MIT6.824-lab2B-2022篇(万字推导思路及代码构建)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、整体流程思路
- 二、初始化,发送ticker
-
- 2.1、初始化
- 2.2、发送ticker
- 三、进行日志增量的RPC
-
- 3.1、 进行reply构造
- 3.2、处理reply
- 四、Debug
- 五、总结
前言
忙里偷闲总算是把lab2b肝完了…不得不说五月真是最近最忙的一个月。对于lab2b,难度其实确实比lab2a大,甚至是比整个Lab1大的。2b其实是在2a的基础上完成日志增量,但是这个逻辑大体是很好实现的,但是日志增量对应了很多下标是特别容易犯错,且你要保证兼容前几个通过的pass,最终得到allpass。且在某些方面,你要重新回去修改lab2a的代码,重新去查错,这个整个兼容过程是非常痛苦的。具体debug放到后面再谈。
一、整体流程思路
- 首先你要对Lab2b整体的日志增量的测试过程与可视化中演示、亦或者是可视化那样的联系起来,你才可以知道你要实现lab2b的那些事情,并通过lab2b中的各个test。
在paper、可视化的display中,raft这个框架中,首先是client,写入数据到raft框架的leader的日志数组中,然后leader再把这条日志数据,发送各个slave节点。最后等半数的slave都同意更新后,leader再更新返回。这在client看来就是所有的rf节点组成了一个统一的状态机。
那么回到我们lab2b又是怎么建立起联系呢?
- 对于lab2中去看2b的test其实可以可以发现,其实是调用raft中的start函数,对leader节点写入log,然后检测log是否成功其实就是通过applyChan协程一直检测,可以自己多去看看test的源码。然后具体的代码编写、字段其实paper中也提到了,包括一些实现的细节也在figure中有提到。

对于我的start(仅供参考):
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
// Your code here (2B).
if rf.killed() {
return index, term, false
}
rf.mu.Lock()
defer rf.mu.Unlock()
// 如果不是leader,直接返回
if rf.status != Leader {
return index, term, false
}
isLeader = true
// 初始化日志条目。并进行追加
appendLog := LogEntry{Term: rf.currentTerm, Command: command}
rf.logs = append(rf.logs, appendLog)
index = len(rf.logs)
term = rf.currentTerm
return index, term, isLeader
}
二、初始化,发送ticker
2.1、初始化
对于初始化的话的操作,对于lab2a没太大的差别。主要在于多了初始化日志下标数组。
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me
// Your initialization code here (2A, 2B, 2C).
// 对应论文中的初始化
rf.applyChan = applyCh //2B
rf.currentTerm = 0
rf.votedFor = -1
rf.logs = make([]LogEntry, 0)
rf.commitIndex = 0
rf.lastApplied = 0
rf.nextIndex = make([]int, len(peers))
rf.matchIndex = make([]int, len(peers))
rf.status = Follower
rf.overtime = time.Duration(150+rand.Intn(200)) * time.Millisecond // 随机产生150-350ms
rf.timer = time.NewTicker(rf.overtime)
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
//fmt.Printf("[ Make-func-rf(%v) ]: %v\n", rf.me, rf.overtime)
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
2.2、发送ticker
对于2A其实主要多的在于实现发送初始日志包。nextIndex代表的其实是代表下一次发送的日志的index代表哪里,paper中的表格也有体现。因此剪切发送的log也是根据这个来。
func (rf *Raft) ticker() {
for rf.killed() == false {
// Your code here to check if a leader election should
// be started and to randomize sleeping time using
// 当定时器结束进行超时选举
select {
case <-rf.timer.C:
if rf.killed() {
return
}
rf.mu.Lock()
// 根据自身的status进行一次ticker
switch rf.status {
// follower变成竞选者
case Follower:
rf.status = Candidate
