Pyhton - 数据分析之pandas模块一览总表
http://pandas.pydata.org/docs/user_guide/10min.html
https://www.runoob.com/pandas/pandas-tutorial.html
https://geek-docs.com/pandas/pandas-tutorials/pandas-tutorial.html
分组Groupby用法详解:https://zhuanlan.zhihu.com/p/101284491
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。pandas 这个名称来源于panel data(面板数据),从而可见其要处理的数据是多维度的而非单维度。
- pandas 含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具。经常是和其他工具一起使用,如数值计算工具NumPy和SciPy,分析库statsmodels与scikit-learn,以及数据可视化库matplotlib。
- 可以读取较多类型的文件格式,从简单的txt、csv、json到excel,hdf5、pickle再到sas、sql、stata等等文件格式都有得以支持。
- 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas和Numpy的区别:
- Numpy是以矩阵为基础的数学计算模块,是数值计算的扩展包。
- Pandas主要做数据处理,提供了DataFrame的数据结构,契合统计分析的表结构,可用Numpy或其他方式进行计算。
- NumPy是构建pandas的基础,后者大量借鉴了NumPy编码风格。
安装: pip install pandas
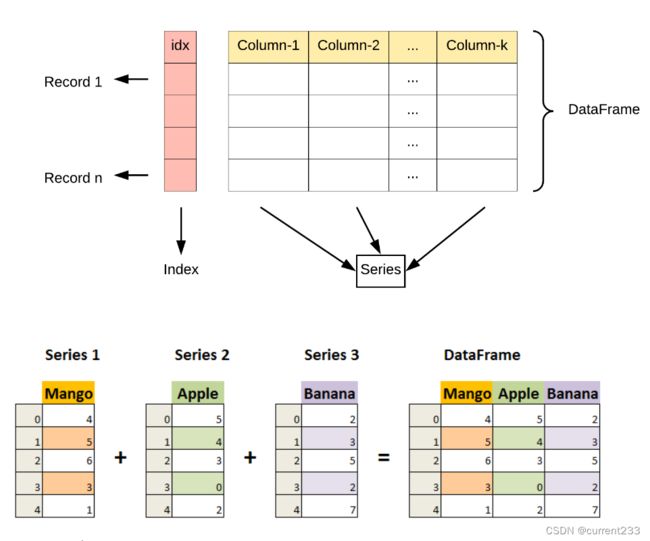
一、数据结构组成
Pandas包含以下三个数据结构:系列(Series),数据帧(DataFrame),面板(Panel)。
- Series:一维数组,序列,大小不可变,由同种数据类型元素组成。类似于python中的列表和Numpy中的Ndarray对象。在 Series 中包含的数据类型可以是整数,浮点数,字符串,python对象等。
同种类型数据构成,大小不可变,数据可变。 - DataFrame: 二维数组,大小可变的表格结构,它含有一组有序的列,每列可以是不同的数据类型(整型、字符串、
布尔值等)。使用表格数据(DataFrame),在语义上只需要考虑行和列,而不是轴0和轴1。DataFrame既有行索引,也有列索引,它可以看作是Series组成的字典,不过这些Series共用一个索引。DataFrame是Series的容器。
可以由不同的数据类型构成,大小可变,数据可变。含行索引和列索引,可以对行和列执行算术运算 - Panel:三维数组。Panel是DataFrame的容器。
可以由不同的数据类型构成,大小可变,数据可变。
Panel 相当于一个存储 DataFrame 的字典,3个轴(axis)分别代表意义如下:
axis 0:items item 对应一个内部的数据帧(DataFrame)
axis 1:major_axis 每个数据帧(DataFrame)的索引行
axis 2:minor_axis 每个数据帧(DataFrame)的索引列
二、数据基本操作
1. 创建数据结构
| 函数 | 说明 |
|---|---|
| pandas.Series( data, index, dtype, name, copy) | 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。Series 由索引(index)和列组成。如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据。【data一组数据(支持多种数据类型,如ndarray,list,constants 类型)。index数据索引标签,索引值必须是唯一的,与data的长度相同,默认为np.arange(n),其中n是数组长度,即[0,1,2,3…. range(len(array))-1] - 1],从 0 开始。dtype数据类型,默认会自己判断。name设置名称。copy拷贝数据,默认为 False。】 |
| pandas.DataFrame( data, index, columns, dtype, copy) | 是一个二维的数组结构,类似二维数组。【data一组数据(ndarray、系列series, map, 列表list, 字典dict 等类型)。index索引值,或者可以称为行标签。columns列标签,默认为 RangeIndex (0, 1, 2, …, n) 。dtype数据类型。copy拷贝数据,默认为 False。】 |
| pandas.Panel(data, items, major_axis, minor_axis, dtype, copy) | 创建 Panel。【data 支持多种数据类型,如ndarray,series,map,lists,dict,constant和其他数据帧(DataFrame)。items即axis=0。major_axis即axis=1。minor_axis即axis=2。dtype每列的数据类型。copy是否复制数据,默认为false。】 |
| pandas.date_range(start=None, end=None, periods=None, freq=‘D’, tz=None, normalize=False, name=None, closed=None, **kwargs) | 生成日期范围。【start开始时间。end结束时间。periods偏移量。freq频率,默认天,pd.date_range()默认频率为日历日,pd.bdate_range()默认频率为工作日。tz时区。name索引对象名称。normalize时间参数值正则化到午夜时间戳(这里最后就直接变成0:00:00,并不是15:30:00)。closed默认为None的情况下,左闭右闭,left则左闭右开,right则左开右闭。】pd.date_range(end=‘1/30/2017 15:00:00’, periods=10) # 增加了时、分、秒 |
