多条数据
第二参数是一个元组列表,包含我们插入的数据
1
2 """批量插入数据"""
3 def insertmany(database):
4 conn = connect_database(database)
5 # 2获取游标实例
6 cursor = conn.cursor()
7 sql="insert into user(name,classname)values(%s,%s)"
8 sqlvalues=[('huahua',"M211"),('DD',"M211"),("xiaoyang","M211")]
9 cursor.executemany(sql,sqlvalues)
10 # 提交
11 conn.commit()
12 rows=cursor.rowcount
13 print(f"{rows}行记录插入成功!")
14 select_showall(database,"select * from user")
防sql注入,一般sql语句中用占位符传值
1 databse2="mashang"
2 conn = connect_database(databse2)
3 mycursor=conn.cursor()
4 # 避免sql注入
5 sql="select * from vipinfo where name=%s"
6 sqlvals=("zhangsan",)
7 data=mycursor.execute(sql,sqlvals)
8 print(data)
三、PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2
中则
使用mysqldb。
我们可以使用命令安装最新版的 PyMySQL :
pip install PyMySQL
实现的逻辑跟mysql-connector一致,及相同的操作,操作方法一致
import pymysql
2
3 conn=pymysql.connect(host="localhost",user="root",password="admin",databa
se="mashang")
4 print(conn)
5 # 获取流标实例
6 mycursor=conn.cursor()
7 mycursor.execute("select * from vipinfo")
8 data=mycursor.fetchall()
9 print(data)
详解装饰器&反射原理及应用
一、装饰器
装饰器:装饰函数和类,作用:扩展增强函数和类的功能
@:语法糖
二、装饰器的分类
两大类:装饰器函数和装饰器类
三、装饰器函数定义及应用
函数:封装代码最小单元,提供代码复用性
装饰器函数利用函数的一些特征:
1、函数可以作为参数
3、函数可以作为变量
2、函数也可以返回函数
装饰器函数实质:调用装饰函数的内置方法
装饰器函数可以装饰所有的函数(有参数,没参数)
1 import time
2
3 """
4 """
5 # 装饰器函数
6
7 # 其他函数只要被装饰器函数装饰即可
8
9 def runTime(func):
10 """
11 装饰函数
12 原来功能+扩展的功能:统计每个函数的耗时多久
13 :return:
14 """
15 def wrapper(*args,**kwargs):
16 start = time.time()
17 # 原来功能
18 func(*args,**kwargs) # 原来功能
19 end = time.time()
20 cost = end ‐ start
21 print(f"统计函数[{func.__name__}]总共耗时{cost}秒")
22 return wrapper
23
24 @runTime
25 def welcome_vip():
26 """被装饰器函数"""
27 print("欢迎来到码尚学院VIP课堂")
28 time.sleep(1)
29
30 @runTime
31 def sum(*args):
32 sum=0
33 for num in args:
34 sum+=num
35 print(f"求和:{sum}")
36 return sum
37
38
39 welcome_vip() #实质:执行装饰函数的内置方法
40 sum(1,2,3,4,5,6,7,8,9,10)
装饰器类
装饰器类的实质:
调用装饰类中的_ call _内置函数
1
2 """
3 装饰器类
4
5 """
6 import time
7
8 # 定义装饰类‐‐‐‐‐》本质类 作用:原来功能+扩展功能
9 class A:
10 #原来功能 self._func()
11 def __init__(self,func):
12 self._func=func
13
14 #扩展功能
15 def __call__(self,*args,**kwargs):
16 """
17 __call__函数:实例化对象()
18 :return:
19 """
20 start = time.time()
21 # 原来功能
22 self._func() # 原来功能
23 end = time.time()
24 cost = end ‐ start
25 print(f"统计函数总共耗时{cost}秒1")
26
27
28 @A
29 def welcome_vip():
30 """被装饰器函数"""
31 print("欢迎来到码尚学院VIP课堂")
32
33 welcome_vip()
五、装饰器应用场景
常见的场景:授权及日志的收集
六、反射
把字符串映射到实例的变量或者实例的方法,
然后可以去进行调用、修改操作
反射四个重要的方法:
1、getattr 获取对象属性/方法
2、hasattr 判断对象是否有对应的属性
3、delattr 删除指定属性
4、setattr 为对象设置内容
class M211Vip:
2
3 def __init__(self,name,wkage):
4 self.name=name
5 self.wkage=wkage
6
7 def welcome(self):
8 print("恭喜加入组织")
9
10 def learning(self):
11 print("正在跟其他人拉开差距......")
12
13 def mylearning():
14 print("正在自学中....")
15
16 if __name__ == '__main__':
17 bo=M211Vip("波","3")
18 print(bo.name,bo.wkage) #实例属性
19 name=getattr(bo,"name") #把字符串映射到实例的变量
20 wkage=getattr(bo,"wkage")
21 method=getattr(bo,"learning") #映射到实例的方法
22 print(name,type(name))
23 print(wkage, type(wkage))
24 print(method,type(method))
25 # 执行方法
26 method()
27 if hasattr(bo,"learning"):
28 print("正在学习中....")
29 else:
30 print("正在加班中....")
31 # 2、hasattr判断对象是否有对应的属性
32 if hasattr(bo,"name"):
33 print("有name属性....")
34 else:
35 print("没name属性....")
36
37 #setattr 设置对象的内容(属性/方法)
38 setattr(bo,"name","波波") #修改对象的属性
39 name=getattr(bo,"name")
40 print(f"被修改的对象属性:{name}")
41 # 类的外部的函数映射到类里面的方法
42 setattr(bo,"mylearning",mylearning)
43 bo.mylearning()
44 getattr(bo,"mylearning")()
45 # 4、delattr删除指定属性
46 delattr(bo,"wkage")
47 print(bo.wkage)
1
2 #实现反射实现登录、退出、注销‐‐‐‐‐》关键字驱动
3 # excel ‐‐‐> open_brower close click input
4
5 class mashang:
6
7 def login(self):
8 print("正在登录.....")
9
10 def loginout(self):
11 print("正在退出.....")
12
13 def register(self):
14 print("正在注册.....")
15
16
17 def run(self):
18 """
19 1 login
20 2、loginout
21 3、register
22 :return:
23 """
24 fucslist=["login","loginout","register"]
25 num=int(input("请你输入操作数字:"))
26 methods=fucslist[num‐1]
27 action=getattr(self,methods)
28 action()
29
30 if __name__ == '__main__':
31 mashang().run()
基于工具Postman的接口自动化基础应用以及接口关联
一、什么是接口 ?
硬件接口:USB接口,投影仪接口,鼠标键盘接口。
软件接口:称为API,微信(腾讯公司):提现和充值。银行卡(银行系统),银联接口(想要调用必须拿到鉴权码:token,key,
appkey)。软件的接口主要使用与数据交互。
软件接口分类:
内部接口:开发人员开发一个系统,此系统提供了一些接口给本系统使用。特点:对于安全要求不高,外界访问不到。只需要测正例。
外部接口:
1.系统对外提供的接口:这种接口外部的用户是可以接触到,对安全性要求很高。
2.系统调用外部的接口:开发的电商系统需要支付宝和微信支付。只需要测正例。
二、为什么需要做接口测试?
集成阶段
国防科大:509的WEB集成框架。十几个子系统,首长决策子系统,预算子系统(生长曲线,二次方程,抛物线等),坦克管理子系统,飞机管理子系统。
1.前后端分离,子系统分离。
2.基于安全考虑
3.测试前移。
三、目前市面上的接口架构设计以及基于的协议
(1)基于SOAP的接口架构,它是一种轻量级的简单的基于XML的协议规范。
基于webservice协议,地址是以?wsdl结尾。是一种比较old的技术。soapui
(2)基于RPC的接口架构,它是一种远程调用,调用服务器的服务接口就和调用本地一样。
1.dubbo协议,阿里的rpc的框架。地址是以dubbo://,适合传输高并发数据量少的数据。
2.基于springcloud的微服务。
3.thrift,rmi,hessian
(3)基于RestFul的接口架构,主流,默认是使用的http协议。它默认使用json传输数据,它有一种约定规则(80%以上):
对于同样的一个接口地址:http://127.0.0.1/yuser,使用不同的请求方式得到的结果不一样。
get(查询用户),post(增加用户),put(修改用户),delete(删除用户)
四、http协议详解
(1)什么是http协议?
http协议是超文本传输协议,主要是用于浏览器和服务器之间交互数据,交互分为请求和响应两部分。请求:请求行,请求头,请求
正文数据。响应:响应行,响应头,响应正文数据。响应码:1XX信息,2XX请求成功,3XX重定向,4XX客户端错误,5XX服务器错
误。
请求:
请求行:POST /phpwind/index.php?m=u&c=login&a=dorun HTTP/1.1
请求头:
Host: 47.107.116.139
Connection: keep-alive
Content-Length: 112
Accept: application/json, text/javascript, /; q=0.01(客户端接收的数据类型)
X-Requested-With: XMLHttpRequest(ajax异步请求(不需要刷新),高速上有多条道,多线程)
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114
Safari/537.36(客户端类型)
Content-Type: application/x-www-form-urlencoded; charset=UTF-8(内容的格式)
Origin: http://47.107.116.139
Referer: http://47.107.116.139/phpwind/index.php?m=u&c=login
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: csrf_token=78e0caa2743c89fa; wNq_visitor=Nsb6UFT9aEsPxBlZw0XRqvIIZVOHaYgnTMt9rdP0EoY%3D;
wNq_lastvisit=697%091621428405%09%2Fphpwind%2Findex.php%3Fm%3Du%26c%3Dlogin%26a%3Dcheckname(Cookie
信息)
Cookie的原理:(清空本地的Cookie数据,然后按Shitf+F5去缓存刷新)
Cookie它不是缓存,它是保存在客户端的一小段的文本信息,格式是dict格式,

原理:当客户端第一次访问服务器的时候,那么服务器就会生成Cookie信息,这个Cookie信息会通过响应头里面的Set-Cookie传输
到客户端。从第2-N次请求,只要访问当前的域名和路径,那么客户端就会在请求头的Cookie里面自动的带上客户端的Cookie信息。
请求正文数据:

响应:
响应行
响应头
响应正文数据
五、接口返回的数据格式
1.json格式
JSON是一种数据格式,它由键值对和列表组成。
键值对:{key1:value1}
列表:[array1,array2]
接口开发的潜规则:{error_code:错误码,message:错误码的中文说明,data:[]}
2.html格式
3.XML格式
六、接口测试的流程和方案
1,拿到api接口文档(规范:swagger,showdoc,不规范:word文档,没有:抓包或录制,一般需要抓包或者录制的接口很有可能
只测正例),熟练接口业务,接口地址,接口鉴权,接口入参,接口出参,错误码。
头痛的面试题:在你们的这个项目(App)你测了哪些接口?凡是有数据交互的地方就有接口.。
例如:查询支付宝余额接口。查询芝麻分接口。
2.编写接口测试计划和方案(接口怎么测)。
思路:
正例:输入正常的入参,接口成功返回。
反例:
鉴权反例:鉴权码为空,错误的鉴权码,鉴权码过期。。。。
参数反例:参数为空,参数类型异常,参数长度异常,错误码异常…
其他场景:接口黑名单,接口调用次数,接口分页(0,1,中间页,最后一页)
其他场景:根据业务而定。
3.编写接口测试用例。
4.使用接口测试工具执行接口测试。
5.输出接口测试报告(HTML格式)
七、目前市面上的接口测试工具
Postman+newman+git+jenkins实现接口自动化。
newman是专为postman而生,主要用于和jenkins持续集成。
Jmeter+Ant+Git+Jenkins实现接口自动化。
Ant是Jmeter的插件,主要用于和jenkins持续集成。
其他工具:
soupui,apipost,fiddler,charles
八、微信公众号的接口测试
appID:wx6b11b3efd1cdc290 ID
appsecret:106a9c6157c4db5f6029918738f9529d 秘钥
九、Postman的安装和界面介绍
安装:在官网下载安装即可。
mock server服务器。桩程序。(前后端分离,前端已经开发好了,后端的接口没有开发好,那么我们测试就可以自定义一个Mock
Server,前端访问Mock的接口去测试。)
十、Postman发送Get以及Post请求

Params:get请求传参。
Authorization:鉴权
Headers:请求头
Body:post请求传参

raw:传json,xml,javascript,txt.html
binary:把文件转化成二进制传参。
Pre-requests Script:接口请求之前的脚本。
Tests:接口请求之后的脚本。
Settings:设置。
Cookie:是Postman自动的管理Cookie信息的按钮。
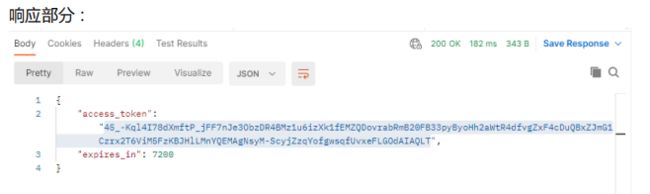
Body:响应的数据
Pretty:可以以json,xml,html,txt查看响应数据。
Raw:以文本的格式查看响应数据
Preview:以网页的形式查看响应数据
Cookies:响应的Cookie信息
Headers:响应头信息
Test Results:查看断言结果
状态码:200
状态信息:OK
接口数据返回耗时:182MS
接口返回的数据量:343个字节。
面试题:Get请求和Post请求有什么区别?
1.get请求是获取数据,而post请求一般都是提交数据。
2.post请求比get安全。
3.本质的区别是:传输的方式不一样,get在url的后面以?的方式传参,多个参数之间用&分隔。post是通过body表单传参
jenkins持续集成环境从0到1搭建全过程
jenkins下载以及JDK环境准备。
- jenkins官网下载地址:https://jenkins.io/download/ 目前稳定版本:
2.204.2
jenkins项目有两条发布线,分别是LTS长期支持版(或稳定版)和每周更新版
(最新版)。建议选择LTS长期支持版,下载通用java项目war包。

2.下载jdk1.8以上版本并安装,安装后配置jdk的环境变量。(这里不再累述具
体步骤)
二、jenkins安装
安装方式一: - 在Dos窗口中切换到"jenkins.war"目录。输入命令:java -jar
jenkins.war 安装。

安装方式二:
1.下载tomcat8以上版本,解压后把jenkins.war包放入解压后的webapps目
录。打开Tomcat下bin目录的startup.bat启动tomcat服务。(这里不再累述具
体步骤)
启动时发现dos窗口中有很多乱码,不影响运行,但是看着总是不舒服,解决方
案如下:我们来到tomcat目录的conf子目录中,找到一个名为
“logging.properties” 的文件,打开这个文本文件,找到如下配置项:
java.util.logging.ConsoleHandler.encoding = UTF-8
将 UTF-8 修改为 GBK,修改后的效果为:
java.util.logging.ConsoleHandler.encoding = GBK
保存后,重启tomcat!这时乱码已经解决了。
注意:两种安装方式都会在C盘目录下生成一个jenkins的文件夹。C盘下的这个
文件夹可独立运行。
(1)把jenkins.war包放入到C:/jenkins文件夹中,然后在C:/jenkins下新建一个
startjenkins.bat文件,输入如下内容:
@echo off
cd /d %JENKINS_HOME%
java -jar jenkins.war
pause
(2)设置环境变量:增加JENKINS_HOME变量,如下:
JENKINS_HOME:C:\jenkins
双击startjenkins.bat文件出现:jenkins is fully up and runing说明启动成功
jenkins了。
2.在浏览器中访问jenkins项目:http://localhost:8080/jenkins 出现解锁
Jenkins界面,说明jenkins项目搭建完成,这里需要输入管理员密码。如下图:

上图中有提示:管理员密码在:C:\jenkins\secrets\initialAdminPassword 打
开此文件获得密码并输入密码,第一种安装方式点击”继续”按钮后如出现如下
图的报错信息:这是jenkins的一个Bug,解决方案是:通过地址
http://localhost:8080访问jenkins项目即可。

点击:【选择插件来安装】(选择【安装推荐的插件】也可以),根据笔者的经
验选择【选择插件来安装】安装插件顺利些,选择后出现如下默认插件安装界面
这个页面会默认选中安装一些插件,直接点击”安装”按钮,安装所有推荐的插件。

等待所有插件安装完成(耐心等待1-2个小时)。安装插件的时候,会有一些插件
安装失败(如上图的X),这些插件的安装是有前置条件的,等安装结束后,按右下角“重试”,继续安装,之前失败的插件就都能安装了。安装完成后,点击“继续”按钮,
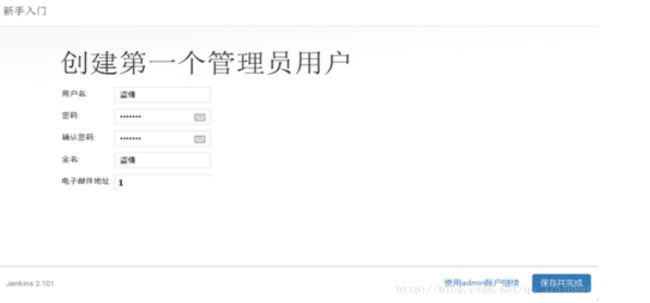
输入用户名:admin,密码:123456,确认密码:123456,全名:admin,
电子邮件地址后点“保存并完成”按钮

