Mit6.824-lab3b-2022
Mit6.824-lab3b-2022
写在前面
个人感觉3b需要做的工作比3a还要简单,只是添加了个server的snapshot,但是由于加入了snapshot所以3a的测试对raft的代码要求又高了一个档次,我基本上所有的精力也都花到对raft部分的debug上了,由于进行apply的chan不能上锁,这里会出现各种乱序的bug,只能说这个地方的设计确实是有点难受了。而且每次十几万行的log信息,找出来错误信息再一点点分析真的头痛,以及client还会反复发送命令,覆写之前的命令等,让log更加困难。不过也怪自己raft写的实在是差强人意,感觉一开始设计的逻辑就不太好,最后只能到处缝缝补补。做到后面真的想干脆重构代码算了。
实验目标
实验要求很简单,给server增加一个snapshot功能,每当raft的log长度到达一个值,就打包一个snapshot并发送snapshot命令给raft,同时当raft发送snapshot时,接收并把自己本地维持的数据替换为snapshot的数据。
这里还是借用一下这位的图,代码在这里
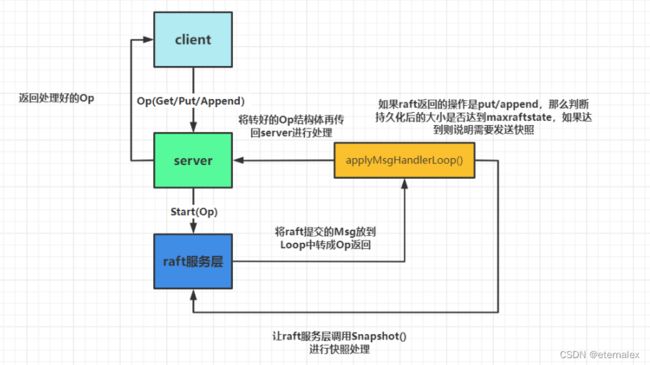
实验内容
读写snapshot
这部分和raft一样,没什么好说的,只需要保持本地数据和每个client发送的最新命令的index即可。
func (kv *KVServer)kvServerSnapShot()[]byte{
w := new(bytes.Buffer)
e :=labgob.NewEncoder(w)
if e.Encode(kv.DB) != nil||
e.Encode(kv.ClientSequence) != nil{
return nil
}
return w.Bytes()
}
func (kv *KVServer)readSnapShot(data []byte){
if len(data) == 0{
return
}
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var db map[string]string
var cs map[int64]applyResult
if d.Decode(&db) !=nil ||
d.Decode(&cs) != nil {
return
}
kv.DB = db
kv.ClientSequence = cs
log.Println(kv.DB,cs,kv.me)
}
snapshot
两个条件之一满足就发送snapshot,raft.Persister的size达到maxraftstate或是log长度达到了一定限度
func (kv *KVServer) snapshot(persister *raft.Persister,snapshotTriger <- chan bool){
if kv.maxraftstate < 0{
return
}
for !kv.killed(){
ratio := float64(persister.RaftStateSize()) / kv.maxraftstate
if ratio > SnapshotThreshold{
kv.mu.Lock()
if data := kv.kvServerSnapShot();data == nil{
}else{
log.Println(kv.DB,kv.me,kv.lastApplied)
kv.rf.Snapshot(kv.lastApplied, data)
}
ratio = 0.0
kv.mu.Unlock()
}
select{
case <- snapshotTriger:
case <-time.After(time.Duration((1-ratio)*SnapshoterCheckInterval) * time.Millisecond):
}
}
}
接收snapshot
读到snapshot说明该raft收到了Leader发送的snapshot并提交了,此时替换自己维护的数据,并清空commandApply
func(kv *KVServer) apply(applyCh <-chan raft.ApplyMsg, lastSnapshoterTriggeredCommandIndex int,snapshotTriger chan<- bool){
var result string
for message := range applyCh{
if message.SnapshotValid{
kv.mu.Lock()
kv.lastApplied = message.SnapshotIndex
kv.readSnapShot(message.Snapshot)
// clear all pending reply channel, to avoid goroutine resource leak
for _, ca := range kv.commandApply {
ca.replyChannel <- applyResult{Err: ErrWrongLeader}
}
kv.commandApply = make(map[int]commandEntry)
kv.mu.Unlock()
continue
}
if !message.CommandValid{
continue
}
if message.CommandIndex - lastSnapshoterTriggeredCommandIndex > SnapshoterAppliedMsgInterval{
select{
case snapshotTriger <- true:
lastSnapshoterTriggeredCommandIndex = message.CommandIndex
default:
}
}
…………
…………
…………
}
}
}
测试
server的代码部分很简单,但是这个lab对raft的要求要比lab2d高得多,所以lab2d写的不好的话很可能需要回去改代码。
需要注意的交互
由于正常apply和接收snapshot后提交都需要放开锁,因而这里可能有多种顺序,假设snapshot提交的index为n,那么snapshot提交前,apply可以提交到大于n的位置,但是snapshot提交后必须从n+1开始提交,因而需要考虑两个锁解开前后代码运行的所有顺序。
需要注意好raft的snapshot(),接收leader的snapshot和自己循环apply其中两两之间可能的交互
几个可能出现的错误与原因。
- get命令发现某一个value值缺了中间一个,如1,2,3,5,6
- 值最后缺了一个,如1,2,3,4 但应该是1,2,3,4,5
这两种情况很可能是接收了snapshot后修改了lastapplied,但是常规apply循环此时并没有结束,因而自增了lastapplied
raft执行snapshot()后是否需要更新lastapplied
我看到有许多人在这里吧lastapplied修改成index,我认为不应该这样做,因为在server发送snapshot后,raft执行snapshot前,很可能进行了其他提交,这时候绝不应该修改,但奇怪的是我这里修改了但是2d仍然可以通过,但是3b不能通过。
修改后的代码在 这里,其实里面有些没用的代码,但是基于能跑就不动的原则,还是不改了。
总结
由于我是用虚拟机做的,不知道什么原因有时候会出些有的没的莫名其妙的错误,包括但不限于速度测试不通过,raft的leadder通过一些不可能的条件访问log超限等。以及log信息真的太多搞得我虚拟机崩溃没法启动只能进root里手动清理磁盘。最后跑测试也可以千次不错,同时lab2也千次通过。