17ASAP如何更好地改进少样本提示:在LLMs的prompt中添加语义信息,来提高代码摘要生成+代码补全任务的性能。CodeSearchNet数据集【网安AIGC专题11.7】
Improving Few-shot Prompts with Relevant Static Analysis Products
- 写在最前面
- 论文名片
- 未来论文的思考
- 背景
-
- LLM in SE 预训练语言模型在软件工程中的应用和发展趋势
-
- few-shot learning
- Prompt Engineering及其例子
-
- prompt格式:文本、视觉(bounding box、关键像素点)、语音
- prompt的两大好处
- Prompt的不同分类
-
- Zero-shot prompt
- Few-shot
- Instruct prompt 指导提示
- Chain-of-thought prompt 思维链提示(这个看到过好几次了hh)
- Prompt使用技巧
-
- 温度和Top_K
- Retrieval检索器
- Summarizing Code 代码摘要生成
- 创新点
-
- ASAP
-
- 具体实现
- 效果
- 模型与方法
-
- 仅解码器模型
- Retrieving Exemplars from Training Data 从训练数据中检索样本
- Automatic Semantic Prompt Augmentation 自动语义提示增强
-
- 存储库名称和路径
- 标记标识符
- 数据流图(DFG)
- 用例和补全流水线
- 默认情况下,ASAP被配置了分析来提取存储库信息、标记标识符、构建DFGs
- 三、实验数据集、指标和设置
-
- Dataset
- Metrics指标
-
- BLEU
- CodeXGLUE基准
- Experimental Setup & Evaluation Criteria实验设置和评价标准
- 实验结果
-
- Encoder-decoders & Few-shot Learning
- Prompt Enhanced Few-shot Learning提示增强的少样本学习
- Same Project Code Summarization相同的项目代码总结
- ASAP是模型无关的吗?
- ASAP for Completion
- Performance on Other Metrics
- Ablation Study
- 两个示例说明
- 五、讨论
-
- Does the Model Memorize the Path?
- Is the Identifier Tag Necessary?
- What’s Better: More Shots or ASAP?
- 六、威胁与限制
- 七、总结
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
范晓萱同学分享了Improving Few-shot Prompts with Relevant Static Analysis Products《用相关静态分析产品改进少样本提示》
论文:https://arxiv.org/pdf/2304.06815.pdf
论文12页信息量比较大,PPT相当充实,长达49页
分享时语速快而不乱,好飒啊
方向给出更好提示的结构,添加语义信息,从而让大模型有更好的结果也是我感兴趣的,感觉未来无论是日常Prompt或者论文都有可能会用到
原文1.8w字,侧重自己感兴趣的部分,方便后面找论文灵感
论文名片
- 大型语言模型(LLM)是一类新的计算引擎,通过提示工程进行“编程”。
- 开发人员在处理编码任务时往往会有意识和无意识地记住一系列
语义事实,这些都是快速阅读产生的肤浅、简单的事实。 - 转换器式 LLM 可能并没有天生能够
执行简单级别的“代码分析”,需要明确添加此类型信息来帮助处理代码。 - 目标是使用
代码摘要任务来研究这个问题,并评估用语义事实显式地自动增强 LLM 的提示是否真的有帮助。 - 先前的研究表明,LLM 在代码摘要方面的 性能受益于 从同一项目or通过信息检索方法找到的示例中
抽取的少量样本。 添加语义事实确实有帮助,可以提高先前工作建议的几种不同设置的性能,包括两种不同的大型语言模型。
在大多数情况下,性能的改善接近或超过2 BLEU;
对于具有挑战性的CodeSearchNet数据集中的PHP语言,这种增强产生了超过30 BLEU的性能。
未来论文的思考
- 添加语义信息的方法 能够提高LLMs在代码摘要任务中的性能。
- 探究如何通过在LLMs的prompt中添加语义信息,来提高代码摘要任务的性能。
背景
大型语言模型(LLM) 在任务上的表现通常优于较小的、自定义训练的模型,特别是在使用“少量”示例集进行提示时。
LLM使用大量数据在自我监督(掩蔽或去噪)任务上进行预训练,并随着训练数据和参数数量的增加而表现出令人惊讶的优异行为。
LLM只需few-shot (or even zero-shot) learning,即可在许多任务中表现出色:
只需在prompt中首先插入几个范例输入输出对,模型就可以为给定的输入生成非常好的输出!
LLM in SE 预训练语言模型在软件工程中的应用和发展趋势
重点:
- 预训练LLM的成本,两个关键因素,即
微调的硬件支持和数据集的难度,推动了预训练LLM在软件工程中的使用。- LLM在few-shot时表现更好,与小模型相比具有更大的优势。
- few-shot learning的定义和使用方法。
- LLM已经广泛应用于软件工程中的许多不同问题,包括
代码生成、测试、突变生成、程序修复、事件管理,甚至代码摘要生成。这些建立在预先训练的LLM之上的工具正在推动技术的发展。 - 两个关键因素决定了预训练LLM日益占据主导地位,这两个因素都集中在
成本上。
第一个因素 是训练自己的大型模型,甚至对预训练的LLM进行广泛的微调,都需要昂贵的硬件。
第二个因素 是为许多重要的软件工程任务生成受监督的数据集是困难和耗时的,除了最大的组织之外,通常超出了其他所有组织的能力。 - 尽管存在一些较小的模型,如
Polycoder或Codegen,专门用于代码,已经获得了普及。
但与整体LLM趋势相反,这些小模型在few-shot时表现不佳,因此在只有少量数据可用时没有帮助。
因此,文章关注的是LLM而不是小模型。
few-shot learning
通过few-shot learning,模型实际的参数保持不变。相反,根据之前的定义,我们将一些问题实例与解决方案一起呈现给模型(即,作为“范例”的问题-解决方案对),并要求它完成最后一个实例(“测试输入”)的答案,我们没有为其提供解决方案。
因此,对于每个示例由