点击“保存并完成”出现下图表示jenkins已经配置完成。点击[开始使用
jenkins]登录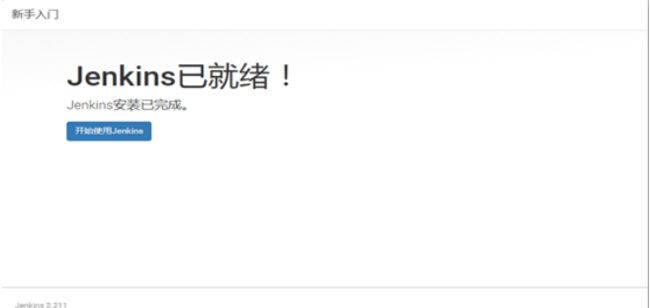
精通Postman接口测试之接口关联,动态参数,断言以及Postman+Newman+Jenkins持续集成
一、接口关联,接口依赖
下一个接口的参数是使用的上一个接口的返回值?
接口测试,接口自动化。
1.JSON提取器。(都是从返回值里面提取)
1 //javascript脚本,var定义变量
2 //打印responseBody返回值
3 console.log(responseBody)
4 //使用json提取器把responseBody返回值转化成一个字典。
5 var jd = JSON.parse(responseBody)
6 //提取access_token,并且设置为全局变量(就是在任何接口请求都可以访问的变量)
7 pm.globals.set("access_token",jd.access_token);
取得全局变量:{{access_token}}
2.正则表达式提取器(都是从返回值里面提取)
var token = responseBody.match(new RegExp('"access_token":"(.*?)"'));
2 pm.globals.set("access_token",token[1]);
3.从响应头里面中去提取
1 //从响应头里面提取变量
2 var types = postman.getResponseHeader("Content‐Type")
3 console.log(types)
4.从Cookie里面中去提取
1 //从Cookie里面提取变量
2 var csrf_token = postman.getResponseCookie('csrf_token');
3 console.log(csrf_token.value)
二、Postman的动态参数
接口测试中常常会出现接口的参数不能写死,必须使用随机数来实现。
1.内置的动态参数
{{KaTeX parse error: Expected 'EOF', got '}' at position 10: timestamp}̲} 时间戳 {{randomInt}} 随机的0-1000的整数
{{$guid}} 随机的很长的字符串
2.自定义动态参数(重点)
1 //自定义的时间戳
2 var times = Date.now();
3 pm.globals.set("times",times);
4 //让接口请求停留3秒(3秒灌水机制),time.sleep(3)
5 const sleep = (milliseconds) => {
6 const start = Date.now();
7 while (Date.now() <= start + milliseconds) {}
8 };
9 sleep(3000);
三、Postman的全局变量和环境变量
全局变量:就是在所有接口请求里面都可以访问的变量
环境变量:就是全局变量。(开发环境,测试环境,线上环境)
四、Postman的断言
//断言返回吗为200
//断言返回结果中包含指定的字符串
//断言并检查返回的JSON数据
//断言返回的值等于一个字符串
//断言响应头包含Content-type
//断言响应时间少于200M
1 //断言返回吗为200
2 pm.test("Status code is 200", function () {
3 pm.response.to.have.status(200);
4 });
5 //断言返回结果中包含指定的字符串
6 pm.test("Body matches string", function () {
7 pm.expect(pm.response.text()).to.include("string_you_want_to_search");
8 });
9 //断言并检查返回的JSON数据
10 pm.test("Your test name", function () {
11 var jsonData = pm.response.json();
12 pm.expect(jsonData.value).to.eql(100);
13 });
14 //断言返回的值等于一个字符串
15 pm.test("Body is correct", function () {
16 pm.response.to.have.body("response_body_string");
17 });
18 //断言响应头包含Content‐type
19 pm.test("Content‐Type is present", function () {
20 pm.response.to.have.header("Content‐Type");
21 });
22 //断言响应时间少于200MS
23 pm.test("Response time is less than 200ms", function () {
24 pm.expect(pm.response.responseTime).to.be.below(200);
25 });
特别注意:
1.postman内置的动态参数无法做断言。所以必须使用自定义的动态参数。
2.在tests里面不能使用{{}}的方法取全局变量,必须使用以下方式:
pm.globals.get(“times1”)
globals[‘times1’]
globals.times1
五、必须带请求头的接口如何测试
我不知道到底需要用到哪些请求头
六、Postman+newman+jenkins实现自动生成报告并持续集成。
Postman是接口测试而生
Newman是为Postman而生(新男人)
一、安装
1、安装Node.js
下载地址:https://nodejs.org/en/ 双击安装
验证:打开cmd,输入node出现>说明安装成功。
2.安装npm
打开cmd输入:npm install --global --production windows-build-tools
等待安装完成即可。
3.安装newman
打开cmd输入:npm install -g newman
验证:打开cmd输入newman -v 出现版本信息说明成功。
二、导出postman的测试用例,环境变量,全局变量
newman run “e:\yongli.json” -e “e:\huanjing.json” -g “e:\quanju.json” -r
cli,html,json,junit --reporter-html-export “e:\report.html”
-e 环境变量
-g 全局变量
-r cli,html,json,junit --reporter-html-export 测试报告输出的路径
三、和jenkins持续集成
1.构建:执行window批处理命令
2.构建后:Publish HTML Reports
精通Postman接口测试之接口鉴权,接口Mock,接口加解密以及接口签名Sign
一、接口鉴权(鉴定是否有访问接口的权限)
(1) cookie,session,token鉴权。
cookie鉴权:
cookie它是服务器产生的,保存在浏览器,主要是因为http协议无连接,无状态。(超市:没有会员卡,cookie:会员
卡)
cookie通过键值对的方式来保存记录。原理:第1次访问服务器的时候,那么服务器就会产生cookie并且在响应头的setcookie里面发送给浏览器,浏览器保存,在第2-N次请求时会带上cookie信息。
cookie一般包括信息:name,value,domain,path,expries,size。
回话级cookie和持久化cookie。
缓存并不等于cookie。
session鉴权:
session它是服务器产生的,保存在服务器的内存。它可以通过cookie来传参sessionid。原理:当你登录的时候,那么服
务器会生成session,它通过cookie把sessionid传给客户端,然后在后面所有的请求里面都会自动的带上sessionid。然
后和服务器的内存中的ssioniid对比以判断是否是同一个客户端。保存在服务器的内存里面的ssession的失效时间为30分
钟。
在apache-tomcat-8.5.43\conf\web.xml文件里面的session-timeout可以修改默认的失效的时间。
sessionid可以隐藏域,也可以url或者是cookie传递。
token鉴权:
token是服务器的产生的,保存在服务器的文件或数据库(硬盘),一般情况下接口测试通过一个专门的获取token的 接
口或者是登录接口来获取token.,获取后每次请求其他接口都必须带上token鉴权。
面试题:cookie,session,token的相同点和不同点?
相同点:
都是在服务器产生的,都是用于鉴权。只是保存在不同的地方。
不同点:
cookie保存在客户端,所以不安全,一般情况下用cookie保存一些非重要的数据,而通过session去保存一些重要的数
据,session是保存在服务器的内存当中,而token是独立的鉴权,它和sesion和cookie无关。
(2)Postman的鉴权方式。
bearer token鉴权:就是发送一个鉴权码(令牌)。
basic Auth鉴权:通过用户名和密码实现鉴权。
二、接口Mock Sersver
mock测试就是测试过程中,对于一些不容易创建或者是不容易获取的比较复杂的对象,用一个模拟的对象去代替。
mock一把是为了解决单元之间的耦合依赖关系。(桩服务)
比如:工作中前后端分离,前端已经开发好了,但是后端的接口没有开发好。
项目之间的对接。(开发电子商务,支付宝支付。)
三、接口的加解密
接口加密:接口测试当中把传输的数据加密成密文(0101011101100)再传输。
接口解密:获取密文后把密文还原成原始数据。
1.目前市面上的加密方式
对称式加密(私钥加密):DES,AES,Base64
非对称式加密(双钥加密):RSA(公钥《公开》和私钥《保密》)
只加密不解密:MD5,SHA1,SHA3…(就是这两种)
http://www.bejson.com
Postman实现解密接口(可遇不可求,除非自定义。)
四、接口签名sign(接口鉴权的一种)
BATJ,金融项目,银行项目等。
1.什么是接口签名?
接口签名就是使用appid,appsecret,nonce(流水号),timestamp,以及其它的各种参数按照一定的规则(ASCII排序)组
成用来识别你的账号有没有访问api接口的权限的字符串,组成之后再进行加密,这个经过加密之后的字符串就是sign签
名。
appid和appsec在线下针对不同的接口调用方提供的。
流水号nonce,订单号一般是一串10位以上的随机一组数字或者随机的一组字符串。数字+字符串(guid)。
timestamp时间戳,一般10分钟之内有效。
2、为什么要做接口签名?(大大提高接口的安全性)
(1)防止接口鉴权码泄漏,接口被伪装攻击,(签名,只需要提供签名不需要鉴权码)
(2) 防止接口数据被篡改,(原理:签名针对的是所有的请求数据,只要有一个数字别改动了,那么sign就变了。就会请
求失败。)
(3)防止接口被重复提交,nonce是唯一的。并且只有10分钟之内有效。
3、接口签名的规则有很多,每个公司都不一样,但是大同小异(90%以上相似)。举例:
(1)获取到所有的参数包括params和body,把所有的参数的key按照ascii码升序排列。
{a:2,c:1,b:3}改成{a:2,b:3,c:1,}
(2)把参数按照key=value的方式组合,多个参数用&分开。
a=2&b=3&c=1
(3)用申请到的appid和appsecret拼接到参数的最前面
appid=123&appsecret=456&a=2&b=3&c=1
(4)把订单号和时间戳拼接到参数的最后面
appid=123&appsecret=456&a=2&b=3&c=1&nonce=12121313×tamp=235235235
(5)把上述字符串通过MD5加密。加密之后大写。形成sign
sign=WEO987979798DDFGF767FDG
(6)然后把sign放到url或者请求头(一般用这种)或请求体里面发送给服务器做鉴权。
//接口签名
//1.获取到asppid和appsecret
var appid = "test";
var appsecret = "123";
console.log(appid);
console.log(appsecret);
//2.获得nonce流水号
var nonce = getnonce(1000000000,9999999999);
console.log(nonce);
//3.获得时间戳
var timestamp = new Date().getTime();
console.log("timestamp="+timestamp)
//4.获取到params里面的参数
var params_args = pm.request.url.query.members;
console.log("params_args="+params_args);
//5.获取到body里面的参数(JSON.parse加载成对象,JSON.stringify加载成字符串)
var body_args = request.data;
console.log("body_args="+JSON.stringify(body_args));
//6.把params和body的参数组合成一个变量
for(var i=0;i<params_args.length;i++){
body_args[params_args[i].key] = params_args[i].value;
}
console.log("body_args2="+JSON.stringify(body_args));
//7.把组合的数据按照key升序
body_args = objectsort(body_args)
console.log("body_args3="+JSON.stringify(body_args));
//8.把字典格式的参数转换成key=value&key=value的格式
var new_string = "";
for(var key in body_args){
new_string += key + "=" + body_args[key] + "&";
}
console.log("new_string="+JSON.stringify(new_string));
//9.在字符串的前面加上aooid和appsecret,在字符串的后面加nonce,timestamp.
new_string = "appid="+appid+"&"+"appsecret="+appsecret+"&"+new_string+"nonce="+nonce+"&"+"timestamp="+timestamp;
console.log(new_string);
//10.对上述字符做MD5加密后并大写形成sign签名,然后把sign保存为全局变量
var sign = CryptoJS.MD5(new_string).toString().toUpperCase();
console.log("sign="+sign);
pm.globals.set("sign",sign);
//------------------------------------------------------
//获得任意长度的随机数字
function getnonce(min,max){
return Math.floor(Math.random() * (max - min + 1)) + min;
}
//把对象的key升序排序函数(此方法固定)
function objectsort(obj){
var new_key = Object.keys(obj).sort();
console.log(new_key);
var arr = {};
for(var i=0;i<new_key.length;i++){
arr[new_key[i]] = obj[new_key[i]];
}
return arr;
}
接口自动化框架封装思想建立之httprunner框架
接口自动化框架封装思想的建立。httprunner(热加载:动态参数),去应用
意义不大。
一、什么是Httprunner?
1.httprunner是一个面向http协议的通用测试框架,目前最新的版本3.X。以前比较流行的
2.X的版本。
2.它的思想是只需要维护yaml/json/py文件就可以实现接口自动化测试,性能测试,线上
监控,持续集成。
3.架构图
二、httprunner的设计理念
1.充分复用开源项目,不追求重复的造轮子,而是将市面强大的轮子转成战车,降低框架的
开发成本以及学习成本。
2.遵循约定大于临时配置的准则。(合同,考勤)
3.配置文件组织测试用例。
三、httprunner环境安装
1.python环境:3.7.3
2.安装httprunner
pip install httprunner
验证:hrun -V
3.必须知道的5个httprunner的命令
httprunner:主命令,用于所有功能
hrun:用于运行yaml/json/pytest测试用例。
hmake:用于将yaml/json测试用例转化成pytest文件。
har2case:用于将har文件转化成yaml/json/pytest测试用例。
locusts:用于性能测试
四、httprunner快速上手
1.使用抓包工具:fiddler、charles操作一遍抓包。导出har文件。
2.通过har2case命令把har文件转化成yaml/json/pytest文件格式。
har2case get_token.har 生成pytest文件格式的测试用例
har2case get_token.har -2y 生成yaml格式的测试用例
har2case get_token.har -2j 生成json格式的测试用例
运行:
hrun get_token.yml
hrun get_token.json
hrun get_token_test.py
发现运行完成之后py文件里面的断言自动的去掉了,说明不管是运行yml、json其实最终都
会重新成py文件运行。
五、YAML测试用例结构分析
每一个测试用例都是一个list of dict(字典列表)结构,其中包括config【配置】和
teststeps【步骤】
[{},{},{}]
cofig:配置
name:用例名称
variables:全局变量
verify:是否开启https验证
teststeps:步骤
name: /cgi-bin/token 步骤名称
request: 请求
headers: 请求头
Accept: ‘/’
Accept-Encoding: gzip, deflate, br
Cache-Control: no-cache
Connection: keep-alive
Host: api.weixin.qq.com
Postman-Token: 50f8bb1a-7826-49f8-835e-ec889063b7cc
User-Agent: PostmanRuntime/7.28.0
method: GET 请求方式
params: 请求参数
appid: wx74a8627810cfa308
grant_type: client_credential
secret: e40a02f9d79a8097df497e6aaf93ab80
url: https://api.weixin.qq.com/cgi-bin/token 请求路径
validate:断言
- eq:
- status_code
- 200
- eq:
- headers.Content-Type
- application/json; encoding=utf-8
六、接口关联
在request标签下加一个extract标签提取返回值,通过content或body提取。
extract:
aaa: content.access_token
然后通过$变量名使用
params:
access_token: a a a 七、动态参数:通过 d e b u g t a l k . p y 的热加载的方式实现。第一步:创建一个 d e b u g t a l k . p y 文件,然后再里面写一个函数。第二步:在 y a m l 文件中通过 aaa 七、动态参数:通过debugtalk.py的热加载的方式实现。 第一步:创建一个debugtalk.py文件,然后再里面写一个函数。 第二步:在yaml文件中通过 aaa七、动态参数:通过debugtalk.py的热加载的方式实现。第一步:创建一个debugtalk.py文件,然后再里面写一个函数。第二步:在yaml文件中通过{函数名()}的方式调用。
八、环境变量
开发环境,测试环境,线上环境。预发布环境。
在config下加入:
base_url: https://api.weixin.qq.com
九、全局变量和局部变量
config下的variables是全局变量
teststeps:下的variables是局部变量
- name: /cgi-bin/tags/update
有两种写法:
1.换行的键值对
2.{}的方式
十、生成HTML格式的报告
hrun httprunneres --html=httprunneres/report.html
就是pytest里面pytest-html插件的报告一模一样。
一、httprunner常规的关键字详解
httprunner测试用例的结构
config:配置
name:名称
variables:全局变量
verify:https协议
base_url:环境变量
teststeps:步骤
name:步骤名称
request:请求
headers:请求头
method:请求方式
params:参数
url:请求路径
cookie:cookie信息
json:用于发送http请求正文
data:用于发送http请求正文
extract:提取(通过content或body提取,json提取器。支持正则表达式提取。)
validate:断言
eq相等
equals相等
str_eq(str(a)=str(b))
lt:小于
le:小于或等于
gt:大于
ge:大于或等于
contains:包含
简化:
name:接口名称
request:请求
headers:请求头
method:请求方式
data:参数
url:请求路径
cookie:cookie信息
extract:提取(通过content或body提取,json提取器。支持正则表达式提取。)
validate:断言
equals相等
str_eq(str(a)=str(b))
contains:包含
二、httpruner接口自动化项目架构
先要切换到项目的根目录,使用:httprunner startproject 项目名(没有虚拟环境)
har:存放har文件
reports:存在报告
testcases:存放测试用例
api:存放yml文件,接口定义。
data:数据驱动
testsuites:测试套件
.env:存放环境变量
.gitignore 当你的项目使用git做版本控制的时候,添加在此文件中的文件不会被git管理。
debugtalk,py实现热加载。
分层架构:三层
1.接口定义层(api):为了更好的管理接口描述,每个一个接口定义都应该尽量的能够单
独运行。
2.测试用例层(testcases)
3.测试套件层(testsuites)
关系:testcases调用api层(使用api关键字),testsuites调用testcases层。(使用
testcase关键字)
三、环境变量
环境变量可以写入.env文件。
然后在api接口定义层里面使用:${ENV(变量名)}获取环境变量。
httprunner实际的工作应用其他不多,只有一小部分的公司用它做接口自动化,主要目
的:思想。
每个项目的接口不一样。
每个公司的框架都是不一样的。
一、httprunner如何实现数据驱动
3.X开始,使用parameters定义数据源。应用于测试用例层。
第一种:直接在脚本里面指定参数列表,最简单。适合于参数比较少的情况。
1 config:
2 name: 测试用例
3 parameters:
4 appid‐grant_type‐secret‐assert_str:
5 ‐ ["wx74a8627810cfa308","client_credential","e40a02f9d79a8097df497e6aaf9
3ab80","access_token"]
6 ‐ ["","client_credential","e40a02f9d79a8097df497e6aaf93ab80","errcode"]
7 ‐ ["wx74a8627810cfa308","","e40a02f9d79a8097df497e6aaf93ab80","errmsg"]
8 teststeps:
9 ‐ name: 获得token鉴权码API
10 api: api/get_token.yml
第二种:使用CSV文件,适合于参数比较大的情况
config:
2 name: 测试用例
3 parameters:
4 appid‐grant_type‐secret‐assert_str: ${P(data/get_token_data.csv)}
5 teststeps:
6 ‐ name: 获得token鉴权码API
7 api: api/get_token.yml
1 appid,grant_type,secret,assert_str
2 "wx74a8627810cfa308","client_credential","e40a02f9d79a8097df497e6aaf93ab8
0","access_token"
3 "","client_credential","e40a02f9d79a8097df497e6aaf93ab80","errcode"
4 "wx74a8627810cfa308","","e40a02f9d79a8097df497e6aaf93ab80","errmsg"
注意:
1.csv文件中第一行必须放参数名称,并且参数名称必须和测试用例里面的名称
一致。
2.csv文件中第二行放数据,每一组数据占一行。
3.parameters指定的参数顺序可以不一致,个数也可以不一致。
第三种方式:使用函数生成数据,适用于数据变化大的情况
1 #生成数据
2 def get_token_data():
3 return [
4
{"appid":"wx74a8627810cfa308","grant_type":"client_credential","secret":"e4
0a02f9d79a8097df497e6aaf93ab80","assert_str":"access_token"},
5 {"appid": "", "grant_type": "client_credential", "secret": "e40a02f9d79a
8097df497e6aaf93ab80","assert_str": "errcode"},
6 {"appid": "wx74a8627810cfa308", "grant_type": "", "secret": "e40a02f9d79
a8097df497e6aaf93ab80","assert_str": "errmsg"}
7 ]
1 config:
2 name: 测试用例
3 parameters:
4 appid‐grant_type‐secret‐assert_str: ${get_token_data()}
5 teststeps:
6 ‐ name: 获得token鉴权码API
7 api: api/get_token.yml
二、httprunner文件上传
前提条件:需要安装如下两个包
pip install requests_toolbelt filetype
pip install “httprunner[upload]”
三、如何生成allure报告
第一步
1.官网下载allure文件:https://github.com/allure-framework/allure2/releases
2.下载之后解压到非中文的目录
3.把bin路径配置到系统变量path中:E:\allure-2.13.7\bin (注意分号不要是中文的)
第二步:
安装allure报告:pip install allure-pytest
验证:allure --version
注意:可能需要重启pycharm。
第三步:
1.在reports目录下生成temps目录,并且在temps目录下生产临时的json格式的临时报告。
os.system(“hrun testsuites/test_suites.yml ‐‐alluredir=reports/temps ‐‐cl
ean‐alluredir”)
加上–clean-alluredir表示:每执行一次把原来的清除。
2.根据临时json报告生成allure报告
os.system(“allure generate reports/temps ‐o reports/allures ‐‐clean”)
加上–clean表示:每执行一次把原来的清除
四、接口自动化框架文件对应关系
一个接口对应一个yaml文件,一个yaml文件对应一个csv文件
用例管理框架之pytest单元测试框架
一、pytest用例管理框架(单元测试框架)
1.分类
python:unittest,pytest 非常熟练。
java:testng,junit
2.主要作用。
发现测试用例:从多个py文件里面按照一定的规则找到测试用例。
执行测试用例:按照一定的顺序执行测试用例。并生成结果。
pytest::默认从上到下,可以装饰器就改变规则。
unittest:默认安装ASCII顺序去执行。
判断测试结果:断言。
生成测试报告:pytest-html,allure报告。
二、pytest简介
1.基于python的单元测试框架,它可以和selenium,requests,appium结合实现自动化
测试。
2.实现用例跳过skip和reruns失败用例重跑。
3.它可以结合allure-pytest插件生成allure报告。
4.很方便和jenkins实现持续集成。
5.有很多强大的插件:
pytest-html 生成html测试报告。
pytest-xdist 多线程执行测试用例。
pytest-ordering 改变测试用例的执行顺序。
pytest-rerunfailures 失败用例重跑
allure-pytest 生成allure报告。
放到一个requirements.txt的文档中,如:
pytest
pytest-html
pytest-xdist
pytest-ordering
pytest-rerunfailures
allure-pytest
然后通过:pip install -r requirements.txt
报错:参数错误。
windows7+python3.7.3+pytest5.4.3 6.2.4
三、pytest的最基本的测试用例的规则
1.模块名必须以test_开头或者_test结尾。
2.测试类必须以Test开头,并且不能带有init方法。
3.测试用例必须以test_开头。
命令规范:
模块名:一般全小写:多个英文之间用_隔开。
类名:类名一般是首字母大写
方法名:一般全小写:多个英文之间用_隔开。
四、运行方式
1.主函数方式。
1 import pytest
2
3 if __name__ == '__main__':
4 pytest.main()
常见参数:
-v:输出更加详细的信息。比如文件和用例名称等。
-s:输出调试信息。打印信息等。
可以合并成:-vs
–reruns 数字:失败重跑
-x:出现1个失败就停止测试。
–maxfail=2 出现N个失败就终止测试。
–html=report.html 生成html的测试报告
-n:多线程。
-k:运行测试用例名称中包含指定字符串的用例。
pytest.main([‘-vs’,‘-k’,‘weiwei or baili’])
pytest.main([‘-vs’,‘-k’,‘weiwei and baili’])
2.指定模块运行。
1 if __name__ == '__main__':
2 pytest.main(['‐vs','testcases/test_api2.py'])
3.指定文件夹
1 if __name__ == '__main__':
2 pytest.main(['‐vs','testcases/'])
4.通过node id的方式运行测试用例。
1 if __name__ == '__main__':
2 pytest.main(['‐vs','testcases/test_api.py::TestApi::test_product_manage_
weiwei'])
2.命令行方式
pytest
3.通过pytest.ini的配置文件运行。(不管是命令行还是主函数都会读取这个配置文件)
[pytest] 用于标记这个文件是pytest的配置文件
addopts = -vs 命令行参数,多个参数之间用空格分隔。 addoptions
testpaths = testcases/ 配置搜索测试用例的范围
python_files = test_.py 改变默认的文件搜索规则
python_classes = Test 改变默认的类搜索规则
python_functions = test_* 改变默认的测试用例的搜索规则。
#用例分组
markers =
smoke:冒烟用例
productmanage:商品管理模块
特别提示:
此文件中最好不要出现中文, 如果有中文的情况下,比如使用notpad++改成GBK的编
码。
用例里面加标记
class TestApi:
2
3 @pytest.mark.smoke
4 def test_baili(self):
5 print("百里老师")
6
7 @pytest.mark.productmanage
8 def test_product_manage_weiwei(self):
9 print("微微老师")
执行的时候通过-m参数指定标记
1 addopts = ‐vs ‐m smoke
五、pytest默认的执行测试用例的顺序
从上到下。
改变默认用例的执行顺序:在用例上加标记:
@pytest.mark.run(order=1)
注意:有order装饰器的优先,相同的从上到下,然后再是没有装饰器的,负数不起作用。
六、跳过测试用例。
粒度:不想这么细。
1.无条件跳过
1 @pytest.mark.skip(reason="粒度不需要")
2 @pytest.mark.smoke
3 def test_baili(self):
4 print("百里老师")
2.有条件跳过
1 @pytest.mark.skipif(age>2,reason="以后的版本都不执行")
2 @pytest.mark.smoke
3 def test_aaa(self):
4 print("aaa")
七、用例的前后置,固件,夹具,钩子函数
1 import pytest
2
3 def setup_module():
4 print("在每个模块之前执行")
5
6 def teardown_module():
7 print("在每个模块之后执行")
8
9 class TestApi:
10
11 def setup_class(self):
12 print("在每个类之前执行,创建日志对象(创建多个日志对象,那么日志会出现重
复),创建数据库连接")
13
14 def teardown_class(self):
15 print("在每个类之后执行,销毁日志对象,关闭数据库连接")
16
17 def setup(self):
18 print("在每个用例之前执行,web自动化:打开浏览器,加载网页,接口自动化:日志开
始")
19
20 def teardown(self):
21 print("在每个用例之后执行,日志结束,关闭浏览器")
22
23 @pytest.mark.productmanage
24 def test_product_manage_weiwei(self):
25 print("微微老师")
26
27 @pytest.mark.smoke
28 def test_baili(self):
29 print("百里老师")
30
31 @pytest.mark.smoke
32 def test_aaa(self):
33 print("aaa")
34
35 class TestApi2:
36
37 def test_duo_class(self):
38 print("多个类的情况")
一、使用fixture实现部分前后置
setup/teardown
setup_class/teardown_class
语法:
@pytest.fixture(scope=“作用域”,params=“数据驱动”,autouser=“自动执行”,ids=“自定
义参数名称”,name=“别名”)
scope=“作用域”
functioin:在每个方法(测试用例)的前后执行一次。
class:在每个类的前后执行一次。
module:在每个py文件前后执行一次。
package/session:每个package前后执行一次。
1.function级别:在每个函数的前后执行
1 @pytest.fixture(scope="function")
2 def execute_sql():
3 print("执行数据库的验证,查询数据库。")
4 yield
5 print("关闭数据库的连接")
调用:
1 def test_baili(self,execute_sql):
2 print("百里老师"+execute_sql)
yield和return,都可以返回值,并且返回的值可以在测试用例中获取。
yield生成器,反复一个对象,对象中可以有多个值,yield后面可以接代码。
