扩散模型Diffusion model | DDPM
扩散模型Diffusion model | DDPM
论文原文:Denoising Diffusion Probabilistic Model
前言—和VAE的联系
DDPM实际上是VAE而不是扩散模型
多步扩散
DDPM将VAE的编码过程和生成过程分解为T步,每一个 p ( x t ∣ x t − 1 ) p(x_{t}|x_{t−1}) p(xt∣xt−1)和 q ( x t − 1 ∣ x t ) q(x_{t−1}|x_{t}) q(xt−1∣xt)仅负责建模一个微小变化,它们依然建模为正态分布。
对于微小变化来说,可以用正态分布足够近似地建模(高斯混合模型的思想),类似于曲线在小范围内可以用直线近似,多步分解就有点像用分段线性函数拟合复杂曲线,因此理论上可以突破传统单步VAE的拟合能力限制。
编码能力
DDPM是放弃了模型的编码能力,最终只得到一个纯粹的生成模型
核心推导步骤
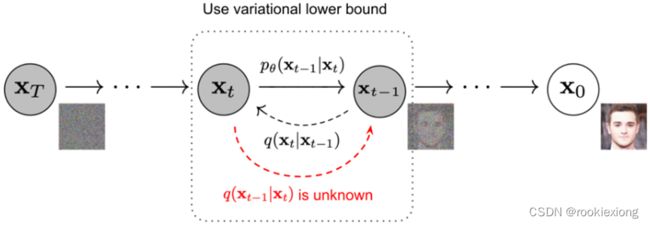
引入了一个 q ( x t − 1 ∣ x t , x 0 ) q(x_{t−1}|x_{t},x_{0}) q(xt−1∣xt,x0)来进行裂项相消,然后转化为正态分布的KL散度形式。
而后用 p θ ( x t − 1 ∣ x t ) p_{\theta}(x_{t−1}|x_{t}) pθ(xt−1∣xt)来近似 q ( x t − 1 ∣ x t , x 0 ) q(x_{t−1}|x_{t},x_{0}) q(xt−1∣xt,x0)从而极大似然 p θ ( x 0 ) p_{\theta}(x_{0}) pθ(x0)
模型推导
前向过程
给定一个从真实数据分布 x 0 ∼ q ( x ) x_{0}\sim q(x) x0∼q(x)中采样的数据点,前向扩散过程中分 T T T步向样本中加入少量高斯噪声,产生一系列带噪声的样本 x 0 , . . . , x T x_{0},...,x_{T} x0,...,xT。加入噪声的均值和方差由控制。即
x t = α t x t − 1 + β t ε t , ε t ∼ N ( 0 , I ) \boldsymbol{x}_t=\alpha_t\boldsymbol{x}_{t-1}+\beta_t\boldsymbol{\varepsilon}_t,\quad\boldsymbol{\varepsilon}_t\sim\mathcal{N}(\boldsymbol{0},\boldsymbol{I}) xt=αtxt−1+βtεt,εt∼N(0,I)
其中有 α t , β t > 0 \alpha_t,\beta_t>0 αt,βt>0且 α t 2 + β t 2 = 1 \alpha_t^2+\beta_t^2=1 αt2+βt2=1(方便下述正态分布相加计算), β t \beta_t βt通常很接近于0.

反向过程
如果我们可以反转上述过程并从 q ( x t − 1 │ x t ) q(x_{t-1}│x_{t} ) q(xt−1│xt)中采样,我们将能够从高斯噪声输入 x T ∼ N ( 0 , I ) \boldsymbol{x}_T\sim\mathcal{N}(\boldsymbol{0},\boldsymbol{I}) xT∼N(0,I)中重建真实样本。由 x t = α t x t − 1 + β t ε t \boldsymbol{x}_t=\alpha_t\boldsymbol{x}_{t-1}+\beta_t\boldsymbol{\varepsilon}_t xt=αtxt−1+βtεt可知, x t − 1 = 1 α t ( x t − β t ε t ) \boldsymbol{x}_{t-1}=\frac1{\alpha_t}(\boldsymbol{x}_t-\beta_t\boldsymbol{\varepsilon}_t) xt−1=αt1(xt−βtεt),由于此过程难以直接计算,可以用神经网络模拟为
μ ( x t ) = 1 α t ( x t − β t ϵ θ ( x t , t ) ) \boldsymbol{\mu}(\boldsymbol{x}_t)=\frac1{\alpha_t}(\boldsymbol{x}_t-\beta_t\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,t)) μ(xt)=αt1(xt−βtϵθ(xt,t))
那么我们的损失函数可以理解为(考虑了扩散过程中的时间因素):
∥ x t − 1 − μ ( x t ) ∥ 2 = β t 2 α t 2 ∥ ε t − ϵ θ ( x t , t ) ∥ 2 \left\|\boldsymbol{x}_{t-1}-\boldsymbol{\mu}(\boldsymbol{x}_t)\right\|^2=\frac{\beta_t^2}{\alpha_t^2}\left\|\boldsymbol{\varepsilon}_t-\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,t)\right\|^2 ∥xt−1−μ(xt)∥2=αt2βt2∥εt−ϵθ(xt,t)∥2