fallthrough
case Candidate:
// 初始化自身的任期、并把票投给自己
rf.currentTerm += 1
rf.votedFor = rf.me
votedNums := 1 // 统计自身的票数
// 每轮选举开始时,重新设置选举超时
rf.overtime = time.Duration(150+rand.Intn(200)) * time.Millisecond // 随机产生200-400ms
rf.timer.Reset(rf.overtime)
// 对自身以外的节点进行选举
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
voteArgs := RequestVoteArgs{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: len(rf.logs),
LastLogTerm: 0,
}
if len(rf.logs) > 0 {
voteArgs.LastLogTerm = rf.logs[len(rf.logs)-1].Term
}
voteReply := RequestVoteReply{}
go rf.sendRequestVote(i, &voteArgs, &voteReply, &votedNums)
}
case Leader:
// 进行心跳/日志同步
appendNums := 1 // 对于正确返回的节点数量
rf.timer.Reset(HeartBeatTimeout)
// 构造msg
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
args := AppendEntriesArgs{
Term: rf.currentTerm,
LeaderId: rf.me,
PrevLogIndex: 0,
PrevLogTerm: 0,
Entries: nil,
LeaderCommit: rf.commitIndex, // commitIndex为大多数log所认可的commitIndex
}
reply := AppendEntriesReply{}
// 如果nextIndex[i]长度不等于rf.logs,代表与leader的log entries不一致,需要附带过去
args.Entries = rf.logs[rf.nextIndex[i]-1:]
// 代表已经不是初始值0
if rf.nextIndex[i] > 0 {
args.PrevLogIndex = rf.nextIndex[i] - 1
}
if args.PrevLogIndex > 0 {
//fmt.Println("len(rf.log):", len(rf.logs), "PrevLogIndex):", args.PrevLogIndex, "rf.nextIndex[i]", rf.nextIndex[i])
args.PrevLogTerm = rf.logs[args.PrevLogIndex-1].Term
}
//fmt.Printf("[ ticker(%v) ] : send a election to %v\n", rf.me, i)
go rf.sendAppendEntries(i, &args, &reply, &appendNums)
}
}
rf.mu.Unlock()
}
}
}
三、进行日志增量的RPC
3.1、 进行reply构造
- 对于这一块就是先对个节点先进行写入日志,在发送RPC失败时,应该遵从论文的叙述,不断的进行retries,具体的在5.3节末尾,此处不在赘述。
- 然后在单个节点的RPC中将RPC的返回状态分为如下几个类别:
const (
AppNormal AppendEntriesState = iota // 追加正常
AppOutOfDate // 追加过时
AppKilled // Raft程序终止
AppCommitted // 追加的日志已经提交 (2B
Mismatch // 追加不匹配 (2B
)
对于args、reply的结构体的设置也是根据paper尽可能的还原:
// AppendEntriesArgs 由leader复制log条目,也可以当做是心跳连接,注释中的rf为leader节点
type AppendEntriesArgs struct {
Term int // leader的任期
LeaderId int // leader自身的ID
PrevLogIndex int // 预计要从哪里追加的index,因此每次要比当前的len(logs)多1 args初始化为:rf.nextIndex[i] - 1
PrevLogTerm int // 追加新的日志的任期号(这边传的应该都是当前leader的任期号 args初始化为:rf.currentTerm
Entries []LogEntry // 预计存储的日志(为空时就是心跳连接)
LeaderCommit int // leader的commit index指的是最后一个被大多数机器都复制的日志Index
}
type AppendEntriesReply struct {
Term int // leader的term可能是过时的,此时收到的Term用于更新他自己
Success bool // 如果follower与Args中的PreLogIndex/PreLogTerm都匹配才会接过去新的日志(追加),不匹配直接返回false
AppState AppendEntriesState // 追加状态
