Python学完可实现90%数据分析绘图:Seaborn神器
最近小伙伴问我有什么刷题网站推荐,在这里推荐一下牛客网,里面包含各种面经题库,全是免费的题库,可以全方面提升你的职业竞争力,提升编程实战技巧,赶快来和我一起刷题吧!牛客网链接|python篇
本章主要介绍python的seaborn数据可视化的应用
文章目录
- Python数据可视化
- python数据可视化大杀器之Seaborn详解
- ️1.关系图
-
- 1.1 lineplot
- 1.2 relplot
- 1.3 scatterplot(散点图)
- 1.4 气泡图
- 2. 分类型图表
-
- 2.1 boxplot(箱线图)
- 2.2 violinplot(小提琴图)
- 2.3 barplot(条形图)
- 2.4 pointplot(点图)
- 2.5 swarmplot
- 2.6 catplot(分类型图表的接口)
- 3.分布图
-
- 3.1 displot(单变量分布图)
- 3.2kdeplot(核密度估计图)
- ☘️3.3绘制山脊图
- 3.4 joinplot(双变量关系分布图)
- 3.5 pairplot(变量关系图)
- 4. 回归图
-
- 4.1 lmplot
- 4.2 residplot(残差图)
- 5.矩阵图
-
- 5.1 heatmap(热力图)
- 5.2 clustermap聚类图
- ✏️6.FacetGrid绘制多个图表
-
- ✒️6.1 绘制多个直方图
- ️6.2 绘制多个折线图
- 文章推荐
python数据可视化大杀器之Seaborn详解
一张好的图胜过一千个字,一个好的数据分析师必须学会用图说话。python作为数据分析最常用的工具之一,它的可视化功能也很强大,matplotlib和seaborn库使得绘图变得更加简单。本章主要介绍一下Searborn绘图。学过matplotlib的小伙伴们一定被各种参数弄得迷糊,而seaborn则避免了这些问题,废话少说,我们来看看seaborn具体是怎样使用的。
Seaborn中概况起来可以分为五大类图
- 1.关系类绘图
- 2.分类型绘图
- 3.分布图
- 4.回归图
- 5.矩阵图
接下来我们一一讲解这些图形的应用,首先我们要导入一下基本的库
%matplotlib inline
# 如果不添加这句,是无法直接在jupyter里看到图的
import seaborn as sns
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
如果上面报错的话需要安装相应的包
pip install seaborn
pip install numpy
pip install pandas
pip install matplotlib
我们可以使用set()设置一下seaborn的主题,一共有:darkgrid,whitegrid,dark,white,ticks,大家可以根据自己的喜好设置相应的主题,默认是darkgrid。我这里就设置darkgrid风格
sns.set(style="darkgrid")
接下来导入我们需要的数据集,seaborn和R语言ggplot2(感兴趣欢迎阅读我的R语言ggplot2专栏)一样有许多自带的样例数据集
# 导入anscombe数据集
df = sns.load_dataset('anscombe')
# 观察一下数据集形式
df.head()
| dataset | x | y | |
|---|---|---|---|
| 0 | I | 10.0 | 8.04 |
| 1 | I | 8.0 | 6.95 |
| 2 | I | 13.0 | 7.58 |
| 3 | I | 9.0 | 8.81 |
| 4 | I | 11.0 | 8.33 |
️1.关系图
1.1 lineplot
绘制线段
seaborn里的lineplot函数所传数据必须为一个pandas数组,这一点跟matplotlib里有较大区别,并且一开始使用较为复杂,sns.lineplot里有几个参数值得注意。
-
x: plot图的x轴label
-
y: plot图的y轴label
-
ci: 置信区间
-
data: 所传入的pandas数组