有了这个提示,LLM生成output,模拟提示中的示例所示的输入输出行为。在实践中,这种方法表现得相当好。
Prompt Engineering及其例子
Prompt Engineering 代理了传统Bert类模型的微调训练的方式,使用更为高效的Prompt来指导LLM,使其产生出期望的结果,而无需改变模型的权重。
prompt 是人与大模型交互的媒介,是与LLM进行交互最直接最常用的方式:直接告诉模型我们要它干什么,模型便会干什么。
例如,我们可以问模型“用最多20个词总结下列文字”、“中国的首都在哪里?”、“判断下列文字的情感是正向还是负向”等等。我们输入的这些prompt,将会被模型识别、处理,最终输出为我们要的答案。
注意,有时内容为空,如比较简短的prompt:“中国的首都在哪里”、“模仿百年孤独的开头写一段话”这种言简意赅的prompt就只有指令、没有内容。

prompt格式:文本、视觉(bounding box、关键像素点)、语音

主流的prompt一般采用文本格式。但文本并非唯一的形式。
我们在视觉任务中往往可以采用视觉prompt,如bounding box、关键像素点等。以最近大火的segment anything model[1]为例,其便使用了不同的视觉prompt。
除此之外,我们在其他任务中也可以使用语音等多种形式的prompt。
prompt的两大好处
总体来说,prompt有两大好处:
- 有研究表明,1个prompt相当于100个真实数据样本[2],充分说明了prompt蕴含的信息量之巨大。
- prompt在下游任务
数据缺乏的场景下、甚至是zero-shot场景下,有着无可比拟的优势。因为大模型通常无法在小数据上微调,因此,基于prompt的微调技术便成为了首要选择。
[1] Segment anything https://ai.facebook.com/research/publications/segment-anything/
[2] https://arxiv.org/abs/2103.08493
Prompt的不同分类
Zero-shot prompt
零样本的prompt,即在评测大模型能力时,不给模型提供参考示例,仅通过任务描述或问题来推断出结果。
优点:这种方式灵活性高,不需要为每个新任务重新训练模型。
缺点:模型可能无法准确理解任务的微妙差别或特定要求。
> 例子:判断以下句子的情绪的类别
Few-shot
- Few-shot 学习是通过少量标注样本来完成任务的一种学习方式
- 标注样本通常包括输入和预期输出,帮助模型更好地理解任务性质和要求
- Few-shot 学习比 zero-shot 学习性能更好,但 代价 是
消耗更多 token,可能会达到上下文长度限制 - 在自然语言处理中,Few-shot 学习可以应用于
文本分类、指代消解、机器翻译、对话生成等任务 - Few-shot 学习可以减少标注数据成本,具有更好的泛化性能,但需要为每个新任务提供示例文本
- Few-shot 学习可能不适用于需要快速处理大量未知任务的场景,而且需要更多计算资源和时间进行模型训练和调整
- 在实际应用前需要综合评估具体场景
> 例子:
> 以下是一些示例句子及其情绪类别,请根据这些示例句子的情绪类别,判断下面句子的情绪类别。
> 示例1:这部电影太令人难过了。情绪类别:负面情绪
> 示例2:我非常兴奋明天的聚会。情绪类别:正面情绪
> 示例3:今天的天气真是美妙。情绪类别:正面情绪
> 示例4:我感到非常生气,因为他没有履行承诺。情绪类别:负面情绪
>
> 请判断下面句子的情绪类别:
> 句子1:这个好笑的视频让我笑了很久。
> 句子2:我非常失望他没有来参加我的生日派对。
> 句子3:这个好消息真是让我高兴。
> 句子4:我感到非常焦虑,因为明天有一场重要的面试。
Instruct prompt 指导提示
- 上述通过举例让LLM来理解具体的任务是什么,相当于给LLM进行示范,让他按照上述的模板来进行词语接龙
- 因此
直接用语言对我们想要的任务进行描述,让模型理解我们想要做的事情是什么 - 将Few shot和 Instruct 结合起来的方式就是给出几个示例,但这些示例是描述具体的任务,而不是一步步来做具体的分析演示
- 这个方法称为
in-context instruction learning,即通过在任务的上下文中给出具体的指令,让LLM对任务有更深入的理解能力,提问方式如下所示。
> 例子:
> 定义:确定对话的说话人,“代理人”或“客户”。 输入:我已经成功地为您订了票。 输出:代理人。
> 定义:确定问题所要求的类别,“数量”或“位置”。 参赛作品:美国最古老的建筑是什么? 输出:位置。
> 定义:将电影评论的情绪分类为“积极的”或“消极的”。 我敢打赌,这个视频游戏比电影有趣多了。 输出:情绪分类。
Chain-of-thought prompt 思维链提示(这个看到过好几次了hh)
- 当面对一个复杂问题时,人类常常采取分解问题的方法来解决它。
- 这种方法包括将大问题分解为小问题,然后逐一解决。
- 举例来说,如果你要组织一个大型的生日聚会,你可能会先考虑场地、食物、娱乐等方面,然后逐步解决这些小问题。很自然地就
从人类的思维逻辑过程迁移至大模型的prompt(提示)上。 - 这种思维模式被称为"Chain of Thought",也适用于逻辑推理任务的提示。
假设你要用一个语言模型来解决一个法律问题:
> 例子:
> 第一步:了解背景 Prompt: "请简要描述这个法律问题的背景和主要矛盾点。"
> 第二步:相关法律和案例 Prompt: "在这个法律背景下,有哪些相关的法律条款或先例案例?"
> 第三步:应用法律到具体问题 Prompt: "这些法律条款或案例如何应用于我的具体问题?有没有可能的解释或者争议点?"
> 第四步:可能的解决方案 Prompt: "根据以上的信息,最可能的解决方案或建议是什么
这样的Chain of Thought不仅能帮助模型更好地理解问题,还能帮助使用者更清晰地看到问题解决的全过程,就像我们人类解决问题时会做的那样。
Prompt使用技巧
温度和Top_K
在使用语言模型时,有两个关键参数需要注意,它们是温度和Top_K。
温度(Temperature):是介于0和1之间的数值,用于控制模型输出的多样性。
当温度为0时,模型会输出最有可能的答案;
当温度大于0时,模型会输出更多样化但可能不那么精确的答案。
数值越大,模型随机性越强,适合生成任务。
> 例子:
> 温度为 0:LLM 可能会输出“苹果是一种水果。”
> 温度为 1:LLM 可能会输出“苹果是一种多汁、美味的水果,常用于制作各种美食。”
Top_K:是一个整数,用于限制模型在生成每个单词时考虑的候选单词数量。
例如,当Top_K设置为50时,模型在生成下一个单词时只会考虑概率最高的前50个选项。
例子:
Top_K 为 10:模型输出可能更加一致和准确。
Top_K 为 100:模型输出可能更加多样,但准确性可能会下降。
Retrieval检索器
重点
- LLM无法获取最新的知识和信息,并可能产生幻觉
- Retrieval方法可以规避这一问题
- Retrieval的核心目标是通过对query编码,将其与外部文档进行检索,找出最相关的文档片段
- 文本检索常用向量化和向量数据库进行检索
- 向量数据库支持近似搜索功能
- 仅使用模型内部检索也对于问题的问答有用
- LLM经过训练之后,对于最新的知识和信息就不再能够获取,另外对于内部的一些信息和知识有可能会产生幻觉,通过retrieval的方法能够很好的规避这个问题。
- Retrieval的思想非常简单,就是通过对query的编码,然后将其与外部文档进行一个检索,将检索的内容加入至外部文档中,根据最新的检索的内容和query的问题,重新组合传入大语言模型中。这里的核心目标是根据问题
找出文档中和问题最相关的片段,文本检索里边比较常用的是利用向量进行检索,我们可以把文档片段全部向量化(通过语言模型,如bert等),然后存到向量数据库(如Annoy、 FAISS、hnswlib等)里边,来了一个问题之后,也对问题语句进行向量话,以余弦相似度或点积等指标,计算在向量数据库中和问题向量最相似的top k个文档片段,作为上文输入到大模型中。向量数据库都支持近似搜索功能。 - 另外有研究表示,即使不针对外部的知识,仅仅使用模型内部检索,对于问题的问答也是有用的。
Summarizing Code 代码摘要生成
- 文档完备的代码更容易维护,例如函数摘要头。
随着项目的发展,摘要注释可能会过时。自动代码摘要生成应运而生,已经取得了相当大的进展。 - 最初,基于模板的方法很流行,但创建具有良好覆盖率的模板列表很具有挑战性。
后来,研究人员专注于基于检索(IR)的方法,主要是基于相似性的度量检索现有代码(带有摘要)。
但是,只有在可用池中可以找到类似的代码注释对时,这种有前途的方法才有效。 - 最近,像CodeBERT和CodeT5这样的预训练语言模型在代码摘要生成方面表现最好。
然而,LLM现在在许多问题中通常优于预训练的较小的模型。
Ahmed和Devanbu[3]报告说,LLM可以用一个简单的提示,只包含同一个项目中的几个样本,就胜过预训练的语言模型。
这项工作说明了,谨慎建造提示词结构(即“提示词工程”)的前景。
[3] Toufique Ahmed and Premkumar Devanbu. 2022. Few-shot training LLMs for project-specific code summarization. In 37th IEEE/ACM International Conference on Automated Software Engineering. 1–5.
创新点
ASAP
- 提出了一种自动语义增强提示ASAP,用于构建软件工程任务提示。
- ASAP方法基于一个类比,即有效的提示与开发人员在手动执行任务时所考虑的事实有关。
假设使用开发人员在手动执行任务时考虑的语法和语义事实提示LLM,将提高LLM在该任务上的性能。 - 本文在代码摘要生成上说明ASAP方法的应用。该任务需要代码,通常是一个函数,并使用自然语言对其进行总结,以促进需求的可追溯性和维护。
此外,使用代码补全任务来确认假设。