return 返回一个值,return后面不能接代码。
注意:如果加入autouse=True参数,那么表示自动使用,那么和setup、
teardown功能一致。
2.class级别:在每个类的前后执行一次。
1 @pytest.fixture(scope="class")
2 def execute_sql():
3 print("执行数据库的验证,查询数据库。")
4 yield
5 print("关闭数据库的连接")
调用
1 @pytest.mark.usefixtures("execute_sql")
2 class TestApi2:
3
4 def test_duo_class(self):
5 print("多个类的情况")
3.module级别:在每个模块的前后执行一次。和setup_module和teardown_module效果一样
1 @pytest.fixture(scope="module",autouse=True)
2 def execute_sql():
3 print("执行数据库的验证,查询数据库。")
4 yield "1"
5 print("关闭数据库的连接")
4.package、sesion级别,一般是和connftest.py文件一起使用。
autouse=True 自动调用
params=数据(list,tuple,字典列表,字典元祖)
1 def read_yaml():
2 return ['甄子丹','成龙',"菜10"]
3
4 @pytest.fixture(scope="function",params=read_yaml())
5 def execute_sql(request):
6 print(request.param)
7 print("执行数据库的验证,查询数据库。")
8 yield request.param
9 print("关闭数据库的连接")
这里的params用于传输数据(list,tuple,字典列表,字典元祖),需要在夹
具里面通过request(固定写法)接收,然后通过request.param(固定写法)
获取数据,然后再通过yield把数据返回到测试用例中,然后使用。
ids参数:它要和params一起使用,自定义参数名称。意义不大。了解即可
1 def read_yaml():
2 return ['甄子丹','成龙',"菜10"]
3
4 @pytest.fixture(scope="function",params=read_yaml(),ids=
['zzd','cl','cyl'])
5 def execute_sql(request):
6 print(request.param)
7 print("执行数据库的验证,查询数据库。")
8 yield request.param
9 print("关闭数据库的连接")
name参数:对fixtrue固件取的别名。意义不大。了解即可,用了别名后,那
么真名会失效,只能使用别名
1 def read_yaml():
2 return ['甄子丹','成龙',"菜10"]
3
4 @pytest.fixture(scope="function",params=read_yaml(),ids=
['zzd','cl','cyl'],name="jj")
5 def execute_sql(request):
6 print(request.param)
7 print("执行数据库的验证,查询数据库。")
8 yield request.param
9 print("关闭数据库的连接")
二、当fixture的级别为package,session时,那么一般和conftest.py
文件一起使用。
1.名称是固定的conftest.py,主要用于单独的存放fixture固件的。
2.级别为package,sesion时,那么可以在多个包甚至多个py文件里面共享前后置。
举例:登录。
模块:模块的共性。
3.发现conftest.py文件里面的fixture不需要导包可以直接使用。
4.conftest。py文件,可以有多个。
作用:出现重复日志,初始化一次日志对象。规避日志重复。连接数据库。关闭数据库。
注意:多个前置同时存在的优先级。
1.conftest.py为函数级别时优先级高于setup/teardown
2.conftest.py为class级别时优先级高于setup_class/teardown_class
3.conftest.py为session级别时优先级高于setup_module/teardown_module
三、pytest断言
使用的是python原生的assert
四、pytest结合allure-pytest实现生成allure报告
第一步
1.官网下载allure文件:https://github.com/allure-framework/allure2/releases
2.下载之后解压到非中文的目录
3.把bin路径配置到系统变量path中:E:\allure-2.13.7\bin (注意分号不要是中文的)
第二步:
安装allure报告:pip install allure-pytest
验证:allure --version
注意:可能需要重启pycharm。
第三步:
1.pytest.ini文件如下
1 [pytest]
2 addopts = ‐vs ‐‐alluredir=reports/temps ‐‐clean‐alluredir
3 testpaths = testcases/
4 python_files = test_*.py
5 python_classes = Test*
6 python_functions = test_*
7 #鐢ㄤ緥鍒嗙粍
8 markers =
9 smoke:冒烟测试
10 productmanage:商品管理模块
加上–clean-alluredir表示:每执行一次把原来的清除
2.all.py文件如下:
1 if __name__ == '__main__':
2 pytest.main()
3 time.sleep(3)
4 os.system("allure generate reports/temps ‐o reports/allures ‐‐clean")
加上–clean表示:每执行一次把原来的清除。
第四步:实现logo定制。
1.修改E:\allure-2.13.7\config下的allure.yml配置文件,加入:自定义logo插件。最后一句
1 plugins:
2 ‐ junit‐xml‐plugin
3 ‐ xunit‐xml‐plugin
4 ‐ trx‐plugin
5 ‐ behaviors‐plugin
6 ‐ packages‐plugin
7 ‐ screen‐diff‐plugin
8 ‐ xctest‐plugin
9 ‐ jira‐plugin
10 ‐ xray‐plugin
11 ‐ custom‐logo‐plugin
2.修改插件里面的图片和样式
1 /*
2 .side‐nav__brand {
3 background: url('custom‐logo.svg') no‐repeat left center !important;
4 margin‐left: 10px;
5 }
6 */
7
8 .side‐nav__brand{
9 background: url('logo.png') no‐repeat left center !important;
10 margin‐left: 20px;
11 height: 90px;
12 background‐size: contain !important;
13 }
14
15 .side‐nav__brand‐text{
16 display: none;
17 }
用例管理框架pytest之allure报告定制以及数据驱动
一、企业级的Allure报告的定制
左边的定制:
1.史诗(项目名称): @allure.epic(“项目名称:码尚教育接口自动化测试项目”)
2.特性(模块名称):@allure.feature(“模块名称:用户管理模块”)
3.分组(接口名称):@allure.story(“接口名称:查询商品”)
4.测试用例标题:
(1)@allure.title(“测试用例标题:输入正确的条件查询成功1”),适用于一个方法对
应一个用例。
(2)allure.dynamic.title(“测试用例标题:输入正确的条件查询成功2”),适用于一个
方法对应多个用例。也就是有数据驱动的情况
1 import allure
2 import pytest
3 @allure.epic("项目名称:码尚教育接口自动化测试项目")
4 @allure.feature("模块名称:用户管理模块")
5 class TestApi:
6
7 @allure.story("接口名称:查询商品")
8 @allure.title("测试用例标题:输入正确的条件查询成功1")
9 def test_product_manage_weiwei(self):
10 allure.dynamic.title("测试用例标题:输入正确的条件查询成功2")
11 print("微微老师")
12
13 @allure.story("接口名称:测试百里接口")
14 def test_baili(self,user_setup):
15 print("百里老师:")
16 print(user_setup)
右边的定制:
1.用例的严重程度
blocker:中断缺陷:致命bug:内存泄漏,用户数据丢失,系统奔溃。
critical:临界缺陷:严重bug:功能未实现,功能错误,重复提交
normal:一般缺陷,一般bug,条件查询有误,大数据了无响应等
minor级别:次要缺陷:提示bug,颜色搭配不好,字体排列不整齐,错别字。
trivial级别:轻微缺陷:轻微bug,没有使用专业术语,必填项无提示。建议。
1 @allure.severity(allure.severity_level.BLOCKER)
2.用例描述
1 @allure.story("接口名称:查询商品")
2 @allure.title("测试用例标题:输入正确的条件查询成功1")
3 @allure.description("测试用例描述1")
4 def test_product_manage_weiwei(self):
5 allure.dynamic.title("测试用例标题:输入正确的条件查询成功2")
6 allure.dynamic.description("测试用例描述2")
7 print("微微老师")
3.测试用例连接的定制
接口地址:
Bug地址:
测试用例的地址:
1 @allure.story("接口名称:查询商品")
2 @allure.title("测试用例标题:输入正确的条件查询成功1")
3 @allure.description("测试用例描述1")
4 @allure.link(name="接口地址",url="https://api.weixin.qq.com/cgi‐
bin/token")
5 @allure.issue("Bug连接")
6 @allure.testcase("测试用例地址")
7 def test_product_manage_weiwei(self):
8 allure.dynamic.title("测试用例标题:输入正确的条件查询成功2")
9 allure.dynamic.description("测试用例描述2")
10 print("微微老师")
4.测试用例步骤的定制
1 @allure.story("接口名称:查询商品")
2 @allure.title("测试用例标题:输入正确的条件查询成功1")
3 @allure.description("测试用例描述1")
4 @allure.link(name="接口地址",url="https://api.weixin.qq.com/cgi‐
bin/token")
5 @allure.issue("Bug连接")
6 @allure.testcase("测试用例地址")
7 def test_product_manage_weiwei(self):
8 allure.dynamic.title("测试用例标题:输入正确的条件查询成功2")
9 allure.dynamic.description("测试用例描述2")
10 #增加步骤
11 for a in range(1,10):
12 with allure.step("测试用例步骤"+str(a)+""):
13 print("步骤"+str(a)+"执行的脚本")
14 print("微微老师")
5.附件的定制
web自动化
1 #附件的定制:body附件内容, name=None文件名, attachment_type=None文件扩展名
2 with open("E:\\shu.png",mode="rb") as f:
3 allure.attach(body=f.read(),name="错误截图",attachment_type=allure.attach
ment_type.PNG)
接口自动化
1 allure.attach(body="https://api.weixin.qq.com/cgi‐bin/token",name="请求地
址:",attachment_type=allure.attachment_type.TEXT)
2 allure.attach(body="get", name="请求方式:",attachment_type=allure.attachm
ent_type.TEXT)
3 data = {
4 "grant_type":"client_credential",
5 "appid":"wx6b11b3efd1cdc290",
6 "secret":"106a9c6157c4db5f6029918738f9529d"
7 }
8 allure.attach(body=json.dumps(data), name="请求数据:",attachment_type=all
ure.attachment_type.TEXT)
9 rep = requests.get(url="https://api.weixin.qq.com/cgi‐bin/token",params=d
ata)
10 allure.attach(body=rep.text, name="响应数据:", attachment_type=allure.at
tachment_type.TEXT)
二、企业中真实的定制有哪些?
[email protected](“项目名称”)
[email protected](“模块名称”)
[email protected](“接口名称”)
[email protected](allure.severity_level.BLOCKER) 严重程度
5.allure.dynamic.title(“用例名称:测试用例名称”)
6.allure.dynamic.description(“用例描述:测试用例描述”)
7.with allure.step(“测试步骤的名称”):
print(“执行测试步骤代码”)
8.allure.attach(body, name, attachment_type, extension) 测试用例附件
三、allure报告如何在本地访问。
因为pycharm自带容器。tomcat,Nginx,weblogic
1.在本地搭建本地服务器。
2.通过启动服务打开allure报告。
allure open ./reports/allures
四、allure中的数据驱动装饰器
@pytest.mark.parametrize(参数名,数据(list,tuple,字典列表,字典元祖))
第一种基本用法
1 @allure.story("接口名称:测试百里接口")
2 @pytest.mark.parametrize("args_name",["百里","星瑶","依然"])
3 def test_baili(self,args_name):
4 print("百里老师:")
5 print(args_name)
第二种用法:
1 @allure.story("接口名称:测试百里接口")
2 @pytest.mark.parametrize("name,age",[["百里","13"],["星瑶","10"],["依
然","11"]])
3 def test_baili(self,name,age):
4 print("百里老师:")
5 print(name,age)
YAML有两种数据:
-开头的代码list
键值对:key:value
YAML的格式:
‐
2 name: 获取token接口
3 description: 接口描述
4 request:
5 method: get
6 url: https://api.weixin.qq.com/cgi‐bin/token
7 data:
8 grant_type: client_credential
9 appid: wx6b11b3efd1cdc290
10 secret: 106a9c6157c4db5f6029918738f9529d
11 validate: None
第一种:ALT+Enter
第二种:ctrl+alt+空格
接口自动化之requests模块详解以及Cookie,Session关联处理
一、Requests库简介
用于发送http请求的第三方库。安装:
pip install requests
二、Requests库常用的方法
1.requests.get(url, params=None, **kwargs) 发送get请求(通过params传
参)
2.requests.post(url, data=None, json=None, **kwargs) 发送post请求(通过data
和json传参)
请求头:
1.请求正文格式:multipart/formdata 文件上传
ContentType:multipart/formdata 一般用于传价值对和文件
2.请求正文格式:application/xwwwformurlencoded 键值对
ContentType:application/xwwwformurlencoded 以表单的方式传参,数据格式:
key1=value1&key2=value2
3.请求正文格式“:raw
Content-Type:application/json
Content-Type:text/plain
Content-Type:application/javascript
Content-Type:text/html
Content-Type:application/xml
4.请求正文格式:binary
Content-Type:application/octetstream 二进制流的数据
3.requests.put() 发送put请求
4.requests.delete() 发送delete请求
5.requests.request() 发送任意请求,最核心的方法
method, 请求方式
url, 请求路径
params=None, get方式传参
data=None, post,put,patch传参
headers=None, 请求头
cookies=None, 请求的cookie信息
files=None, 文件上传
json=None post传参
auth=None, 鉴权
timeout=None, 超时
allow_redirects=True, 重定向
proxies=None, 代理
hooks=None,
stream=None, 文件下载
verify=None, 是否需要验证证书
cert=None, CA证书
6.requests.session() 发送任意请求,最核心的方法
三、request()执行之后返回response对象
print(res.text) 响应的字符串格式的数据
print(res.content) 响应的bytes类型格式的数据
print(res.json()) 响应的字典数据格式
print(res.status_code) 响应的状态码
print(res.reason) 响应的状态信息
print(res.cookies) 响应的cookie信息
print(res.headers) 响应头
print(res.request.headers) 请求头
四、实战(发送get,post
json.dumps(data) 序列化,把字典转换成str字符串
json.loads(data) 反序列化,把字符串转换成字典
post:
data (键值对的字典)
默认:ContentType:application/xwwwformurlencoded 数据格式:
key1=value1&key2=value2
当使用json.dumps(data)转换之后,那么默认:‘ContentType’: ‘application/json’
json(有嵌套的字典):
默认:‘ContentType’: ‘application/json’
files:(文件上传)
默认:ContentType’: ‘multipart/formdata;
boundary=50dcca52ed21a4b55651353785ca905a’
五、需要带请求头的接口,需要带Cookie的接口
cookie关联。基本上所有的web项目的接口都需要做cookie关联。
六、一般情况下我们会使用session对象关联。
因为session就表示同一个回话,同一个回话里面的cookie会自动关联。
七、封装没有固定的方式,只有一个方向
Web自动化之HTML&JavaScript详解
一、HTML常用标签
HTML :超文本标记语言
超文本:不仅只包含文字,还有超链接、视频…这些元素
HTML与HTML5(H5)
HTML5=HTML+一些其他特殊标签 比如:canvas 画图标签
HTML结构标签对:
< html>
< head>
< title>网页的标题
< /head>
< body>
< /body>
< /html>
常用标签分为:双标签+单标签
1 <html>
2 <head>
3 <title>我的个人页面</title>
4 </head>
5 <body>
6 <!‐‐段落标签‐‐>
7 <p>
8 <font size="6" color="blue" ><b><i>自我介绍</i></b></font>
9 </p>
10 姓名:星瑶<br/>
11 专业:计算机软件<br/>
12 图片:<br/><img src="微微2.png"></img><br/>
13 <a href="https://wwww.baidu.com" target="_black" >查看更多</a>
14 <!‐‐‐分隔线‐‐‐>
15 <hr width="100%" size="1" color="red"/>
16 <!‐‐常用标签:表格 ‐‐>
17 <table border="1" width="300px" height="300px">
18 <!‐‐行标签‐‐>
19 <tr>
20 <!‐‐列标签‐‐>
21 <td colspan="2">1</td>
22
23 <td rowspan="3">3</td>
24 </tr>
25 <tr>
26 <td>4</td>
27 <td>5</td>
28
29 </tr>
30 <tr>
31 <td>7</td>
32 <td>8</td>
33
34 </tr>
35 </table>
36
37 <!‐‐常用标签:表单 数据提交‐‐>
38 <form action="url地址" method="">
39 <!‐‐提交的方式:post/get get:url传递参数 post通过表单传参 post方式更加安全‐
‐>
40
41 <!‐‐文本框 密码框 按钮 复选框 单选框‐‐>
42 用户名:<input type="text"></input><br/>
43 密码<input type="password"></input><br/>
44 <!‐‐单选框‐‐>
45 性别:<input type="radio" name="xb" >男</input> <input type="radio"
name="xb">女</input><br/>
46 <!‐‐复选框 ‐‐>
47 爱好:<input type="checkbox" >学习</input> <input type="checkbox"
>money</input> <input type="checkbox" >小姐姐</input> <br/>
48 上传作业:<input type="file" >学习</input>
49 学习计算机语言:
50 <select>
51 <option>java</option>
52 <option>Python</option>
53 <option>php</option>
54 </select> <br/>
55 文本域:
56 <textarea cols="25" rows="10"></textarea> <br/>
57 普通按钮:
58 <input type="button" value="打卡学习" ></input><br/>
59 特殊按钮(提交按钮):
60 <input type="submit" value="提交"></input><br/>
61 特殊按钮(重置按钮):
62 <input type="reset" value="重置"></input><br/>
63
64
65 </form>
66
67
68
69 </body>
70 </html>
前端页面布局:div table frame 框架
基于frame来进行页面设计:
1 <html>
2 <frameset rows="30%,*">
3 <frame src="mypage.html" ></frame>
4 <frameset cols="50%,50%">
5 <frame src="https://taobao.com"></frame>
6 <frame src="https://www.baidu.com/"></frame>
7 </frameset>
8
9 </frameset>
10 </html>
二、javascript脚本
用户交互:必须懂明白javascript脚本
1、什么是javascript(js)
javascript:前端脚本语言,实现用户的交互
网页端执行js脚本两种方式:
1、内嵌式
2、外部导入
2、js变量和函数
1 <html>
2 <head>
3 <title>网页的标题</title>
4 <script language="javascript">
5 document.write("执行外部js脚本"+"
")
6 <!‐‐变量‐‐>
7 var a=10;
8 var name="xingyao";
9 var c= true;
10 document.write(a+"
");
11 document.write(name+"
");
12 document.write(c+"
");
13 <!‐‐javascript函数‐‐>
14 function zt1(){
15 <!‐‐函数体语句‐‐>
16 var value="正在学习<>" ;
17 document.getElementById("result").value=name;
18
19 }
20 function zt2(){
21 <!‐‐函数体语句‐‐>
22 var value2="正在学习<<接口自动化测试>>";
23 document.getElementById("result").value=value3;
24
25 }
26 function zt3(){
27 <!‐‐函数体语句‐‐>
28 var value3="正在学习<>" ;
29 document.getElementById("result").value=value3;
30
31 }
32
33 </script>
34 </head>
35 <body>
36 <form>
37 <input type="button" value="专题一" onclick="zt1()"></input><br/>
38 <input type="button" value="专题二" onclick="zt2()" ></input><br/>
39 <input type="button" value="专题三" onclick="zt3()"></input><br/>
40 .....<br/>
41 <input type="button" value="专题八"></input><br/>
42 当前学习阶段:<input type="text" id="result" value="Python基础"></input><b
r/>
43 </form>
44 </body>
45 </html>
3、js弹窗处理
网页的弹窗有三种
1、提示弹窗
2、包含确定和取消的弹窗
3、包含确定和取消的弹窗+用户输入
4、js流程控制语句和switch结构语句应用
1、if/else语句进行控制
if(条件){
}
else{
}
2、if/else嵌套
if(条件){
if(条件){
}
else{
}
}
else{
if(条件){
}
else{
}
}
3、switch语句
switch(变量){
case 常量1:
js代码;
break;
case 常量2:
js代码;
break;
case 常量3:
js代码;
break;
…
default:
js代码
break;
}
练习
充钱规则:根据不同支付方式,享受不同的折扣,显示最终的成交价格
支付方式:下拉框 微信支付 9折 京东支付8折 支付宝支付7折
Q币的数量:
Q币单价:
结算按钮:点击结算按钮显示最终成交价格,显示下面的这个文本框
成交价:
1 <html>
2 <head>
3 <title>网页的标题</title>
4 <script language="javascript">
5 document.write("执行外部js脚本"+"
")
6 <!‐‐变量‐‐>
7 var a=10;
8 var name="xingyao";
9 var c= true;
10 document.write(a+"
");
11 document.write(name+"
");
12 document.write(c+"
");
13 <!‐‐javascript函数‐‐>
14 function zt1(){
15 <!‐‐函数体语句‐‐>
16 var value="正在学习<>" ;
17 document.getElementById("result").value=name;
18
19 }
20 function zt2(){
21 <!‐‐函数体语句‐‐>
22 var value2="正在学习<<接口自动化测试>>";
23 document.getElementById("result").value=value2;
24
25 }
26 function zt3(){
27 <!‐‐函数体语句‐‐>
28 var value3="正在学习<>" ;
29 document.getElementById("result").value=value3;
30
31 }
32 function abc(){
33 alert("操作成功!!");
34 }
35 function con(){
36 var res=confirm("请问需要删除此商品?");
37 if (res==true){
38 alert("删除");
39 }
40 }
41 function pro(){
42 var res=prompt("请输入需要删除的商品的编号");
43 alert(res);
44 }
45
46 function jiesuan(){
47 var paymoney;
48 <!‐‐int类型转化 parseInt‐‐>
49 var price=parseInt(document.getElementById('danjian').value);
50 var count=parseInt(document.getElementById('shuliang').value);
51 var paytype=document.getElementById('fangshi').value;
52
53 <!‐‐ isNaN 表示不是一个数字 !isNaN()判断参数是数字‐‐>
54 if (!isNaN(price) && !isNaN(count)){
55 <!‐‐计算支付金额‐‐>
56 <!‐‐选择不同的支付方式,计算方式不一样‐‐>
57 switch(paytype){
58 case "9":
59 case "8":
60 case "7":
61 case "6":
62 paymoney=price*count*parseInt(paytype)/10;
63 break;
64 default:
65 alert("请选择支付方式!!!");
66
67 }
68 <!‐‐计算支付金额显示在结算金额输入框 ‐‐>
69 document.getElementById('jsje').value=paymoney+"元";
70
71
72 }
73 else{
74 alert("Q币单价及Q币的数量必须是数字!!!");
75 }
76
77
78
79
80 }
81
82
83 </script>
84 </head>
85 <body>
86 <hr color="red" size="2" width="100%">
87 <form>
88 <input type="button" value="专题一" onclick="zt1()"></input><br/>
89 <input type="button" value="专题二" onclick="zt2()" ></input><br/>
90 <input type="button" value="专题三" onclick="zt3()"></input><br/>
91 .....<br/>
92 <input type="button" value="专题八"></input><br/>
93 当前学习阶段:<input type="text" id="result" value="Python基础"></input><b
r/>
94 <hr color="red" size="2" width="100%">
95
96 <input type="button" value="alert弹窗" onclick="abc()"></input><br/>
97 <input type="button" value="confirm弹窗" onclick="con()"></input><br/>
98 <input type="button" value="prompt弹窗" onclick="pro()"></input><br/>
99 </form>
100 <hr color="red" size="2" width="100%">
101 <form>
102 支付方式:
103 <select id="fangshi">
104 <option value="9">现金支付(9折)</option>
105 <option value="8">支付宝支付(8折)</option>
106 <option value="7"> 微信支付(7折)</option>
107 <option value="6">京东支付(6折)</option>
108 </select><br/>
109 Q币单价:<input type="text" id="danjian"></input><br/>
110 购买数量:<input type="text" id="shuliang"></input><input type="button"
value="结算" onclick="jiesuan()"></input><br/>
111 结算金额:<input type="text" id="jsje" ></input>
112 </form>
113 </body>
114 </html>
什么web自动化测试
web端测试: 对网页的测试
UI测试: web测试+app测试
web自动化测试:通过代码对网页进行测试
UI测试=web自动化测试+APP自动化测试
selenium简介
selenium是企业主流应用广泛web自动化测试框架
selenium的三大组件:
1、selenium IDE 浏览器插件:实现脚本录制
2、WebDriver 实现对浏览器的各种操作(API包)
3、Grid 分布式执行,用例同时在多个浏览器同时执行,提搞测试效率
web自动化测试环境搭建
环境搭建步骤:
1、安装selenium(第三方库)
cmd命令:pip install selenium
2、安装浏览器(谷歌浏览器)
常见浏览器:chrome浏览器、IE浏览器、Firefox浏览器
3、安装浏览器驱动
谷歌浏览器驱动:chromedriver.exe
IE浏览器驱动:ieserverdriver.exe
Firefox浏览器驱动:geckodirver.exe
特别注意事项:下载驱动版本必须与浏览器的版本一致
下载地址:http://npm.taobao.org/mirrors/chromedriver/
chromedriver.exe文件放置到python安装路径(python.exe所在的路径)
web自动化测试第一个脚本
打开浏览器,加载项目地址
1 from selenium import webdriver
2
3 # 指令1:打开浏览器
4 driver=webdriver.Chrome()
5 # 指令2:加载项目地址
6 driver.get("https://www.baidu.com")
7 # 不断发送其他指令:不同指令操控浏览器做不同的事情
selenium原理及源码讲解
selenium脚本如何操控浏览器进行对应的操作?