UpNextIndex int // 用于更新请求节点的nextIndex[i]
}
对于真正复制的时候要考虑什么样的情况下,可以进行追加,而什么时候追加的日志是conflict的,对于论文中conflict是这样描述的:
paper:Reply false if log doesn’t contain an entry at prevLogIndex,whose term matches prevLogTerm (§5.3)
可以思考得出有两个情况会导致conflict:
- 1、 如果preLogIndex的大于当前日志的最大的下标说明跟随者缺失日志,拒绝附加日志
- 2、 如果preLog出`的任期和preLogIndex处的任期和preLogTerm不相等,那么说明日志存在conflict,拒绝附加日志
由这个论述我们可以这样构造出这样的代码片段:
if args.PrevLogIndex > 0 && (len(rf.logs) < args.PrevLogIndex || rf.logs[args.PrevLogIndex-1].Term != args.PrevLogTerm) {
reply.AppState = Mismatch
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
以及追加到自身后,要记得进行将该log提交至chan中。也因此是应该追加的更新逻辑是,追加到自身rf.logs中后你需要先更新自身的commitIndex至追加后的长度,但是这时还没apply, lastApplied应该是真正提交到chan的下标,等commit更新后去提交到chan里再更新apply。这也是容易混乱的点。
完整的逻辑:
// AppendEntries 建立心跳、同步日志RPC
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
//fmt.Printf("[ AppendEntries func-rf(%v) ] arg:%+v,------ rf.logs:%v \n", rf.me, args, rf.logs)
// 节点crash
if rf.killed() {
reply.AppState = AppKilled
reply.Term = -1
reply.Success = false
return
}
// args.Term < rf.currentTerm:出现网络分区,args的任期,比当前raft的任期还小,说明args之前所在的分区已经OutOfDate 2A
if args.Term < rf.currentTerm {
reply.AppState = AppOutOfDate
reply.Term = rf.currentTerm
reply.Success = false
return
}
// 出现conflict的情况
// paper:Reply false if log doesn’t contain an entry at prevLogIndex,whose term matches prevLogTerm (§5.3)
// 首先要保证自身len(rf)大于0否则数组越界
// 1、 如果preLogIndex的大于当前日志的最大的下标说明跟随者缺失日志,拒绝附加日志
// 2、 如果preLog出`的任期和preLogIndex处的任期和preLogTerm不相等,那么说明日志存在conflict,拒绝附加日志
if args.PrevLogIndex > 0 && (len(rf.logs) < args.PrevLogIndex || rf.logs[args.PrevLogIndex-1].Term != args.PrevLogTerm) {
reply.AppState = Mismatch
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
// 如果当前节点提交的Index比传过来的还高,说明当前节点的日志已经超前,需返回过去
if args.PrevLogIndex != -1 && rf.lastApplied > args.PrevLogIndex {
reply.AppState = AppCommitted
reply.Term = rf.currentTerm
reply.Success = false
reply.UpNextIndex = rf.lastApplied + 1
return
}
// 对当前的rf进行ticker重置
rf.currentTerm = args.Term
rf.votedFor = args.LeaderId
rf.status = Follower
rf.timer.Reset(rf.overtime)
// 对返回的reply进行赋值
reply.AppState = AppNormal
reply.Term = rf.currentTerm
reply.Success = true
// 如果存在日志包那么进行追加
if args.Entries != nil {
rf.logs = rf.logs[:args.PrevLogIndex]
rf.logs = append(rf.logs, args.Entries...)
}
// 将日志提交至与Leader相同
for rf.lastApplied < args.LeaderCommit {
rf.lastApplied++
applyMsg := ApplyMsg{
CommandValid: true,
CommandIndex: rf.lastApplied,