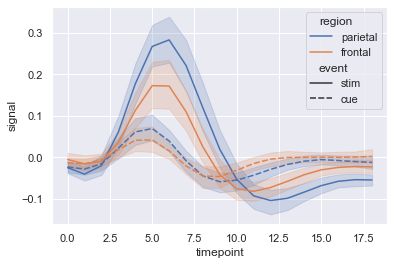
绘制时间序列图
# 导入数据集
fmri = sns.load_dataset("fmri")
# 绘制不同地区不同时间 x和y的线性关系图
sns.lineplot(x="timepoint", y="signal",
hue="region", style="event",
data=fmri)
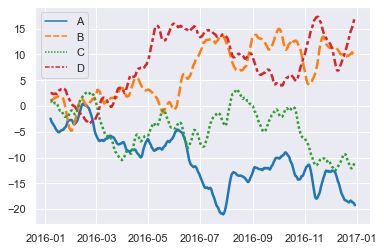
rs = np.random.RandomState(365)
values = rs.randn(365, 4).cumsum(axis=0)
dates = pd.date_range("1 1 2016", periods=365, freq="D")
data = pd.DataFrame(values, dates, columns=["A", "B", "C", "D"])
data = data.rolling(7).mean()
sns.lineplot(data=data, palette="tab10", linewidth=2.5)
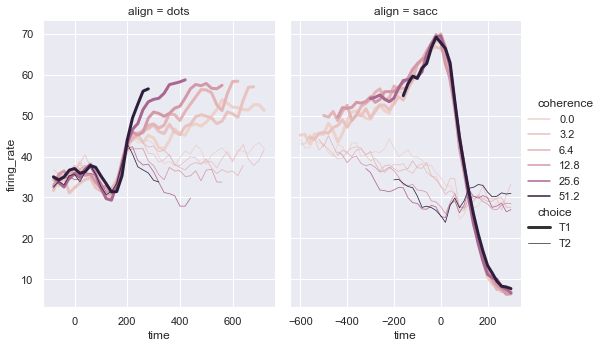
1.2 relplot
这是一个图形级别的函数,它用散点图和线图两种常用的手段来表现统计关系。
# 导入数据集
dots = sns.load_dataset("dots")
sns.relplot(x="time", y="firing_rate",
hue="coherence", size="choice", col="align",
size_order=["T1", "T2"],
height=5, aspect=.75, facet_kws=dict(sharex=False),
kind="line", legend="full", data=dots)
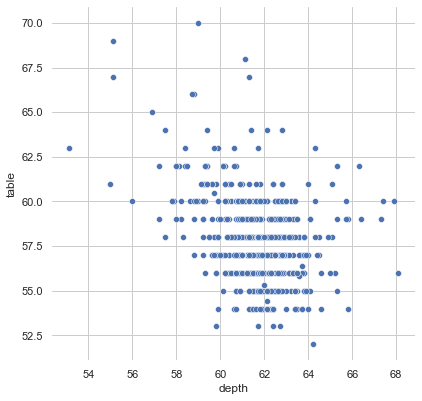
1.3 scatterplot(散点图)
diamonds.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326.0 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326.0 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327.0 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334.0 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335.0 | 4.34 | 4.35 | 2.75 |
sns.set(style="whitegrid")
# Load the example iris dataset
diamonds = sns.load_dataset("diamonds")
# Draw a scatter plot while assigning point colors and sizes to different
# variables in the dataset
f, ax = plt.subplots(figsize=(6.5, 6.5))
sns.despine(f, left=True, bottom=True)
sns.scatterplot(x="depth", y="table",
data=diamonds, ax=ax)
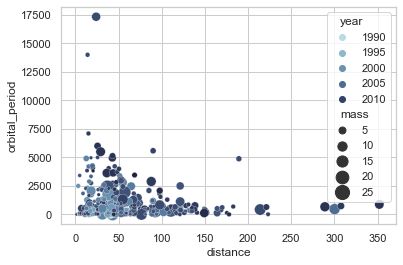
1.4 气泡图
气泡图是在散点图的基础上,指定size参数,根据size参数的大小来绘制点的大小
- 1.4.1 普通气泡图
# 导入鸢尾花数据集
planets = sns.load_dataset("planets")
cmap = sns.cubehelix_palette(rot=-.2, as_cmap=True)
ax = sns.scatterplot(x="distance", y="orbital_period",
hue="year", size="mass",