具体实现
ASAP的具体实现过程可以分为以下几个步骤:
通过使用ASAP,可以使用源代码中的语义信息来增强提示符,提高语言模型的准确性和效率,从而改善代码自动生成的结果。
-
ASAP的目的是使用语义代码分析进一步增强提示符。由于观察到开发人员使用代码的属性(如参数名称、局部变量名称、调用的方法和数据流),文章建议使用
从源代码中自动提取的语义事实来增加提示符。 -
将
这些语义事实与所需的输出一起添加到few-shot提示中,为语言模型提供相关示例,并说明这些提取的事实如何有助于构建一个好的摘要。
向模型提供目标代码和从中提取的语义事实,并要求模型发出摘要。
- 这些语义事实具体包括
函数的全限定名、参数名及其数据流图。这些事实在few-shot例子中作为单独的、确定的字段呈现给LLM。
效果
- ASAP使用代码中导出的事实用于SE任务。
- 本文使用code-davinci-002, textdavinci-003.和GPT-3.5-turbo模型评估ASAP方法。
- 本文发现ASAP方法在代码摘要生成任务上显著提高了LLM的性能。
在几乎所有情况下,本文观察到统计上显著的改善几乎或超过2 BLEU。
对于PHP,ASAP方法第一次在这个具有挑战性的数据集上突破了30 BLEU。 - 本文发现ASAP方法还可以提高代码补全任务的性能。

