Python爬虫获取数据实战:2023数学建模美赛春季赛帆船数据网站sailboatdata.com(状态码403forbidden→使用cloudscraper绕过cloudflare)
当我们爬取到一个html文件时,一般篇幅很长,我们需要对其做文档解析。
利用之前我所做的模板,我们爬到的内容一般分为一下两种:
1.json数据型
通过科学上网进入该网站,F12,刷新。观察发现,第一个url中并没有我们需要的数据,而帆船数据是在https://rr3d63yhaq-2.algolianet.com/1/indexes/wp_posts_sailboat/query?x-algolia-agent=Algolia%20for%20JavaScript%20(4.13.0)%3B%20Browser这个url中
这个网站一共收藏了8887个Sailboats,每页显示50条,共有178页
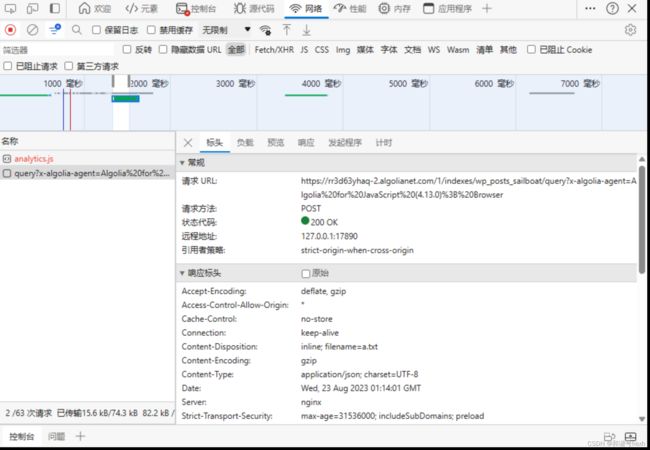
表单数据中可以设置我们需要的页数:
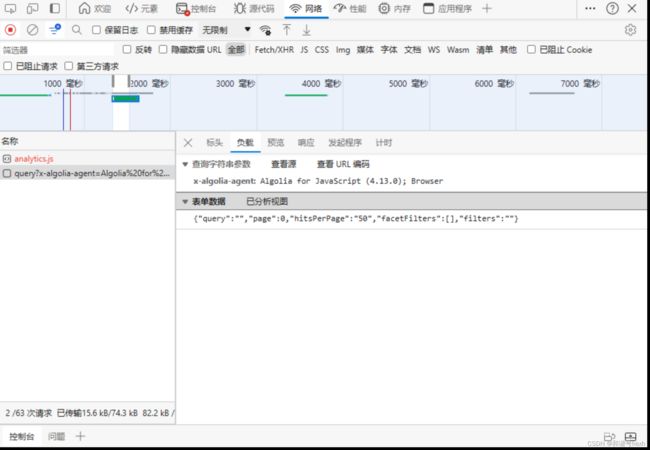
我们爬取第0页的数据,其余页面同理:
# -*- coding: utf-8 -*-
# @Time: 2023-08-18 16:33
# @Author: hexh
# @File: main1.py
# @Software: PyCharm
import os
import random
from crawlerTemplate import crawler
import time
if __name__ == "__main__":
folderpath = r"./target"