palette=cmap, sizes=(10, 200),
data=planets)
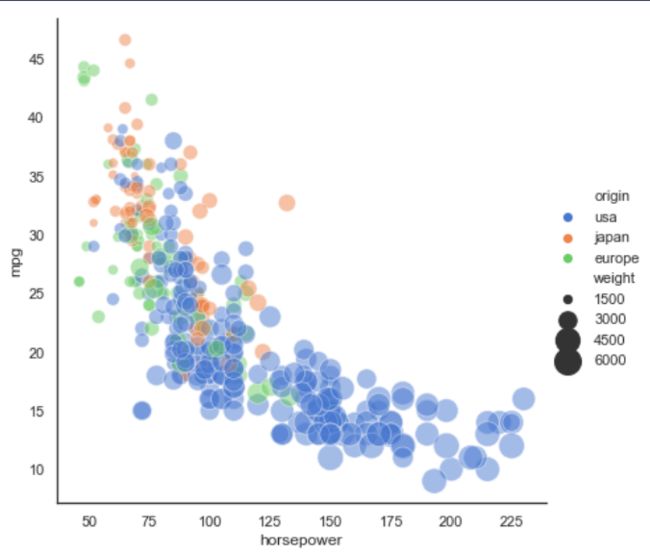
- 1.4.2 彩色气泡图
sns.set(style="white")
#加载示例mpg数据集
mpg = sns.load_dataset("mpg")
# 绘制气泡图
sns.relplot(x="horsepower", y="mpg", hue="origin", size="weight",
sizes=(40, 400), alpha=.5, palette="muted",
height=6, data=mpg)
2. 分类型图表
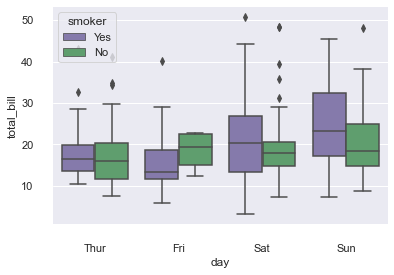
2.1 boxplot(箱线图)
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。
绘制分组箱线图
# 导入数据集
tips = sns.load_dataset("tips")
# 绘制嵌套的箱线图,按日期和时间显示账单
sns.boxplot(x="day", y="total_bill",
hue="smoker", palette=["m", "g"],
data=tips)
sns.despine(offset=10, trim=True)
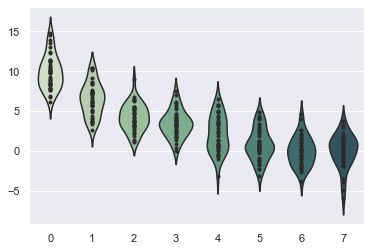
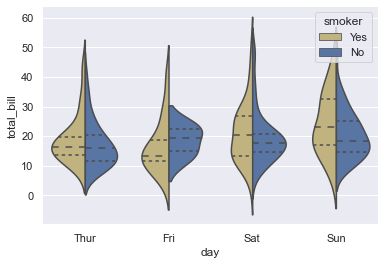
2.2 violinplot(小提琴图)
violinplot与boxplot扮演类似的角色,它显示了定量数据在一个(或多个)分类变量的多个层次上的分布,这些分布可以进行比较。不像箱形图中所有绘图组件都对应于实际数据点,小提琴绘图以基础分布的核密度估计为特征。
绘制简单的小提琴图
# 生成模拟数据集
rs = np.random.RandomState(0)
n, p = 40, 8
d = rs.normal(0, 2, (n, p))
d += np.log(np.arange(1, p + 1)) * -5 + 10
# 使用cubehelix获得自定义的顺序调色板
pal = sns.cubehelix_palette(p, rot=-.5, dark=.3)
# 如何使用小提琴和圆点进行每种分布
sns.violinplot(data=d, palette=pal, inner="point")
绘制分组小提琴图
tips = sns.load_dataset("tips")
# 绘制一个嵌套的小提琴图,并拆分小提琴以便于比较
sns.violinplot(x="day", y="total_bill", hue="smoker",
split=True, inner="quart",
palette={"Yes": "y", "No": "b"},
data=tips)
sns.despine(left=True)
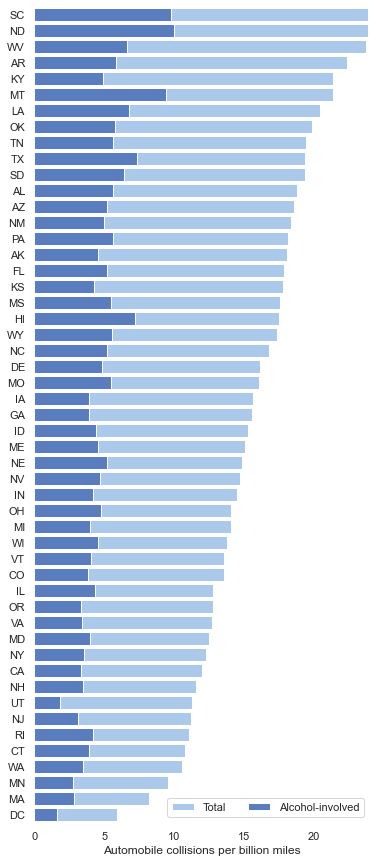
2.3 barplot(条形图)
条形图表示数值变量与每个矩形高度的中心趋势的估计值,并使用误差线提供关于该估计值附近的不确定性的一些指示。
绘制水平的条形图
crashes = sns.load_dataset("car_crashes").sort_values("total", ascending=False)
# 初始化画布大小
f, ax = plt.subplots(figsize=(6, 15))
# 绘出总的交通事故
sns.set_color_codes("pastel")
sns.barplot(x="total", y="abbrev", data=crashes,
label="Total", color="b")
# 绘制涉及酒精的车祸
sns.set_color_codes("muted")
sns.barplot(x="alcohol", y="abbrev", data=crashes,
label="Alcohol-involved", color="b")
# 添加图例和轴标签
ax.legend(ncol=2, loc="lower right", frameon=True)
