K8s部署 Redis 主从集群

目录
编辑
一、环境准备
1.1 环境说明
1.2 安装说明
1.3 Redis集群说明
1)单实例模式
2)哨兵模式
3)集群模式
二、安装NFS
2.1 安装NFS
2.2 创建NFS共享文件夹
2.3 配置共享文件夹
2.4 使配置生效
2.5 查看所有共享目录
编辑
2.6 启动nfs
2.7 其他节点安装nfs-utils
三、创建PV卷
3.1 创建namespace
3.2 创建nfs 客户端sa授权
3.3 创建nfs 客户端
3.4 创建StoreClass
3.5 执行命令创建NFS sa授权、NFS客户端以及StoreClass
3.6 创建PV
3.7 执行命令创建PV
3.8 PV卷知识普及(解析为什么需要SC、PV)
四、搭建Redis集群
4.1 普及知识
4.2 创建headless服务
4.3 创建redis.conf配置
4.4 创建名称为redis-conf的Configmap
4.5 创建redis 对应pod集群
4.6 执行命令创建Service和Redis 集群Pod
4.7 查看集群状态
五、集群初始化
5.1 启动容器
5.2 替换ubuntu镜像源
5.3 安装软件环境
5.4 安装redis-trib
5.5 创建Redis集群
5.6 为Master添加slave
5.7 查看集群状态
编辑
5.8 查看集群节点情况
六、测试主从切换
6.1 查看节点的角色
6.2 删掉redis-0 Mster节点,观察情况
七、开放外网端口
7.1 创建用于外部访问的service
八、Redis故障转移疑问解答
一、环境准备
1.1 环境说明
本文搭建MongoDB,基于WMware虚拟机,操作系统CentOS 8,且已经基于Kubeadm搭好了k8s集群,k8s节点信息如下:
| 服务器 | IP地址 |
| master | 192.168.31.80 |
| node1 | 192.168.31.8 |
| node2 | 192.168.31.9 |
如需知道k8s集群搭建,可跳转我的文章《kubeadm部署k8s集群》查看。
1.2 安装说明
Redis ( Remote Dictionary Server),即远程字典服务。
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
1.3 Redis集群说明
一般来说,Redis部署有三种模式。
1)单实例模式
一般用于测试环境。
2)哨兵模式
在redis3.0以前,要实现集群一般是借助哨兵sentinel工具来监控master节点的状态。如果master节点异常,则会做主从切换,将某一台slave作为master。引入了哨兵节点,部署更复杂,维护成本也比较高,并且性能和高可用性等各方面表现一般。
3)集群模式
3.0 后推出的 Redis 分布式集群解决方案;主节点提供读写操作,从节点作为备用节点,不提供请求,只作为故障转移使用;如果master节点异常,也是会自动做主从切换,将slave切换为master。
后两者用于生产部署,但总的来说,集群模式明显优于哨兵模式。那么今天我们就来讲解下:k8s环境下,如何部署redis集群(三主三从)。
二、安装NFS
2.1 安装NFS
我选择在 master 节点创建 NFS 存储,首先执行如下命令安装 NFS:
yum -y install nfs-utils rpcbind2.2 创建NFS共享文件夹
mkdir -p /var/nfs/redis/pv{1..6}2.3 配置共享文件夹
vim /etc/exports
/var/nfs/redis/pv1 *(rw,sync,no_root_squash)
/var/nfs/redis/pv2 *(rw,sync,no_root_squash)
/var/nfs/redis/pv3 *(rw,sync,no_root_squash)
/var/nfs/redis/pv4 *(rw,sync,no_root_squash)
/var/nfs/redis/pv5 *(rw,sync,no_root_squash)
/var/nfs/redis/pv5 *(rw,sync,no_root_squash)2.4 使配置生效
exportfs -r
2.5 查看所有共享目录
exportfs -v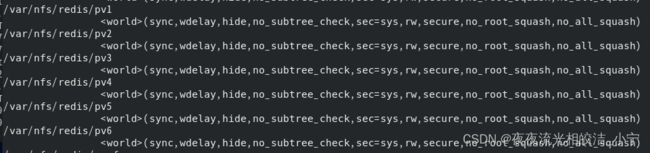
2.6 启动nfs
systemctl start nfs-server
systemctl enabled nfs-server
systemctl start rpcbind
systemctl enabled rpcbind2.7 其他节点安装nfs-utils
yum -y install nfs-utils三、创建PV卷
PersistentVolume简称pv,持久化存储,是k8s为云原生应用提供一种拥有独立生命周期的、用户可管理的存储的抽象设计。在创建PV卷之前,需要创建NFS客户端、NFS 客户端sa授权和StoreClass存储类。
3.1 创建namespace
kubectl create ns redis-cluster3.2 创建nfs 客户端sa授权
cat > redis-nfs-client-sa.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: redis-nfs-client
namespace: redis-cluster
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-runner
namespace: redis-cluster
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get","list","watch","create","delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get","list","watch","create","delete"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["get","list","watch","create","update","patch"]
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["create","delete","get","list","watch","patch","update"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-provisioner
namespace: redis-cluster
subjects:
- kind: ServiceAccount
name: redis-nfs-client