三者如何通信,实现web自动化测试:
结合selenium源码讲解selenium的原理:
1、启动浏览器驱动(chromedriver.exe)服务
2、selenium脚本与浏览器驱动建立连接,再selenium脚本发送指令(基于http通信)
(发送指令给浏览器驱动,浏览器驱动控制浏览器操作)
不同的指令对浏览器进行不同的操作
指令包(API包):JsonWireProtocol( JWP)
JsonWireProtocol ∙ SeleniumHQ/selenium Wiki ∙ GitHub
打开浏览器,执行的命令1:
response = self.execute(Command.NEW_SESSION, parameters)
指定请求地址http://ip:端口号/路径+请求方式+请求参数
response = self.command_executor.execute(driver_command, params)
selenium常用浏览器操作及元素定位
元素定位
1、web自动化测试就是通过代码对网页进行测试,在对网页进行测试之前,必须掌握如何
定位元素
2、元素定位的八大方法
1、基于id/name/class/tag_name定位
2、基于a标签元素的链接文本定位
1 """
2 元素定位
3 """
4 import time
5
6 from selenium import webdriver
7
8 driver=webdriver.Chrome()
9 driver.get("http://www.baidu.com")
10 time.sleep(2)
11 # type: WebElement
12 el_select=driver.find_element_by_id("kw")
13 # #通过元素的name属性定位
14 el2=driver.find_element_by_name("wd")
15 # # 通过标签定位 一般情况下 不用这个
16 el4=driver.find_element_by_tag_name("input")
17
18 # class属性定位
19 el3=driver.find_element_by_class_name("s_ipt")
20
21 # 通过链接文本定位
22 el6=driver.find_element_by_link_text("新闻")
23 el6.click()
24
25
26 # # 通过部分链接文本定位
27 el7=driver.find_element_by_partial_link_text("新")
28 el7.click()
29 # 返回元素列表[]
30 els=driver.find_elements_by_partial_link_text("新")
31 driver.find_elements_by_id()
32 driver.find_elements_by_name()
33 driver.find_elements_by_class_name()
34 driver.find_elements_by_tag_name()
基于xpath定位
1 """
2 xpath定位
3
4 find_element_by_xpath基于这个方法来实现
5 """
6
7 # 通过绝对路径定位
8 import time
9 from selenium import webdriver
10
11
12 driver=webdriver.Chrome()
13 driver.get("http://www.baidu.com")
14 time.sleep(2)
15 # driver.find_element_by_xpath("xpath语句如何来写")
16 # 通过绝对路径定位(不要用) 不只是为了定位这个元素,考虑脚本的稳定 通过/从页面开
始标签一直导航到目标标签
17 el1=driver.find_element_by_xpath("/html/body/div[1]/div[1]/div[5]/div/di
v/form/span[1]/input")
18 # 通过相对路径定位 //开头 经常用到的方法
19 el2=driver.find_element_by_xpath("//form/span/input")
20
21 # 标签+索引=唯一定位目标标签
22 el3=driver.find_element_by_xpath("//form/span[1]/input")
23 # 唯一定位标签+属性
24 el4=driver.find_element_by_xpath("//form[@id='form']/span[1]/input[@id
='kw']")
25 # 唯一定位标签+多个属性
26 el5=driver.find_element_by_xpath("//form[@id='form'and @name='f']/span
[1]/input[@id='kw']")
27 # 标签+部分属性定位 s_ipt
28 el6=driver.find_element_by_xpath("//form/span[1]/input[substring(@class,
3)='ipt']")
29 el7=driver.find_element_by_xpath("//form/span[1]/input[contains(@id,'k
w')]")
30 el8=driver.find_element_by_xpath("//form/span[1]/input[starts‐with(@i
d,'k')]")
31 el9=driver.find_element_by_xpath("//div[@id='s‐top‐left']/a[text()='新
闻']")
32 # 元素操作:输入 send_keys
33 el7.send_keys("码尚教育")
34 time.sleep(2)
35 driver.close()
36 # copyxpath 页面工具复制
37 el10=driver.find_element_by_xpath('//*[@id="kw"]')
38 # //标签[属性]
39 # 通过文本定位
40 el11=driver.find_element_by_xpath("//a[text()='新闻']")
41 el6.click()
42 # xpath定位 =属性+文本+索引 综合使用
43 # xpath定位能否定位到
元素定位不到可能的原因
1、定位语句不对
2、是否加等待
3、元素嵌套在iframe/frame元素标签中(切换frame)
多层嵌套frame/iframe
4、要定位的元素非当前窗口(切换句柄)
一、弹窗处理
driver.switch_to.alert
1
2 import time
3
4 from selenium.webdriver.common.by import By
5 from selenium import webdriver
6
7 driver=webdriver.Chrome()
8 driver.get(r"C:\Users\xingyao\Desktop\test.html")
9
10 el=driver.find_element(By.ID,"1")
11 time.sleep(2)
12 el.click()
13 # 弹窗进行处理
14 alert=driver.switch_to.alert
15 print(alert.text)
16 # 点击确认
17 # alert.accept()
18
19 time.sleep(2)
20 driver.close()
二、下拉框操作
1 """
2 实现下拉框的操作
3 from selenium.webdriver.support.select import Select
4 """
5 from selenium.webdriver.support.select import Select
6
7 import time
8
9 from selenium.webdriver.common.by import By
10 from selenium import webdriver
11
12 driver=webdriver.Chrome()
13 driver.get(r"C:\Users\xingyao\Desktop\test.html")
14
15 # 定位下拉框
16 el1=driver.find_element(By.ID,"banji")
17 select=Select(el1)
18 # 展示下拉框所有选项内容显示
19 print("展示下拉框所有选项内容",select.options)
20 time.sleep(2)
21
22 # 实现选择下拉框选项选择 有三种方式 索引 value 选项内容
23 select.select_by_index(1)
24 time.sleep(2)
25 select.select_by_value("22")
26 time.sleep(2)
27 select.select_by_visible_text("全栈VIP23期")
28 time.sleep(2)
29 driver.close()
键盘操作
1 """
2 键盘操作
3
4 """
5 import time
6
7 from selenium import webdriver
8 from selenium.webdriver.common.by import By
9 from selenium.webdriver.common.keys import Keys
10
11
12 driver=webdriver.Chrome()
13 driver.get("https://www.baidu.com")
14 driver.find_element(By.ID,"kw").send_keys("码尚教育")
15 time.sleep(2)
16 # ctrl+a
17 driver.find_element(By.ID,"kw").send_keys(Keys.CONTROL,'a')
18
19 # ctrl+c
20 driver.find_element(By.ID,"kw").send_keys(Keys.CONTROL,'c')
21 # ctrl+x
22 driver.find_element(By.ID,"kw").send_keys(Keys.CONTROL,'x')
23 driver.find_element(By.ID,"kw").clear()
24 time.sleep(2)
25 # ctrl+v
26 driver.find_element(By.ID,"kw").send_keys(Keys.CONTROL,'v')
27
28 time.sleep(2)
29 driver.close()
鼠标操作
1 """
2 鼠标操作
3 ActionChains 动作链
4 可以把多个鼠标操作按照顺序连贯的统一执行
5 """
6 from selenium.webdriver import ActionChains
7
8
9 import time
10
11 from selenium.webdriver.common.by import By
12 from selenium import webdriver
13
14 driver=webdriver.Chrome()
15 driver.get("https://www.baidu.com")
16 driver.maximize_window()
17 time.sleep(2)
18 el_set=driver.find_element(By.ID,"s‐usersetting‐top")
19 # ActionChains(driver).move_to_element(el_set).perform()
20 # 第二种写法
21 actions=ActionChains(driver)
22 actions.move_to_element(el_set)
23 actions.perform()
24 time.sleep(1)
25 el_gjselect=driver.find_element(By.LINK_TEXT,"高级搜索")
26 el_gjselect.click()
27 time.sleep(2)
28 driver.close()
29
30 """
31 ActionChains 常用的鼠标操作方法
32 鼠标常用操作:
33 滑块操作
34 click_and_hold 点击鼠标左键不松开
35 context_click 鼠标右击
36 double_click 双击
37 drag_and_drop 从一个元素拖到鼠标到另外一个元素
38 drag_and_drop_by_offset 拖到某个坐标松开
39 move_by_offset 鼠标从当前位置移动到某个坐标
40 move_to_element
41 move_to_element_with_offset 移动到距某个元素(左上角坐标)多少距离的位置
42 pause 停留
43 release 释放鼠标
44 """
45
css定位
1 """
2 css定位
3 基于find_element_by_css_selector()实现
4 """
5 import time
6
7 from selenium import webdriver
8 from selenium.webdriver.common.by import By
9
10 driver=webdriver.Chrome()
11 driver.get("https://www.baidu.com")
12
13
14 # 通过绝对路径进行定位 一般不用
15 el1=driver.find_element_by_css_selector("html body div div div div div f
orm span input ")
16 el2=driver.find_element_by_css_selector("html>body> div> div> div> div >
div> form> span> input ")
17
18
19 # 2通过id定位 #id属性值
20 # 3通过class属性定位 .class属性值 s_ipt
21 el3=driver.find_element_by_css_selector("#kw")
22
23 el4=driver.find_element_by_css_selector('.s_ipt')
24 # 4通过其他属性定位,并且多个属性定位
25 el5=driver.find_element_by_css_selector("[autocomplete='off']")
26 el6=driver.find_element_by_css_selector("[autocomplete='off'][class='s_i
pt']")
27 # 5通过标签定位 标签名+属性/id/class进行定位 组合定位
28 el7=driver.find_element_by_css_selector("input#kw")
29 el8=driver.find_element_by_css_selector("input.s_ipt")
30 el9=driver.find_element_by_css_selector("input[autocomplete='off']")
31
32 #6通过层级定位 层级之间通过>或者空格隔开 相对路径
33 el10=driver.find_element_by_css_selector("form#form>span>input#kw")
34
35 # 通过兄弟节点定位
36 # 场景:同一个元素下面多一个相同的元素 多胞兄弟
37 # 第一个元素 标签:first‐child
38 # 第二个元素 标签:nth‐child(n)
39 # 最后元素 标签:last‐of‐type
40
41 el11=driver.find_element_by_css_selector("div#s‐top‐left>a:first‐child")
42 el12=driver.find_element_by_css_selector("div#s‐top‐left>a:nth‐
child(3)")
43
44 el13=driver.find_element_by_css_selector("div#s‐top‐left>a:last‐of‐
type")
45 # el13.click()
46 # el10.send_keys("chromedriver")
47 # time.sleep(2)
48 # driver.close()
49
50 """
51 定位多个元素
52 """
53 ellist=driver.find_elements_by_css_selector("#kw")
54 print(ellist)
55 # 返回WebElement
56 el14=ellist[0]
57
58
59 """
60 元素定位是否通过一个方法,支持所有的定位方式定位到元素
61 find_element()
62 find_elements() 基于多个定位方式找到一组元素
63 """
64
65 el15=driver.find_element(By.CSS_SELECTOR,"#kw")
66
67 el16=driver.find_element(By.ID,"kw")
68
69 el14.send_keys("chromedriver")
70 time.sleep(2)
71 driver.close()
72
73 """
74 webdriver底层关于元素定位 8+8+2=18
75
76 """
二、元素的常用操作
四大操作:
1、输入
2、点击
3、获取文本
4、获取属性
1
2 """
3 元素四大操作
4 """
5 import time
6 from selenium import webdriver
7 from selenium.webdriver.common.by import By
8
9 driver=webdriver.Chrome()
10 driver.get("http://www.baidu.com")
11 time.sleep(2)
12 el1=driver.find_element(By.ID,"kw")
13 # 输入
14 # el1.send_keys()
15 # 点击
16 # el1.click()
17 # 获取元素文本内容
18 el2=driver.find_element(By.LINK_TEXT,"新闻")
19 print("打印该元素的文本内容:",el2.text)
20 # 获取元素的属性
21 print("获取autocomplete属性值:",el1.get_attribute("autocomplete"))
22
三、三大切换
1、切换窗口:当定位的元素不在当前窗口,则需要切换窗口
import time
3 from selenium import webdriver
4 from selenium.webdriver.common.by import By
5 from selenium.webdriver.support.wait import WebDriverWait
6 from selenium.webdriver.support import expected_conditions as EC
7
8 """
9 元素等待:
10 1、强制等待 time.sleep(秒数) 停留
11 2、智能等待(隐士等待) driver.implicitly_wait(秒数) 给页面上所有的元素设置全
局等待时间
12 只要在设置的时间范围内找到了元素,就会执行下一个代码,最多等待设置的时间
13 3、显示等待 显示等待:等待当前需要操作的元素 基于多种条件+等待元素
14 多种条件:等待元素可见?等待url跳转为xxx?等待新窗口出现?很多场景条件
15 from selenium.webdriver.support.wait import WebDriverWait
16 from selenium.webdriver.support import expected_conditions
17 自动化测试框架脚本:
18 以显示等待为主
19 以强制等待为辅
20 """
21
22
23 driver=webdriver.Chrome()
24 # 智能等待
25 # driver.implicitly_wait(10)
26 driver.get("http://www.baidu.com")
27 # 输入搜索内容
28 el1=driver.find_element(By.ID,"kw")
29 el1.send_keys("chromedriver")
30 #点击百度一下
31 el2=driver.find_element(By.ID,'su')
32 el2.click()
33 # 显示等待
34 loc=(By.LINK_TEXT,"ChromeDriver Mirror")
35 # 等待元素存在
36 WebDriverWait(driver,15,0.5).until(EC.presence_of_element_located(loc))
37 # 点击搜索的内容
38 el3=driver.find_element(*loc)
39 el3.click()
40 # 新打开的窗口里面定位元素 需要切换窗口
41 # 获取浏览器窗口列表 最早打开的窗口放到list的最前面
42 wins=driver.window_handles
43 print(wins)
44 # 切换最后打开的窗口
45 driver.switch_to.window(wins[‐1])
46
47 el4=driver.find_element(By.LINK_TEXT,"2.0/")
48 el4.click()
49 # 为了看到效果
50 time.sleep(3)
51 driver.close()
切换iframe:当定位的元素在frame/iframe,则需要切换
1 """
2 定位的元素包含在iframe/frame标签里面
3 切换到iframe/frame
4 """
5 import time
6
7 from selenium.webdriver.common.by import By
8 from selenium import webdriver
9
10 driver=webdriver.Chrome()
11 driver.get("https://ke.qq.com/?tuin=80805fad")
12
13 driver.find_element(By.ID,"js_login").click()
14 time.sleep(2)
15 # 切换iframe 方式一:id
16 # driver.switch_to.frame("id")
17 # 切换iframe 方式二:索引 索引值从0开始
18 driver.switch_to.frame(1)
19 # 切换iframe 方式三:找到iframe元素
20 # driver.switch_to.frame(driver.find_elements(By.XPATH,"//iframe")[2])
21 # 再定位元素
22 driver.find_element(By.LINK_TEXT,"帐号密码登录").click()
23 time.sleep(2)
24 driver.close()
元素三大等待
import time
3 from selenium import webdriver
4 from selenium.webdriver.common.by import By
5 from selenium.webdriver.support.wait import WebDriverWait
6 from selenium.webdriver.support import expected_conditions as EC
7
8 """
9 元素等待:
10 1、强制等待 time.sleep(秒数) 停留
11 2、智能等待(隐士等待) driver.implicitly_wait(秒数) 给页面上所有的元素设置全
局等待时间
12 只要在设置的时间范围内找到了元素,就会执行下一个代码,最多等待设置的时间
13 3、显示等待 显示等待:等待当前需要操作的元素 基于多种条件+等待元素
14 多种条件:等待元素可见?等待url跳转为xxx?等待新窗口出现?很多场景条件
15 from selenium.webdriver.support.wait import WebDriverWait
16 from selenium.webdriver.support import expected_conditions
17 自动化测试框架脚本:
18 以显示等待为主
19 以强制等待为辅
20 """
21
22
23 driver=webdriver.Chrome()
24 # 智能等待
25 # driver.implicitly_wait(10)
26 driver.get("http://www.baidu.com")
27 # 输入搜索内容
28 el1=driver.find_element(By.ID,"kw")
29 el1.send_keys("chromedriver")
30 #点击百度一下
31 el2=driver.find_element(By.ID,'su')
32 el2.click()
33 # 显示等待
34 loc=(By.LINK_TEXT,"ChromeDriver Mirror")
35 # 等待元素存在
36 WebDriverWait(driver,15,0.5).until(EC.presence_of_element_located(loc))
37 # 点击搜索的内容
38 el3=driver.find_element(*loc)
39 el3.click()
40 # 新打开的窗口里面定位元素 需要切换窗口
41 # 获取浏览器窗口列表 最早打开的窗口放到list的最前面
42 wins=driver.window_handles
43 print(wins)
44 # 切换最后打开的窗口
45 driver.switch_to.window(wins[‐1])
46
47 el4=driver.find_element(By.LINK_TEXT,"2.0/")
48 el4.click()
49 # 为了看到效果
50 time.sleep(3)
51 driver.close()
一、日期控件
只读控件的日期控件,如何实现输入?
javascript 实现 调用execute_script
1 """
2 js操作
3 execute_script
4 """
5
6 import time
7 from selenium import webdriver
8 from selenium.webdriver.common.by import By
9 from selenium.webdriver.common.keys import Keys
10
11
12 driver=webdriver.Chrome()
13 driver.get("https://www.12306.cn/index/")
14 time.sleep(2)
15 # 只读日期控件元素
16 el_data=driver.find_element(By.ID,"train_date")
17 # 去掉readonly属性‐‐‐》通过js操作元素driver.execute_script()
18 # arguments 把execute_script后面的第二个或者第三个或者到第n个参数到放在argum
ents
19 js="var el=arguments[0];el.removeAttribute('readonly');"
20 # 执行js脚本,去掉readonly属性
21 driver.execute_script(js,el_data)
22 # 清除日期控件默认值
23 el_data.clear()
24 time.sleep(2)
25 # # 日期控件输入设置的日期
26 el_data.send_keys('2021‐10‐01')
27 print("时间控件设置的日期:",el_data.get_attribute("value"))
二、滚动条操作
什么情况下,需要把元素放到可见区域我才可以操作呢?
懒加载/慢加载 必须把元素移动可见区域,才会实现加载 ----》滚动条操作
execute_script
1 """
2 滚动条操作
3 """
4 import time
5 from selenium import webdriver
6 from selenium.webdriver.common.by import By
7 from selenium.webdriver.common.keys import Keys
8 from selenium.webdriver.support.wait import WebDriverWait
9 from selenium.webdriver.support import expected_conditions as EC
10
11 driver=webdriver.Chrome()
12 driver.get("https://www.baidu.com")
13 driver.find_element(By.ID,"kw").send_keys("selenium webdriver")
14 driver.find_element(By.ID,"su").click()
15 loc=(By.XPATH,"//div[@id='7']/h3/a")
16 # 显示等待 presence_of_element_located不一定元素可见,只要存在即可
17 WebDriverWait(driver,15).until(EC.presence_of_element_located(loc))
18 el2=driver.find_element(*loc)
19 time.sleep(2)
20 # el2.click()
21 # 实现滚动条从顶部到底部
22 driver.execute_script("scrollTo(0,document.body.scrollHeight)")
23 time.sleep(2)
24 # 实现滚动条从浏览器底部到顶部
25 driver.execute_script("scrollTo(document.body.scrollHeight,0)")
26 time.sleep(2)
27 # 操作哪个元素,滚动条移动到元素附近(元素与页面的顶部对齐,元素与页面的底部对
齐)
28 js2="arguments[0].scrollIntoView(false);"
29 driver.execute_script(js2,el2)
30 time.sleep(2)
三、文件上传
1 """
2 文件上传操作
3
4 类型一:支持直接输入
5
6 类型二:不可以直接输入,只能选择
7 """
8 import time
9 from selenium import webdriver
10 from selenium.webdriver import ActionChains
11 from selenium.webdriver.common.by import By
12
13
14 # 类型一:支持直接输入
15 driver=webdriver.Chrome()
16 driver.get(r"E:\VIP\M211\web\WebCode\class06\test.html")
17 time.sleep(4)
18 el_file=driver.find_element(By.ID,"f1")
19 el_file.send_keys(r"E:\VIP\M211\web\WebCode\class06\test.html")
20 time.sleep(2)
21 driver.close()
22
23 # 类型二:不可以直接输入,只能选择
24 # 如何定位windows窗口及窗口的元素?
25 # 环境准备
26 # 1、定位工具(失败window窗口及元素)‐‐‐winSpy
27 # 2、第三方库 pywin3
28 # 安装: pip install pywin3
29 # 切换源 pip install ‐i https://pypi.douban.com/simple pywin3
30 # 如何定位windows窗口及窗口的元素?
31 #文件上传输入框: #32770‐ComboBoxEx32 ‐ComboBox ‐Edit
32 # 打开按钮:#32770‐Button
33
34 import win32gui
35 import win32con
36
37 driver=webdriver.Chrome()
38 driver.get(r"E:\VIP\M211\web\WebCode\class06\test.html")
39 time.sleep(4)
40 el_file=driver.find_element(By.ID,"f1")
41 ActionChains(driver).move_to_element(el_file).click().perform()
42 def upload(filePath,browser_type="Chrome"):
43 if browser_type == "Chrome":
44 title = "打开"
45 else:
46 title = "文件上传"
47 #32770‐ComboBoxEx32 ‐ComboBox ‐Edit
48 dialog = win32gui.FindWindow("#32770",title) #一级窗口 ‘打开窗口’
49 ComboBoxEx32 = win32gui.FindWindowEx(dialog,0,"ComboBoxEx32",None) #二级
50 ComboBox = win32gui.FindWindowEx(ComboBoxEx32,0,"ComboBox",None) #三级
51 edit = win32gui.FindWindowEx(ComboBox,0,"Edit",None) #四级
52 # 32770‐Button
53 button = win32gui.FindWindowEx(dialog,0,"Button",None) #四级
54 # 往文件名编辑框中输入文件路径
55 # 上传操作
56 win32gui.SendMessage(edit,win32con.WM_SETTEXT,None,filePath)
57 win32gui.SendMessage(dialog,win32con.WM_COMMAND,1,button) #点击打开按钮
58
59 filepath=r"E:\VIP\M211\web\WebCode\class06\test.html"
60 time.sleep(5)
61 upload(filePath=filepath)
62 print("文件上传成功")
63 time.sleep(10)
Unittest框架
Unittest框架:框架=测试模块+测试管理模块+测试统计模块,python的内置模块
import unittest
Unittest框架四大组件:
1、TestCase 测试用例
2、TestFixture
3、TestSuite
4、TestRunner
三、TestCase 测试用例
unittest中TestCase部分的规则:
1、用例类必须继承Unittest.TestCase,并且以test开头
2、每条用例,都必须以test开头
3、用例执行的顺序按照ASCII
0-9 a-z A-Z 顺序来执行用例
unittest也可以通过命令运行
命令执行TestShopnc类下的所有用例: python -m unittest 用例文件名.用例类
执行某一条用例: python -m unittest 用例文件名.用例类.用例名称
1
2 class TestShopnc(unittest.TestCase):
3
4 def test01_login(self):
5 # 用例操作步骤
6 # self.driver = webdriver.Chrome()
7 # self.driver.get("https://www.baidu.com")
8 # el1=self.driver.find_element(By.ID,"kw")
9 # el1.send_keys("码尚教育")
10 print("用例01")
11 #用例断言?
12
13 def test02_selectgoods(self):
14 print("用例02")
15
16 def test03_intocart(self):
17 print("用例03")
18
19 def test04_paygoods(self):
20 print("用例04")
TestFixture 测试夹具 执行测试用例前的前置操作及后置操作
web自动化测试:
前置操作:
后置操作:
1 # 前置操作
2 def setUp(self):
3 #
4 webdriver.Chrome.close()
5 webdriver.Chrome.quit()
6 # 加载项目
7 print("setUp执行每条用例前都会执行函数代码,有n条用例,则会执行n次")
8
9 @classmethod
10 def setUpClass(cls):
11 # 前置操作:连接数据,打开浏览器
12 print("setUpClass执行用例前会执行 ,总共只执行一次")
13
14 # 后置操作
15 def tearDown(self) ‐> None:
16 # 后置操作:浏览器的关闭
17 print("tearDown执行完每条用例前都会执行代码,有n条用例,则会执行n次")
18
19 @classmethod
20 def tearDownClass(cls) ‐> None:
21 # 退出浏览器,关闭数据库连接,清理数据
22 print("tearDownClass执行完所有用例之后会执行代码 ,总共只执行一次")
TestSuite 测试套件 用例集(把需要执行的用例汇总到一起)
1、用例加载器
1
2 if __name__ == '__main__':
3
4 print("main方法")
5 suite=unittest.TestSuite()
6 # 添加一个用例
7 suite.addTest(TestShopnc('test01_login'))
8 suite.addTest(TestShopnc('test02_ashopping'))
9 # # 添加多个用例
10 caselist=[TestShopnc('test03_intocart'),TestShopnc('test04_paygood')]
11 suite.addTests(caselist)
12 # 用例加载器
13 # 用例 TestLoader() suite
14 # loadTestsFromTestCase 加载某个用例类(继承TestCase)下的所有用例
15 suite2=unittest.TestSuite()
16 testcases=unittest.TestLoader().loadTestsFromTestCase(TestShopnc)
17 suite.addTests(testcases)
18 # 利用默认加载器实现加载用例
19 suite3 = unittest.TestSuite()
20 # 匹配test*.py用例文件名称
21 testcases=unittest.defaultTestLoader.discover('test*.py')
22 unittest.main(defaultTest="suite3")
六、TestRunner 测试运行器 执行用例,把执行的结果输出给到用户
用例执行结果状态:
. 用例执行成功
E 用例有异常
F 用例执行失败(断言失败)
unitest的应用
一、TestRunner 测试运行器 执行用例,输出测试结果
1、unittest提供生产测试报告的模块 TextTestRunner 生成文本格式测试报告
2、常见的第三方库结合unittest生产html格式测试报告
HtmlTestRunner
官网下载HtmlTestRunner.py只能支持python2版本,支持Python3,需要做修改
路径:python安装路径/Lib
HtmlTestRunner 的应用
BeatifulReport 的应用
企业测试报告的优化及定制 优化测试报告模板 通过js+html/html5
pytest+allure 生成更加美观的测试报告+优化定制(装饰器)
1 import unittest
2 from class08.testcase_01 import TestCase01
3 import HTMLTestRunner
4 import BeautifulReport
5 from BeautifulReport import BeautifulReport
6
7 # 加载用例
8 testcases=unittest.TestLoader().loadTestsFromTestCase(TestCase01)
9 # 执行用例,生产对应的测试报告TextTestRunner
10 # with open('./reports/report.txt',"w+") as txtfile:
11 #文件写入测试结果
12 # unittest.TextTestRunner(stream=txtfile,verbosity=2).run(testcases)
13
14 #HTMLTestRunner生成的测试报告
15 # with open('./reports/report.html', "wb+") as htmlfile:
16 # runner=HTMLTestRunner.HTMLTestRunner(stream=htmlfile,title="码尚教育测
试报告",description="码尚教育测试用例详情")
17 # runner.run(testcases)
18 #BeautifulReport 生成的测试报告
19 with open('./reports/report.html', "wb+") as htmlfile:
20 BeautifulReport(testcases).report(description="码尚教育测试报
告",filename="report_bf",report_dir="reports")
二、装饰器 @ unittest.skip 强制跳过&条件跳过
1
2 class TestCase01(unittest.TestCase):
3
4 @unittest.skip("此用例暂时不启用")
5 def test_login(self):
6 """
7 登录
8 :return:
9 """
10 print("用例01")
11 @unittest.skipIf(3>2,"条件为真,则跳过执行")
12 def test_selectgoods(self):
13 """
14 检索商品
15 :return:
16 """
17 print("用例02")
18
19 @unittest.skipUnless(2>3,"条件:2>3不成立,则跳过执行")
20 def test_gointocart(self):
21 """
22 加入购物车
23 :return:
24 """
25 print("用例03")
1 """
2 @unittest.skip 强制跳过执行
3 @unittest.skipIf 符合条件,则跳过执行
4 @unittest.skipUnless 条件不成立,则跳过执行
5 """
6 import unittest
7
8 @unittest.skipUnless(False,"整个模块下的用例强制跳过执行")
9 class TestSkipModule(unittest.TestCase):
10
11 def test_login(self):
12 """
13 登录
14 :return:
15 """
16 print("用例01")
17
18 def test_selectgoods(self):
19 """
20 检索商品
21 :return:
22 """
23 print("用例02")
24
25 def test_gointocart(self):
26 """
27 加入购物车
28 :return:
29 """
30 print("用例03")
31
32 if __name__ == '__main__':
33 unittest.main()
三、unittest的常用断言方法
1 常用断言方法
2 1、assertIn(字符1,字符2) 字符1是否包含在字符2
3 2、self.assertNotIn(字符1,字符2) 字符1不包含包含在字符2
4 self.assertEqual(参数1,参数2,"断言失败的描述") 参数1等于参数2
5 self.assertNotEqual(参数1,参数2,"断言失败的描述")参数不等于参数2
6 self.assertTrue(True)
7 self.assertFalse(False)
from selenium import webdriver
2
3 class TestCase01(unittest.TestCase):
4
5 def setUp(self) ‐> None:
6 # 打开chrome浏览器
7 self.driver=webdriver.Chrome()
8
9 def test_selectgoods(self):
10 """
11 检索商品
12 :return:
13 """
14 self.driver.get("http://47.107.116.139/shopnc/shop/")
15 # 定位搜索输入
16 el_select=self.driver.find_element(By.ID,"keyword")
17 el_select.send_keys("手机")
18 el_button=self.driver.find_element(By.ID,"button")
19 el_button.click()
20 time.sleep(2)
21 #断言:验证测试结果与预期结果是否一致
22 #获取商品列表的标题
23 content=self.driver.find_element(By.XPATH,"//div[@class='goods‐name']/
a").text
24 print(content)
25 #判断content是否包含手机字符?
26 #常用断言方法
27 """
28 常用断言方法
29 1、assertIn(字符1,字符2) 字符1是否包含在字符2
30 2、self.assertNotIn(字符1,字符2) 字符1不包含包含在字符2
31 self.assertEqual(参数1,参数2,"断言失败的描述") 参数1等于参数2
32 self.assertNotEqual(参数1,参数2,"断言失败的描述")参数不等于参数2
33 self.assertTrue(True)
34 self.assertFalse(False)
35 """
36 # 标题是否包含手机
37 self.assertIn("手机2222",content,"断言失败的描述")
38 #列表下有多少个商品 返回元素列表得到个数
39 # count=els.count
40 # self.assertEqual(count,1)
自动化测试框架之pom设计模式详解
一、什么是POM
POM page object model 页面对象模型 WEB自动化测试框架应用最为广泛的一种框架
设计模式
设计思路:web项目由很多页面组成,把每个页面当做页面对象来进行设计
Python专题:什么是对象?通过类描述一组对象 对象=属性+方法
码尚电商项目=n个页面=登录页面=对每个页面设计对应页面类=相同属性+相同的方法
登录页面=对每个页面设计对应页面类=相同属性+相同的方法
class LoginPage:
#属性?元素、页面标题…
#方法?你在页面进行操作/行为:点击、定位、输入…等等元素及页面的操作
每个页面有相同的属性及方法 比如:点击、输入、元素定位
基于POM进行设计分为四层进行架构:
第一层 basepage层 每个页面有相同的属性及方法 比如:点击、输入、元素定位
第二层 pageobjects层 针对每个页面定义页面类 每个页面有独有的属性及方法
登录页面 LoginPage类
注册页面 RegisterPage类
第三层 TestCases层 用例层包含项目的业务流程
第四层 TestData 测试数据
二、如何基于POM进行自动化框架架构?
1、base层封装
1 import time
2 from selenium import webdriver
3 from selenium.webdriver.common.by import By
4
5 class BasePage:
6 """
7 BasePage:定义每个页面的相同属性及方法
8 相同属性?获取浏览器驱动对象(数据)
9 相同方法?元素定位、点击、输入...等等操作
10 """
11 def __init__(self,driver=webdriver.Chrome()):
12 self.driver=driver
13
14 def locator(self,loc):
15 """元素定位"""
16 # loc=(By.LINK_TEXT,"登录")
17 # WebElement对象
18 return self.driver.find_element(*loc)
19
20 def input(self,loc,value):
21 """输入"""
22 self.locator(loc).send_keys(value)
23
24 def click(self,loc):
25 """点击"""
26 self.locator(loc).click()
27
28 def sleep(self,s):
29 time.sleep(s)
2、pageobjects层封装
1 import time
2
3 from selenium.webdriver.common.by import By
4
5 from class09.base.basepage import BasePage
6
7
8 class LoginPage(BasePage):
9 """
10 登录页面类=页面独有的属性及方法
11 页面独有的属性:页面元素定位
12 方法:登录页面的操作
13 """
14 #登录页面的属性
15 el_username=(By.ID,"user_name")
16 el_password=(By.ID, "password")
17 el_login=(By.XPATH, "//input[@name='Submit']")
18 url="http://47.107.116.139/shopnc/shop/index.php?act=login&op=index"
19
20 #方法
21 def login(self,usname,passwd):
22 #实现登录的步骤
23 self.driver.get(self.url)
24 self.sleep(2)
25 # 输入用户名
26 self.input(loc=self.el_username,value=usname)
27 # 输入密码
28 self.input(loc=self.el_password,value=passwd)
29 # 点击登录
30 self.click(loc=self.el_login)
31 time.sleep(2)
32
33
34 class GoodlistPage(BasePage):
35 pass
3、TestCases层封装
1 import unittest
2 from class09.pageobjects.webpage import LoginPage
3
4 class TestLogin(unittest.TestCase):
5 def test_login(self):
6 # 实例化对象
7 loginpage=LoginPage()
8 username = "xingyao"
9 password = "mashang"
10 loginpage.login(username,password)
数据驱动:现在主流的设计模式之一(以数据驱动测试)
结合unittest框架如何实现数据驱动?ddt模块实现
数据驱动的意义:通过不同的数据对同一脚本实现循环测试,最终实现数据与脚本的分离
ddt模块模块的安装 pip install ddt
ddt模块:一个类装饰器+三个装饰器方法
ddt类装饰器 装饰继承unittest.TestCase的类
data装饰器方法 data()装饰器方法把列表、元组、字典作为参数
unpack装饰器方法 实现把复杂的数据实现分解成多个数据
file_data装饰器方法 可以直接接收数据文件(json数据/基于yaml数据文件),实现循环
测试
关键字驱动:现在主流的设计模式之一
什么关键字驱动?(以关键字函数驱动测试)
关键字驱动又叫动作字驱动
把项目业务封装成关键字函数,再基于关键字函数实现自动化测试
项目业务实现转化为关键字函数?
覆盖项目业务=用例集合覆盖测试
用例集合=一个一个用例实现覆盖测试
覆盖用例=多个操作步骤组成=多个关键字函数
操作步骤封装成对应的关键字函数
比如:登录用例
登录用例=多个操作步骤组成 基于每个操作步骤封装对应的关键字函数
登录用例:
1、打开浏览器 关键字函数open_browser()
2、加载项目地址 关键字函数load_url()
3、输入用户名 关键字函数 input()
4、输入密码 关键字函数 input()
5、点击登录 关键字函数 click()
pom :把每个页面当做一个对象来进行编程 实现某个业务流程的测试=调用页面对象的一
些属性及方法实现测试
数据驱动:用外部数据驱动测试
关键字驱动:所有业务流程封装成对应的函数 实现某个业务流程的测试=调用多个关键字
方法,实现业务流程的测试
App环境搭建&Appium运行原理详解
一、APP环境搭建
1、安装JDK,配置jdk环境变量
2、安装配置android sdk
3、Appium server安装
4、安装模拟器(夜神模拟器)
5、安装Python的第三方库 appium-python-client
二、Appium及Appium自动化测试原理
Appium跨平台、开源的app自动化测试框架,用来测试app应用程序,支持Android/IOS
操作系统
为什么通过代码操作不同的操作系统(Android/IOS)不同版本的手机终端的应用程序?
web自动测试:如何通过代码,实现操作pc端的浏览器进行对应的操作?
代码selenium中webdriver–xxx浏览器驱动----操控浏览器实现对应操作
app自动化测试:
代码-----? 操控手机端的应用程序,实现对应app自动化测试