2. 数据结构的属性和方法
| 属性或方法 | 描述 |
|---|---|
| df.axes | 返回 Series 索引列表。返回DataFrame行轴标签和列轴标签列表。 |
| df.dtypes | 返回 Series 数据类型。返回DataFrame每列的数据类型。 |
| df.empty | 返回布尔值,表示对象是否为空, 返回True表示对象为空。 |
| df.ndim | 返回对象的维数。根据定义,一个Series是一个一维数据结构,DataFrame是一个2D对象。 |
| df.size | 返回Series基础数据中的元素个数。返回 DataFrame 中的元素个数。 |
| df.values | 以ndarray形式返回 Series 中的实际数据值。将DataFrame中的实际数据作为NDarray返回。 |
| df.T | 返回DataFrame的转置,行和列将交换。 |
| df.shape | 返回表示DataFrame的维度的元组。 元组(a,b),其中a表示行数,b表示列数。 |
3. 读取/添加/删除
Pandas 索引和选择数据,Python和NumPy索引运算符"[]“和属性运算符”."可以快速轻松地访问Pandas数据结构。由于要访问的数据类型不是预先知道的,直接使用标准运算符具有一些限制。
| 索引 | 描述 |
|---|---|
| df.loc[index_name, col_name] | 按标签的行列交叉选取。基于标签(label),包括行标签(index)和列标签(colums),即行名称和列名称,可以使用def.loc[index_name, col_name]选择指定位置的数据。【单个标量标签,df.loc['a']选择的是 index 为’a’的一行。标签列表,df.loc[['a', 'b', 'c']]只选择行。切片对象,在最终选择的数据数据中包含切片的 start 和 stop,df.loc['c' : 'h'] 即包含’c’行,也包含’h’行。布尔数组,用于筛选符合某些条件的行,可以使用 list, array, 也可以使用Series(使用Series时 index需要一致,否则会报 IndexError),df.loc[df.A>0.5] 筛选出所有’A’列大于0.5的行。】# df.loc[lambda df:[0,1]] 选择前两行 |
| df.iloc() | 按位置序号的行列交叉选取。基于整数的索引,利用元素在各个轴上的索引序号进行选择,序号超过范围产生IndexError,切片时允许序号超过范围。【整数,与.loc相同,如果只使用一个维度则对行选择,小标从 0 开始,df.iloc[5]选择第 6 行。整数列表或者数组,df.iloc[[5, 1, 7]]选择第 6 行, 第 2 行, 第 8 行。元素为整数的切片操作,与.loc不同,这里下标为 stop 的数据不被选择,df.iloc[0:3]只包含 0,1,2行,不包含第 3 行。布尔数组进行筛选, 可以使用 list 或者 array,使用 Series会出错(NotImplementedError 和 ValueError,前者是 Series 的 index 与待切片 DataFrame的index 不同时报错,后置 index 相同时报错),df.iloc[np.array(df.A>0.5)],df.iloc[list(df.A>0.5)]。】# df.iloc[lambda df:[0,1]] 选择前两行 |
| df.ix() | 基于标签和整数,进行选择和子集化对象的混合方法。在0.20.0中已经不建议使用了。 |
| df[] | 快捷的整行整列选取。【df[标签列表],选取多个整列。df[切片],选取整行(切片操作,选择的是列,并且必须使用列名。只能输入一个维度,不能用逗号隔开输入两个维度。)】# df[‘A’] |
| 运算符. | 属性访问,可以使用属性运算符.来选择列。# df.A |
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
# 读取
print (df['one']) # 从数据帧(DataFrame)中读取一列。
print (df.loc['b']) # 读取行,通过将行索引传递给loc()函数来选择行
print (df.iloc[1]) # 读取行,通过将整数位置传递给iloc()函数来选择行
print (df[2:4]) # 按行切片选择,使用:运算符选择多行
# 添加
df['three']=pd.Series([10,20,30],index=['a','b','c']) # 向一个 DataFrame 中添加一个新列
df['four']=df['one']+df['three'] # 向一个 DataFrame 中添加一个新列
df = df.append(df2) # 将新行添加到 DataFrame
print(df)
# 删除
del df['three'] # 删除列
df.pop('four') # 弹出一列(删除列)
df = df.drop('a') # 删除行。 如果标签重复,则会删除多行。
print(df)
4. 选项和自定义操作
Series,DatFrames和Panel都有pct_change()函数
| 函数 | 说明 |
|---|---|
| pandas.get_option(param) | 获取解释器的默认参数值。【param参数:display.max_rows获取显示上限的行,默认配置参数值是60。display.max_columns获取显示上限的列,默认配置参数值是20。】# pd.get_option(“display.max_rows”) |