模型与方法
在早期的工作中,基于transformer的预训练语言模型在NLP和软件工程中都提供了显著的收益。
预训练的语言模型可以分为三类:仅编码器、编码器-解码器和仅解码器模型。
虽然编码器-解码器模型最初在许多任务上显示出成功,但现在仅解码器的LLM在许多任务上更具可扩展性和有效性。
编码器-解码器模型:BERT是最早的预训练语言模型之一,使用两个自监督任务:带掩码机制的语言模型(MLM)和下一句预测(NSP)对其进行预训练。
后来,RoBERTa仅对BERT进行一些小调整,CodeBERT和GraphCodeBERT将这些思想引入软件工程,以非常相似的预训练目标进行训练,并解决更复杂的问题。
尽管CodeBERT和GraphCodeBERT是仅限编码器的模型,但它们可以应用于调优后的代码汇总,级联到在调优期间训练的解码器。
Ahmed和Devanbu报告说,多语言模型,通过多语言数据进行微调,比单语言模型表现更好。
他们还报告说,标识符在代码摘要生成任务中起着关键作用。
PLBART[2]和CodeT5[64]也包括预训练的解码器,据报道,它们在代码汇总任务中工作得很好。
最近,已经发现非常大规模(仅解码器)的自回归LLM(具有175B+参数)在没有任何显式训练的情况下,通过少量学习就可以成功地进行代码总结。
仅解码器模型
仅解码器模型(自回归模型):在生成式预训练中,任务是在给定之前的标记的情况下自动回归预测下一个标记,生成一段连续的文本。
这个模型一般包含一个解码器和一个嵌入层,用于将输入的标记嵌入到向量空间中。
解码器的每一步输入是上一步的输出和一个特殊的Token,表示当前位置,以此来区分不同位置的单词。
在预训练完这个模型之后,可以通过对解码器进行微调来进行特定任务的文本生成或者其他相关任务。
这种单向的自回归训练,可以防止模型从未来的tokens中收集信息。
较新的生成模型,如GPT, GPT-2和GPT-3,也以这种方式训练,但它们有更多的参数,并且是在更大的数据集上训练的。
当前的大型语言模型,如GPT-3,有大约(或超过)175B个参数。
这些强大的模型在很少的提示下表现得非常好,以至于人们对通过微调进行特定任务参数调整的兴趣降低了。
Codex是GPT-3的变体,在代码和自然语言注释方面进行了密集训练。
Codex家族包括两个版本:Codex-cushman,较小,有12B个参数;
CodexDavinci,最大,有175B个参数。 Codex模型被广泛用于各种任务。
本文的实验主要针对Code-davinci模型,特别是Code-davinci-002,它擅长于将自然语言翻译成代码,并支持代码补全和代码插入。
还有一些新型号,如TextDavinci-003和GPT-3.5-turbo;与Codex变体不同,这些模型理解并生成自然语言和代码。
虽然针对聊天功能进行了优化,但GPT-3.5-turbo在传统补全任务中也表现出色。
Text-Davinci-003是一个类似于Code-Davinci-002的补全模型。
本文使用Code-davinci-002,Text-Davinci-003和GPT-3.5-turbo模型研究ASAP提示增强是如何工作的。
Retrieving Exemplars from Training Data 从训练数据中检索样本
如前所述,当与非常大的模型一起使用时,few-shot学习效果相当好。
我们用少量的
然而,为少量的学习精心选择范例是有帮助的。
Nashid等人发现,基于检索的范例选择有助于解决断言生成和程序修复等问题[4]。根据他们的建议,使用BM25 信息检索(Information retrieval,IR)算法从训练集中选择相关的小样本。
BM25[55]是一种基于频率的检索方法,可以有效提高TF-IDF。
我们注意到,在few-shot学习中,与相同的固定示例相比,有了实质性的改进,实验部分也提供了响应的证明。
Nashid等人[4]比较了几种检索方法,发现BM25的效果最好,因此,后续实验也使用它。
[4] Noor Nashid, Mifta Sintaha, and Ali Mesbah. 2023. Retrieval-Based Prompt Selection for Code-Related Few-Shot Learning. In Proceedings, 45th ICSE.
Automatic Semantic Prompt Augmentation 自动语义提示增强
存储库名称和路径
使用特定域的信息增强提示可以提高LLM在各种任务上的性能。
先前的工作表明,使用来自同一存储库的代码增强提示可以提高代码摘要生成任务的性能。
我们认为,基本的存储库级元信息,如存储库名称和到存储库的完整路径,提供了额外的上下文。
例如,像“tony19/logback- android”,“apache/parquet-mr”和“ngageoint/ geo-package-android”这样的存储库名称都将函数连接到特定的域(例如,android, apache, geo-location),这可以增强对要总结的目标代码的理解。
展示了如何使用存储库级信息增强提示符的示例。与存储库名称类似,函数的路径也可以对模型做出贡献。
标记标识符
先前的工作表明,语言模型在生成代码摘要时发现标识符比代码结构更有价值。
然而,标识符在代码中扮演着不同的角色。局部变量、函数名、参数、全局变量等,在它们出现的方法的功能中起着不同的作用;阅读代码的开发人员当然知道标识符的角色,只需确定其作用范围和用途。
因此,使用标识符的特定角色来增加提示可以帮助模型更好地“理解”功能。ASAP使用TreeSitter遍历函数的AST并收集标识符及其角色。
尽管模型可以访问代码的token序列,因此也可以访问所有标识符,但它们以标记标识符的形式访问模型可能:a)为模型节省一些计算工作,b)更好地调节模型的输出。
展示了如何使用带标记的标识符增强函数的提示符。

数据流图(DFG)
Guo等人引入了GraphcodeBERT模型,该模型在预训练阶段中使用数据流图(DFG)代替抽象语法树(AST)等语法级结构。GraphcodeBERT在各种软件工程(SE)任务上的表现优于CodeBERT。
作者将这些DFG信息整合到few-shot的示例中,并推测,这为模型提供了对每个范例和目标示例的更好的语义理解。
每行包含一个标识符及其索引,以及该特定数据流向的标识符的索引。
与repo和带标签的标识符不同,数据流图可能非常长,因此不方便将完整的数据流添加到提示符中。
在长提示符的情况下,只在提示符中保留DFG的前30行。
除了标识符之外,DFG还提供了对标识符在函数中的重要性的更好理解。
显示了用于实验的数据流程图(DFG)