namespace: redis-cluster
roleRef:
kind: ClusterRole
name: nfs-client-runner
apiGroup: rbac.authorization.k8s.io3.3 创建nfs 客户端
cat > redis-nfs-client.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-nfs-client
labels:
app: redis-nfs-client
# replace with namespace where provisioner is deployed
namespace: redis-cluster
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: redis-nfs-client
template:
metadata:
labels:
app: redis-nfs-client
spec:
serviceAccountName: redis-nfs-client
containers:
- name: redis-nfs-client
image: quay.io/external_storage/nfs-client-provisioner:latest
volumeMounts:
- name: redis-nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME ## 这个名字必须与storegeclass里面的名字一致
value: my-redis-nfs
- name: ENABLE_LEADER_ELECTION ## 设置高可用允许选举,如果replicas参数等于1,可不用
value: "True"
- name: NFS_SERVER
value: 192.168.31.80 #修改为自己的ip(部署nfs的机器ip)
- name: NFS_PATH
value: /var/nfs/redis #修改为自己的nfs安装目录
volumes:
- name: redis-nfs-client-root
nfs:
server: 192.168.31.80 #修改为自己的ip(部署nfs的机器ip)
path: /var/nfs/redis #修改为自己的nfs安装目录3.4 创建StoreClass
StorageClass:简称sc,存储类,是k8s平台为存储提供商提供存储接入的一种声明。通过sc和相应的存储插件(csi)为容器应用提供持久存储卷的能力。
cat > redis-storeclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: redis-nfs-storage
namespace: redis-cluster
provisioner: my-redis-nfs3.5 执行命令创建NFS sa授权、NFS客户端以及StoreClass
kubectl apply -f redis-nfs-client-sa.yaml
kubectl apply -f redis-nfs-client.yaml
kubectl apply -f redis-storeclass.yaml3.6 创建PV
这里我们创建6个PV卷,分别对应Redis的三主三从。
cat > redis-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-nfs-pv1
namespace: redis-cluster
spec:
storageClassName: redis-nfs-storage
capacity:
storage: 500M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.31.80
path: "/var/nfs/redis/pv1"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-nfs-pv2
namespace: redis-cluster
spec:
storageClassName: redis-nfs-storage
capacity:
storage: 500M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.31.80
path: "/var/nfs/redis/pv2"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-nfs-pv3
namespace: redis-cluster
spec:
storageClassName: redis-nfs-storage
capacity:
storage: 500M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.31.80
path: "/var/nfs/redis/pv3"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-nfs-pv4
namespace: redis-cluster
spec:
storageClassName: redis-nfs-storage
capacity:
storage: 500M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.31.80
path: "/var/nfs/redis/pv4"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-nfs-pv5
namespace: redis-cluster
spec:
storageClassName: redis-nfs-storage
capacity:
storage: 500M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.31.80
path: "/var/nfs/redis/pv5"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: redis-nfs-pv6
namespace: redis-cluster
spec:
storageClassName: redis-nfs-storage
capacity:
storage: 500M
accessModes:
- ReadWriteMany
nfs:
server: 192.168.31.80
path: "/var/nfs/redis/pv6"3.7 执行命令创建PV
kubectl apply -f redis-pv.yaml3.8 PV卷知识普及(解析为什么需要SC、PV)
这里说一下,为什么要创建SC,PV?