| pandas.set_option(param, value) | 设置解释器的默认参数值。【display.max_rows设置要显示的默认行数(避免只显示部分行数据)。display.max_columns设置要显示的默认列数(避免列显示不全)。display.max_colwidth显示最大列宽(避免属性值或列名显示不全)。display.width 每一行的宽度(避免换行)。display.precision显示十进制数的精度。display.expand_frame_repr显示数据帧以拉伸页面。precision设置显示数值的精度。】# 自定义列宽pd.set_option(“display.max_rows”,80),#只会影响浮点列,而不影响整数列,设置字段小数位精度一致pd.set_option(“display.float_format”, “{:.2f}”.format) |
| pandas.set_printoptions(linewidth=100, suppress=True) | 打印numpy时设置显示宽度,并且不用科学计数法显示。 |
| pandas.reset_option(param) | 解释器的参数重置为默认值。# pd.get_option(“display.max_rows”) |
| pandas.describe_option(param) | 打印参数的描述。 |
| pandas.option_context() | 临时设置解释器的参数,退出使用块时,恢复为默认值。# with pd.option_context(“display.max_rows”,10): |
5. Series对象的字符串和文本数据s.str
Pandas提供了一组字符串函数,可以方便地对字符串数据进行操作。 最重要的是,这些函数忽略了NaN值。几乎这些方法都使用Python 字符串函数。因此,将Series对象转换为String对象,然后执行该操作。
| 函数 | 描述 |
|---|---|
| s.str.lower() | 将Series/Index中的字符串转换为小写。 |
| s.str.upper() | 将Series/Index中的字符串转换为大写。 |
| s.str.len() | 计算字符串长度。 |
| s.str.strip() | 帮助从两侧的系列/索引中的每个字符串中删除空格(包括换行符)。 |
| s.str.split(pattern) | 用给定的模式拆分每个字符串。# s.str.split(’ ') |
| s.str.cat(sep=pattern) | 使用给定的分隔符连接系列/索引元素。# s.str.cat(sep=’ ') |
| s.str.get_dummies() | 返回具有单热编码值的数据帧(DataFrame)。 |
| s.str.contains(pattern) | 如果元素中包含子字符串,则返回每个元素的布尔值True,否则为False。#s.str.contains(’ ')包含空格返回True |
| s.str.replace(a,b) | 将值a替换为值b。 |
| s.str.repeat(value) | 重复每个元素指定的次数value。 |
| s.str.count(pattern) | 返回模式中每个元素pattern的出现总数。 |
| s.str.startswith(pattern) | 如果系列/索引中的元素以模式开始,则返回true。 |
| s.str.endswith(pattern) | 如果系列/索引中的元素以模式结束,则返回true。 |
| s.str.find(pattern) | 返回模式第一次出现的位置。-1表示元素中没有这样的模式可用。 |
| s.str.findall(pattern) | 返回模式的所有出现的列表。空列表([])表示元素中没有这样的模式可用。 |
| s.str.swapcase | 变换字母大小写。 |
| s.str.islower() | 检查系列/索引中每个字符串中的所有字符是否小写,返回布尔值。 |
| s.str.isupper() | 检查系列/索引中每个字符串中的所有字符是否大写,返回布尔值。 |
| s.str.isnumeric() | 检查系列/索引中每个字符串中的所有字符是否为数字,返回布尔值。 |
6. 描述性统计函数
Pandas 描述性统计,有很多方法用来计算DataFrame的描述性统计信息和其他相关操作。 其中大多数是sum(),mean()等聚合函数,但其中一些,如sumsum(),产生一个相同大小的对象。 一般来说,这些方法采用轴参数,就像ndarray.{sum,std,…},但轴可以通过名称或整数来指定。
- DataFrame – “index”(axis=0,default),”columns”(axis=1)
| 函数 | 说明 |
|---|---|
| len(df) | 统计行数。# print(len(df))不包括表头(列标签) |
df.count() |
返回每列的计数(计数仅包括非空值的数量) |
| df.sum(axis) | 返回所请求轴的值的总和,默认情况下axis=0。 |
df.mean() |
返回每列的平均值 |
df.std() |
返回数值列的Bressel标准偏差 |
| df.describe( include) | 计算有关 DataFrame 列的统计信息的摘要。该函数给出了平均值,标准差和IQR值。 而且,函数排除字符列,并给出关于数字列的摘要。【 include是用于传递关于什么列需要考虑用于总结的必要信息的参数,获取值列表,默认情况下是number汇总数字列(数字值),object 汇总字符串列,all 将所有列汇总在一起(不应将其作为列表值传递)。】 |
