汇编语言学习笔记
汇编语言的不同种类
-
as86汇编:能产生16位代码的Intel 8086汇编
mov ax, cs //cs→ax,目标操作数在前 -
GNU as汇编:产生32位代码,使用AT&T系统V语法
movl var, %eax // var→%eax,目标操作数在后 -
内嵌汇编,gcc编译x.c文件会产生中间结果汇编文件
汇编语言的组成
汇编语言由三部分组成:
- 汇编指令。通过编译器把指令翻译成机器指令,也就是机器码
- 伪指令。告诉编译器如何翻译
- 符号体系。
+-*/
RAM和ROM
内存最小单元:字节
RAM(Random Access Memory)(随机存取存储器):允许读和写,断电后指令和数据就丢失了,直接与cpu交换数据
ROM(Read-Only Memory(只读存储器):只允许读,断电后指令和数据都存在
CPU中的三条总线
CPU通过地址总线,数据总线和控制总线实现对外部元器件的控制,三种总线的宽度标志了CPU不同方面的性能:
- 地址总线的宽度决定了CPU的寻址能力
- 数据总线的宽度决定了CPU与其他器件进行数据传输的能力(一次传输的数据量)
- 控制总线的宽度决定了CPU对系统中其他器件的控制能力
8086CPU给出读取物理地址的方法
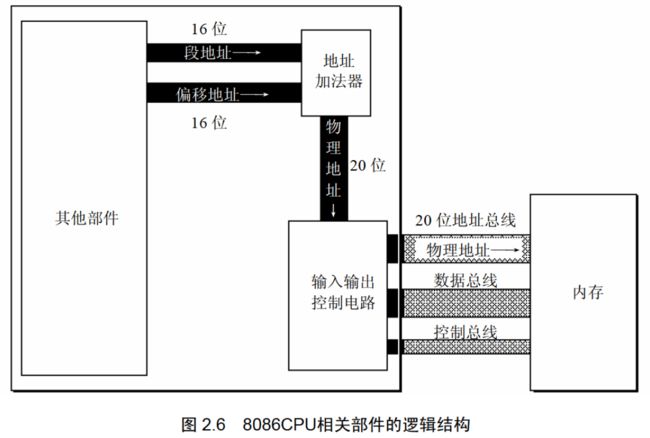
- CPU中的相关部件提供两个16位的地址,一个是段地址,一个是偏移地址
- 段地址和偏移地址通过内部总线送入一个成为地址加法器的部件
- 地址加法器将两个16位的地址合成为一个20位的物理地址
- 地址加法器通过内部总线将20位物理地址送入输入输出控制电路
- 20位物理地址被地址总线传送到存储器
物理地址 = 段地址 * 16 + 偏移地址(段地址*16就相当于左移4位)
上述的本质含义是:CPU在访问内存时,用一个基础地址和一个相对于基础地址的偏移地址相加,给出内存单元的物理地址。

为什么非得是基础地址+偏移地址的思想如上图所示
段寄存器
由于CPU访问内存时候需要相关部件提供内存单元的段地址和偏移地址,以便送入地址加法器合成物理地址,因此段寄存器主要提供段地址,8086CPU有4个段寄存器:**CS **
** 、DS、SS、ES**
CS:代码段寄存器
IP:指令指针寄存器
加入CS中的内容为M,IP中的内容为N,则从内存M*16+N单元开始读取一条指令并执行。即将CS:IP寄存器指向的内存单元当做指令,CS当做指令的段地址,IP当做偏移地址
总结一下寄存器和段寄存器的种类
寄存器:ax、bx、cx、dx、ah、al、bh、bl、ch、cl、dh、dl、sp、bp、si、di
段寄存器:ds、ss、cs、es
CPU中的栈
段寄存器SS和寄存器SP表示了栈顶的位置,栈顶的段地址存放在SS中,偏移地址存放在SP中。即SS:SP指向栈顶元素
push和pop指令执行时,CPU从SS和SP中得到栈顶的地址。
入栈的时候,栈顶从高地址向低地址方向增长。
8086处理器不会去管理栈顶超界的问题,需要我们自己小心是否会有越界行为。
总结:


源程序和程序
一段源程序包含汇编指令和伪指令,汇编指令是由计算机执行、处理的指令或者数据,一般叫做程序
伪指令就是不由计算机执行,而是编译器执行的代码
源程序就是程序+伪指令