三、Appium自动化配置项
不同系统不同版本可能用到不同的软件包/框架----》python脚本指定操作终端的这些参数
设置
Desired Capabilities - Appium
常用必备参数:
platformName 操作系统(IOS/android) Android
platformVersion 版本 5.1.1
deviceName 设备名称 ? 127.0.0.1:62001
appPackage 包名 ‘com.tal.kaoyan’
appActivity 入口启动页面 ‘com.tal.kaoyan.ui.activity.SplashActivity’
四、常见ADB命令
ADB命令:命令调试桥
1、连接模拟器 命令:查看连接设备:adb devices 或者 连接设备: adb connect
127.0.0.1:62001
不同模拟器端口号不同:雷神:5555 夜神:62001 mumu:7555 逍遥:21503
2、获取包名及入口启动页面
aapt dump badging apk包路径 C:\Users\xingyao\Desktop\kaoyan3.1.0.apk
进入aapt.exe所在的路径(D:\Andriod_SDK\Andriod_SDK\build-tools\29.0.3),再输
入命令
命令:aapt dump badging C:\Users\xingyao\Desktop\kaoyan3.1.0.apk
app 应用程序如何装到模拟器上
获取包名:
获取启动页面appActivity 的值

启动被测app应用程序
python脚本发送http请求给到appium server ,实现操控app应用程序
进行其他的操作,继续下一个http请求
六、查看详细日志文件
1、自动化脚本发送 http请求,请求参数:终端设置参数
2、创建会话
3、确认终端设备是否连接,并且确认安卓的版本 确认设置其他参数与终端是否一致
4、 appium会推送一个包’AppiumBootstrap.jar’
AppiumBootstrap.jar:实现appium server与手机终端进行数据交互
5、下一个http请求
APP自动化测试环境搭建
1、安装jdk
1、系统变量→新建 JAVA_HOME 变量,变量值填写jdk的安装目
录
2、系统变量→寻找 Path 变量→编辑,在变量值最后输入
%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;
3、系统变量→新建 CLASSPATH 变量;变量值填写
.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar
4、检验是JDK否配置成功 运行cmd 输入 java -version ,如果出
现如下结果,则说明JDk环境变量配置成功
2、安装配置Andriod sdk
解压SDK并配置SDK的环境变量。
(1)SDK的下载
下载地址:http://tools.android-studio.org/index.php/sdk/
下载版本选择:android-sdk_r24.4.1-windows.zip
(2)SDK的安装
进入D:\android-sdk-windows目录,双击SDK Manager.exe下载对应
的包:
a.以下三个Android工具包必须安装:只需要下载最新的版本就行了。