| df.head(n) | 返回前n行(观察索引值)。默认数量为5,可以传递自定义数值。 |
| df.tail(n) | 返回最后n行(观察索引值)。默认数量为5,可以传递自定义数值。 |
| df.median() | 返回每列的中位数 |
| df.mode() | 值的模值, 众数 |
df.min() |
所有值中的最小值 |
df.max() |
所有值中的最大值 |
| df.abs() | 绝对值 |
| df.prod() | 数组元素的乘积 |
| df.cumsum() | 累计总和 |
| df.cumprod() | 累计乘积。sum(),cumsum()函数能与数字和字符(或)字符串数据元素一起工作,不会产生任何错误。字符聚合从来都比较少被使用,虽然这些函数不会引发任何异常。由于这样的操作无法执行,因此,当DataFrame包含字符或字符串数据时,像abs(),cumprod()这样的函数会抛出异常。 |
| df.mad() | 平均绝对方差 |
| df.cummax() | 累计最大值 |
| df.cummin() | 累计最小值 |
| df.var() | 方差 |
| df.sem() | 标准误差 |
| df.skew() | 偏差 |
| df.kurt() | 样本值峰度 |
| df.quantile() | 分位数 |
| df[‘lable’].nunique() | 统计有多少种不同的值 |
| df[‘lable’].value_counts() | 对 列 中每种不同的值 进行计数。【返回的结果以 Series(系列) 的形式表示,其中包括数值和它的计数值。这个 Series 对象拥有叫做 index 的属性,包含了每个不同数值,可以用 index.tolist() 获取所有数值。而每个数值出现的计数值则是 Series 对象中的数值部分,可以通过 tolist() 函数将其转换为一个列表对象。】# value_counts_result = data[‘column_name’].value_counts(),result_df = pd.DataFrame({‘value’: value_counts_result.index.tolist(), ‘count’: value_counts_result.tolist()}) |
| df.isin() | 判断某个值是否在数据中出现过。#data.isin([2, 4]判断了数据中是否包含了2和4两个值 |
| df.pct_change(axis) | Series,DatFrames和Panel都有,计算百分数变化,将每个元素与其前一个元素进行比较,并计算变化百分比。【axis默认情况下0对列进行操作,1对行进行操作。】 |
| df.cov() | 协方差。Series对象时计算序列对象之间的协方差,NA将被自动排除。当应用于DataFrame时计算所有列之间的协方差(cov)值。# frame[‘a’].cov(frame[‘b’]),frame.cov()第一个语句中a和b列之间的cov结果值,与由DataFrame上的cov返回的值相同。 |
| df.corr(method) | 相关系数。显示了任何两个数值(Series)之间的线性关系。【method方法来计算pearson(默认),spearman和kendall之间的相关性。】#frame[‘a’].corr(frame[‘b’]),frame.corr()如果DataFrame中存在任何非数字列,则会自动排除。 |
| s.rank(ascending) | 数据排名,为元素数组中的每个元素生成排名,在相同的情况下,分配平均等级。【ascending默认为true的升序参数,当设置为false时数据按照降序排序。tie-breaking方法:average 默认值,相同数据分配平均数;min相同数据分配最小等级;max相同数据分配最大等级;first 相同数据根据出现在数组的顺序分配等级。】 |
| pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=‘raise’, ordered=True) | 将数值数据转换为分类数据。将数据均匀划分成n等份,每份的间距相等,返回的是一个特殊的Categorical对象,一组表示面元名称的字符串。等宽法即是将属性值分为具有相同宽度的区间,区间的个数k根据实际情况来决定,比如属性值在[0,60]之间,最小值为0,最大值为60,我们要将其分为3等分,则区间被划分为[0,20] 、[21,40] 、[41,60],每个属性值对应属于它的那个区间。【x要传入和切分的一维数组,需要离散化的数组、Series、DataFrame对象。bins分组数据,输入整数(x宽度范围内的等宽面元数量,x的范围在每个边上被延长1%,以保证包括x的最小值或最大值)、序列尺度(允许非均匀bin宽度的bin边缘,在这种情况下没有x的范围的扩展)、或间隔索引。right为True时表示分组区间是包含右边,不包含左边即(], False代表[)分组左边闭合。labels标签参数,表示分组的自定义标签,必须与结果箱相同长度,如果FALSE只返回整数指标面元。retbins是否返回面元,为True返回用浮点数填充的N维数组(bin的具体范围值),当bins是单个数值时很有用(因为bin是数字的话, 划分组具体数值我们是不知道的)。precision返回面元的小数点几位,存储和显示 bin 标签的精度,整数默认为3。include_lowest第一个区间是否应该是左包含的。duplicates如果bin列表里有重复,raise报错/drop直接删除至保留一个。ordered标签是否有序,适用于返回的类型 Categorical 和 Series(使用 Categorical dtype),为 True则将对生成的分类进行排序,为 False则生成的分类将是无序的(必须提供标签)。】按值切割,即根据数据值的大小范围等分成n组,落入这个范围的分别进入到该组。 |