程序执行过程的跟踪

1.obj是目标文件
目标文件要连接外界需要的库形成可执行文件
可执行文件被操作系统提供的shell程序加载进入内存,然后获得cpu执行
可执行文件中程序执行完毕后,cpu返还给shell0
[BX]和loop指令
[bx]和[0]有些类似,[0]表示内存单元,其偏移量是0,例如:
-
mov ax, [0]
表示将一个内存单元的内容送入ax中,这个内存单元的长度为2字节,存1个字,偏移地址为0,段地址在ds中
-
mov al, [0]
将一个内存单元的内容送入al中,这个内存单元的长度为1字节,存1个字节,偏移地址为0,段地址在ds中
-
mov ax, [bx]
将一个内存单元的内容送入ax中,这个内存单元的长度为2字节,存1个字,偏移地址在bx中,段地址在ds中
也可以段前缀来表示:
- mov ax,ds:[bx]
表示将一个内存单元的内容送入ax,这个内存单元2个字节,存放1个字,偏移地址在bx中,段地址在ds中
可执行文件的组成
可执行文件由描述信息和程序组成,程序来自于源程序中的汇编指令和定义的数据。描述信息则主要是编译,连接程序对源程序中相关伪指令进行处理所得到的信息。
数据、指令、栈放入不同的栈
CPU到底如何处理我们定义的段中的内容,是当做指令执行,当做数据访问还是当做栈空间,完全是靠程序中具体的汇编指令,即:
- CS:IP -----指令
- SS:SP----- 栈
- DS-----数据
与运算和或运算
-
与(and)
这个操作可以将操作对象的相应位置设为0,因为全1才为1。
-
或(or)
该操作可以将操作对象的相应位设为1,因为有1就为1。
[bx+idata]:一种更灵活的指明内存的方式
之前前面说到过用[bx]来指明一个内存单元,我们还可以用一种更为灵活的方式指明内存单元。
[bx+idata]表明一个内存单元,它的偏移地址为bx+idata(bx中的数值加上idata)
比如mov ax, [bx + 200]指的是将一个内存单元的内容送入ax,这个内存单元长2字节,存放1个字,偏移地址为bx中的数值加上200,段地址在ds中
几种不同的寻址方式
- **[idata]**用一个常量表示地址,可用于直接定位一个内存单元
- **[bx]**用一个变量来表示内存地址,可用于简介定位一个内存单元
- **[bx+idata]**用一个变量和常量来表示地址,可在一个起始地址的基础上用变量简介定位一个内存单元
- **[bx+si]**用两个变量表示地址
- **[bx+si+idata]**用两个变量和一个常量表示地址
汇编语言中数据位置的表达
-
立即数(idata)
直接包含在机器指令中的数据(执行前在CPU的指令缓冲器中)
-
寄存器
指令要处理的数据在寄存器中,给出相应寄存器的名就行
-
段地址(SA)和偏移地址(EA)
如果指令要处理的数据在内存中,在汇编指令中用[X]的格式给出SA、EA在某个段寄存器中
转移指令的原理
可以修改IP或同时修改CS和IP的指令统称为转移指令。转移指令就是可以控制CPU执行内存中某处代码的指令。
8086CPU的转移指令分为以下几类:
-
无条件转移指令
主要有jmp指令,可以同时修改CS和IP。主要给出两种信息:
-
转移的目的地址
-
转移的距离(段间转移、段内转移、段内近转移)
-
-
条件转移指令
jcxz指令,所有的有条件转移指令都是短转移,对IP的修改范围是:-128~127
-
循环指令
loop指令,短转移,对IP的修改范围是:-128~127循环指令
-
过程
-
中断
CALL和RET指令
call和ret指令都是转移指令,他们都修改IP,或同时修改CS和IP。
-
ret和retf
ret指令用栈中的数据修改IP的内容,从而实现近转移
retf指令用栈中的数据修改CS和IP的内容,从而实现远转移
-
call
CPU执行call指令时,有两步操作:
- 将当前的IP或CS和IP压入栈中
- 转移
call指令不能实现短转移
flag寄存器

