自动化测试如何区分用例集合及编写规范
前言
前面的文章介绍过如何设计自动化测试case,有同学在后台问到:业务比较复杂,有很多串行并行甚至组合的业务场景,执行case时经常遇到由于前后依赖导致的case失败问题,该如何处理?
当业务复杂度和工作量上来之后,在具体的实践中这是个避不开的问题。那如何解决这个问题?我建议可以通过按照业务和场景区分用例集合的方式来解决。
业务量和复杂度增长现状是什么?
以我的亲身经历而言,当业务爆发式增长时,测试团队会面临如下几点变化和调整:
| 对比项 |
业务增长前 |
业务增长后 |
| 团队组织架构 |
大团队 |
大团队小team,按照业务域划分不同小团队 |
| 团队协作方式 |
互相协作,沟通成本低 |
跨team协作频次变高,构成成本高 |
| 团队技术栈构成 |
比较单一,学习和迁移成本低 |
技术栈多样,学习和迁移成本高 |
| 测试case覆盖率 |
只覆盖核心场景,保证主流程正向流程 |
PO/P1/P2场景,正向逆向场景都覆盖 |
| 测试人员职责划分 |
每个人都熟悉整体业务流程和场景 |
每个人只熟悉岗位职责内的业务流程和场景 |
这里我们只讨论和自动化测试case相关的区别。
业务增长自然而然带来的是流程的复杂度提升和业务场景的多样性,同时用户体验和线上的小问题影响范围,也会扩大。
因此在测试case的覆盖率上,覆盖的颗粒度会更细致。
以电商下单场景为例:核心流程在case设计和执行以及结果校验时,主要会关心商品库存、是否使用优惠券、是否参与活动以及订单数据是否入库到之后的是否支付成功,这是一个正向的核心场景case。如下图所示:
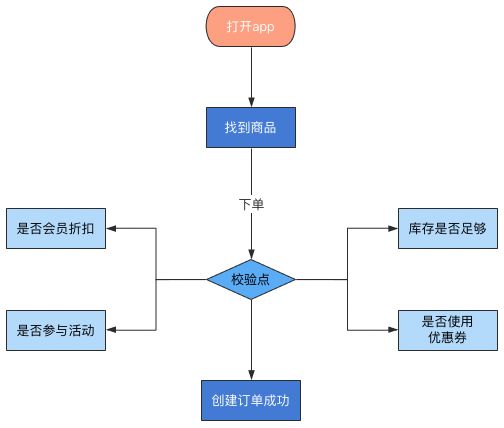
正常的下单流程能否走下去,主要依赖于上图的几个校验点。
假设,团队按照不同的业务域拆分为好多个小团队,职责和边界划分更细致时,该怎么做呢?
如何区分自动化测试的用例集合?
还是以电商的主要业务流程为例说明,假设团队拆分的更细致,业务链路依赖更复杂,怎么办?如下图:
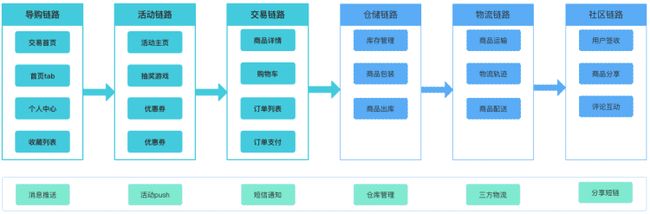
可以看到每个链路都会依赖于上下游链路的部分数据或者调用关系。面对如此复杂的场景和跨团队协调,这个时候区分用例集合的好处就体现了出来。那么如何区分用例集合呢?看下图:
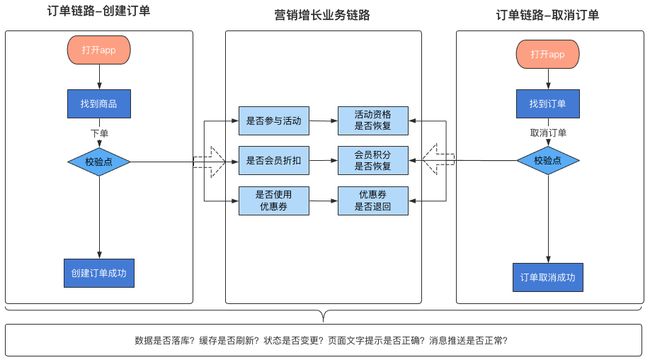
如上图所示,如果团队是按照业务域或者业务链路做了区分,团队内同学负责的模块也不一致,区分的大致思路如上。
如何理解呢?就是每个人只负责设计自己所负责模块的case,考虑好正向逆向流程的校验点,然后调用和依赖模块对应的场景和数据,和对方约定好,遵循互信原则即可。
区分用例集合的过程要注意什么?