| pandas.qcut(x, q, labels=None, retbins=False, precision=3, duplicates=’raise’) | 以相同数量的记录放进每个区间,是按照分位数对样本进行划分的,这样划分的结果是的每个区间的大小基本相同,但不一定完全相同,例如把a列分成4等份,就是按照四分位数划分的。等频法即是将属性值分为具有相同宽度的区间,区间的个数k根据实际情况来决定。比如有60个样本,我们要将其分为k=3部分,则每部分的长度为20个样本。【x要进行分组的数据,数据类型为一维数组,或Series对象。q整数或分位数组成的数组,即要将数据分成几组。labels可以理解为组标签,这里注意标签个数要和组数相等。】等频切割,即基本保证每个组里的元素个数是相等的。 |
| DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True) | 分组操作包括拆分对象、应用函数和组合结果的一些组合。这可以用于对大量数据进行分组,并对这些组进行计算操作。将数据根据某个(多个)字段划分为不同的群体(group)进行分析。#数据集按照score字段进行划分/分组,得到一个DataFrameGroupBy对象grouped=df.groupby('score').groups。#根据对应组的数据值,选择一个组grouped.get_group(91)。#通过 agg() 函数可以对分组对象应用多个聚合函数grouped['score'].agg([np.size,np.mean,np.std]),grouped[‘score’].agg({‘salary’:‘median’,‘age’:‘mean’})。#对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果data['avg_salary'] = data.groupby('company')['salary'].transform('mean')。#虽然说apply拥有更大的灵活性,但apply的运行效率会比agg和transform更慢oldest_staff = data.groupby('company',as_index=False).apply(get_oldest_staff) |
| DataFrame.drop_duplicates(subset=[‘comment’], keep=‘first’, inplace=True) | 根据某列去重。【subset列表的形式填写要进行去重的列名,默认为 None 表示根据所有列进行。keepfirst可选参数:默认值 first保留第一次出现的重复行,删除后面的重复行; last删除重复项,保留最后一次出现;False 删除所有重复项。inplace默认为 False 删除重复项后返回副本,True直接在原数据上删除重复项。】#df.drop_duplicates(subset=[‘comment’], keep=‘first’, inplace=True) |
| df.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=‘’) | 重置索引。【drop重新设置索引后是否将原索引作为新的一列并入DataFrame,默认为False。inplace是否在原DataFrame上改动,默认为False。level如果索引(index)有多个列,仅从索引中删除level指定的列,默认删除所有列。col_level如果列名(columns)有多个级别,决定被删除的索引将插入哪个级别,默认插入第一级。col_fill如果列名(columns)有多个级别,决定其他级别如何命名】 |
| pd.concat(objs, axis=0, join=‘outer’, ignore_index=False, keys=None, levels=None, names=None, sort=False, verify_integrity=False, copy=True) | 实现纵向和横向连接合并,将数据连接后会形成一个新对象(Series或DataFrame)。【objs需要连接的数据,可以是多个DataFrame或者Series,它是必传参数。axis连接轴的方法,默认值为0,即按行连接,追加在行后面;值为1时追加到列后面(按列连接:axis=1)。join合并方式,其他轴上的数据是按交集(inner)还是并集(outer)进行合并。ignore_index是否保留原来的索引。keys连接关系,使用传递的键作为最外层级别来构造层次结构索引,就是给每个表指定一个一级索引。names索引的名称,包括多层索引。verify_integrity是否检测内容重复,参数为True时,如果合并的数据与原数据包含索引相同的行,则会报错。copy如果为False,则不要深拷贝。】 |
判断是否存在指定列名的数据
if 'A' in df:
if 'A' in df.columns:
if {'A', 'C'}.issubset(df.columns):
if set(['A','C']).issubset(df.columns):
7. 缺失值处理 - 数据清洗
数据清洗是对一些没有用的数据进行处理的过程。
- 很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要对使数据分析更加准确,就需要对这些没有用的数据进行处理。
- 在计算各种描述性统计量时,其实并没有考虑NaN值(缺失值)。
- 四种空数据:n/a,NA,—,na
| 函数 | 说明 |
|---|---|
| numpy.NaN 或 numpy.nan | 为数据结构中的元素赋值为NaN。#ser = pd.Series([0, 1, 2, np.NaN, 9], index=[‘red’, ‘blue’, ‘yellow’, ‘white’, ‘green’]),ser[‘white’] = None |