c.安卓版本:安装和模拟器的安卓版本一致。现在android 5开发的场景多一些

(3)配置SDK的环境变量
我的电脑右键属性–>高级系统设置–>高级–>环境变量–>系统变量:
1、新建:
变量名:ANDROID_HOME
变量值:D:\android-sdk-windows (SDK的实际安装路径)
2、编辑PATH,在最后面添加:
%ANDROID_HOME%\platformtools;%ANDROID_HOME%\tools;%ANDROID_HOME%\buildtools\29.0.3;
(如果原来PATH路径最后不是;则加一个;再添加上面的内容)
3、验证是否安装并配置成功:
在dos中输入adb验证。
3、模拟器的安装-夜神
(1)夜神模拟器的下载
下载地址:https://www.yeshen.com/
版本选择:最新版
(2)夜神模拟器的安装
下一步下一步傻瓜式安装。
(3)被测app的安装
把apk包直接拖拽到夜神模拟中安装
(4)设置模拟器/真机的环境
a.启用设备的开发者选项,启动调试功能。
夜神模拟器:设置->多次点击版本号直到出现提示【开发者选项】->返
回上一步能看到【开发者选项】->USB调试。
b.输入命令前:因为SDK下的adb[在SDK安装目录的platform-tools目
录下]和模拟器的nox_adb[在夜神安装目录的bin目录下]版本不一致,
所以需要把SDK路径下的abd.exe复制到模拟器的bin路径下,重命名为
nox_adb.exe,原来的ox_adb.exe先备份。
4、安装appium server
解压文件,执行.exe文件,即可
5、安装appium-python-client
pip install appium-python-client
一、Appium常用元素定位工具
1、U IAutomator View Android SDK自带的定位工具
工具所在的位置 Android SDK安装路径/tools/
2、Appium Desktop Inspector
appium server工具自带的定位工具
3、Weditor
Uiautomator2 Python第三方库 appUI自动化测试框架
安装:
命令01: dos命令窗口 ----- pip install Uiautomator2
命令02:dos命令窗口 ----- python -m uiautomator2 init
命令03: dos命令窗口 ----- pip install weditor
确认工具是否安装成功:weditor --help
Weditor工具的使用
1、启动weditor工具
2、选择操作系统,填写设置设备名称,点击连接
3、开始定位元素,获取元素信息
4、退出工具 ctrl c
dos命令窗口-----命令:weditor
通过定位工具获取app页面元素有哪些属性
1、 resourceid
2、class属性/classname 元素标签名
3、text 文本内容
4、description属性(content-desc)
5、元素定位方式 ( weditor提供xpath定位语句)
6、appPackage
7、appActivity (weditor)
二、app元素定位方法
1、resourceid属性定位元素基于find_element_by_id来定位元素
2、通过text属性定位元素 MobileBy.ANDROID_UIAUTOMATOR
这种定位方式利用系统自带框架(Uiautomator1/Uiautomator2)实现元素定位,基于
java代码编写
通过这些框架实现元素定位==实质就是调用这些框架里面的方法(UiSelector类实现元素
定位)
UiSelector - Android中文版 - API参考文档 (apiref.com)
3、基于description属性(content-desc)定位方法:
4、选择xpath定位 等同于web自动化测试xpath定位的方法一致(weditor)
1 # ‐*‐ coding=utf‐8 ‐*‐
2 # @time:2021/8/4
3 # @phone:15874198829
4 # @author:码尚教育_星瑶
5 import time
6
7 from appium import webdriver
8 # web自动测试定位方式
9 from selenium.webdriver.common.by import By
10 # app元素定位方式
11 from appium.webdriver.common.mobileby import MobileBy
12
13
14 # 设置操控终端的配置参数
15 desired_caps={
16 "automationName":"UiAutomator2", #默认框架
17 "platformName":"Android", #指定操作系统
18 "platformVersion":"5.1.1",#指定系统版本
19 "deviceName":"127.0.0.1:62001",#指定设备名称
20 "appPackage":"com.tal.kaoyan",#被操作的应用程序包名
21 "appActivity":"com.tal.kaoyan.ui.activity.SplashActivity" , #启动页面
22 "noReset":"True" # 为true 不重置 为false 重置
23 }
24 # 发送指令给appium server
25 driver=webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_caps)
26 #1、元素定位方式一: resourceid属性定位元素基于find_element_by_id来定位元素
27 username_el=driver.find_element(MobileBy.ID,"com.tal.kaoyan:id/login_ema
il_edittext")
28
29 username_el2=driver.find_element_by_id("com.tal.kaoyan:id/login_email_ed
ittext")
30
31 #1、元素定位方式二: 基于text属性可以用MobileBy.ANDROID_UIAUTOMATOR
32
33 el3=driver.find_element(MobileBy.ANDROID_UIAUTOMATOR,'new UiSelector().t
ext("请输入用户名")')
34 el4=driver.find_element_by_android_uiautomator('new UiSelector().text("请
输入用户名")')
35 # 输入内容
36 # el3.send_keys("xingyao1202")
37
38 # MobileBy.ANDROID_UIAUTOMATOR支持多个属性组合定位:className resourceId
39 # 多个属性组合定位 new UiSelector().方法1().方法2().方法3()
40 # UiSelector类里面的方法,如果参数是字符串类型,必须是双引号
41
42 el5=driver.find_element(MobileBy.ANDROID_UIAUTOMATOR,'new UiSelector().c
lassName("android.widget.EditText").resourceId("com.tal.kaoyan:id/login_pas
sword_edittext") ')
43 el4.send_keys("xingyao1202")
44 time.sleep(2)
45
46
47 #定位方式三:基于content‐desc/description属性定位:MobileBy.ACCESSIBILITY_I
D
48 el6=driver.find_element(MobileBy.ACCESSIBILITY_ID,"content‐desc/descript
ion属性值")
49 el7=driver.find_element_by_accessibility_id("content‐desc/description属性
值")
APP自动化之Appium多点触控&列表滑动&Touchaction应用
一、toast元素的定位
toast元素就是简易的消息提示框,toast显示窗口显示的时间有限,一般3秒左右
1 # ‐*‐ coding=utf‐8 ‐*‐
2 # @time:2021/8/7
3 # @phone:15874198829
4 # @author:码尚教育_星瑶
5
6 # 设置操控终端的配置参数
7 from appium import webdriver
8 from appium.webdriver.common.mobileby import MobileBy
9 from selenium.webdriver.support.wait import WebDriverWait
10 from selenium.webdriver.support import expected_conditions as EC
11
12 desired_caps={
13 "automationName":"UiAutomator2", #默认框架
14 "platformName":"Android", #指定操作系统
15 "platformVersion":"5.1.1",#指定系统版本
16 "deviceName":"127.0.0.1:62001",#指定设备名称
17 "appPackage":"com.tal.kaoyan",#被操作的应用程序包名
18 "appActivity":"com.tal.kaoyan.ui.activity.SplashActivity" , #启动页面
19 "noReset":"True" # 为true 不重置 为false 重置
20 }
21 # 发送指令给appium server
22 driver=webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_caps)
23 # 输入用户名
24 el_username=driver.find_element(MobileBy.ID,"com.tal.kaoyan:id/login_ema
il_edittext")
25 el_username.send_keys("xingyao")
26 # 点击登录
27 el_login=driver.find_element(MobileBy.ID,"com.tal.kaoyan:id/login_login_
btn")
28 el_login.click()
29 #展示toast元素展示的文本内容:邮箱帐户密码不能为空
30 # 定位toast元素 xpath
31 toast_loc=(MobileBy.XPATH,"//*[contains(@text,'邮箱帐户密码不能为空')]")
32 #显示等待
33 # 修改轮询的时间为0.01秒
34 WebDriverWait(driver,15,0.01).until(EC.presence_of_element_located(toast
_loc))
35 toast_text=driver.find_element(*toast_loc).text
36 print("获取toast元素的文本内容:",toast_text)
二、滑屏操作
比如:在app看小说实现翻页
同一个水平位置左滑:
开始位置与结束位置的坐标特点:
Y坐标相同
x坐标从大到小
同一个水平位置右滑:
开始位置与结束位置的坐标特点:
Y坐标相同
x坐标从小到大
上滑:
开始位置与结束位置的坐标特点:
X坐标相同
Y坐标从大到小
下滑:
开始位置与结束位置的坐标特点:
X坐标相同
Y坐标从小到大
1
2 from appium import webdriver
3 from appium.webdriver.common.mobileby import MobileBy
4
5 """
6 滑屏操作
7 """
8
9
10 desired_caps={
11 "automationName":"UiAutomator2", #默认框架
12 "platformName":"Android", #指定操作系统
13 "platformVersion":"5.1.1",#指定系统版本
14 "deviceName":"127.0.0.1:62001",#指定设备名称
15 "appPackage":"com.tal.kaoyan",#被操作的应用程序包名
16 "appActivity":"com.tal.kaoyan.ui.activity.SplashActivity" , #启动页面
17 "noReset":False # 为true 不重置 为false 重置
18 }
19 # 发送指令给appium server
20 driver=webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_caps)
21 # 点击取消
22 el_cancel=driver.find_element(MobileBy.ID,"android:id/button2")
23 el_cancel.click()
24
25 #实现滑屏
26 # 获取整个app屏幕的大小
27 size=driver.get_window_size()
28 x=size["width"]
29 y=size["height"]
30 # 左滑2次
31 for i in range(0,2):
32 driver.swipe(start_x=x*0.9,end_x=x*0.2,start_y=y*0.8,end_y=y*0.8,durati
on=1000)
33 print("实现左滑两次")
34 # 上滑
35 # 下滑
36 # 右滑
三、触屏操作
一、如何查看指针的指针位置