用例和补全流水线
ASAP有3个组成部分:一个LLM,一个可用示例池(标记的输入-输出对,例如,带注释的代码),以及一个用于从代码中获取事实的静态分析工具。一个配置文件会指定这些组件。
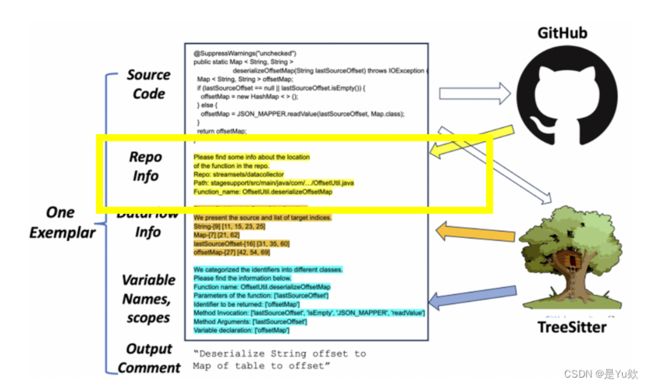
一旦配置完成后,开发人员对函数体Cin(如左图所示)调用ASAP ,并需要一个输出(例如,代码摘要)。 ASAP使用Cin对其样本池进行BM25检索以得到样本候选集 e c 1 ec_1 ec1, e c 2 ec_2 ec2 ……其中,每个 e c i ec_i eci 是< i n p u t i input_i inputi , o u t p u t i output_i outputi >形式的一对; 在本文的情景下, i n p u t i input_i inputi是函数定义, o u t p u t i output_i outputi 是函数头注释。BM25选择与给定的 C i n C_{in} Cin 最匹配的 i n p u t i input_i inputi 。
ASAP然后对输入 C i n C_{in} Cin 和几个范例输入 i n p u t i input_i inputi s应用程序分析,生成分析结果和几个 s。

我们将每个样本构建为一个三元组:
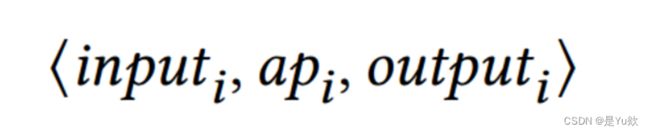
其中,每个三元组都为LLM说明了输入源代码input 通过分析结果到输出output 之间的关系。
最终的提示为:

ASAP然后用该提示符查询LLM,并返回补全(例如,自然语言摘要)。
默认情况下,ASAP被配置了分析来提取存储库信息、标记标识符、构建DFGs
默认情况下,ASAP被配置了分析来提取存储库信息、标记标识符、构建DFGs。这些分析是独立的,它们的输出分别在提示符中标记。
例如,图2显示了在ASAP构建的提示符中DFG分析的输出。这几个few-shot示例被扩展并插入到提示符中:代码、存储库信息、标记标识符、DFG和所需的(Gold)摘要都包含在每个few-shot中。目标示例仅包含分析结果,并提示LLM生成所需的输出。
在之前使用“chain of thought” 或“step by step”推理的工作中,没有给模型这样的信息,我们只是用一些指令帮助它组织对样本的推理。在这里,我们不是让模型自己进行推理,而是使用一个简单的程序分析工具向外部提供它,因为我们可以从非常有效的分析工具中获得非常精确的信息。每个小样本示例都包含源代码、派生信息和结论(摘要),从而为模型提供示例性的“思想链”,以便在生成所需的目标摘要时隐式使用。
下图展示了应用于每个样本的方法的整体流程。

三、实验数据集、指标和设置
Dataset
实验使用广泛使用的CodeSearchNet数据集。
CodeSearchNet是通过提取函数前缀文档的第一段来构建的,但受到一些限制(例如:长度)。它是一个仔细去重复的多项目数据集,允许(要求更高的)跨项目测试。
去重复是关键:与去重复数据集相比,机器学习模型中的代码重复可能会欺骗性地大大提高性能指标。
它是CodeXGLUE基准的一部分,该基准包括10个软件工程任务的14个数据集。
许多模型已经在这个数据集上进行了评估。CodeSearchNet包含来自六种不同编程语言(即Java, Python, JavaScript, Ruby, Go, PHP)的数千个示例。
然而,本文没有使用整个测试数据集,使用我们的模型API端点,这将是非常昂贵和缓慢的;相反,我们选择了从每种语言中均匀随机抽取1000个样本。
由于原始数据集是跨项目的,并且我们对其进行了统一采样,因此我们的子样本包含跨项目数据。
此外,对同一项目的数据集进行了子集设置:按创建日期对同一项目数据进行排序,确保只有时间较早的样本被使用。
这是现实的,因为只有较旧的、已经存在的数据可供使用。