-
ZF标志
零标志位,如果执行相关指令后结果为0,zf=1,若不为0,zf=0
对于运算指令如add、sub、mul、div等会影响标志寄存器
对于传送指令mov、push、pop等不会对寄存器有什么影响
-
PF标志
奇偶标志位。如果执行指令后结果所有bit位中1的个数是偶数,pf=1,为奇数,pf=0
-
SF标志
符号标志位。执行指令后结果如果为负数,sf=1,如果非负数,sf=0。
SF标志就是CPU对有符号数运算的一种记录,记录数据的正负。
-
CF标志
进位标志位。在进行无符号数运算的时候,它记录了运算结果的最高有效位向更高位的进位值,或从更高位的借位值。
当出现进位的时候,会将最高位保存起来,记录在CF位中
-
OF标志
溢出:在进行有符号数运算时,如果超过了机器所能表示的范围成为溢出。
溢出标志位。记录有符号数运算的结果是否发生了溢出,如果溢出of=1,否则of=0
cf和of的区别:cf是对无符号数运算有意义的标志位,of是对有符号数运算有意义的标志位
CPU的内中断
任何一个通用的CPU都具备一种能力,可以在执行完当前正在执行的指令后,检测到从CPU外部发送过来的或内部产生的一种特殊信息,并且可以立即对所接收到的信息进行处理。这种特殊的信息,称为:中断信息。
中断表明CPU不再接着向下执行,而是转去处理这个特殊的信息。
中断可以来自内部和外部,本书主要讨论内中断
内中断有以下几种情况产生:
- 除法错误
- 单步执行
- 执行into指令
- 执行int指令
中断是不同的信息,因此必须先识别不同信息来源。所以中断信息中必须包含识别来源的编码,叫做中断类型码。这个中断类型码是一个字节型数据,可以表示256种中断信息的来源。
- 中断过程
- 从中断信息中获取中断类型码
- 标志寄存器的值入栈(因为在中断过程中要改变标志寄存器的值,因此先将其保存在栈中)
- 设置标志寄存器的第8位TF和第9位IF的值为0
- CS的内容入栈
- IP的内容入栈
- 从内存地址为中断类型码*4和中断类型码 *4+2的两个字单元中读取中断处理程序的入口地址设置IP和CS
端口的读写
CPU可以直接读写一下3个地方的数据:
- CPU内部的寄存器
- 内存单元
- 端口
端口所在的芯片和CPU通过总线相连,所以端口地址和内存地址一样,通过地址总线来传送。CPU总共可以定位64KB个不同的端口,因此端口的范围是0~65535
端口的读写指令只有两条:in和out
外中断
CPU除了能够执行指令进行运算以外,还应该能够对外部设备进行控制,接收它们的输入,向它们进行输出。要及时处理外设的输入,要解决一下两个问题:
- 外设的输入随时可能发生,CPU如何得知
- CPU从何处得到外设的输入?
答:外设接口芯片中有若干寄存器,CPU将这些寄存器当做端口来访问。外设的输入不直接送入内存和CPU中,而是送入相关的接口芯片的端口中;同理,CPU向外设的输出也不是直接送入外设,而是先送入端口,再由相关芯片送到外设。因此,**CPU通过端口和外部设备进行联系。**由于外设的输入随时可能到达,因此CPU提供中断机制来满足这种要求。这种中断信息来自CPU外部,相关芯片向CPU发出相应的中断信息,CPU执行完当前的指令后,可以检测到发送过来的中断信息,引发中断过程进而处理外设输入。
外中断一共有两类:
- 可屏蔽中断。该中断CPU可以不响应。是否响应要看标志寄存器中IF位的设置,当CPU检测到可屏蔽中断信息时,IF=1,则CPU在执行完当前指令后响应中断,如果IF=0,则不响应可屏蔽中断。(键盘输入就属于可屏蔽中断)
- 不可屏蔽中断。指CPU必须响应的外中断,CPU执行完当前指令后,立即响应引发中断过程。
先送入端口,再由相关芯片送到外设。因此,**CPU通过端口和外部设备进行联系。**由于外设的输入随时可能到达,因此CPU提供中断机制来满足这种要求。这种中断信息来自CPU外部,相关芯片向CPU发出相应的中断信息,CPU执行完当前的指令后,可以检测到发送过来的中断信息,引发中断过程进而处理外设输入。
外中断一共有两类:
- 可屏蔽中断。该中断CPU可以不响应。是否响应要看标志寄存器中IF位的设置,当CPU检测到可屏蔽中断信息时,IF=1,则CPU在执行完当前指令后响应中断,如果IF=0,则不响应可屏蔽中断。(键盘输入就属于可屏蔽中断)
- 不可屏蔽中断。指CPU必须响应的外中断,CPU执行完当前指令后,立即响应引发中断过程。