ax.set(xlim=(0, 24), ylabel="",
xlabel="Automobile collisions per billion miles")
sns.despine(left=True, bottom=True)
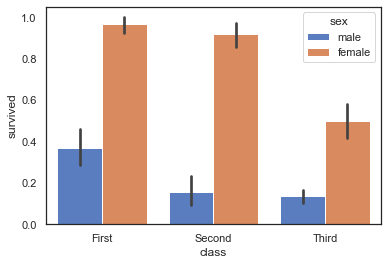
绘制分组条形图
titanic = sns.load_dataset("titanic")
# 绘制分组条形图
g = sns.barplot(x="class", y="survived", hue="sex", data=titanic,
palette="muted")
2.4 pointplot(点图)
点图代表散点图位置的数值变量的中心趋势估计,并使用误差线提供关于该估计的不确定性的一些指示。点图可能比条形图更有用于聚焦一个或多个分类变量的不同级别之间的比较。他们尤其善于表现交互作用:一个分类变量的层次之间的关系如何在第二个分类变量的层次之间变化。连接来自相同色调等级的每个点的线允许交互作用通过斜率的差异进行判断,这比对几组点或条的高度比较容易。
sns.set(style="whitegrid")
iris = sns.load_dataset("iris")
# 将数据格式调整
iris = pd.melt(iris, "species", var_name="measurement")
# 初始化图形
f, ax = plt.subplots()
sns.despine(bottom=True, left=True)
sns.stripplot(x="value", y="measurement", hue="species",
data=iris, dodge=True, jitter=True,
alpha=.25, zorder=1)
# 显示条件平均数
sns.pointplot(x="value", y="measurement", hue="species",
data=iris, dodge=.532, join=False, palette="dark",
markers="d", scale=.75, ci=None)
# 图例设置
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles[3:], labels[3:], title="species",
handletextpad=0, columnspacing=1,
loc="lower right", ncol=3, frameon=True)
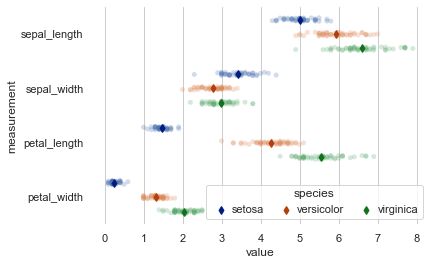
可以看出各种鸢尾花四个特征的分布情况,以setosa为例,发现其petal_width值集中分布在0.2左右
2.5 swarmplot
能够显示分布密度的分类散点图
sns.set(style="whitegrid", palette="muted")
# 加载数据集
iris = sns.load_dataset("iris")
# 处理数据集
iris = pd.melt(iris, "species", var_name="measurement")
# 绘制分类散点图
sns.swarmplot(x="measurement", y="value", hue="species",
palette=["r", "c", "y"], data=iris)
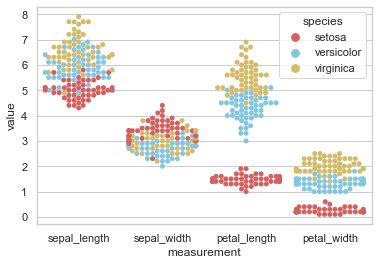
2.6 catplot(分类型图表的接口)
可以通过指定kind参数分别绘制下列图形:
- stripplot() 分类散点图
- swarmplot() 能够显示分布密度的分类散点图
- boxplot() 箱图
- violinplot() 小提琴图
- boxenplot() 增强箱图
- pointplot() 点图
- barplot() 条形图
- countplot() 计数图
3.分布图
3.1 displot(单变量分布图)
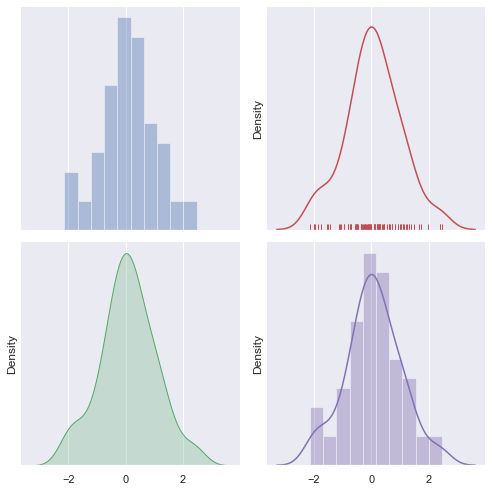