Metrics指标
BLEU
BLEU是用于代码摘要生成和提交日志生成的最广泛使用的基于相似性的度量。BLEU计算在生成的候选译文和一个或多个参考译文中出现的-grams(通常用于∈[1…4])的比例;这些分数的几何平均值是BLEU,通常归一化为0-100的范围。在句子级粒度上,BLEU倾向于在很少(或没有)较长-grams的时候过度惩罚,因此,“句子BLEU”被批评与人类判断的相关性很差。
使用各种平滑技术来降低句子BLEU对稀疏-gram匹配的敏感性,并使其更符合人类质量评估。
本文报告了 两个变体的数据:BLEU-CN,它使用一种拉普拉斯平滑,BLEU-DC,它使用较新的平滑方法。其他提出的指标,如BERTScore、BLEURT、NUBIA,在计算上很昂贵,没有被广泛使用,因此不容易与之前的基准测试工作进行比较。
考虑到所有这些选项,代码摘要生成指标以及独立的提交日志生成指标一直存在争议。在本文中,遵循先前的工作,主要使用BLEU-CN,这便于将本文方法的结果与以前的工作进行比较。
CodeXGLUE基准
CodeXGLUE基准推荐BLEU-CN,并且大多数较新的模型使用该度量。
然而,本文并没有忽视其他措施。除了BLEU-CN和BLEU-DC,还汇报了另外两种测量方法ROUGE-L和METEOR的结果。
在所有的情况下,ASAP都实现了显著的整体改进:观察到除了Go以外的所有编程语言的收益都大于2.0 BLEU(表3)。
文章认为收益大于2.0 BLEU很重要,原因有两个:
首先Roy等人提供了基于人类主题研究的论点,即对于代码摘要生成(我们的中心任务),获得2.0或更高的BLEU更有可能符合人类对改进的感知。
其次,认为即使是较小的收益也很重要(特别是如果可重复且具有统计意义),因为这些任务的增量进展积累起来,会产生强大的实际影响,正如数十年来在自然语言翻译方面的工作所证明的那样。

Experimental Setup & Evaluation Criteria实验设置和评价标准
本文的主要模型是OpenAI的code-davici-002。本文使用测试版,通过它的web服务API。
为了平衡计算约束,如速率限制和对性能稳健估计的期望,本文选择每个实验处理使用1000个样本(每种语言一个处理,每个few-shot选择方法,使用ASAP,没使用ASAP等等)。
本文的实验在大多数情况下产生了统计上显著的、可解释的结果。每个1000个样本的测试仍然需要5到8个小时,(假设)随着OpenAI的负载因素而变化。根据OpenAI的建议,我们包括了尝试之间的等待时间。
为了从模型中得到明确的答案,文章发现有必要将所有实验的温度设置为0。
该模型的设计允许大约4Ktokens的窗口。这限制了少量样本的数量。在实验中,作者使用了3 shots。
然而,在每个实验中,多达2%的随机选择的样本,作者没有得到很好的结果,要么是提示符不适合模型的窗口,要么是模型神秘地生成了一个空字符串。
由于3个样本的构造太长,作者自动减少了shot数目。当发出空摘要时,通过增加shot次数来重新解决这个问题。这个简单、可重复、开销适中的过程可以合并到自动生成工具中。
本文评估了在不同的设置和使用不同的度量标准下,对代码摘要生成使用ASAP-enhanced提示符的好处。在对六种语言的研究中,发现了整体表现提高的证据。
然而,对于其他详细的分析,因为OpenAI API的速率限制,主要关注Java和Python。

实验结果
Encoder-decoders & Few-shot Learning
首先是在CodeSearchNet上使用基于IR的few-shot learning的基线结果。
先前的工作报告表明,对于程序修复和代码生成等任务,IR方法可以找到更好的少量提示样本。在表2中,我们观察到代码摘要生成也是如此。
我们注意到,仅仅使用BM25作为少量样本选择机制,Java和Python的BLEU-4得分分别提高了3.00(15.10%)和1.12(5.42%)。
由于BM25已经在之前的文章(尽管用于其他任务)中使用过,因此我们认为本文中基于BM25的代码总结的少量学习只是一个基线(而不是贡献本身)。

Prompt Enhanced Few-shot Learning提示增强的少样本学习
现在重点研究ASAP提示增强的效果。
表3显示了组合所有六种编程语言的所有提示组件后实现的组件方面的改进和总体改进。BLEU的改善范围从1.84(8.12%)到4.58(16.27%)。
在大多数情况下,我们看到超过2.0 BLEU的改进,这是Roy等人注意到的人类感知所需的阈值。
我们还注意到所有三个组件(即,Repository Information、标识符、 DFG数据流图)帮助模型在所有六种语言中获得更好的性能,因为我们将这些组件单独与BM25组合在一起。
然而,对于Ruby来说,最好的组合只包括Repo。信息。在大多数情况下,Repository Information相对于其他组件很有帮助。
为了确定改进的显著性,使用了威尔科克森符号秩检验,发现在所有情况下,本文的最终提示与普通BM25few-shot学习相比,即使在调整了错误发现风险之后,也具有统计学显著性。

Same Project Code Summarization相同的项目代码总结
由于预先存在的特定于项目的人工事实的价值,Few-shot学习对软件工程具有特殊的重要性。
这种本地上下文包括特定于项目的名称(用于标识符、API等),以及特定于每个项目的编码模式。
这些现象与项目领域的概念、算法和数据密切相关。有经验的开发人员利用先前的项目特定知识,更好更快地理解代码。
当然,这些细节也可以为机器学习模型提供有用的提示。但是,特定于项目的数据可能是有限的,例如在项目的开始阶段。
在few-shot设置下,即使是有限的特定项目数据,LLM利用这些数据的能力也是非常有用的。
为了了解本文提出的快速增强想法是否有助于特定于项目的代码摘要生成,在Ahmed和Devanbu的数据集上评估了ASAP方法。
由于速率限制,将四个Java和Python项目中的每个项目的测试样本数量减少到100个。由于每个项目测试的样本太少,作者将所有样本组合起来执行统计测试。
在处理同一个项目时,必须小心分割数据,以避免从未来的样本(期望的输出可能已经存在)泄漏到过去的样本。
因此,作者根据该数据集中的创建日期对样本进行排序。
在生成数据集之后,作者应用ASAP方法来评估相同项目设置下的性能,还将结果与交叉项目设置下的性能进行了比较,在交叉项目设置中,作者从完整的交叉项目训练集中检索样本。
表4显示了基于项目的代码摘要生成结果。可以看到,对于4个项目,跨项目的few-shot学习产生了最好的表现,而对于其他4个项目,相同项目的few-shot学习是最有效的。
我们注意到Ahmed & Devanbu没有使用IR来选择few-shot样本,并且在同一个项目的few-shot学习中始终获得了更好的结果。IR确实在Java和Python的大样本中找到了相关的例子,故得到了很好的结果。
作者分析了来自8个项目的16对平均BLEU,同时考虑了跨项目和同一项目的情况。在14例(87.5%)情景下,ASAP快速增强的few-shot学习优于普通BM25检索的few-shot学习。
这表明,在各个项目中,ASAP提示增强是有帮助的。ASAP统计上提高了跨项目和同一项目设置中的性能。