一连串的操作:
首先按压某个元素 press 再移动到元素 move_to 不同圆点移动 最后释放release()
最后:最后调用perform()
多点触控&H5元素定位
1 # ‐*‐ coding=utf‐8 ‐*‐
2 # @time:2021/8/9
3 # @phone:15874198829
4 # @author:码尚教育_星瑶
5 # 单点触控
6 import time
7
8 from appium.webdriver.common.touch_action import TouchAction
9 # 多点触控
10 from appium.webdriver.common.multi_action import MultiAction
11 from appium import webdriver
12 from appium.webdriver.common.mobileby import MobileBy
13 from selenium.webdriver.support.wait import WebDriverWait
14 from selenium.webdriver.support import expected_conditions as EC
15 """
16 MultiAction 多点触控
17 """
18 desired_caps={
19 "automationName":"UiAutomator2", #默认框架
20 "platformName":"Android", #指定操作系统
21 "platformVersion":"7.1.2",#指定系统版本
22 "deviceName":"127.0.0.1:62001",#指定设备名称
23 "appPackage":"com.baidu.BaiduMap",#被操作的应用程序包名
24 "appActivity":"com.baidu.baidumaps.MapsActivity" , #启动页面
25 "noReset":True # 为true 不重置 为false 重置
26 }
27 # 发送指令给appium server
28 driver=webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_caps)
29 # 获取整个屏幕的大小
30 size=driver.get_window_size()
31 width=size["width"]
32 height=size["height"]
33
34
35
36
37 def change_big():
38 # 模拟大拇指触屏操作
39 action_1 = TouchAction(driver)
40 action_1.press(x=width * 0.5, y=height * 0.5).wait(1000).move_to(x=widt
h * 0.5, y=height * 0.8).wait(1000).release()
41 # 模拟食指触屏操作
42 action_2 = TouchAction(driver)
43 action_2.press(x=width * 0.5, y=height * 0.4).move_to(x=width * 0.5,
y=height * 0.1).release()
44 # 两个触屏的操作同时进行
45 manyactions = MultiAction(driver)
46 print("开始放大====>")
47 manyactions.add(action_1)
48 manyactions.add(action_2)
49 manyactions.perform()
50 print("放大操作完成")
51
52
53 for i in range(0,6):
54 change_big()
55 # 实现缩小的操作
56 # 运动轨迹不太一样
二、H5元素
1、APP分类:
1、Android原生APP
2、混合APP(Android原生控件+H5页面)
3、纯H5App
2、H5元素
H5元素容器 WebView
WebView控件实现展示网页
3、H5元素定位环境的搭建
1、手机下载chrome浏览器
2、pc下载谷歌浏览器
3、下载chrome driver (自己电脑上的谷歌浏览器版本必须与驱动的版本匹配)
4、查看WebView是否开启,前提WebView处于debug状态下,才可以进入谷歌浏览器的
调试界面,才可以展示到webview:
调试地址:chrome://inspect/#devices
4、webview开启调试模式:
app中配置如下代码:
在WebView类中调用静态方法setWebContentsDebuggingEnabled):
if (Build.VERSION.SDK_INT >=Build.VERSION_CODES.KITKAT) {
WebView.setWebContentsDebuggingEnabled(true);
注意:一般需要app开发人员开启
定位H5元素的工具:uc-devtools
1 # ‐*‐ coding=utf‐8 ‐*‐
2 # @time:2021/8/9
3 # @phone:15874198829
4 # @author:码尚教育_星瑶
5 import time
6
7 from appium import webdriver
8 from appium.webdriver.common.mobileby import MobileBy
9 from selenium.webdriver.support.wait import WebDriverWait
10 from selenium.webdriver.support import expected_conditions as EC
11 """
12 H5元素的定位
13 """
14 desired_caps={
15 "automationName":"UiAutomator2", #默认框架
16 "platformName":"Android", #指定操作系统
17 "platformVersion":"5.1.1",#指定系统版本
18 "deviceName":"127.0.0.1:62001",#指定设备名称
19 "appPackage":"com.wondershare.drfone",#被操作的应用程序包名
20 "appActivity":"com.wondershare.drfone.ui.activity.Main2Activity" , #启动
页面
21 "noReset":True # 为true 不重置 为false 重置
22 }
23 # 发送指令给appium server
24 driver=webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_caps)
25
26 # text=Backup
27 loc_backup=(MobileBy.ID,"com.wondershare.drfone:id/btnBackup")
28 WebDriverWait(driver,15).until(EC.presence_of_element_located(loc_backup))
29 driver.find_element(*loc_backup).click()
30 print("点击backup")
31 # 点击next
32 time.sleep(8)
33 # text= Next
34 loc_Next=(MobileBy.ANDROID_UIAUTOMATOR,'new UiSelector().text("Next")')
35 WebDriverWait(driver,15).until(EC.presence_of_element_located(loc_Next))
36 driver.find_element(*loc_Next).click()
37 print("点击next")
38
39 #定位原生的app元素
40 # 原生app切换到webview
41 print("contexts:",driver.contexts)
42 # ['NATIVE_APP', 'WEBVIEW_com.wondershare.drfone']
43 # NATIVE_APP:原生app控件黄精
44 # 切换h5环境
45 driver.switch_to.context("WEBVIEW_com.wondershare.drfone")
46 # 实现元素定位
47 print("切换WebView环境")
48 loc_email=(MobileBy.ID,'email')
49 WebDriverWait(driver,5,0.01).until(EC.presence_of_element_located(loc_em
ail))
50 driver.find_element(*loc_email).send_keys("[email protected]")
51 time.sleep(1)
52
53 # 从h5元素切换到app原生控件 需要切换环境NATIVE_APP
54 #
55 driver.switch_to.context("NATIVE_APP")
56 print("切换原生控件元素环境")
57
58 # 元素定位
App自动化测试框架封装
1、PO
PO分为四层base层、pageobjects层、testcases层、testdata层
第一层 base层:抽取每个共同的属性及行为进行封装,定义到basepage类中
第二层:pageobjects层 每个页面定义为一个类,类=属性+页面操作方法
属性:页面元素的定位语句 (By.xx,"‘定位语句’)====>pagelocations
页面操作方法 pageobjects层
web 页面可以展示很多内容 每个页面定位一个页面类 创建 xxxpage.py
app 页面展示内容少点 每个页面定位一个页面类 创建 xxxpage.py
第三层:testcases层 项目覆盖那些流程 unittest/pytest
用例1 用例2 ,用例n… 每个用例创建一个.py文件?
冒烟用例
主流
基于功能模块进行分类管理用例
用例1:
1、操作步骤:里面的操作是属于哪些页面=调用这页面类里面的方法
实例化页面类.方法()
2、断言 验证测试点是否与预期一
App自动化测试之微信小程序
H5元素:通过android.system.WebView实现展示网页上的元素
定位h5元素的工具:uc-devtools
如何实现在app应用程序上展示的网页?
appium—》xxxdriver(浏览器驱动)----->android.system.WebView—>展示网页
微信小程序、微信公众号如何实现app自动化测试?
微信小程序、微信公众号其实就是混合app(原生控件+H5的页面)
原生控件元素与H5元素进行切换,需要切换上下文
driver.switch_to.context(‘’)
微信小程序、微信公众号属于微信应用程序里面的,如何唯一操作被测的微信小程序/微信
公众号
真机连接注意:
1、打开开发者选项-开启usb调试
2、真机必须运行接受adb命令 ---- 仅充电模式,允许ADB调试
3、选择USB配置----MTP 多媒体传输
一、环境准备:
1、微信设置debug调试状态 ,在微信聊天窗口:debugx5.qq.com 点击链接,进行
X5调试页面,选择【信息】选项卡,勾选 TBS内核inspector测试功能(只要打
开tbs,才可以在uc-devtools定位webview)
2、手机上打开微信小程序,通过dev-tools/或者进入谷歌浏览器调试界面,定
位到webview
X5内核
注意:本地的浏览器驱动版本与dev-tools定位的webView的版本要一致
3、微信有很多微信小程序,如何定位到被测的微信小程序?
通过获取微信小程序的进程名称?
adb命令:
命令01:adb shell dumpsys activity top | findstr ACTIVITY

命令02:adb shell ps 进程id

最终获取进程名称:com.tencent.mm:appbrand0
二、通过appium实现对微信小程序进行对应的操作
1 # ‐*‐ coding=utf‐8 ‐*‐
2 # @time:2021/8/14
3 # @phone:15874198829
4 # @author:码尚教育_星瑶
5
6 """微信小程序"""
7 import time
8
9 from appium import webdriver
10
11 desired_caps = {
12 'platformName': 'Android',
13 'fastReset': 'false',
14 'noReset': True,
15 'platformVersion':'9',
16 'deviceName': 'HXJNW18420012584',
17 'appPackage': 'com.tencent.mm',
18 'appActivity': 'com.tencent.mm.ui.LauncherUI',
19 # 'fullReset': 'false',
20 # 'unicodeKeyboard': 'True',
21 # 'resetKeyboard': 'True',
22 'chromedriverExecutable':'D:\\chromedriver\\chromedriver.exe',
23 #支持X5内核的自动化配置,recreateChromeDriverSessions参数为Fasle默认启动and
roid sys webview的版本,
24 'recreateChromeDriverSessions':True,
25 #切换到webview时,小程序是哪个webview?
26 'chromeOptions': {'androidProcess': 'com.tencent.mm:appbrand2'}
27
28 }
29 driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_caps)
30 print("启动会话,打开微信中")
31 time.sleep(15)
32 print("已打开微信,开始进入小程序")
33 # driver.find_element_by_android_uiautomator('text("微信")').click() #点
击微信Tab
34 # 定义一个滑动屏幕的方法
35 def swipeDown(t):
36 x = driver.get_window_size()['width']
37 y = driver.get_window_size()['height']
38 x1 = int(x * 0.5) # x坐标
39 y1 = int(y * 0.25) # 起始y坐标
40 y2 = int(y * (0.25 + t)) # 终点y坐标
41 driver.swipe(x1, y1, x1, y2, 500)
42 swipeDown(0.4) # 向下滑动屏幕的40%,准备从顶部进入小程序
43 print("下滑完成,进入小程序")
44 time.sleep(10)
45 driver.find_element_by_android_uiautomator('text("趣练习Pro")').click() #
点击顶部的图标进入小程序
46 print("打开趣练习Pro")
47 time.sleep(20)
48 print(driver.contexts) # 打印当前所有的上下文
49 # 输出上下文的内容 ['NATIVE_APP', 'WEBVIEW_com.tencent.mm:toolsmp']
50 driver.switch_to.context('WEBVIEW_com.tencent.mm:toolsmp')
51 # [u'NATIVE_APP', u'WEBVIEW_com.tencent.mm:appbrand0', u'WEBVIEW_com.ten
cent.mm:support', u'WEBVIEW_com.tencent.mm:tools', u'WEBVIEW_com.tencent.m
m:appbrand1']
52 # driver.switch_to.context('WEBVIEW_com.tencent.mm:appbrand0') #切换上下
文为WEBVIEW_com.tencent.mm:appbrand0
53 # driver.find_element_by_xpath("/html/body/wx‐view/wx‐view[4]/wx‐form/sp
an/wx‐button").click() # 这个是HTML页面的元素
GIT分布式版本控制系统的安装和配置
一、GIT说明和应用
GIT是分布式版本控制系统,是当前比较流行、比较好用的一款版本控制系统,可以有效高速地处理项目管理工作。GIT是Linus Torvalds当初为了帮助管理Linux内核开发而开发的版本控制系统。
SVN集中式:有中央服务器仓库,从中央服务器获取代码-》操作-》推送给中央服务器。必须有网才可以提交。
GIT分布式:每个人的电脑都有一个仓库,你和同事同事都修改了,只需要把各自的修改推送给对象,就可以相互看到,没有中央服务器,没有网络也可以提交。
利用Git版本控制进行开发的经典场景如下:
- 先从Git服务器上克隆完整的Git仓库到本地(包括代码和版本信息)
- 然后在自己本地的Git环境里根据不同的开发目的,创建分支,修改代码。
- 在本地提交自己的代码到自己创建的分支上。
- 在本地合并分支
- 把服务器上最新版的代码fetch下来,然后跟自己的主分支合并
- 生成补丁(patch),把补丁发送给开发者。
- 看主开发者的反馈,如果主开发者发现两个一般开发者之间有冲突,就会要求他们先解决冲突(他们之间可以合作解决冲突),再由其中一个人提交。如果主开发者可以自己解决,或者没有冲突,就通过。
- 解决冲突的方法:开发者之间可以使用pull命令解决冲突(pull命令的功能是先从Git库中抓取最新的代码到本地),解决完冲突之后再向主开发者提交补丁。
二、GIT下载和安装
1、下载
这里以windows安装为例,下载地址为:https://git-scm.com/downloads,
选择Windows X64位的版本,如下图所示:
2、阅读公共许可,默认即可,点击"Next"

3、选择安装路径,点击"Next"

4、选择组件,按下图选择,点击"Next"

5、选择开始菜单文件夹,默认即可,点击"Next"
6、选择Git默认编辑器,建议选择"Notepad++“,点击"Next”
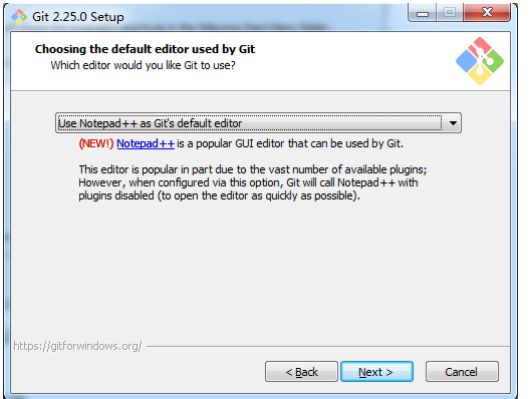
7、配置Path环境,默认即可,点击"Next"

8、选择HTTPS传输后端,默认即可,点击"Next"

9、配置行尾结束转换,默认即可,点击"Next"
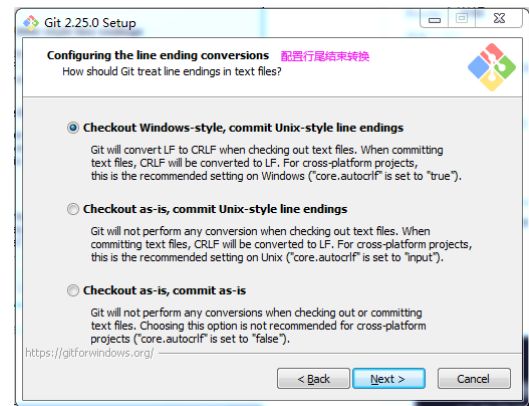
10、配置终端模拟器与Git Bash一起使用,默认即可,点击"Next"

11、配合额外的选择,默认即可,点击"Install"

12、完成Git安装向导,默认即可,点击"Next",完成安装。

13、在电脑桌面点击右键出现如下两个选择,则说明可以使用Git了
三、安装完成后设置GitHub账户密码。
1.了解Git、Github、Gitlab的区别
(1)Git是版本控制系统,能够帮你更好的写程序。类似于SVN。
(2)Github是一个网站,是在线的基于Git的代码托管服务。GitHub同时提供付费账户和免费账户。这两种账户都可以创建公开的代码仓库,但是付费账户也可以创建私有的代码仓库。
(3)Github有个小遗憾、就是你的repo(repository仓库),都需要public(公开), 如果你想要创建private(私人)的repo, 那得付钱,而Gitlab解决了这个问题, 可以在上面创建免费的私人repo。但是Gitlab需要部署到服务器。
2.访问GitHub官网:https://github.com/ 进入官网
3.输入邮箱,进入注册页面。(如果直接进入了注册页面则这一步可以忽略)
4.输入用户名和密码,并验证账户。我这里验证是把一张小狗图片调正
5.欢迎使用Github,可以按实际选择,也可以点击最后的"跳过这一步"
6、验证电子邮件
进入注册时的邮箱:点击下图中的Verify email address按钮验证邮箱地址
7、创建新的仓库
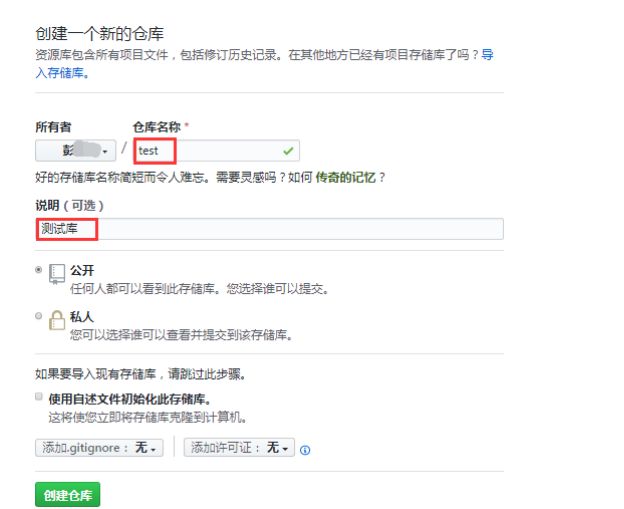
8、测试库创建完成后如下图所示:
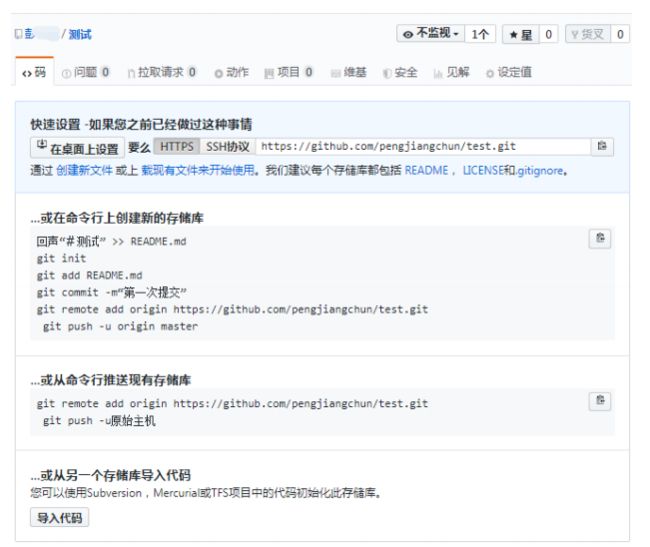
Git,GitHub,Gitee集成Pycharm实现代码版本控制以及基于Flask的接口Mock Server服务器
一、版本控制
1.作用
解决自动化团队之间的协同代码开发问题。
回归到以前的一个时间点。
对代码进行日志管理。
解决代码的冲突问题。
2.工具
CVS/VSS 版本控制工具的老祖。
SVN 基于CS架构的版本控制工具,特点是:集中式的版本控制。
Git Git是目前最主流的控制工具,特点是:分布式的版本控制。
集中式:版本库存放在中央服务器,操作:从服务器获得代码—>操作(增,删,改,查)—
提交到服务器。自动化团队在开发时必须联网(局域网)才可以操作。
分布式:版本库没有中央服务器,每个人的电脑都是一个完整的版本库,不需要联网。
名词解释:
Git:版本控制工具
GitHub:是一个网站,代码库是公开的,私人仓库是需要收费的。服务器在国外是英文的。
Gitee(码云):是一个网站,代码库是公开的,私人仓库免费的。服务器在国内是中文的。
GitLib:项目,在本地的GitHub
安装Git和注册Gitee。