在seaborn中想要对单变量分布进行快速了解最方便的就是使用distplot()函数,默认情况下它将绘制一个直方图,并且可以同时画出核密度估计(KDE)图。具体用法如下:
# 设置并排绘图,讲一个画布分为2*2,大小为7*7,X轴固定,通过ax参数指定绘图位置,可以看第六章具体怎么绘制多个图在一个画布中
f, axes = plt.subplots(2, 2, figsize=(7, 7), sharex=True)
sns.despine(left=True)
rs = np.random.RandomState(10)
# 生成随机数
d = rs.normal(size=100)
# 绘制简单的直方图,kde=False不绘制核密度估计图,下列其他图类似
sns.distplot(d, kde=False, color="b", ax=axes[0, 0])
# 绘制核密度估计图和地毯图
sns.distplot(d, hist=False, rug=True, color="r", ax=axes[0, 1])
# 绘制填充核密度估计图
sns.distplot(d, hist=False, color="g", kde_kws={"shade": True}, ax=axes[1, 0])
# 绘制直方图和核密度估计
sns.distplot(d, color="m", ax=axes[1, 1])
plt.setp(axes, yticks=[])
plt.tight_layout()
3.2kdeplot(核密度估计图)
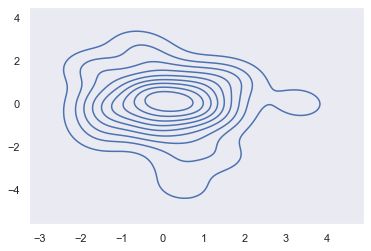
核密度估计(kernel density estimation)是在统计学中用来估计未知分布的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。具体用法如下:
简单的二维核密度估计图
sns.set(style="dark")
rs = np.random.RandomState(50)
x, y = rs.randn(2, 50)
sns.kdeplot(x, y)
f.tight_layout()
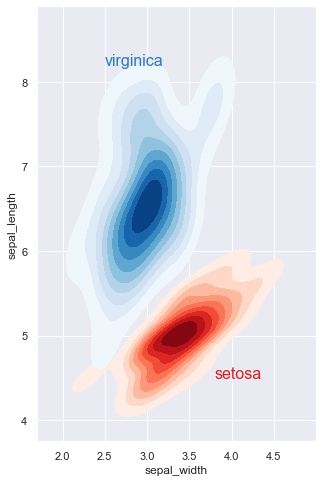
多个核密度估计图
sns.set(style="darkgrid")
iris = sns.load_dataset("iris")
# 按物种对iris数据集进行子集划分
setosa = iris.query("species == 'setosa'")
virginica = iris.query("species == 'virginica'")
f, ax = plt.subplots(figsize=(8, 8))
ax.set_aspect("equal")
# 画两个密度图
ax = sns.kdeplot(setosa.sepal_width, setosa.sepal_length,
cmap="Reds", shade=True, shade_lowest=False)
ax = sns.kdeplot(virginica.sepal_width, virginica.sepal_length,
cmap="Blues", shade=True, shade_lowest=False)
# 将标签添加到绘图中
red = sns.color_palette("Reds")[-2]
blue = sns.color_palette("Blues")[-2]
ax.text(2.5, 8.2, "virginica", size=16, color=blue)
ax.text(3.8, 4.5, "setosa", size=16, color=red)
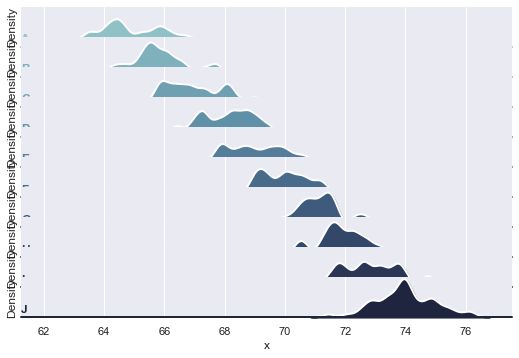
☘️3.3绘制山脊图
rs = np.random.RandomState(1979)
x = rs.randn(500)
g = np.tile(list("ABCDEFGHIJ"), 50)
df = pd.DataFrame(dict(x=x, g=g))
m = df.g.map(ord)
df["x"] += m