| DataFrame.dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False) | 清洗空值,去除NaN的方式。DataFrame对象使用时,只要行或列有一个NaN元素,该行或列的全部元素都会被删除。【axis默认为 0逢空值剔除整行,axis=1 表示逢空值去掉整列。how默认为 ‘any’ 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。thresh设置需要多少非空值的数据才可以保留下来的。subset设置想要检查的列,如果是多个列,可以使用列名的 list 作为参数。inplace默认返回一个新的 DataFrame不会修改源数据,如果设置True将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。】 |
| df[‘A’].isnull() | 判断各个单元格是否为空。 |
| df.fillna() | 替换一些空字段。# df.fillna(12345, inplace = True)使用 12345 替换空字段,df[‘PID’].fillna(12345, inplace = True)使用 12345 替换 PID 为空数据 |
| ser.notnull() | 作为选取元素的条件,实现直接过滤。#ser[ser.notnull()] |
| df.fillna() | 用以替换NaN的元素作为参数,所有NaN可以替换为同一个元素。若要将不同列的NaN替换为不同的元素,依次指定列名称及要替换成的元素即可。#df.fillna(0),df.fillna({‘ball’:1,‘mug’:0,‘pen’:99}) |
8. DataFrame函数应用
使用适当的方法取决于函数是否期望在整个DataFrame行或列或元素上进行操作。
| 函数 | 说明 |
|---|---|
| df.pipe() | 函数应用,表式函数应用。可以通过将函数和适当数量的参数作为管道参数来执行自定义操作,从而对整个DataFrame执行操作。 |
| df.apply() | 行列函数应用。沿DataFrame或Panel的轴应用任意函数,它与描述性统计方法一样,apply()方法使用一个可选的axis参数。 |
| df.applymap() | 元素函数应用。和Series上的map()类似,接受任何Python函数,该函数要求能够接受单个值并返回单个值。 |
| df2.reindex_like(df1,method,limit) | 重新索引(Reindexing)会更改DataFrame的行标签和列标签,意味着符合数据以匹配特定轴上的一组给定的标签。【df2数据帧(DataFrame)被更改并重新编号成df1, 列名称应该匹配,否则将为整个列标签添加NAN。method填充方法,pad/ffill向前填充值;bfill/backfill 向后填充值;nearest 从最近的索引值填充。limit填充限制,限制参数在重建索引时提供对填充的额外控制,限制指定连续匹配的最大计数。】可以通过索引来实现多个操作:重新排序现有数据以匹配一组新的标签。在没有标签数据的标签位置插入缺失值(NA)标记。 |
| df1.rename() | 允许基于一些映射(字典或者Series)或任意函数来重新标记一个轴。提供了一个inplace命名参数,默认为False并复制底层数据, 指定传递inplace = True则表示将数据重命名。 |
| 迭代 | 迭代Series 提供值。DataFrame 提供列名/列标签。Pannel 提供项目标签。 |
| df.iteritems() | 迭代(key,value)对,将每个列作为键,将值与值作为键和列值迭代为Series对象。 |
| df.iterrows() | 将行迭代为(索引,系列)对,产生每个索引值以及包含每行数据的序列。由于iterrows()遍历行,因此不会跨该行保留数据类型。 |
| df.itertuples() | 以namedtuples的形式迭代行,将为DataFrame中的每一行返回一个产生一个命名元组的迭代器。元组的第一个元素将是行的相应索引值,而剩余的值是行值。不要尝试在迭代时修改任何对象。迭代是用于读取,迭代器返回原始对象(视图)的副本,因此更改将不会反映在原始对象上。 |
| df.sort_index(ascending) | 排序,通过传递axis参数和排序顺序,可以对DataFrame进行排序, 默认情况下,按照升序对行标签进行排序。【axis按标签排序(行排序和列排序), 默认情况下0逐行排列,1对列标签进行排序。ascending升序参数,布尔值可以控制排序顺序。 】 |
| df.sort_values(by,kind) | 按值排序的方法。【by指定需要列值,将使用要与其排序值的DataFrame的列名称。kind选择算法的一个配置,提供了mergeesort,heapsort和quicksort。Mergesort是唯一稳定的算法。】#df =df.sort_values(by=‘col1’) ,col1值被排序,相应的col2值和行索引将随col1一起改变,因此看起来没有排序。 |
9. DataFrame窗口函数
为了处理数字数据,Pandas提供了几种窗口函数,如移动窗口函数(rolling()),扩展窗口函数(expanding()),指数加权滑动(ewm()),并可以在其上调用适合的统计函数,如总和,均值,中位数,方差,协方差,相关性等。
- 为了提升数据的准确性,将某个点的取值扩大到包含这个点的一段区间,用区间来进行判断,这个区间就是窗口。移动窗口就是窗口向一端滑行,默认是从右往左,每次滑行并不是区间整块的滑行,而是一个单位一个单位的滑行。
- 窗口函数主要用于通过平滑曲线来以图形方式查找数据内的趋势。如果日常数据中有很多变化,并且有很多数据点可用,那么采样和绘图就是一种方法,应用窗口计算并在结果上绘制图形是另一种方法。