使用Git版本控制工具:
Git原理:工作区---->暂存区---->本地版本库---->push(Gitee,Github,GitLib)
(1)在(Gitee,Github,GitLib)上面创建仓库。
(2)让本地的文件和Gitee上面的仓库关联。
克隆命令:git clone https://gitee.com/mrs_peng/test.git
(3)新增
进入项目名为test的目录,并新建一个a.py文件。
git status 查看当前版本库中的改动。
git add a.py 把文件提交到暂存区。
git commit -m ‘注释’ 把暂存区的文件提交到本地版本库。
git log 查看日志。
(4)修改
直接修改文件。
git status 查看当前版本库中的改动。
git add a.py 把文件提交到暂存区。
git commit -m ‘注释’ 把暂存区的文件提交到本地版本库。
再次直接修改文件。
git status 查看当前版本库中的改动。
git add a.py 把文件提交到暂存区。
git commit -m ‘注释’ 把暂存区的文件提交到本地版本库。
还原到第2次提交时的代码:git reset --hard 7ac8038cd11f0c
(5)删除
直接删除工作区的文件。
git status 查看当前版本库中的改动。
git add . 把文件提交到暂存区。
git commit -m ‘注释’ 把暂存区的文件提交到本地版本库。
(6)把本地版本库里面的文件提交到gitee。
git push
提交代码会冲突吗?
如果说操作的文件不一样,那么不会冲突。如果说:多个人操作同一个文件(配置文件),
那么就会冲突。
3.能不能使用Git和Gitee(Github,Gitlib)集成Pycharm。
(1)新建项目
(2)让Pycharm集成Git版本控制工具。

(3)让Pycharm集成Gitee,GItHub.
先安装插件
(4)分享项目到Gitee
(5)Pycharm文件颜色
无色:代表这个文件已经提交到版本库
红色:代表这个文件在工作区
绿色:代表这个文件已经提交到了暂存区。
蓝色:代表文件有改动。
二、基于Flask的Mock Server服务器
1.Flask的简介
Flask是一个基于Python语言开发的Web应用框架。
安装:pip install flask
1 import hashlib
2
3 from flask import Flask, request
4
5 #初始化一个对象
6 app = Flask(__name__)
7
8 #新建一个函数
9 @app.route("/helloworld",methods=['POST','GET'])
10 def helloworld():
11 return "helloworld"
12
13 def md5(args):
14 return hashlib.md5(str(args).encode('utf‐8')).hexdigest()
15
16 #稍微复杂的接口(要求用户名和密码必须要MD5加密)
17 @app.route("/login",methods=['POST'])
18 def login():
19 username = request.values.get("username")
20 password = request.values.get("password")
21 print(username,password)
22 if username==str(md5("admin")).upper() and password==str(md5("123")).up
per():
23 return "登录成功"
24 else:
25 return "登录失败"
26
27 if __name__ == '__main__':
28 app.run()
Jenkins持续集成CI,持续部署CD,Allure报告集成以及发送电子邮件
一、Jenkins的简介
它是一个可以扩展的持续集成CI和持续部署CD的平台,它只是平台,主要的运作的是插
件。
腾讯课堂:平台。
插件:码尚教育
主要作用:
持续的监控项目版本的发布。实现持续部署CD
监控外部的定时任务。
二、Jenkins的安装
前置工作:在安装之前安装JDK以及配置JDK的环境变量。
非常麻烦。
第一种:自己安装。
第二种:使用已经安装好的jenkin.rar文件使用。
1.qq群上传:jenkins完美插件版.rar文件。解压到C:\jenkins目录。
2,配置jenkins的环境变量。
3.双击startjenkins.bat启动jenkins的服务。
4.在浏览器中输入:http://localhost:8080访问jenkins
三、Jenkins文件夹的作用

jobs:构建作业(job)的配置细节,以及运行作业时的产物和数据。
logs:日志
nodes:节点配置
plugins:插件
Allure jenkens Plugin 解决allure报告和jenkins集成的插件。
HTML publisher 集成HTML报告的插件
RobotFrameowrk 集成RF
Zentimestamp 集成日期和时间
Email Extesion plugin 集成电子邮件
Groovy 解决自动化报告样式丢失的插件
secrets 存放秘钥
updates 存放更新的插件
userContent 定制化的内容
users 用户信息
war 存放web应用程序
workspace 默认工作空间。
四、Jenkins的应用
配置job
1.配置工作空间。

2.构建命令

3.jenkins集成Allure报告。
1)安装allure插件。Manage Jenkins
2)在【全局工具配置】,设置Allure

3)在job里面配置:构建后的操作。
4…jenkins集成HTML的报告。
1)安装HTML publisher插件。Manage Jenkins
2)配置job里面的【构建后操作】
3)配置【构建】,选择

输入一下脚本解决HTML报告样式丢失的问题:
System.setProperty(“hudson.model.DirectoryBrowserSupport.CSP”,“”)
五、Jenkins发送电子邮件
1)安装插件:Email Extension
2)获得邮箱的客户端密码:开启POP3/SMTP的客户端密码。
rrfkzteotfsscajb
PNHZCOTYBOQQNKOZ
3)配置邮箱的发件人,SMTP服务器,收件人等信息。
A。管理员的邮箱:和发件邮箱保持一致

B.点开【高级】
发件人:
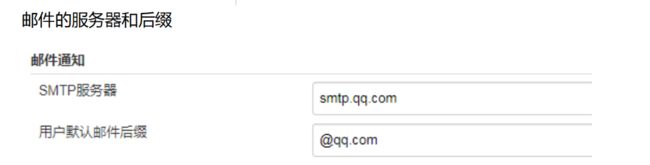
4)在job里面配置:构建后的操作。
修改触发的方式,默认是失败触发,改成总是触发,
六、Jenkins定时任务
分 时 日 月 年

七、Jenkins持续部署CD。
手工发布版本。
开发1.0,代码和数据库导出,部署到测试环境。
开发2.0,代码和数据库导出,部署到测试环境。
开发3.0,代码和数据库导出,部署到测试环境。
开发4.0,代码和数据库导出,部署到测试环境。
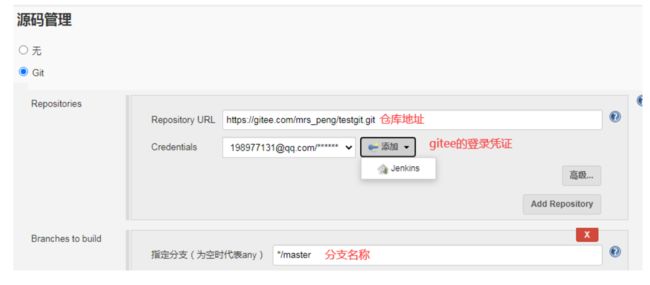
jenkins持续集成环境从0到1搭建全过程
一、 jenkins下载以及JDK环境准备。
- jenkins官网下载地址:https://jenkins.io/download/ 目前稳定版本:
2.204.2
jenkins项目有两条发布线,分别是LTS长期支持版(或稳定版)和每周更新版
(最新版)。建议选择LTS长期支持版,下载通用java项目war包

2.下载jdk1.8以上版本并安装,安装后配置jdk的环境变量。(这里不再累述具
体步骤)
二、jenkins安装
安装方式一:
1.在Dos窗口中切换到"jenkins.war"目录。输入命令:java -jar jenkins.war 安装

安装方式二:
1.下载tomcat8以上版本,解压后把jenkins.war包放入解压后的webapps目
录。打开Tomcat下bin目录的startup.bat启动tomcat服务。(这里不再累述具
体步骤)
启动时发现dos窗口中有很多乱码,不影响运行,但是看着总是不舒服,解决方
案如下:我们来到tomcat目录的conf子目录中,找到一个名为
“logging.properties” 的文件,打开这个文本文件,找到如下配置项:
java.util.logging.ConsoleHandler.encoding = UTF-8
将 UTF-8 修改为 GBK,修改后的效果为:
java.util.logging.ConsoleHandler.encoding = GBK
保存后,重启tomcat!这时乱码已经解决了。
注意:两种安装方式都会在C盘目录下生成一个jenkins的文件夹。C盘下的这个
文件夹可独立运行。
(1)把jenkins.war包放入到C:/jenkins文件夹中,然后在C:/jenkins下新建一个
startjenkins.bat文件,输入如下内容:
@echo off
cd /d %JENKINS_HOME%
java -jar jenkins.war
pause
(2)设置环境变量:增加JENKINS_HOME变量,如下:
JENKINS_HOME:C:\jenkins
双击startjenkins.bat文件出现:jenkins is fully up and runing说明启动成功
jenkins了。
2.在浏览器中访问jenkins项目:http://localhost:8080/jenkins 出现解锁
Jenkins界面,说明jenkins项目搭建完成,这里需要输入管理员密码。如下图:
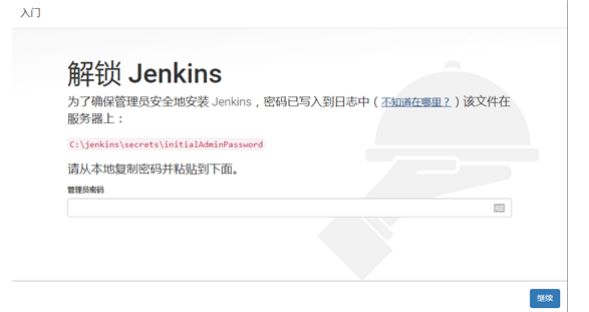
上图中有提示:管理员密码在:C:\jenkins\secrets\initialAdminPassword 打
开此文件获得密码并输入密码,第一种安装方式点击”继续”按钮后如出现如下
图的报错信息:这是jenkins的一个Bug,解决方案是:通过地址
http://localhost:8080访问jenkins项目即可。

点击:【选择插件来安装】(选择【安装推荐的插件】也可以),根据笔者的经
验选择【选择插件来安装】安装插件顺利些,选择后出现如下默认插件安装界
面

这个页面会默认选中安装一些插件,直接点击”安装”按钮,安装所有推荐的插
件。
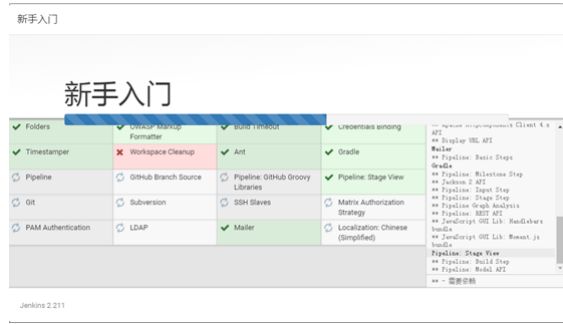
等待所有插件安装完成(耐心等待1-2个小时)。安装插件的时候,会有一些插件
安装失败(如上图的X),这些插件的安装是有前置条件的,等安装结束后,按
右下角“重试”,继续安装,之前失败的插件就都能安装了。安装完成后,点
击“继续”按钮
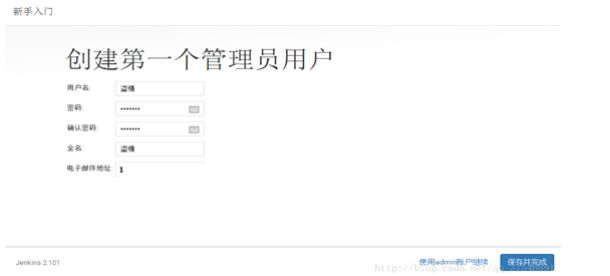
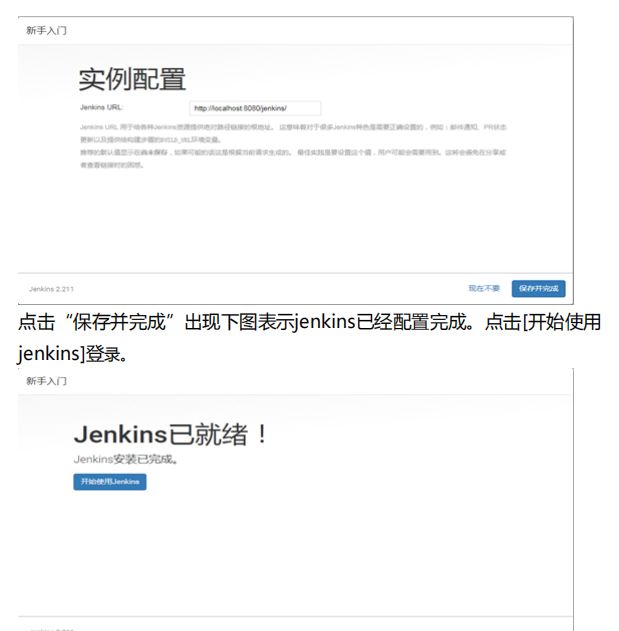
Docker容器技术介绍,应用场景,安装应用以及项目部署
一、什么是Docker
Docker就是一个虚拟机,它是一个开源的容器平台,它和VM有相似的地方,也有不同的地方。
Docker名称解释:
仓库(Docker仓库,Dokcerhub):存放镜像的地方,类似于GitHub,包含:
ubuntu,mysql,tomcat,redis,nginx,通过push上传镜像到仓库,通过pull命令下载镜像。
镜像(images):说白了就是由本体打包出来的一个镜像文件。
容器:容器是正在运行的虚拟机,它是由镜像run时生成的容器,一个镜像可以run出N个容器。
Dockerfile:把自动化的项目通过build命令构建成镜像。
tar文件:可以把镜像文件保存tar文件
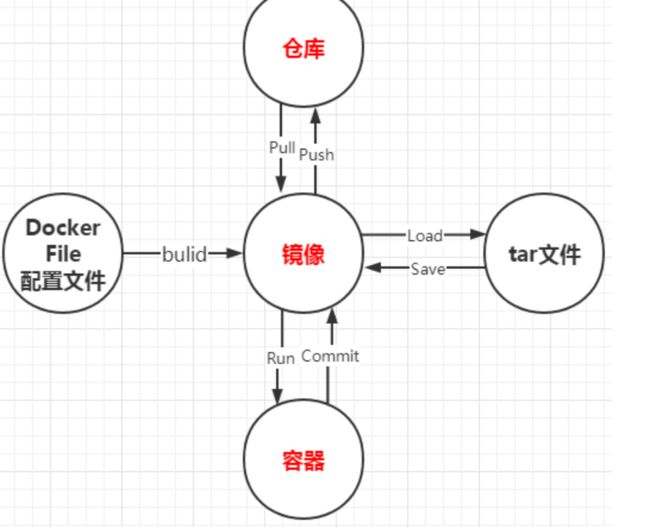
二、Docker虚拟化技术和传统的虚拟技术的区别
Docker的思想来源于集装箱。核心思想是:隔离。
三、为什么需要使用Docker
开发(环境),测试(环境),运维(环境)。
1.我的电脑没问题,为什么你的有问题。
2.开发部署生产环境,还是运维去学习项目的部署的技术。
3.微服务项目:部署项目非常麻烦,需要一天。
DevOps=Jenkins+Docker+K8s
Docker思想:开发项目打包war包+环境打包+数据打包成镜像,然后上传到DockerHub仓
库,然后运维只需要下载开发的镜像,然后运行即可。
四、Docker的安装
centos7为例,只支持centos7以上的版本。
1.安装VM虚拟机和Centos7
2.设置虚拟机网络
- 设置桥接模式
2)设置服务器的IP地址


关闭本机的防火墙和杀毒软件。通过Xshell连接。 - 安装Docker
- 安装依赖包
1 yum install ‐y yum‐utils device‐mapper‐persistent‐data lvm2
2.设置国内的下载源
1 yum‐config‐manager ‐‐add‐repo http://mirrors.aliyun.com/docker‐ce/linux/c
entos/docker‐ce.repo
3.安装docker
1 yum install ‐y docker‐ce
启动
systemctl start docker
查看版本
docker version
四、Docker的应用
1.开始测试之前,测试服务器上面安装Docker,Docker的版本最好和开发一致。
2.根据测试请求说明的镜像地址DockerHub拉取镜像。
3.运行镜像,生成容器。
4.访问项目,开始测试,发现Bug,反馈bug给开发。
Docker的常用命令:
1.搜索镜像:docker search tomcat
2.拉取镜像:docker pull tomcat
3.查看本地镜像文件:docker images
4.运行镜像生成容器:docker run -d -p 9999:8080 镜像ID
-d 在后台运行
-p 9999:8080 服务器的端口映射到容器内的端口。
如:docker run -d 266d1269bb29
5.如何查看本地正在运行的容器:docker ps
如果:docker ps -a
-a 表示查看所有历史运行的容器。
6.查看容器内部的日志信息。
docker logs -f 容器id
7.进入容器:
docker exec -it 容器id /bin/bash
exit是退出
8.启动和停止容器:docker start/stop/restart 容器id
五、Docker部署项目
1.安装rz上传文件的命令
yum install lrzsz
2.切换到/opt目录
cd /opt
3.使用rz命令上传war项目文件到/opt目录。
4.拷贝当前目录下的test.war文件到容器中对应放项目的位置
docker cp test.war b94b4722de68:/usr/local/tomcat/webapps
5.访问项目:
http://192.168.0.200:9999/test
六、Docker运行分布式自动化测试项目(完善)
把自动化项目打包镜像。上传Docker仓库。
自动化环境的selenium
jenkins+docker集成