# 初始化FacetGrid对象
pal = sns.cubehelix_palette(10, rot=-.25, light=.7)
g = sns.FacetGrid(df, row="g", hue="g", aspect=15, height=.5, palette=pal)
# 画出密度
g.map(sns.kdeplot, "x", clip_on=Fals
"?e, shade=True, alpha=1, lw=1.5, bw=.2)
g.map(sns.kdeplot, "x", clip_on=False, color="w", lw=2, bw=.2)
g.map(plt.axhline, y=0, lw=2, clip_on=False)
# 定义并使用一个简单的函数在坐标轴中标记绘图
def label(x, color, label):
ax = plt.gca()
ax.text(0, .2, label, fontweight="bold", color=color,
ha="left", va="center", transform=ax.transAxes)
g.map(label, "x")
# 将子地块设置为重叠
g.fig.subplots_adjust(hspace=-.25)
# 删除与重叠不协调的轴
g.set_titles("")
g.set(yticks=[])
g.despine(bottom=True, left=True)
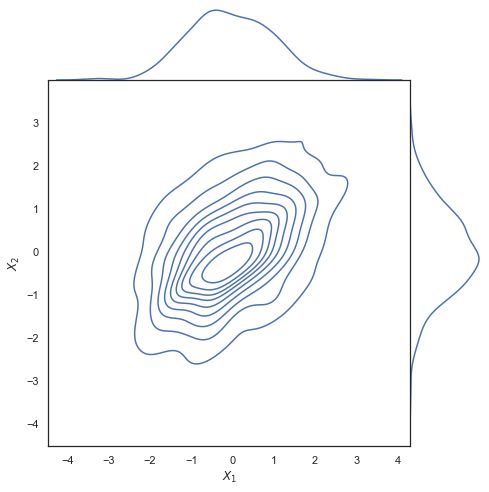
3.4 joinplot(双变量关系分布图)
用于绘制两个变量间分布图
sns.set(style="white")
# 创建模拟数据集
rs = np.random.RandomState(5)
mean = [0, 0]
cov = [(1, .5), (.5, 1)]
x1, x2 = rs.multivariate_normal(mean, cov, 500).T
x1 = pd.Series(x1, name="$X_1$")
x2 = pd.Series(x2, name="$X_2$")
# 使用核密度估计显示联合分布
g = sns.jointplot(x1, x2, kind="kde", height=7, space=0)
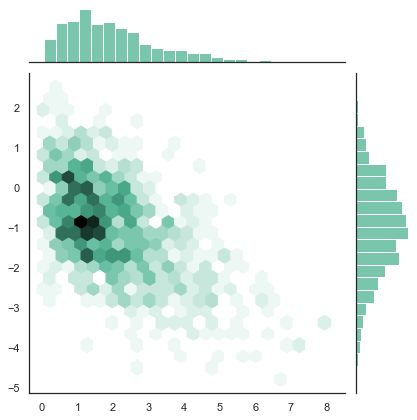
rs = np.random.RandomState(11)
x = rs.gamma(2, size=1000)
y = -.5 * x + rs.normal(size=1000)
sns.jointplot(x, y, kind="hex", color="#4CB391")
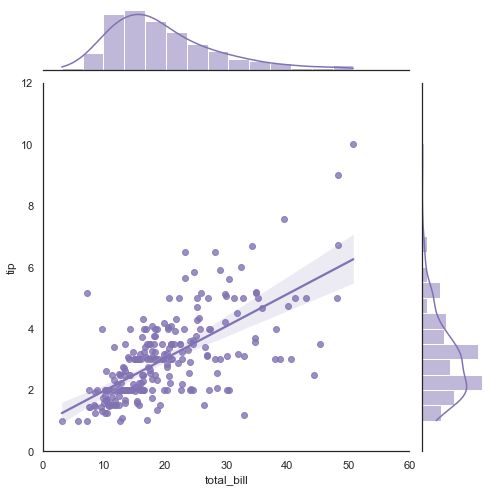
tips = sns.load_dataset("tips")
g = sns.jointplot("total_bill", "tip", data=tips, kind="reg",
xlim=(0, 60), ylim=(0, 12), color="m", height=7)
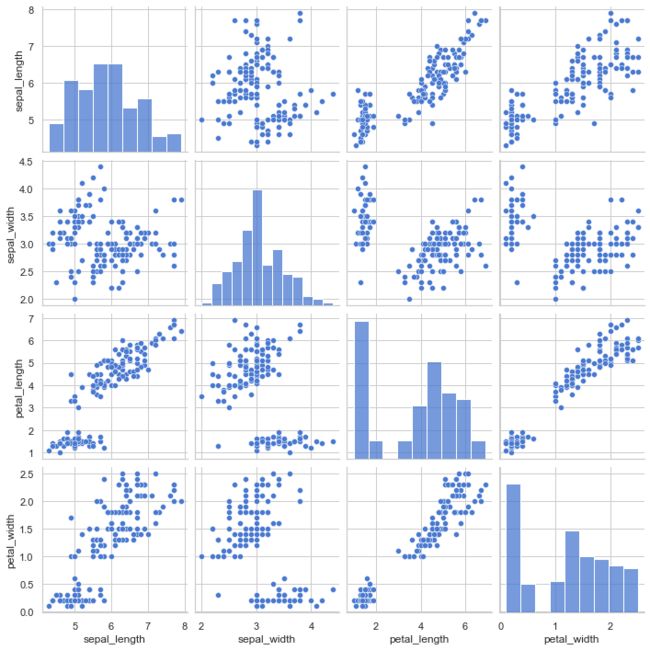
3.5 pairplot(变量关系图)
变量关系组图,绘制各变量之间散点图
df = sns.load_dataset("iris")
sns.pairplot(df)
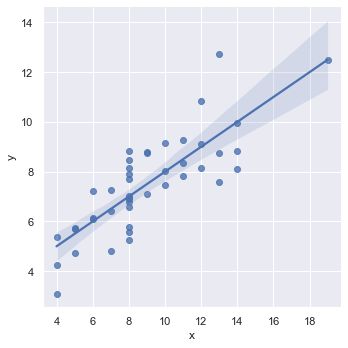
4. 回归图
4.1 lmplot
lmplot是用来绘制回归图的,通过lmplot我们可以直观地总览数据的内在关系,lmplot可以简单通过指定x,y,data绘制
# 绘制整体数据的回归图
sns.lmplot(x='x',y='y',data=df)
# 使用分面绘图,根据dataset分面
sns.lmplot(x="x", y="y", col="dataset", hue="dataset", data=df,
col_wrap=2, ci=None)
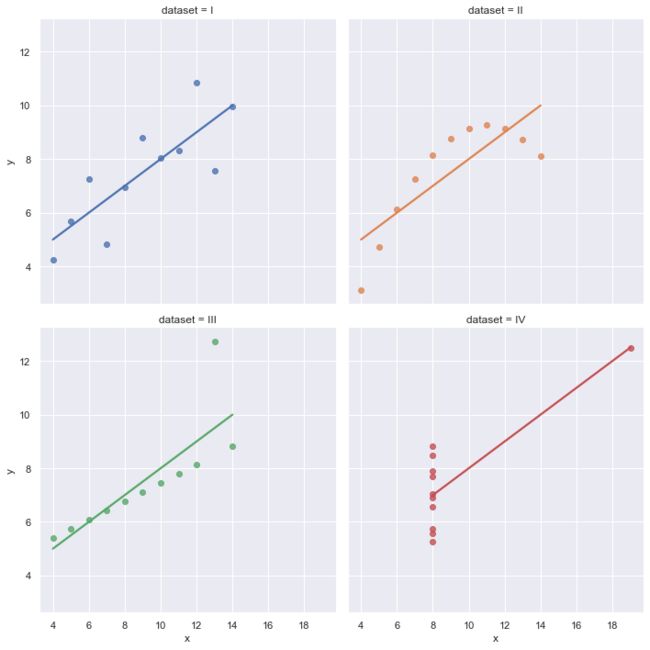
上面显示了每一张图内画一个回归线,下面我们来看如何在一张图中画多个回归线