| 函数 | 说明 |
|---|---|
| df.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None) | 移动窗口函数,此函数可以应用于一系列数据,指定参数window=n,并在其上调用适合的统计函数。【window时间窗的大小,可选参数,有两种形式(int 数值表示计算统计量的观测值的数量即向前几个数据或 offset表示时间窗的大小)。min_periods每个窗口最少包含的观测值数量,小于这个值的窗口结果为NaN,值可以是int,默认None,offset情况下,默认为1。center把窗口的标签设置为居中,布尔型,默认False居右。win_type窗口的类型,截取窗的各种函数,字符串类型,默认为None。on可选参数,对于dataframe而言,指定要计算滚动窗口的列,值为列名。axis对列进行计算(int、字符串,默认为0)。closed定义区间的开闭,支持int类型的window,对于offset类型默认是左开右闭,默认为right,可以根据情况指定为left、both等。】# df.rolling(window=3).mean()设置的窗口window=3,也就是3个数取一个均值。index0, index1 为NaN,是因为它们前面都不够3个数,等到index2 的时候,它的值计算方式为(index0+index1+index2)/3,index3 的值就是(index1+index2+index3)/3,第n个元素的值将是n,n-1和n-2元素的平均值。 |
| rolling_count() | 计算各个窗口中非NA观测值的数量 |
| rolling_sum() | 计算各个移动窗口中的元素之和 |
| rolling_mean() | 计算各个移动窗口中元素的均值 |
| rolling_median() | 计算各个移动窗口中元素的中位数 |
| rolling_var() | 计算各个移动窗口中元素的方差 |
| rolling_std() | 计算各个移动窗口中元素的标准差 |
| rolling_min() | 计算各个移动窗口中元素的最小值 |
| rolling_max() | 计算各个移动窗口中元素的最大值 |
| rolling_corr() | 计算各个移动窗口中元素的相关系数 |
| rolling_corr_pairwise() | 计算各个移动窗口中配对数据的相关系数 |
| rolling_cov() | 计算各个移动窗口中元素的的协方差 |
| rolling_quantile() | 计算各个移动窗口中元素的分位数 |
| df.expanding(min_periods=1, center=False, axis=0) | 扩展窗口函数,可应用于一系列数据,类似cumsum()函数的累计求和,其优势在于还可以进行更多的聚类计算。 【指定min_periods = n参数并在其上调用适当的统计函数。和.rolling()函数参数用法相同,不同的是,其不是固定窗口长度,其长度是不断的扩大的。】#df.expanding(min_periods=3).mean()设置min_periods=3,也就是至少3个数取一个均值。index0, index1 为NaN,是因为它们前面都不够3个数,等到index2 的时候,它的值计算方式为(index0+index1+index2)/3,index3 的值就是(index0+index1+index2+index3)/3,第n个元素的值将是n,n-1,n-2…’1’这n个元素的平均值。 |
| df.ewm(com=None, span=None, halflife=None, alpha=None, min_periods=0, adjust=True, ignore_na=False, axis=0) | 指数加权滑动函数,可应用于系列数据,指定com,span,halflife参数,并在其上调用适当的统计函数。该函数表示指数加权滑动,使用场景较少。#df.ewm(com=0.5).mean() |
三、数据读取与写入
1. 处理excel表格
有表头和无表头区别
对内容的读取分有表头和无表头两种方式,默认情形下是有表头的方式,即将第一行元素自动置为表头标签,其余内容为数据;当在read_excel()方法中加上header=None参数时是不加表头的方式,即从第一行起,全部内容为数据。读取到的Excel数据均构造成并返回DataFrame表格类型(以下以df表示)。
对有表头的方式,读取时将自动地将第一行元素置为表头向量,同时为除表头外的各行内容加入行索引(从0开始)、各列内容加入列索引(从0开始)。
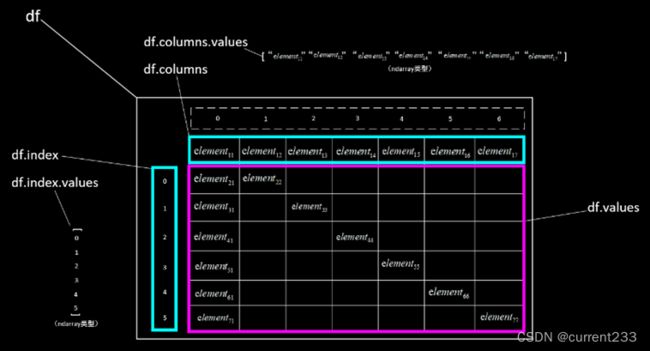
对无表头的方式,读取时将自动地为各行内容加入行索引(从0开始)、为各列内容加入列索引(从0开始),行索引从第一行开始。

pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=None, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, parse_dates=False, date_parser=None, thousands=None, decimal=’.’, comment=None, skipfooter=0, convert_float=None, mangle_dupe_cols=True, storage_options=None)
读取read_excel()
| 主要参数 | 解释 |
|---|---|
| io | 文件路径。 |