区分用例集合的注意事项,主要参考如下几点:
- 业务团队按照一定的原则划分,而不是混乱;
- 每个团队之间要明确好业务边界和职责边界;
- 调用依赖和边界遵循统一的调用方式(如restful);
- 测试数据的存储和校验建议统一维护而非各自独立;
- 测试用例要按照不同条件做区分(类似打标签形式);
- 持续集成任务要按照前后依赖做好执行时序的区分;
自动化测试用例选择
自动化测试主要应用于基础功能的验证和回归,对于在项目迭代过程中不断修改的功能来说,手工测试的效率是大大高于自动化测试的。
因此,我们在进行自动化之前,要挑选基础功能来进行自动化。
在这个过程中,我们可以从手工测试用例中进行挑选,也可以专门为自动化编写一套用例。
在自动化初期,建议从手工测试用例中进行挑选。一方面手工测试用例的覆盖度最为全面,可以保证测试的全面性;
另一方面,也会提高测试效率。
我们挑选用例的原则是:清晰、简单、基础、改动小的功能。
自动化测试用例编写
挑选完合适的用例之后,就是通过代码编写自动化用例的过程。这个过程主要包括数据预置、用例编写和用例后置三个步骤。
1、数据预置
在进行用例编写之前,我们需要准备一些数据,保证用例能够真正的执行起来。比如,我们在测试一个网页登录功能,我们需要系统的URL参数、需要一个可以登录的用户名和密码;
我们需要测试删除文件的功能,就需要提前上传一个文件,这个文件可以提前预置,也可以在执行删除操作之前,执行一个上传操作;通过哪种方式预置数据,需要根据项目的实际情况选择。
我们将数据预置和用例编写分开是为了减少用例之间的耦合度,保证上一个用例执行的结果不会对下一条用例产生影响。此外,有利于用例的维护和修改。
2、用例编写
我们准备好测试数据后,就要开始自动化用例的编写,在编写过程中需要注意以下几个方面:
熟悉业务。自动化测试是为了业务系统服务的,只有充分的了解业务,明确如何将手工测试用例通过自动化实现,才能保证用例质量。
使用变量。通常,我们需要将变量统一管理,写入配置文件,这样方便统一修改。例如:我们需要测试一个业务系统,这个系统包含测试环境和生产环境,我们需要将自动化脚本灵活的适用于每个环境,这个时候,我们就需要将url等系统参数写入配置文件,方便修改和迁移。
写明操作过程。在编写操作过程时,代码注释必不可少。每一步都是怎么操作的,需要验证什么功能。
设置检查点。在编写测试用例的过程中,需要设置合理的检查点,添加断言,判断用例是否执行成功。在用例执行后,将预期结果和实际结果进行对比,输出测试结果,明确功能是否执行成功,是自动化测试的关键。不添加断言的用例执行,是没有任何意义的。
3、用例后置
用例后置时指用例执行完成之后的操作,与数据预置相对应,是为了自动化能够循环执行。
比如:我们需要测试文件上传功能,在用例执行通过之后,需要将文件删除,便于下一次自动执行。
此外,我们应该在用例后置之后进行一些合理的检查,比如上个步骤中,我们如果删除文件失败的话,依然会影响下一次的操作。因此,我们需要结合项目实际情况,对一些核心文件进行检查,保证自动化的顺利执行。
用例编写规范
在用例编写过程中,我们需要遵守一些规范来提高用例质量。主要包括:连续性、独立性、完整性、可重用性、可维护性和逻辑分块。
1、连续性
保证用例之间的连续性,保证用例可以批量执行。比如,我们在进行UI自动化时,要保证上一个操作之后进入下一个操作的执行界面。
2、独立性
用例之间要相互独立,保证上一个用例的执行结果不会对下一个用例的执行产生影响。这样,才能更清楚的定位到问题。此外,需要保证一个用例的执行不会修改到下一个用例的数据。
3、完整性
每一个用例都需要有数据准备、操作过程,断言和用例后置的全部过程,能够根据用例明确具体的测试内容。
4、可重用性
类似于开发的公共代码,我们要抽象出自动化测试的原子操作,提供给其他用例调用,这样可以减少开发成本
5、可维护性
用例名要清晰,做到见名知意;对每个步骤、每个变量添加明确的注释;对哪些是预置数据、哪些是检查项、预期结果都有明确的说明;用例步骤要简单明了
6、逻辑分块
根据一定的规则进行逻辑分块(例如可以根据不同功能划分),保证逻辑块的独立性,可以抽出单个功能用例进行验证。
感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:
这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!有需要的小伙伴可以点击下方小卡片领取