Command: rf.logs[rf.lastApplied-1].Command,
}
rf.applyChan <- applyMsg
rf.commitIndex = rf.lastApplied
//fmt.Printf("[ AppendEntries func-rf(%v) ] commitLog \n", rf.me)
}
return
}
虽然大体流程逻辑很简单,但是这可能只能保证前两个是正确的,后面还有各种容错测试,你的下标可能也会带来各种的bug。
3.2、处理reply
对于一轮发送的日志请求,与vote一致,超过半数节点就可以更新自身的commitIndex,并apply至客户端,对于一些返回的任期比自己大的reply那么说明肯定是经历了网络分区,需要进行投票重排。
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply, appendNums *int) {
if rf.killed() {
return
}
// paper中5.3节第一段末尾提到,如果append失败应该不断的retries ,直到这个log成功的被store
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
for !ok {
if rf.killed() {
return
}
ok = rf.peers[server].Call("Raft.AppendEntries", args, reply)
}
// 必须在加在这里否则加载前面retry时进入时,RPC也需要一个锁,但是又获取不到,因为锁已经被加上了
rf.mu.Lock()
defer rf.mu.Unlock()
//fmt.Printf("[ sendAppendEntries func-rf(%v) ] get reply :%+v from rf(%v)\n", rf.me, reply, server)
// 对reply的返回状态进行分支
switch reply.AppState {
// 目标节点crash
case AppKilled:
{
return
}
// 目标节点正常返回
case AppNormal:
{
// 2A的test目的是让Leader能不能连续任期,所以2A只需要对节点初始化然后返回就好
// 2B需要判断返回的节点是否超过半数commit,才能将自身commit
if reply.Success && reply.Term == rf.currentTerm && *appendNums <= len(rf.peers)/2 {
*appendNums++
}
// 说明返回的值已经大过了自身数组
if rf.nextIndex[server] > len(rf.logs)+1 {
return
}
rf.nextIndex[server] += len(args.Entries)
if *appendNums > len(rf.peers)/2 {
// 保证幂等性,不会提交第二次
*appendNums = 0
if len(rf.logs) == 0 || rf.logs[len(rf.logs)-1].Term != rf.currentTerm {
return
}
for rf.lastApplied < len(rf.logs) {
rf.lastApplied++
applyMsg := ApplyMsg{
CommandValid: true,
Command: rf.logs[rf.lastApplied-1].Command,
CommandIndex: rf.lastApplied,
}
rf.applyChan <- applyMsg
rf.commitIndex = rf.lastApplied
//fmt.Printf("[ sendAppendEntries func-rf(%v) ] commitLog \n", rf.me)
}
}
//fmt.Printf("[ sendAppendEntries func-rf(%v) ] rf.log :%+v ; rf.lastApplied:%v\n",
// rf.me, rf.logs, rf.lastApplied)
return
}
case Mismatch:
if args.Term != rf.currentTerm {
return
}
rf.nextIndex[server] = reply.UpNextIndex
//If AppendEntries RPC received from new leader: convert to follower(paper - 5.2)
//reason: 出现网络分区,该Leader已经OutOfDate(过时)
case AppOutOfDate:
// 该节点变成追随者,并重置rf状态
rf.status = Follower
rf.votedFor = -1
rf.timer.Reset(rf.overtime)
rf.currentTerm = reply.Term
case AppCommitted:
if args.Term != rf.currentTerm {
return
}
rf.nextIndex[server] = reply.UpNextIndex
}
return
}
四、Debug
对于Lab2b开头其实说过了,大体流程其实不难,难得部分是其众多的test,且你不只是单单只需要关注日志增量的部分,还可能返回去关注你投票的部分。因为在后面众多的容错性测试中,是一定要重新进行选举的,而lab2a测试的都只是小部分场景。 以此为基础,兼容、排错我觉得是最难的部分,以及是最痛苦的部分。