ASAP是模型无关的吗?
到目前为止,实验的结果与code-davinci-002模型有关。
故作者还将语义提示增强应用于另外两个模型,text-davinci-003和gpt-3.5-turbo(聊天模型),实验结果见表6。在Java、Python和PHP的500个样本上,ASAP快速增强的few-shot学习方法将gpt-3.5-turbo模型的性能提高了1.68%至9.13%,将test- davincii -003模型的性能提高了13.08%至18.69%。

Gpt-3.5-turbo在代码摘要生成时的性能比code- davincii -002和text-davincii-003更差。Turbo版本是冗长的,并且生成的注释在风格上不同于开发人员编写的注释,也不同于提示符中的几个示例。更加精细的提示词工程可能会改进turbo模型,使其产生更自然、更简短的注释;这是留给未来的工作。
Text-davinci-003模型显示了最大的性能提升(尽管仍然被code-davinci-002超越)。注意,text-davinci-003是一个补全模型,类似于code-davinci-002。本文的研究结果表明,与聊天模型相比,ASAP对补全模型更有效。作者还进行了威尔科克森符号秩检验,结果的统计显著性(除了java下的gpt-3.5-turbo)表明,ASAP将不仅仅适用于code-davinci-002模型。
ASAP for Completion
- 实验主要关注few-shot下的代码摘要生成
- 作者探讨了zero-shot下ASAP在
代码补全任务上的适用性 - 评估了包含行补全任务的语义事实的价值,模型根据前一行生成下一行
- 统一随机地从CodeSearchNet数据集中收集了9292个Java和6550个Python样本来进行评估
- 为每个样本随机选择一行,并让模型在给定所有前面的行的情况下生成这行
- 在应用ASAP时,在前面的行之前附加了存储库信息和其他语义事实(即标记的标识符,DFG)
- 在生成带标签的标识符和DFG时,作者
只使用了前一行的部分信息,以避免信息从后面的行泄漏到目标行。
与CodeXGLUE基准一致,作者使用两个指标,精确匹配(EM)和编辑相似性(ES),来衡量模型的性能。
具体来说,作者对EM进行了McNemar测试,并进行了威尔科克森符号秩检验,以评估模型的性能,类似于对代码摘要生成所做的测试。
表5展示实验结果,可以观察到EM的总体增益为5.79%,ES的总体增益为5.11%,突出了合并语义事实的有效性。对于Python,发现只有ES的改进具有统计学意义,而EM没有。

Performance on Other Metrics
除了BLEU-CN,作者还使用其他3个指标来衡量性能:BLEU-DC, ROUGE-L和METEOR。
在表10中,结果显示了ASAP在所有三个指标上的平均收益。作者进行了威尔科克森符号秩检验,发现BLEU-DC和ROUGE-L对所有语言的性能都有显著改善。
然而,在6种语言中的4种语言中没有观察到METEOR的显著差异,尽管在所有6种比较中,采用了ASAP的样本平均值确实有所改善。
值得注意的是,每种语言作者只用了1000个语言样本(由于成本),所以看到一些没有观察到显著性的情况并不意外。
为了评估ASAP的整体影响,作者将所有语言的数据集合并,并对code- davincic -002模型(6000个样本)进行相同的测试。然后,得到了所有三个指标的统计显著性(p值< 0.01),这表明ASAP确实有价值。

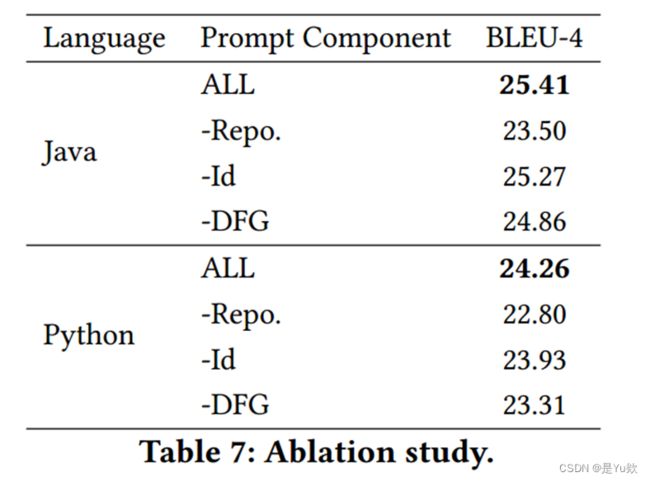
Ablation Study
消融研究的主要目的是衡量模型的每个方面对最终观察性能的贡献。在实验中,作者删除了增强提示的每个语义成分并观察性能。
可以发现Repo.组件对Java和Python语言下的模型性能贡献最大(表7)。但是,标记的标识符和DFG也很有帮助。当在提示符中组合所有三个组件时,可以获得最佳结果。
两个示例说明
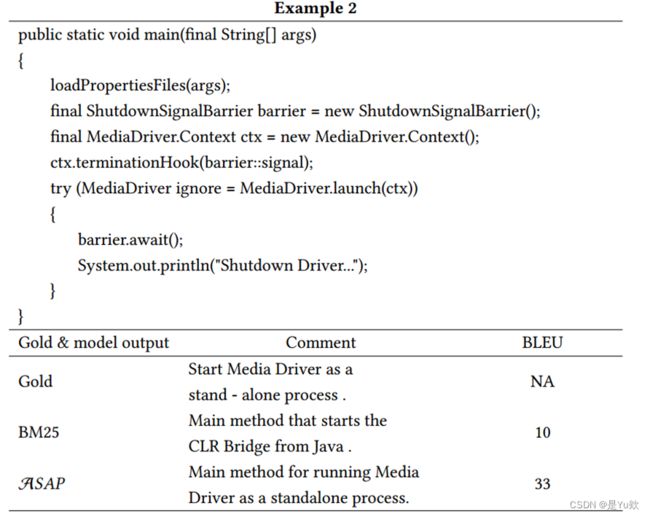
在手动检查结果时,观察到在几个示例中,ASAP增强提示能够恢复对摘要至关重要的新信息。表8显示了两个使用ASAP提示的示例结果。
在第一个示例中,基线模型未能生成术语“element-wise”。但是,本文提出的提示增强版本可以捕捉到这一重要的概念,与基线得分39.0相比,ASAP的BLEU-4得分为74.0。

