My name is Farooq and I am with HDinsight support team here at Microsoft. In this blog I will try to give some brief overview of Sqoop in HDinsight and then use an example of importing data from a Windows Azure SQL Database table to HDInsight cluster to demonstrate how you can get stated with Sqoop in HDInsight.
What is Sqoop?
Sqoop is an Apache project and part of Hadoop ecosystem. It allows data transfer between Hadoop\HDInsight cluster and relational databases such as SQL, Oracle, MySQL etc. Sqoop is a collection of related tools, for example import, export, list-all-tables, list-databases etc. To use Sqoop, you specify the tool you want to use and the arguments that control the tool. For more information on Sqoop please check Sqoop User Guide.
When do you need to use Sqoop?
You need to use Sqoop only when you are trying to import/export data between Hadoop and a relational Database. HDInsight provides a full-featured Hadoop Distributed File System (HDFS) over Windows Azure Blob storage (WABS) and if you want to upload data to HDInsight or WASB from any other source, for example from your local computer's file system then you should use any of the tools discussed in this article. The same article also discusses how to import data to HDFS from SQL Database/SQL Server using Sqoop. In this blog I will elaborate on the same with an example and try to provide more details information along the way.
What do I need to do for Sqoop to work in my HDInsight cluster?
HDInsight 2.1 includes Sqoop 1.4.3. The Microsoft SQL Server SQOOP Connector for Hadoop is now part of Apache SQOOP 1.4. So you do not need to install the connector separately. All HDInsight clusters also have Microsoft SQL Server JDBC driver installed; so all components that are needed to transfer data between HDInsight cluster and SQL server are already installed in a HDI cluster and you do not have to install anything.
How can I run a Sqoop job?
With HDInsight preview version we could only run the Sqoop commands from Hadoop command line after doing a remote desktop session (RDP) on the HDInsight cluster head node. However the release version of HDInsight SDK includes the PowerShell cmdlet to run Sqoop job remotely. So we can
- Run Sqoop jobs locally from HDInsight head node using Hadoop Command Line
- Run Sqoop job remotely using HDInsight SDK PowerShell cmlets
We recommend that you run your Sqoop commands remotely using HDInsight SDK cmdlets . We will discuss both the options in detail. First let's see how we can run Sqoop jobs locally from HDInsight head node using Hadoop Command Line.
Run Sqoop jobs locally from HDInsight head node using Hadoop Command Line
I am assuming you already have a Windows Azure SQL Database. If you don't and you want to get one please follow the steps in this article. Let's follow the steps below to create a test table and populate with some sample data in your Windows Azure SQL Database which we will import in our HDInsight cluster shortly. I will show how to do this from Windows Azure portal but you can also connect to the Windows Azure SQL Database from SSMS and do the same.
Note: if you want to transfer data from a SQL server on your environment instead then you need to change the Sqoop command with appropriate connection information and it should be very similar to the connection string I have provided later in this blog under 'More sample Sqoop commands' section for SQL server on Window Azure VM.
-
Login to your Windows Azure Portal and select 'SQL Databases' from the Left and click 'Manage' at the bottom.
- Provider your Windows Azure SQL Database user ID and password to login and then click 'New Query' to open a new query window to run T-SQL queries.
-
Copy paste the following T-SQL query and execute to create a test table Table1.
CREATE TABLE [dbo].[Table1](
[ID] [int] NOT NULL,
[FName] [nvarchar](50) NOT NULL,
[LName] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_Table_4] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
) ON [PRIMARY]
GO
-
Run the Following to Populate Table1 with 4 rows.
INSERT INTO [dbo].[Table1] VALUES (1,'Jhon','Doe'), (2,'Harry','Hoe'), (3, 'Carla','Coe'), (4,'Jackie','Joe');
GO
-
Now finally run the following T-SQL to make sure that is table is populated with the sample data. You should see the output as below.
SELECT * from [dbo].[Table1]
Now let's follow the steps below to Import the rows in Table1 to the HDInsight Cluster.
- Login to your HDInsight cluster head node via Remote Desktop (RDP) and double click the 'Hadoop Command Line' icon in the desktop to open Hadoop Command Line. RDP access is turned off by default but you can follow the steps inthis blog to enable RDP and then RDP to the head node of your HDInsight cluster.
- In Hadoop Command Line please navigate to the "C:\apps\dist\sqoop-1.4.3.1.3.1.0-06\bin" folder.
Note: Please verify the path for the Sqoop bin folder in your environment. It may slightly vary from version to version.
-
Run the following Sqoop command to import all the rows of table "Table1" from Windows Azure SQL Database "mfarooqSQLDB" to HDInsight Cluster.
sqoop.cmd import –-connect "jdbc:sqlserver://
.database.windows.net:1433;username= @ ;password= ;database= " --table Table1 --target-dir /user/hdp/SqoopImportTable1 Once the command is executed successfully you should see something similar as below in Hadoop Command Line window.
- There are quite a number of tools available to upload/download and view data in WASB. Let's use Azure Storage Explorer tool. You need to install the tool in your work station and configure for your cluster. Once all is done open the tool and find out /user/hdp/SqoopImportTable1 folder. You should see something similar as below. It shows 4 files indicating 4 map jobs were used. You can select a file and click the 'View' button to see the actual text data.
Now let's export the same rows back to the SQL server from HDInsight cluster. Please use a different table with the same schema as 'Table1'. Otherwise you would get a Primary Key violation error since the rows already exist in 'Table1'.
-
Create an empty table 'Table2' with the same schema as 'Table1'.
CREATE TABLE [dbo].[Table2](
[ID] [int] NOT NULL,
[FName] [nvarchar](50) NOT NULL,
[LName] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_Table_2] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
) ON [PRIMARY]
GO
- Run the following Sqoop command from Hadoop Command Line.
sqoop.cmd export --connect "jdbc:sqlserver://
More sample Sqoop commands:
Import from a SQL server on Window Azure VM:
sqoop.cmd import --connect "jdbc:sqlserver://
Export to a SQL server on Window Azure VM:
sqoop.cmd export --connect "jdbc:sqlserver://
Importing to HIVE from Windows Azure SQL Database:
C:\apps\dist\sqoop-1.4.2\bin>sqoop.cmd import –connect "jdbc:sqlserver://
Note: This will store the files under hive/warehouse/TableName folder in HDFS (For example hive/warehouse/table1/part-m-00000 )
Run Sqoop job remotely using HDInsight SDK PowerShell cmlets
To use HDInsight PowerShell tools you need to install Windows Azure PowerShell tools first and then install HDInsight PowerShell tools. Then you need to prepare your workstation to use the HDInsight SDK. Please follow the detail steps in this earlier blog post to install the tools and prepare your work station to use the HDInsight SDK.
Once you have installed and configured Windows Azure PowerShell tools and HDInsight SDK running a Sqoop job is very easy. Please follow the steps below to import all the rows of table "Table2" from Windows Azure SQL Database "mfarooqSQLDB" to HDInsight Cluster.
-
Open the Windows azure PowerShell console on the workstation and run the following cmdlets one at a time.
Note: You can also use Windows Powershell ISE to type the code and run all at once. Powershell ISE makes edits easy and you can open the tool from "C:\Windows\System32\WindowsPowerShell\v1.0\powershell_ise.exe".
-
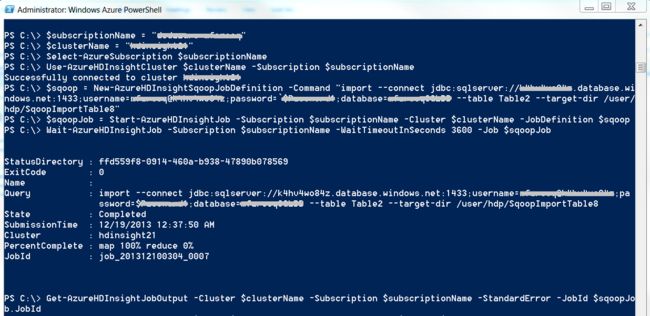
Set the variables for your Windows Azure Subscription name and the HDInsight cluster name.
$subscriptionName = "
" $clusterName = "
" Select-AzureSubscription $subscriptionName
Use-AzureHDInsightCluster $clusterName -Subscription $subscriptionName
-
Define the Sqoop job that we want to run. In this exercise we will import all the rows of table "Table2" that we created earlier in Windows Azure SQL Database.
$sqoop = New-AzureHDInsightSqoopJobDefinition -Command "import --connect jdbc:sqlserver://
.database.windows.net:1433;username= @ ; password= ; database= --table Table2 --target-dir /user/hdp/SqoopImportTable8" -
Run the Sqoop job that we just defined.
$sqoopJob = Start-AzureHDInsightJob -Subscription $subscriptionName -Cluster $clusterName -JobDefinition $sqoop
-
Run the following to wait for the completion or failure of the HDInsight job and show its progress.
Wait-AzureHDInsightJob -Subscription $subscriptionName -WaitTimeoutInSeconds 3600 -Job $sqoopJob
-
Run the following to retrieve the log output for a job from the storage account associated with a specified cluster.
Get-AzureHDInsightJobOutput -Cluster $clusterName -Subscription $subscriptionName -StandardError -JobId $sqoopJob.JobId
If the Sqoop job completes successfully you should see something similar as below in your Windows Azure PowerShell command line window.
Troubleshooting tips
When you run a Sqoop job command it runs MapReduce job in Hadoop Cluster (map only and no reduce task). You can specify the number of map tasks but by default four tasks are used. There is no separate log file specific to Sqoop. So we need to troubleshoot Sqoop job failure or performance issues as any other MapReduce job failure or performance issues and start by checking the task logs. I plan to write more on how to troubleshot Sqoop issues by focusing on some specific scenarios in the near future.
That's all for today and I hope you found this blog useful. I look forward to your comments and suggestions J.