对于所有test情况:
- TestBasicAgree2B():最基础的追加日志测试。先使用nCommitted()检查有多少的server认为日志已经提交(在执行Start()函数之前,所有的服务器都不应该提交日志),若满足条件则调用cfg.one(),其通过调用rf.Start(cmd)来追加日志。rf.Start(cmd)用于模拟Raft实例从Client接收实例的情况。
- TestRPCBytes2B:基于RPC的字节数检查保证每个cmd都只对每个peer发送一次。
- TestFailAgree2B:断连小部分,不影响整体Raft集群的情况检测追加日志。
- TestFailNoAgree2B:断连过半数节点,保证无日志可以正常追加。然后又重新恢复节点,检测追加日志情况。
- TestConcurrentStarts2B:模拟客户端并发发送多个命令
- TestRejoin2B:Leader 1断连,再让旧leader 1接受日志,再给新Leader 2发送日志,2断连,再重连旧Leader 1,提交日志,再让2重连,再提交日志。
- TestBackup2B:先给Leader 1发送日志,然后断连3个Follower(总共1Ledaer 4Follower),网络分区。提交大量命令给1。然后让leader 1和其Follower下线,之前的3个Follower上线,向它们发送日志。然后在对剩下的仅有3个节点的Raft集群重复上面网络分区的过程。
- TestCount2B:检查无效的RPC个数,不能过多。
这上面的描述,只能起到一个大概的描述作用。具体的分析应该回归test函数、以及日志打印来分析。
对于不同的分析流程应该是:
- 先分析其日志追加情况如何 - > 分析其任期情况 - > 分析其leader选举情况
对于不同的test可以自己注释掉不相关的,节省测试时间。
对于笔者来说主要是TestRejoin2B、TestBackup2B出现了问题这里也简单分享一下:
我先是通过分析其追加append的log发现后期leader重连后term涨的非常快,然后再具体打印下领导选举的情况,发现领导选举的过程中有很多情况是没选举出合适的leader,这里简单还原下问题代码:
if args.LastLogTerm < lastLogTerm || args.LastLogIndex < len(rf.logs)) {
reply.VoteState = Expire
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
因为论文中这样提的:
Receiver implementation:
- Reply false if term < currentTerm (§5.1)
- If votedFor is null or candidateId, and candidate’s log is at
least as up-to-date as receiver’s log, grant vote (§5.2, §5.4)

一度认为自己没错,后面再根据日志和paper(特别是Figure 8)多思考理解了几遍,得到了思路。
- at least as up-to-date as receiver’s log的意思应该不只是要跟所发到的节点最新的log需要一致。个人的理解是,领导选举应该是先要保证term是最大的。term最大能保证它在网络分区中,收到的数据(日志条目是最完整的)。对于日志的条目数不能一味的根据长度进行判断,如图中的S5条目虽然没有S1的多,但是它term更大,把s1的进行rollback,这也是raft简化实现的一部分:增量的过程只会从leader到followers单向进行。
那么日志条目有没有什么作用呢,paper中提到的candidate’s log is at least as up-to-date as receiver’s log又是什么意思呢? - 我个人的理解是,要比较日志的下标的条目是有必要的。但是我们最终的目的的是为了选出更有资质当leader的rf节点。也因此对于首先条件应该是判断是term,然后如果term相等时,同时有两个竞争者,两个一样的网络分区。那么这个时候我们再具体的进行数据完备性的检查,此时args的日志下标就不能低于当前节点的日志下标。
由此改出的代码片段为:
if args.LastLogTerm < lastLogTerm || (len(rf.logs) > 0 && args.LastLogTerm == rf.logs[len(rf.logs)-1].Term && args.LastLogIndex < len(rf.logs)) {
reply.VoteState = Expire
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
这也是我最后一个的bug,其他多多少少的bug就不赘述了,这里只提供大概一个debug分享的流程,自己做出一遍,这个课程才有意义。
五、总结
对于做lab2b一度做到自闭,有一次更是改了一天,改不出来又回去重写了lab1的代码。但是所幸还是做出来了,在allpast的时候也感到了兴奋与开心。在这过程中我看到一句话:你本来就是一无所有,重新来过你并不会失去什么。 用来激励后续冲塔的自己,也祝愿看到本篇的读者,git能够坚持下来,实现自己的raft框架。附上自己的gitee:觉得有所帮助可以帮忙点个star~(当然gitee仅供参考,自己构造出来才能有最大的收获)。
gitee:6.824-2022
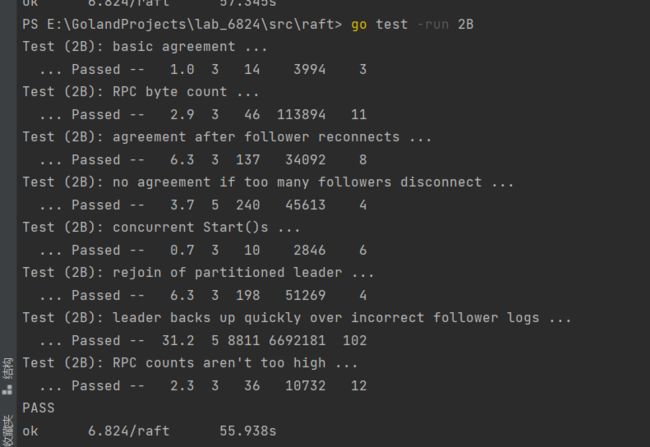
测试截图: