Java爬取某旅游网站的景点信息
前言:这两周在做 Web 课的大作业,顺便琢磨了一下如何使用 Java 从网上获取一些数据,现在写这篇博客记录一下。
PS:这里仅限交流学习用,如利用代码进行恶意攻击他网站,和作者无关!!!
更新:修改了一些内容,本文章仅供参考。
Java爬取某旅游网站的景点信息
网上用 Java 做数据爬取的案例不少,但是很少是能用的,有些是几年前能用,但是现在不行了,有些则是只有一个思路,在上网查阅许多资料之后我琢磨出了一个可行的爬取去哪儿网的景点信息的方案。
使用工具:
- HttpClient:发出请求
- Jsoup:解析页面
- MyBatis:数据保存
所需 Maven 依赖:
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.20version>
dependency>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.4version>
dependency>
<dependency>
<groupId>ch.qos.logbackgroupId>
<artifactId>logback-classicartifactId>
<version>1.2.3version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>RELEASEversion>
<scope>testscope>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpcoreartifactId>
<version>4.4.14version>
dependency>
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpclientartifactId>
<version>4.5.13version>
dependency>
<dependency>
<groupId>commons-httpclientgroupId>
<artifactId>commons-httpclientartifactId>
<version>3.1version>
dependency>
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.11.3version>
dependency>
<dependency>
<groupId>com.squareup.okhttp3groupId>
<artifactId>okhttpartifactId>
<version>4.1.0version>
dependency>
一、发出请求
我这里使用 HttpClient 来发 Get 请求获取我想要的信息,代码如下:
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.cookie.CookiePolicy;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.DefaultHttpParams;
import org.apache.commons.httpclient.params.HttpMethodParams;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
/**
* @author 小关同学
* @create 2021/11/9
*/
public class Request {
public static String doGet(String url) {
// 输入流
InputStream is = null;
BufferedReader br = null;
String result = null;
// 创建httpClient实例
HttpClient httpClient = new HttpClient();
// 设置http连接主机服务超时时间:15000毫秒
// 先获取连接管理器对象,再获取参数对象,再进行参数的赋值
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(15000);
// 创建一个Get方法实例对象
GetMethod getMethod = new GetMethod(url);
// 设置get请求超时为60000毫秒
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 60000);
// 设置请求重试机制,默认重试次数:3次,参数设置为true,重试机制可用,false相反
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER, new DefaultHttpMethodRetryHandler(3, true));
DefaultHttpParams.getDefaultParams().setParameter("http.protocol.cookie-policy", CookiePolicy.BROWSER_COMPATIBILITY);
try {
Thread.sleep(5000);
// 执行Get方法
int statusCode = httpClient.executeMethod(getMethod);
System.out.println("请求状态码:"+statusCode);
// 判断返回码
// if (statusCode != HttpStatus.SC_OK) {
// 如果状态码返回的不是ok,说明失败了,打印错误信息
// System.err.println("Method faild: " + getMethod.getStatusLine());
// } else {
// 通过getMethod实例,获取远程的一个输入流
is = getMethod.getResponseBodyAsStream();
// 包装输入流
br = new BufferedReader(new InputStreamReader(is, "UTF-8"));
StringBuffer sbf = new StringBuffer();
// 读取封装的输入流
String temp = null;
while ((temp = br.readLine()) != null) {
sbf.append(temp).append("\r\n");
}
result = sbf.toString();
// }
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭资源
if (null != br) {
try {
br.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (null != is) {
try {
is.close();
} catch (Exception e) {
e.printStackTrace();
}
}
// 释放连接
getMethod.releaseConnection();
}
return result;
}
}
这里的发出请求代码网上多得是,我这个是借鉴了网上的代码,然后稍作修改而来的,主要修改了判断返回状态码那里,使得一次请求不成功之后程序不会立即停止,而是继续发出请求,直到获取到想要的数据。
PS:这里按理说最好改一下请求头什么的,来避过反爬机制,但是我懒得改了,就让它那样了(能用就行)。
二、对 HTML 页面进行解析(重点)
对 HTML 页面进行解析的话就要使用 Jsoup 了,这里先介绍一下这个 Jsoup 是什么。
Jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。
Jsoup 的主要功能
- 从一个 URL,文件或字符串中解析 HTML;
- 使用 DOM 或 CSS 选择器来查找、取出数据;
- 可操作 HTML 元素、属性、文本。
我们这里使用 Jsoup 解析前面获取到的 HTML 页面信息,代码如下:
import com.entity.Spot;
import com.entity.SpotDetail;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* @author 小关同学
* @create 2021/11/6
* 爬取去哪儿旅行的数据
*/
public class SpotDataCrawler {
/**
* 爬取对应城市景点简介信息
* @param city
* @return
*/
public static Set<Spot> requestSpotData(String city, int page) {
String ascii = CodeTransition.stringToASCII(city);
String target = Request.doGet("http://piao.qunar.com/ticket/list.htm?keyword="+ascii+"®ion=&from=mpl_search_suggest&page="+page);
Document root_document = null;
assert target != null;
//是404页面时,返回null
if (target.contains("非常抱歉,您访问的页面不存在。
")){
return null;
}
root_document = Jsoup.parse(target);
//获取需要数据的div
Element e = root_document.getElementById("search-list");
//得到网页上的景点列表(包含两个样式集合)
Elements yy = e.getElementsByClass("sight_item sight_itempos");
Elements yy2 = e.getElementsByClass("sight_item");
yy.addAll(yy2);
//图片
//#search-list > div:nth-child(1) > div > div.sight_item_show > div > a
//标题
//#search-list > div:nth-child(1) > div > div.sight_item_about > h3 > a
//地点
//#search-list > div:nth-child(1) > div > div.sight_item_about > div > p > span
//简介
//#search-list > div:nth-child(1) > div > div.sight_item_about > div > div.intro.color999
//热度
//#search-list > div:nth-child(1) > div > div.sight_item_about > div > div.clrfix > div > span.product_star_level > em > span
Set<Spot> spotList = new HashSet<>();
for (int i = 0; i < yy.size(); i++) {
Spot spot = new Spot();
//得到每一条景点信息
Element Info = yy.get(i);
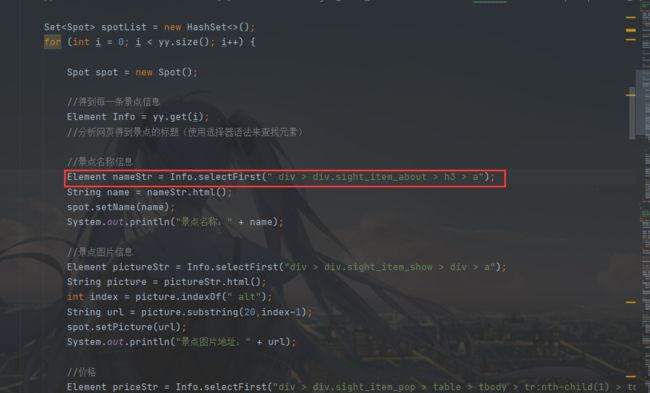
//分析网页得到景点的标题(使用选择器语法来查找元素)
//景点名称信息
Element nameStr = Info.selectFirst(" div > div.sight_item_about > h3 > a");
String name = nameStr.html();
spot.setName(name);
System.out.println("景点名称:" + name);
//景点图片信息
Element pictureStr = Info.selectFirst("div > div.sight_item_show > div > a");
String picture = pictureStr.html();
int index = picture.indexOf(" alt");
String url = picture.substring(20,index-1);
spot.setPicture(url);
System.out.println("景点图片地址:" + url);
//价格
Element priceStr = Info.selectFirst("div > div.sight_item_pop > table > tbody > tr:nth-child(1) > td > span > em");
if (priceStr!=null){
String price = priceStr.html();
if (!price.isEmpty()){
spot.setPrice(Double.parseDouble(price));
System.out.println("价格:" + price);
}
}
//景点地点信息
Element addressStr = Info.selectFirst(" div > div.sight_item_about > div > p > span");
String address = addressStr.html();
spot.setArea(address);
System.out.println("景点地点:" + address);
//景点简介
Element infoStr = Info.selectFirst(" div > div.sight_item_about > div > div.intro.color999");
String info = infoStr.html();
spot.setInfo(info);
System.out.println("景点简介:" + info);
//景点在网页中对应的id
//#search-list > div:nth-child(1) > div > div.sight_item_about > div > p > a
Element spotIdInWebStr = Info.selectFirst("div > div.sight_item_about > div > p > a");
int start = spotIdInWebStr.toString().indexOf("data-sightid=\"");
int end = spotIdInWebStr.toString().indexOf("\">地图");
String spotWebId = spotIdInWebStr.toString().substring(start+14,end);
spot.setSpotWebId(spotWebId);
System.out.println("对应详情页面的id:"+spotWebId);
spotList.add(spot);
}
return spotList;
}
/**
* 爬取景点的详细信息
* @param name 景点名称
* @param webId 景点对应的webId
* @return 返回相关信息
*/
public static Object[] requestSpotDetailData(String name,int id,String webId){
Object[] result = new Object[2];
Spot spot = new Spot();
List<SpotDetail> list = new ArrayList<>();
String ascii = CodeTransition.stringToASCII(name);
String url = "http://piao.qunar.com/ticket/detail_" + webId + ".html?st="+ascii+"#from=mpl_search_suggest";
String target = Request.doGet(url);
assert target != null;
//是404页面时,返回null
if (target.contains("非常抱歉,您访问的页面不存在。
")){
System.out.println("非常抱歉,您访问的页面不存在");
return null;
}
Document root_document;
root_document = Jsoup.parse(target);
//分析网页得到景点的标题(使用选择器语法来查找元素)
spot.setId(id);
//特色看点->推荐理由(保存在Spot里面)
//#mp-charact > div > div.mp-charact-intro > div.mp-charact-desc > p:nth-child(1)
//#mp-charact > div > div.mp-charact-intro > div.mp-charact-desc > p:nth-child(2)
String reason = "";
Element reasonStr1 = root_document.selectFirst("#mp-charact > div:nth-child(1) > div.mp-charact-intro > div.mp-charact-desc > p");
if (reasonStr1!=null){
reason = reasonStr1.html();
}
Element reasonStr2 = root_document.selectFirst("#mp-charact > div > div.mp-charact-intro > div.mp-charact-desc > p:nth-child(1)");
if (reasonStr2!=null){
reason = reasonStr2.html();
}
spot.setInfoDetail(reason);
System.out.println("推荐理由:" + reason);
//开放时间
Element openTimeStr = root_document.selectFirst("#mp-charact > div:nth-child(1) > div.mp-charact-time > div > div.mp-charact-desc > p");
if (openTimeStr!=null){
String openTime = openTimeStr.html();
spot.setOpenTime(openTime);
System.out.println("开放时间:" + openTime);
}
//景点详细信息
//#mp-charact > div:nth-child(2)
//#mp-charact > div:nth-child(2)
Element infoDetailStr = root_document.selectFirst("#mp-charact > div:nth-child(2)");
//如果没有图片等详细介绍
if (infoDetailStr==null){
result[0] = spot;
result[1] = null;
return result;
}
//得到网页上的景点列表(包含两个样式集合)
Elements yy = infoDetailStr.getElementsByClass("mp-charact-event");
System.out.println(yy.size());
for (int i = 0; i < yy.size(); i++) {
SpotDetail spotDetail = new SpotDetail();
//得到每一条景点信息
Element Info = yy.get(i);
//#mp-charact > div:nth-child(2) > div:nth-child(3) > div > img
//#mp-charact > div:nth-child(2) > div:nth-child(3) > div
Element pictureStr = Info.selectFirst("div > img");
if (pictureStr!=null){
int index = pictureStr.toString().indexOf(">");
String pictureUrl = pictureStr.toString().substring(10,index-1);
spotDetail.setPicture(pictureUrl);
System.out.println("景点图片地址:" + pictureUrl);
}
//#mp-charact > div:nth-child(2) > div:nth-child(2) > div > div.mp-event-desc > h3
Element titleStr = Info.selectFirst("div > div.mp-event-desc > h3");
if (titleStr!=null){
String title = titleStr.html();
spotDetail.setTitle(title);
System.out.println("图片标题:"+title);
}
Element pictureDetailStr = Info.selectFirst("div > div.mp-event-desc > p");
if (pictureDetailStr!=null){
String pictureDetail = pictureDetailStr.html();
spotDetail.setInfo(pictureDetail);
System.out.println("图片详情:"+pictureDetail);
}
list.add(spotDetail);
}
result[0] = spot;
result[1] = list;
return result;
}
public static void main(String[] args) throws InterruptedException {
//测试爬取景点简要信息
// for (int i = 1;i <= 10;i++){
// //生成1-10的随机数
// int random = (int)(1+Math.random()*(10-1+1));
// String str = random+"00";
// Thread.sleep(Integer.parseInt(str));
// System.out.println("=======================第"+i+"页=====================");
// Object result = requestSpotData("西安",i);
// if (result==null){
// i--;
// }else{
// System.out.println(result.toString());
// }
// }
//测试爬取景点详细信息
Object[] param = SpotDataCrawler.requestSpotDetailData("陕西历史博物馆",1,"383907200");
System.out.println("===========================分割线==================================");
if (param!=null){
System.out.println(((Spot)param[0]).toString());
for (SpotDetail detail:(List<SpotDetail>)param[1]){
System.out.println(detail.toString());
}
}
}
}
1、对API查询接口的操作
现在进入了重头戏,首先,根据去哪儿景点查询页面获取到景点查询的API接口,如下图:
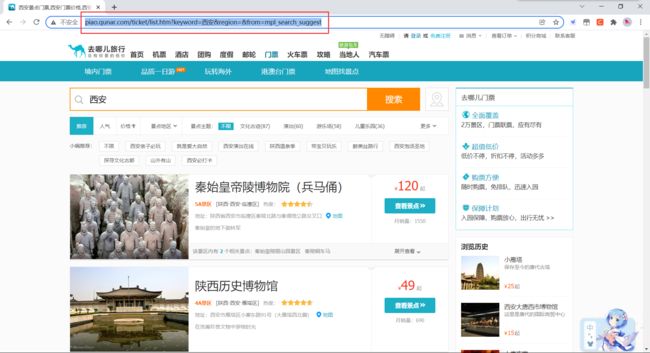
我们可以看到,去哪儿的景点查询API是这样的
http://piao.qunar.com/ticket/list.htm?keyword=要查询景点的UTF-8编码形式®ion=&from=mpl_search_suggest
这里我们要查询的景点是西安,所以得把“西安”这个 keyword 转换为 UTF-8 编码的形式,转换代码如下:
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
/**
* @author 小关同学
* @create 2021/11/7
* 中文转URL
*/
public class CodeTransition {
public static String stringToASCII(String param) {
String result = "";
try {
result = URLEncoder.encode(param,"utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return result;
}
public static void main(String[] args){
System.out.println(stringToASCII("西安"));
}
}
2、对请求到的页面的解析操作
然后我们来对页面进行解析(这里只做部分讲解),
先将获取到的页面进行解析,如下图:

这里使用 Jsoup.parse 方法进行解析,把 String 类型的页面数据解析成 Document 对象,方便我们下一步操作。
3、HTML 中元素的定位
比如我们要获取景点的名称,如下图:
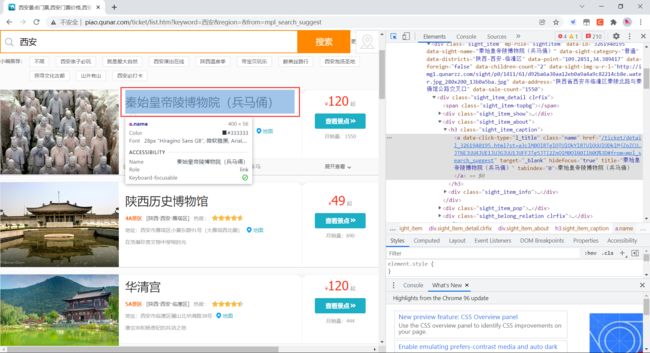
使用浏览器的调试功能定位到相应的 HTML 代码上,然后右键,选择 Copy 下的 Copy Selector 来获取代码在页面中的位置,如下:
#search-list > div:nth-child(1) > div > div.sight_item_about > h3 > a
然后使用 Element 对象定位元素,进而获取到信息,详细的过程我也不讲太多了,自己看代码去。
三、保存获取到的数据

现在我们获取并解析得到了数据,我们现在可以把它们放到数据库里面去了,这里我使用了 MyBatis 框架进行数据持久化操作,代码我就不贴了,想看完整代码的去我 Github 上面看。
最后
项目地址如下:
Github 地址:https://github.com/guanchanglong/DataCrawler
麻烦各位可否在看代码的时候顺手给一颗星 ^ _ ^,举手之劳感激不尽。
PS:可以到我的个人博客查看更多内容
个人博客地址:www.xiaoguantongxue.com