因为redis集群,最终需要对应的文件有,redis.conf、nodes.conf、data,由此可见,这些文件每个节点,都得对应有自己得文件夹。
当然redis.conf可以是一个相同得,其他两个,就肯定是不一样得。如果使用挂载文件夹即是 Volume 的情况部署一个pod,很明显,是不能满足的。
当然,你部署多个不一样的pod,也是可以做到,但是就得写6个部署yaml文件,后期维护也很复杂。最好的效果是,写一个部署yaml文件,然后有6个replicas副本,就对应了我们redis集群(三主三从)。
那一个pod,再使用Volume挂载文件夹,这个只能是一个文件夹,是无法做到6个pod对应不同的文件夹。
所以这里,就引出了SC、PV了。使用SC、PV就可以实现,这6个pod启动,就对应上我们创建的6个PV,那就实现了redis.conf、nodes.conf、data,这三个文件,存放的路径,就是不一样的路径了。
四、搭建Redis集群
4.1 普及知识
RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的,而StatefulSet是什么?顾名思义,有状态的集合,管理所有有状态的服务,比如MySQL、MongoDB集群等。
StatefulSet本质上是Deployment的一种变体,在v1.9版本中已成为GA版本,它为了解决有状态服务的问题,它所管理的Pod拥有固定的Pod名称,启停顺序,在StatefulSet中,Pod名字称为网络标识(hostname),还必须要用到共享存储。
在Deployment中,与之对应的服务是service,而在StatefulSet中与之对应的headless service,headless service,即无头服务,与service的区别就是它没有Cluster IP,解析它的名称时将返回该Headless Service对应的全部Pod的Endpoint列表。
除此之外,StatefulSet在Headless Service的基础上又为StatefulSet控制的每个Pod副本创建了一个DNS域名,这个域名的格式为:
$(pod.name).$(headless server.name).${namespace}.svc.cluster.local
也即是说,对于有状态服务,我们最好使用固定的网络标识(如域名信息)来标记节点,当然这也需要应用程序的支持(如Zookeeper就支持在配置文件中写入主机域名)。
StatefulSet基于Headless Service(即没有Cluster IP的Service)为Pod实现了稳定的网络标志(包括Pod的hostname和DNS Records),在Pod重新调度后也保持不变。同时,结合PV/PVC,StatefulSet可以实现稳定的持久化存储,就算Pod重新调度后,还是能访问到原先的持久化数据。
以下为使用StatefulSet部署Redis的架构,无论是Master还是Slave,都作为StatefulSet的一个副本,并且数据通过PV进行持久化,对外暴露为一个Service,接受客户端请求。
4.2 创建headless服务
cat > redis-hs.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
name: redis-hs
namespace: redis-cluster
spec:
ports:
- name: nnbary
port: 6379
protocol: TCP
targetPort: 6379
selector:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
clusterIP: NoneHeadless service是StatefulSet实现稳定网络标识的基础。
网络访问:pod名称.headless名称.namespace名称.svc.cluster.local 即:pod名称.redis-hs.redis-cluster.svc.cluster.local。
4.3 创建redis.conf配置
/opt/redis/conf 目录下的redis.conf配置,待会创建Configmap需要用到
bind 0.0.0.0
port 6379
daemonize no
# requirepass redis-cluster
# 集群配置
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000requirepass redis-cluster 设置的是集群密码,注释掉是因为通过redis-trib实现集群初始化,有密码会初始化不了,暂时不知道该怎么解决,只能先把密码关掉,哈哈哈。
4.4 创建名称为redis-conf的Configmap
kubectl create configmap redis-conf --from-file=redis.conf -n redis-cluster4.5 创建redis 对应pod集群
cat > redis.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis
namespace: redis-cluster
labels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
spec:
replicas: 6
selector:
matchLabels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
serviceName: redis
template:
metadata:
labels:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis
spec:
terminationGracePeriodSeconds: 20
containers:
- name: redis
image: redis
command:
- "redis-server"
args:
- "/etc/redis/redis.conf"
- "--protected-mode"
- "no"
ports:
- name: redis
containerPort: 6379
protocol: "TCP"
- name: cluster
containerPort: 16379
protocol: "TCP"
volumeMounts:
- name: "redis-conf"
mountPath: "/etc/redis"
- name: "redis-data"
mountPath: "/data"
volumes:
- name: "redis-conf"
configMap:
name: "redis-conf"
items:
- key: "redis.conf"
path: "redis.conf"
volumeClaimTemplates:
- metadata:
name: redis-data
spec:
accessModes: [ "ReadWriteMany" ]
resources:
requests:
storage: 200M
storageClassName: redis-nfs-storage4.6 执行命令创建Service和Redis 集群Pod
kubectl apply -f redis-hs.yaml
kubectl apply -f redis.yaml4.7 查看集群状态
我们经过以上步骤之后,Redis的6个Pod 已经启动起来了,但是我们还没做集群初始化操作,此刻Redis还不是主从集群状态,我们可以检查验证下:
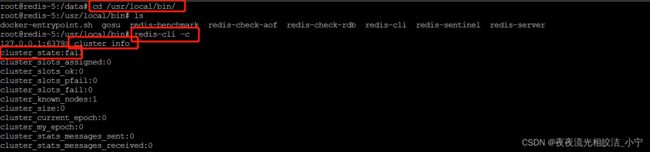
1、 进入容器(可以通过k8s页面,选中节点,通过base或sh进来),然后 cd /usr/local/bin/
2、连接上Redis节点: redis-cli -c
3、查看集群状态:cluster info
五、集群初始化
Redis集群必须在所有节点启动后才能进行初始化,而如果将初始化逻辑写入Statefulset中,则是一件非常复杂而且低效的行为。我们可以在K8S上创建一个额外的容器,专门用于进行K8S集群内 部某些服务的管理控制。 这里,我们专门启动一个Ubuntu的容器,可以在该容器中安装Redis-tribe,进而初始化Redis集群。
5.1 启动容器
kubectl run -it ubuntu --image=ubuntu --namespace=redis-cluster --restart=Never /bin/bash5.2 替换ubuntu镜像源
cat > /etc/apt/sources.list << EOF
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
EOF5.3 安装软件环境
apt-get update
apt-get install -y vim wget python2.7 python-pip redis-tools dnsutils5.4 安装redis-trib
pip install redis-trib==0.5.15.5 创建Redis集群
redis-trib.py create \
`dig +short redis-0.redis-hs.redis-cluster.svc.cluster.local`:6379 \
`dig +short redis-1.redis-hs.redis-cluster.svc.cluster.local`:6379 \
`dig +short redis-2.redis-hs.redis-cluster.svc.cluster.local`:63795.6 为Master添加slave
redis-trib.py replicate \
--master-addr `dig +short redis-0.redis-hs.redis-cluster.svc.cluster.local`:6379 \
--slave-addr `dig +short redis-3.redis-hs.redis-cluster.svc.cluster.local`:6379
redis-trib.py replicate \
--master-addr `dig +short redis-1.redis-hs.redis-cluster.svc.cluster.local`:6379 \
--slave-addr `dig +short redis-4.redis-hs.redis-cluster.svc.cluster.local`:6379
redis-trib.py replicate \
--master-addr `dig +short redis-2.redis-hs.redis-cluster.svc.cluster.local`:6379 \
--slave-addr `dig +short redis-5.redis-hs.redis-cluster.svc.cluster.local`:6379
5.7 查看集群状态
cluster info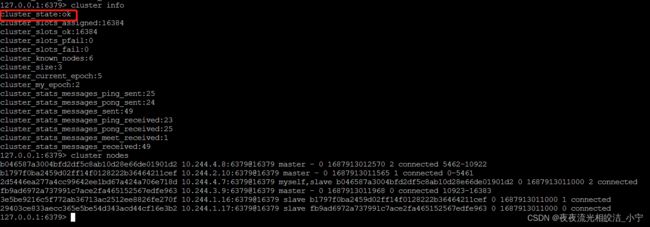
5.8 查看集群节点情况
cluster nodes
六、测试主从切换
在K8S上搭建完好Redis集群后,我们最关心的就是其原有的高可用机制是否正常。这里,我们可以任意挑选一个Master的Pod来测试集群的主从切换机制。
这里我以我的redis-0节点做演示。
6.1 查看节点的角色
1、 进入容器(可以通过k8s页面,选中节点,通过base或sh进来),然后 cd /usr/local/bin/
2、连接上Redis节点: redis-cli -c
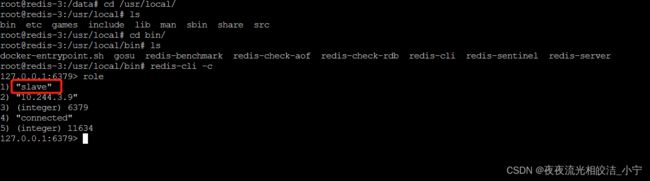
3、查看节点角色:role

可以看出,我们的redis-0节点,是Master节点,他的Slave 节点IP是10.244.1.17,即我们的redis-3节点。

进入redis-3节点,验证,发现确实是这样的:
6.2 删掉redis-0 Mster节点,观察情况
首先查看redis-o节点
kubectl get pod redis-0 -n redis-cluster -o wide
接着删除该Pod
kubectl delete pod redis-0 -n redis-cluster![]()

再次进入redis-0节点查看它的角色信息
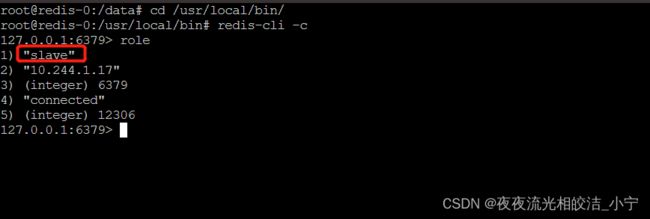
发现redis-0节点变成了slave节点,而他的Master节点,变成了10.244.1.17,即redis-3节点。证明了我们的Redis 主从集群是可用的。
七、开放外网端口
前面我们创建了用于实现StatefulSet的Headless Service,但该Service没有Cluster Ip,因此不能用于外界访问。所以,我们还需要创建一个Service,专用于为Redis集群提供访问和负载均衡。
7.1 创建用于外部访问的service
cat > redis-access-service.yaml
apiVersion: v1
kind: Service
metadata:
name: redis-access-service
labels:
app: redis-outip
spec:
ports:
- name: redis-port
protocol: "TCP"
port: 6379
targetPort: 6379
selector:
k8s.kuboard.cn/layer: db
k8s.kuboard.cn/name: redis八、Redis故障转移疑问解答
大家可能会疑惑,那为什么没有使用稳定的标志,Redis Pod也能正常进行故障转移呢?这涉及了Redis本身的机制。因为,Redis集群中每个节点都有自己的NodeId(保存在自动生成的 nodes.conf中),并且该NodeId不会随着IP的变化和变化,这其实也是一种固定的网络标志。也就 是说,就算某个Redis Pod重启了,该Pod依然会加载保存的NodeId来维持自己的身份。我们可以在进入redis-0容器,看的nodes.conf文件:

如上,第一列为NodeId,稳定不变;第二列为IP和端口信息,可能会改变。 这里,我们介绍NodeId的两种使用场景: 当某个Slave Pod断线重连后IP改变,但是Master发现其NodeId依旧, 就认为该Slave还是之前的 Slave。 当某个Master Pod下线后,集群在其Slave中选举重新的Master。待旧Master上线后,集群发现其 NodeId依旧,会让旧Master变成新Master的slave。
好了,今天的Redis集群部署就分享到这里!欢约大家点赞+收藏,有疑问也欢迎大家评论留言!