忽略前面系数,带入之前的 x t {x}_{t} xt,得到
∥ ε t − ϵ θ ( α ˉ t x 0 + α t β ˉ t − 1 ε ˉ t − 1 + β t ε t , t ) ∥ 2 \left\|\varepsilon_t-\epsilon_\theta(\bar{\alpha}_t\boldsymbol{x}_0+\alpha_t\bar{\beta}_{t-1}\bar{\boldsymbol{\varepsilon}}_{t-1}+\beta_t\boldsymbol{\varepsilon}_t,t)\right\|^2 εt−ϵθ(αˉtx0+αtβˉt−1εˉt−1+βtεt,t) 2
这里选择回退一步到 x t − 1 x_{t-1} xt−1来给出 x t x_{t} xt,因为我们已经事先采样了 ε t \varepsilon_t εt,而 ε t \varepsilon_t εt跟 ε ˉ t \bar{\varepsilon}_{t} εˉt不是相互独立的,所以给定 ε t \varepsilon_t εt的情况下,我们不能完全独立地采样 ε ˉ t \bar{\varepsilon}_{t} εˉt
损失
上述损失函数实际上包含了4个需要采样的随机变量,要采样的随机变量越多,就越难对损失函数做准确的估计。可以通过一个积分技巧来将 ε t \varepsilon_t εt跟 ε ˉ t − 1 \bar{\varepsilon}_{t-1} εˉt−1合并成单个正态随机变量
大致就是去构造两个独立的方程式去解方程:
α t β ˉ t − 1 ε ˉ t − 1 + β t ε t = β t ε ∣ ε ∼ N ( 0 , I ) , β t ε ˉ t − 1 − α t β ˉ t − 1 ε t = β ˉ t ω ∣ ω ∼ N ( 0 , I ) \alpha_t\bar{\beta}_{t-1}\boldsymbol{\bar{\varepsilon}}_{t-1}+\beta_t\boldsymbol{\varepsilon}_t ={{\beta}}_{t}\boldsymbol{\varepsilon}|\boldsymbol{\varepsilon}\sim\mathcal{N}(\mathbf{0},\boldsymbol{I}),\beta_t\bar{\boldsymbol{\varepsilon}}_{t-1}-\alpha_t\bar{\boldsymbol{\beta}}_{t-1}\boldsymbol{\varepsilon}_t = \bar{\beta}_t\boldsymbol{\omega}|\boldsymbol{\omega}\sim\mathcal{N}(\mathbf{0},\boldsymbol{I}) αtβˉt−1εˉt−1+βtεt=βtε∣ε∼N(0,I),βtεˉt−1−αtβˉt−1εt=βˉtω∣ω∼N(0,I)
解出来代回去即可得到DDPM最终用的损失函数:
∥ ε − β ˉ t β t ϵ θ ( α ˉ t x 0 + β ˉ t ε , t ) ∥ 2 \left\|\varepsilon-\frac{\bar{\beta}_t}{\beta_t}\epsilon_\theta(\bar{\alpha}_t\boldsymbol{x}_0+\bar{\beta}_t\boldsymbol{\varepsilon},t)\right\|^2 ε−βtβˉtϵθ(αˉtx0+βˉtε,t) 2
变分下界



推理生成
训练完之后,我们就可以从一个随机噪声 x T ∼ N ( 0 , I ) \boldsymbol{x}_T\sim\mathcal{N}(\boldsymbol{0},\boldsymbol{I}) xT∼N(0,I)出发反向传播 T T T步来进行生成。同时需要进行随机采样,那么需要补上噪声项。
x t − 1 = 1 α t ( x t − β t ϵ θ ( x t , t ) ) + σ t z , z ∼ N ( 0 , I ) \boldsymbol{x}_{t-1}=\frac1{\alpha_t}(\boldsymbol{x}_t-\beta_t\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,t))+\sigma_t\boldsymbol{z},\quad\boldsymbol{z}\sim\mathcal{N}(\mathbf{0},\boldsymbol{I}) xt−1=αt1(xt−βtϵθ(xt,t))+σtz,z∼N(0,I)
实质上,DDPM的采样每次都从一个随机噪声出发,需要重复迭代T步来得到一个样本输出