类似地,在第二个示例中,基线模型没有将函数识别为standalone process,导致BLEU得分较低,为10.0。
然而,本文提出的方法确实将函数确定为一个standalone process,故得到更高的BLEU得分,为33.0。
五、讨论
Does the Model Memorize the Path?
在ASAP的三个要素中,作者发现存储信息对模型的性能影响最大。也许Code-Davinci-002模型在预训练期间就记住了数据中的特定文件路径,当我们提供函数的路径时,也许模型只是回忆其记忆的信息?
为了进一步研究这一怀疑,作者更改了路径表示:接受存储库名称和路径,在“/”处分割tokens,并采用tokens列表的形式呈现给模型。这种方法背后的主要思想是分散原始表示,并向模型呈现预训练期间未遇到的东西。如果模型不是字面上的记忆,它的性能应该不会受到影响。
作者观察到两个版本之间的差异非常小。对于Java,获得了0.24 BLEU,但对于Python,使用标记化的路径导致损失了0.04。这表明模型不太可能记住函数路径。
Is the Identifier Tag Necessary?
在本文中,作者为标识符分配角色,并在提示符中将它们标记为函数名、参数、标识符等。但是这种显式标记真的有助于性能吗?
为了研究这一点疑惑,作者比较了当提供一个普通的、“无标记”的标识符列表时模型的性能。文章观察到,与简单的无标记标识符列表相比,带标记的标识符为Java和Python带来了更好的性能。对于Java和Python,带标记的标识符方法的性能指标BLEU分别增加了0.41和1.22,这表明显式语义信息确实有助于提高模型性能。
What’s Better: More Shots or ASAP?
尽管LLM有数十亿个参数,但它的提示大小有限。例如,code-davinci-002和gpt-3.5-turbo支持仅允许4k标记的提示长度。ASAP增强确实消耗了一些可用的提示长度预算!因此,提出了两种设计选择:1)在提示符中使用更少的ASAP增强样本,或 2)使用更多的无增强的few-shot样本。
为了研究这个问题,作者还尝试在Java和Python语言下的code- davincii -002模型中使用4和5个shots(而不是3个)。然而,表9显示,使用BM25进行更多shots并不一定会带来更好的性能。在较高的采样率下,有可能引入不相关的样本,这可能会损害而不是帮助模型。
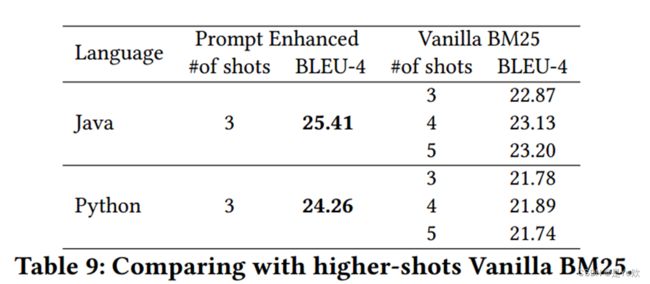
只有在Java中,与基线模型相比,观察到4次和5次shot的性能更好。然而,本文提出的技术只有3shot仍然优于使用5shot的BM25。值得注意的是,模型的上下文窗口每天都在增加,即将推出的GPT-4模型将允许我们拥有多达32K个tokens。因此,在不久的将来,长度限制可能不是一个问题。
然而,本文的研究表明,自动语义增强仍然是一种利用可用提示长度预算的有益方法;此外,构建更多信号丰富、信息丰富的提示,无论长度如何都是有益的。
六、威胁与限制
- 使用大型语言模型时的一个主要问题是:在训练期间测试数据可能
暴露。
遗憾的是,由于无法访问训练数据集,因此无法直接检查这一点。
模型在随机shot时的较低表现表明,记忆可能不是主要因素。当向模型纳入相关信息时,模型的性能随着信息的数量和质量而提高。如果模型已经记住了摘要,即使没有相关范例和语义增强带来的好处,它也可以获得更高的分数。 - 样本量分析:作者通过计算发现所需的样本量总是低于在上述实验中使用的样本量,即1000。
- 最后:对LLM进行微调以使用ASAP可能会提升我们的增强提示方法,但训练成本很高。将把微调部分留给未来的研究。
七、总结
- 在本文中,作者探讨了自动语义增强提示(ASAP)的方法,即提出使用通过语义分析自动派生的标记事实,增强LLM提示中的few-shot样本。
该方法基于一种 直觉,即开发人员经常浏览代码,在代码理解过程中隐式地提取这些事实,从而写出一个好的摘要。 - 虽然可以想象LLM可以自己隐式地推断出这些事实,但推测,在提示中以格式化的方式将这些事实添加到示例和目标中,将有助于LLM在寻求构建摘要时组织其“思维链”。
作者采用了一个具有挑战性的,去重的,精心策划的CodeSearchNet数据集,在两个任务(代码摘要生成和代码补全)上评估了这个想法。研究结果表明, ASAP通常是有用的,它有助于超越最先进的技术。