# 加载鸢尾花数据集
iris = sns.load_dataset("iris")
g = sns.lmplot(x="sepal_length", y="sepal_width", hue="species",
truncate=True, height=5, data=iris)
# 使用truncate参数
# 设置坐标轴标签
g.set_axis_labels("Sepal length (mm)", "Sepal width (mm)")
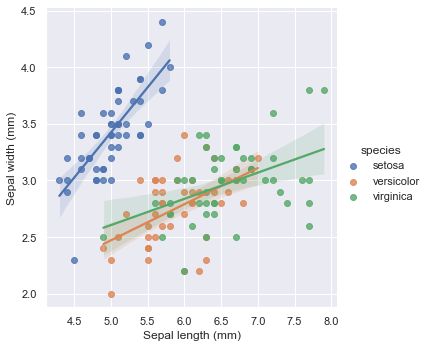
可以看出setosa类型的鸢尾花主要集中在左侧,下面我们再来看一下怎么绘制logistic回归曲线
# 加载 titanic dataset
df = sns.load_dataset("titanic")
# 显示不同性别年龄和是否存活的关系
g = sns.lmplot(x="age", y="survived", col="sex", hue="sex", data=df,
y_jitter=.02, logistic=True)
g.set(xlim=(0, 80), ylim=(-.05, 1.05))
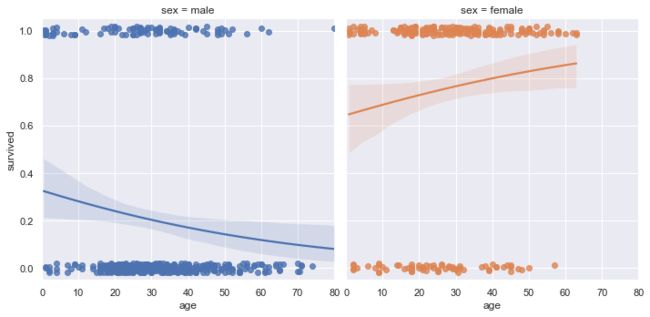
虽然仅仅使用一个变量来拟合logistic回归效果不好,但是为了方便演示,我们暂且这样做,从logistic回归曲线来看,男性随着年龄增长,存活率下降,而女性随着年龄上升,存活率上升
4.2 residplot(残差图)
线性回归残差图
绘制现象回归得到的残差回归图
sns.set(style="whitegrid")
# 模拟y对x的回归数据集
rs = np.random.RandomState(7)
x = rs.normal(2, 1, 75)
y = 2 + 1.5 * x + rs.normal(0, 2, 75)
# 绘制残差数据集,并拟合曲线
sns.residplot(x, y, lowess=True, color="g")
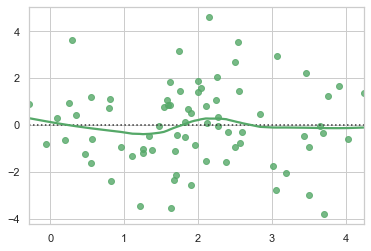
从结果来看,回归结果较好,这是因为我们的数据就是通过回归的形式生成的
5.矩阵图
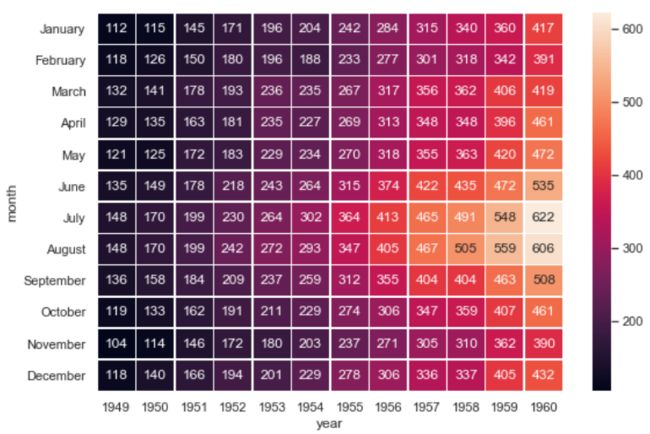
5.1 heatmap(热力图)
常见的我们使用热力图可以看数据表中多个变量间的相似度
# 加载数据
flights_long = sns.load_dataset("flights")
# 绘制不同年份不同月份的乘客数量
flights = flights_long.pivot("month", "year", "passengers")
# 绘制热力图,并且在每个单元中添加一个数字
f, ax = plt.subplots(figsize=(9, 6))
sns.heatmap(flights, annot=True, fmt="d", linewidths=.5, ax=ax)
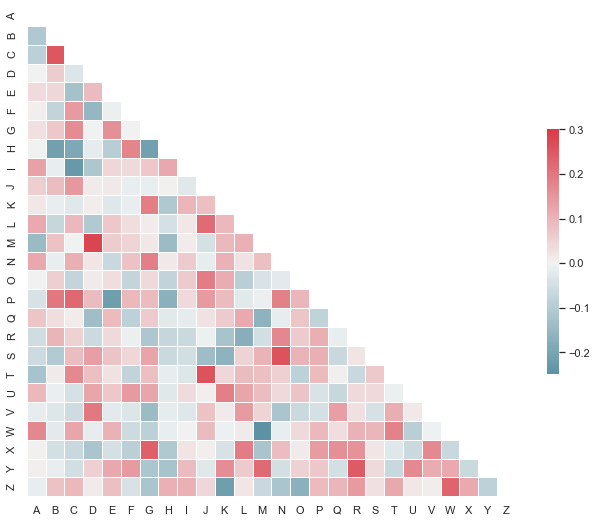
绘制相关系数矩阵,绘制26个英文字母之间的相关系数矩阵
from string import ascii_letters
sns.set(style="white")
# 随机数据集
rs = np.random.RandomState(33)
d = pd.DataFrame(data=rs.normal(size=(100, 26)),
columns=list(ascii_letters[26:]))
# 计算相关系数
corr = d.corr()
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# 设置图形大小
f, ax = plt.subplots(figsize=(11, 9))
# 生成自定义颜色
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# 绘制热力图
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5})
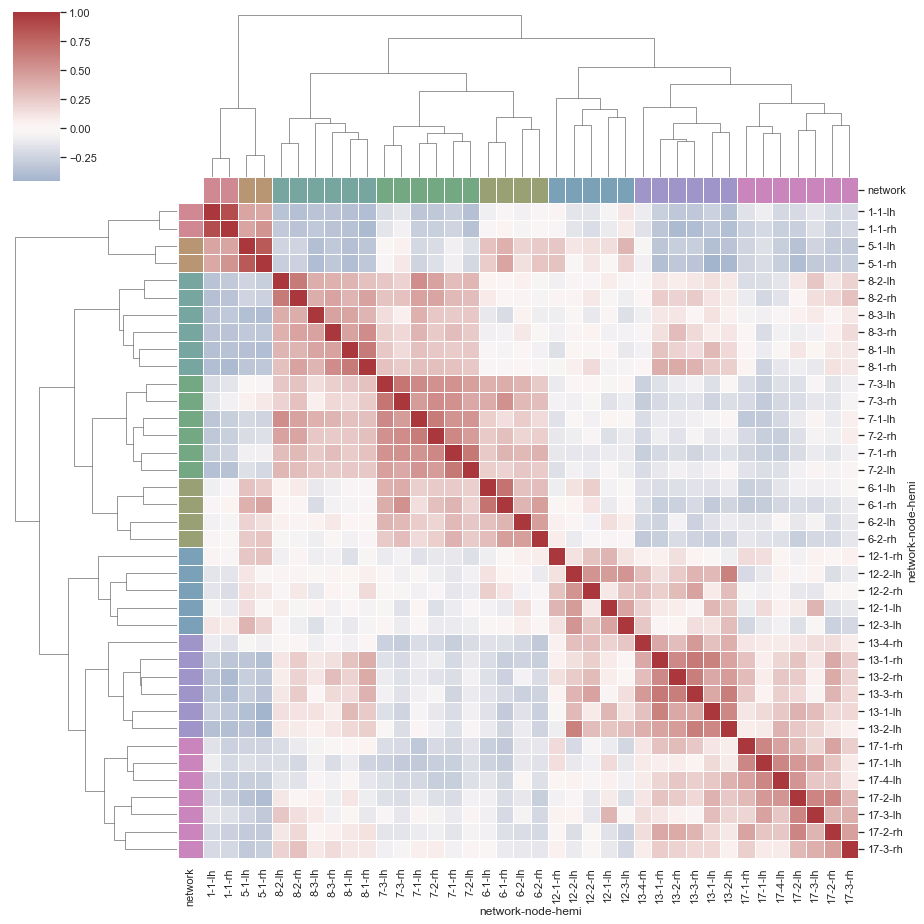
5.2 clustermap聚类图
sns.set()
# 加载大脑网络示例数据集
df = sns.load_dataset("brain_networks", header=[0, 1, 2], index_col=0)
# 选择网络的子集
used_networks = [1, 5, 6, 7, 8, 12, 13, 17]
used_columns = (df.columns.get_level_values("network")
.astype(int)
.isin(used_networks))
df = df.loc[:, used_columns]
# 创建一个分类调色板来识别网络
network_pal = sns.husl_palette(8, s=.45)
network_lut = dict(zip(map(str, used_networks), network_pal))
# 将调色板转换为将在矩阵侧面绘制的向量
networks = df.columns.get_level_values("network")
network_colors = pd.Series(networks, index=df.columns).map(network_lut)
# 画出完整的聚类图
sns.clustermap(df.corr(), center=0, cmap="vlag",
row_colors=network_colors, col_colors=network_colors,
linewidths=.75, figsize=(13, 13))
✏️6.FacetGrid绘制多个图表
是一个绘制多个图表(以网格形式显示)的接口。
步骤:
- 1、实例化对象
- 2、map,映射到具体的 seaborn 图表类型
- 3、添加图例
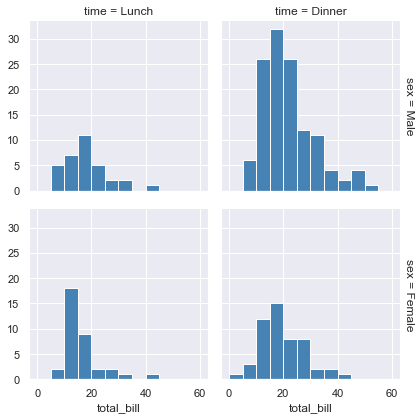
✒️6.1 绘制多个直方图
sns.set(style="darkgrid")
tips = sns.load_dataset("tips")
g = sns.FacetGrid(tips, row="sex", col="time", margin_titles=True)
bins = np.linspace(0, 60, 13)
g.map(plt.hist, "total_bill", color="steelblue", bins=bins)
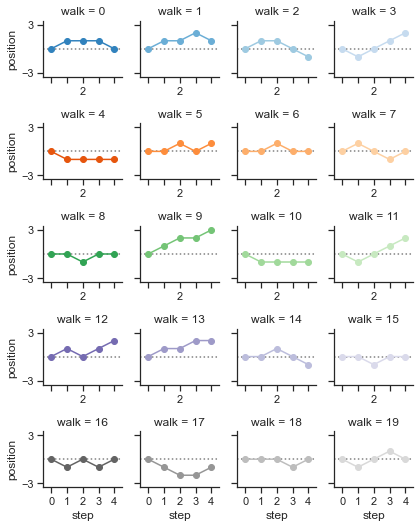
️6.2 绘制多个折线图
sns.set(style="ticks")
# 创建一个包含许多短随机游动的数据集
rs = np.random.RandomState(4)
pos = rs.randint(-1, 2, (20, 5)).cumsum(axis=1)
pos -= pos[:, 0, np.newaxis]
step = np.tile(range(5), 20)
walk = np.repeat(range(20), 5)
df = pd.DataFrame(np.c_[pos.flat, step, walk],
columns=["position", "step", "walk"])
# 为每一次行走初始化一个带有轴的网格
grid = sns.FacetGrid(df, col="walk", hue="walk", palette="tab20c",
col_wrap=4, height=1.5)
# 画一条水平线以显示起点
grid.map(plt.axhline, y=0, ls=":", c=".5")
# 画一个直线图来显示每个随机行走的轨迹
grid.map(plt.plot, "step", "position", marker="o")
# 调整刻度位置和标签
grid.set(xticks=np.arange(5), yticks=[-3, 3],
xlim=(-.5, 4.5), ylim=(-3.5, 3.5))
# 调整图形的布局
grid.fig.tight_layout(w_pad=1)
题外话

感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
若有侵权,请联系删除