| sheet_name (str, int, list, None, default 0) | sheet名称。【str字符串用于引用的’sheet的名称’;int整数用于引用的sheet的索引(从0开始); list字符串或整数组成的列表用于引用特定的sheet; None表示引用所有sheet; default 0默认为0,表示不输入sheet_name的参数下,默认引用第一张sheet的数据】# sheet_name=0读取第1张表格,sheet_name=[‘A1’,1]读取’A1’和第1张表格。 |
| header (int, list of int, default 0) | 指定标题行,默认header=0第一行为标题,可以设置多行如[0,1]为标题行。# hearder=1选择第二行为表头,第一行数据就不要。[1,2,3]选择第2,3,4行的数据作为表头,第二行之上的数据不用。None表示不使用数据源中的表头,即整个表格作为数据读取。header仅为整数就是让这一行称为列标签,如果是列表包含多个整数,含义是这几行都是列标签。 |
| names (array-like, default None) | 自定义表头的名称,需要传递数组参数。在header=None的前提下,补充列名。 |
| index_col(int, list of int, default None) | 指定列为索引列【默认为None,也就是索引为0的列用作DataFrame的行标签。int整数指定第几列为索引列;list of int选择列表中的整数列为索引列。】# index_col=0指定第1列作为索引列。设置多列索引index_col=[0,1]。 |
| usecols(int, str, list-like, or callable default None) | 用于指定读取的列【默认为None,解析所有列。str表示Excel列字母和列范围的逗号分隔列表(例如“ A:E”或“ A,C,E:F”),范围全闭。int表示解析到第几列。int列表表示解析哪几列。】# usecols=[1,3]和[3,1]效果一样,按照表格中的顺序输出。[“职业”,“姓名”]列标签来读取。"C:F"从C列读取至F列。usecols=3,表示解析第0,1,2,3列,共4列。 |
| engine(str, default None) | “xlrd”支持.xls,“openpyxl”支持.xlsx,用于使用第三方的库去解析excel文件。 |
| dtype(Type name or dict of column -> type, default None) | 指定数据列的数据类型。【列的类型名称或字典,默认为None,也就是不改变数据类型。】# dtype={‘年龄’:float16, ‘b’: str }以浮点数的方式读入。每一列的数据类型应该是保持一致的,这样才能和相应的标签呼应。 |
| converters(dict, default None) | 对指定列的数据进行指定函数的处理,传入参数为列名与函数组成的字典。key 可以是列名或者列的序号,values是函数,可以def函数或者直接lambda都行。转换指定列的函数字典{“A”:lambda x: x/100,“B”:lambda x: x/100} |
| skiprows(list like) | 省略指定行数的数据,从第一行开始。# skiprows=1跳过第1行。[1,3,5]跳过第1,3,5行。skiprows=lambda x: x % 2 == 0 跳过偶数行 |
| skipfooter | 省略指定行数的数据,是从尾部数的行开始 |
| true_values(list,default None) | 将指定的文本转换为True,默认为None。# true_values=[‘男’]将性别中的男转换为False |
| false_values(list,default None) | 将指定的文本转换为False,默认为None。 |
| nrows(int, default None) | 默认为None,指定需要读取前多少行,通常用于较大的数据文件中。# nrows=3 读取前三行 |
| na_values(scalar, str, list-like, or dict, default None) | 指定某些列的某些值为NaN。na_values="NaN"一般建议把缺失的值统一设置为"NaN",这样在后面如果需要手动过滤掉缺失值的时候可以索引到位置,如果不设置这个参数,缺失值不是False、0、"NaN"中的任何一个。# na_values=[“n/a”, “na”, “–”],指定[“n/a”, “na”, “–”]为NaN。 |
| keep_default_na(bool, default True) | 表示导入数据时是否导入空值。默认为True,即自动识别空值并导入。 |
2. 处理csv表格
| 函数 | 说明 |
|---|---|
| pd.read_csv(‘nba.csv’) | 读取csv文件。#添加low_memory=False解决警告sys:1: DtypeWarning: Columns(pandas在读取不同块的时候,如果某字段下的数据类型不尽一致,则会出现该警告 。) |
| df.to_string() | 用于返回 DataFrame 类型的数据,如果不使用该函数,则df输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替。 |
| df.head( n ) | 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。 |
| df.tail( n ) | 用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。 |
| df.info() | 返回表格的一些基本信息。non-null 为非空数据。 |
| df.to_csv() | 保存,将 DataFrame 存储为 csv 文件,index=False表示不保存行索引, header=False表示不保存列索引 |