os.chdir(folderpath)
data = {
"query": "",
"page": 0,
"hitsPerPage": "50",
"facetFilters": [],
"filters": ""
}
# data = '{"query":"","page":0,"hitsPerPage":"50","facetFilters":[],"filters":""}'
for i, item in enumerate(os.listdir()):
print("爬取结果为:\n", crawler.main(item,data=data))
# time.sleep(random.randint(-2500,2500)/1000+5)
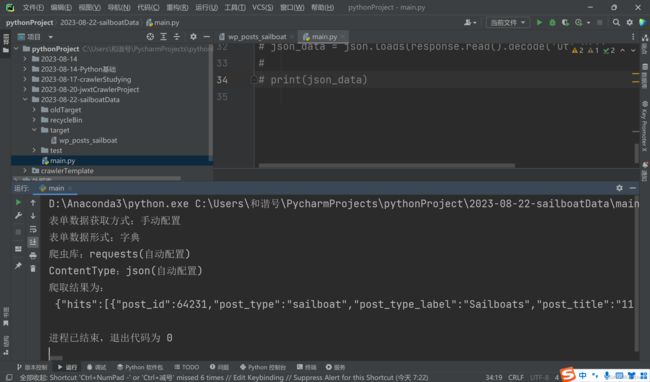
将爬取结果拷贝到一个新的py文件,并赋值给a
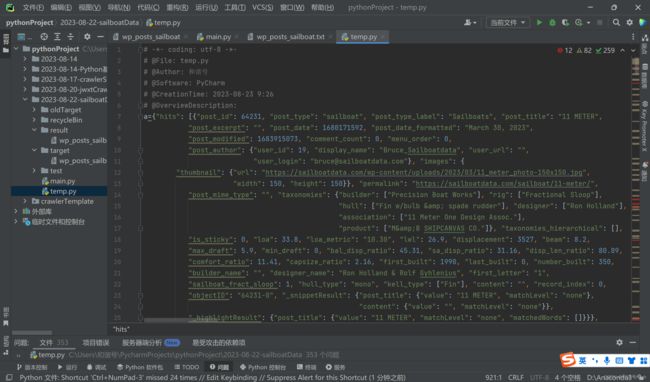
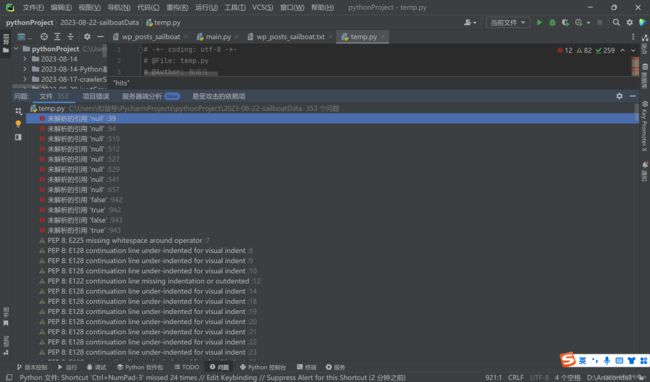
可以发现,只有12处报错,这其实是python数据格式与json不同的地方,我们用Ctrl+R,把错误替换,null→None,true→True,false→False
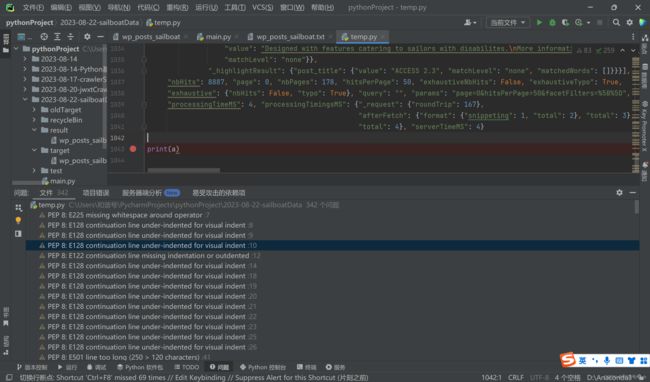
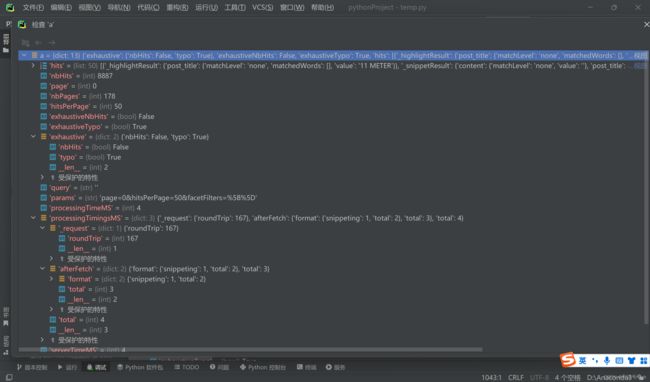
这样就没有报错了,添加断点,debug,检查a,就可以很容易摸清楚它的结构,然后就可以很容易地根据我们的需要保存数据啦~
当然,这里我们只是爬取了这一页,可以手动的进行替换,那如何做到程序化操作呢?
有两种方法:
(1)eval函数
eval函数就是把字符串转成普通变量名。我们可以把一段代码定义成字符串,然后用eval转成普通代码执行。
例如:
eval("print(123)")
a='{1:2,3:4}'
b=eval(a)
print(type(b),b)123
{1: 2, 3: 4}
python之eval()函数---将字符串str转换为列表,字典,元组等 - anna1210 - 博客园 (cnblogs.com)
【知识点】eval() 的用法_Rachel MuZy的博客-CSDN博客
因此,我们在原来的爬虫代码后面添加如下语句:
for i, item in enumerate(os.listdir()):
html=crawler.main(item,data=data)
print("爬取结果为:\n", html)
# time.sleep(random.randint(-2500,2500)/1000+5)
html=html.replace("null","None")
html=html.replace("false","False")
html=html.replace("true","True")
html=eval(html)
print(type(html),html) 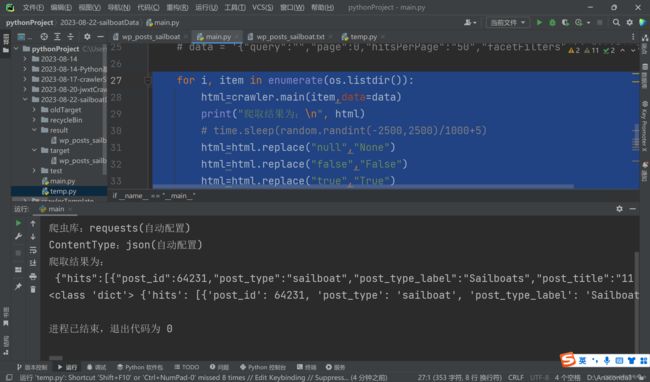
(注意replace不会改变原来对象,要自我赋值)
即可得到字典型的结果,然后提取数据即可。
(2)json.loads()方法
Python的json.loads() 方法_和谐号hexh的博客-CSDN博客
for i, item in enumerate(os.listdir()):
html=crawler.main(item,data=data)
print("爬取结果为:\n", html)
# time.sleep(random.randint(-2500,2500)/1000+5)
# html=html.replace("null","None")
# html=html.replace("false","False")
# html=html.replace("true","True")
# html=eval(html)
html=json.loads(html)
print(type(html),html)
也能到达相同的效果。
2.网页型的数据
以上方法的优点是便捷,但是不足之处是可能数据不够丰富,因此我们想到去对每个帆船的详情页进行爬取:
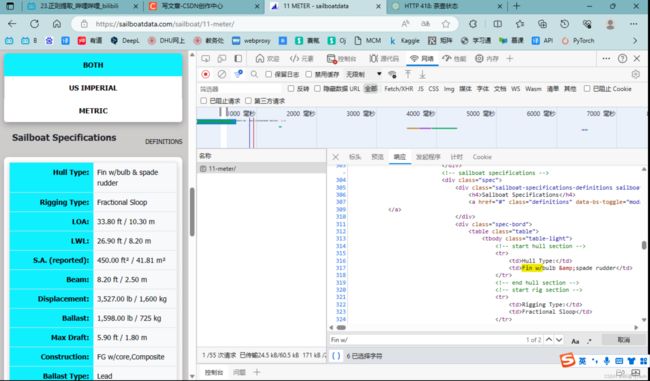
进入详情页,我们发现,数据就是存在于第一个url中:
https://sailboatdata.com/sailboat/11-meter/
这个网址的特点也很鲜明,格式是https://sailboatdata.com/sailboat/帆船名称/
因此,我们可以用之前所讲的方法得到这8887条帆船的名称,然后组合成8887个url进行爬取。
这里,我们仍然以一个帆船为例。
我们使用我的模板进行爬取:
首先制作txt文件,但是这里不知道为什么没有原始复选框
可以复制到docx中,然后替换:

注意替换为后面要有空格
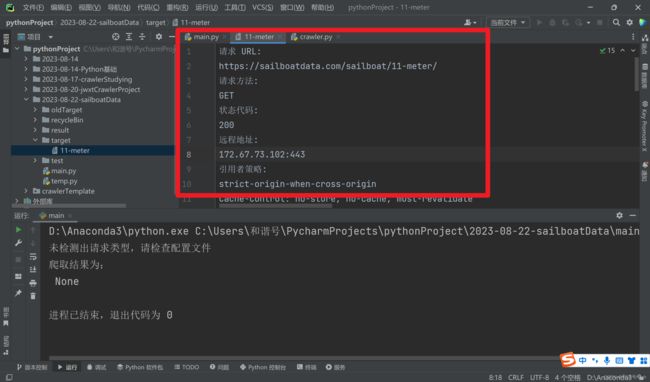
注意这一段不能被替换了。

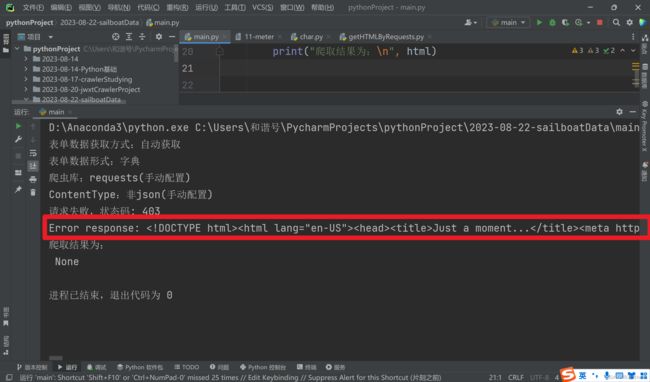
状态码403,表示服务器禁止了我们的请求,错误原因乱码。
修改错误原因的输出格式,改为二进制输出
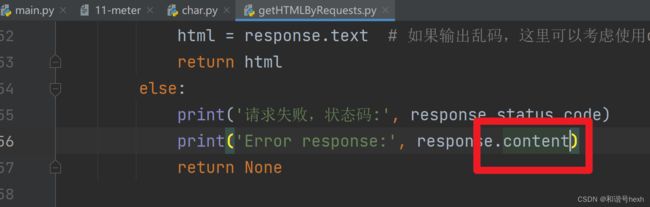
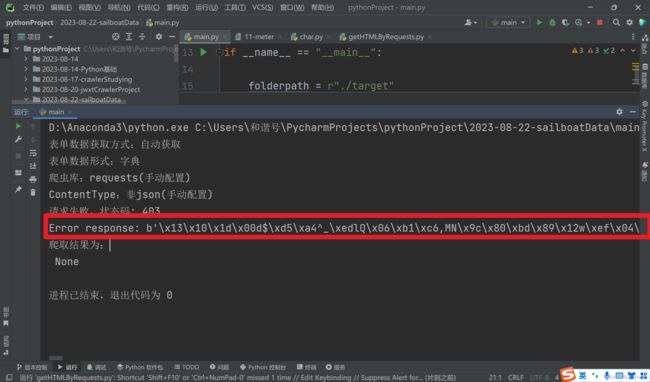
经过一段时间的尝试,以及询问ChatGPT,我最终没能解码出这段二进制文本
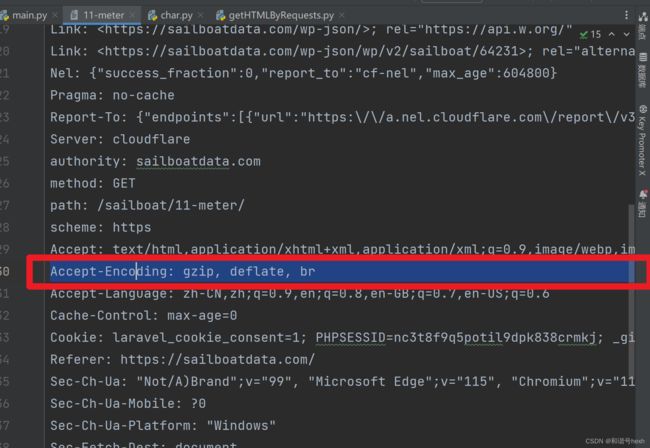
于是我考虑修改请求头
发现,删除该行后再运行,可以正常显示错误提示(把上一步改回成response.text)

ok,百度搜索,尝试解决
期间,我尝试了Docker,vscode,穿云api,selenium等一系列方法,都是徒劳。
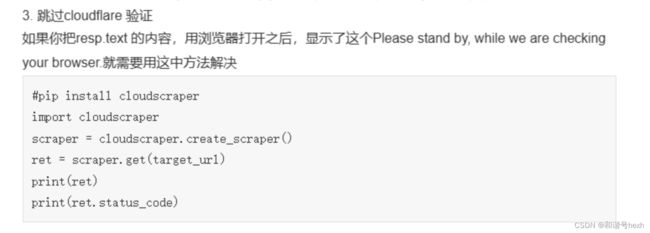
终于使用这篇文章的方法解决了问题:
爬虫 403 增加header和代理ip也没用?有可能是cloudflare在搞事情 (taodudu.cc)
新建main2.py文件
# -*- coding: utf-8 -*-
# @File: char.py
# @Author: 和谐号
# @Software: PyCharm
# @CreationTime: 2023-08-23 10:27
# @OverviewDescription:
import cloudscraper
scraper = cloudscraper.create_scraper()
ret = scraper.get(r'https://sailboatdata.com/sailboat/11-meter/')
print(ret)
print(ret.text)
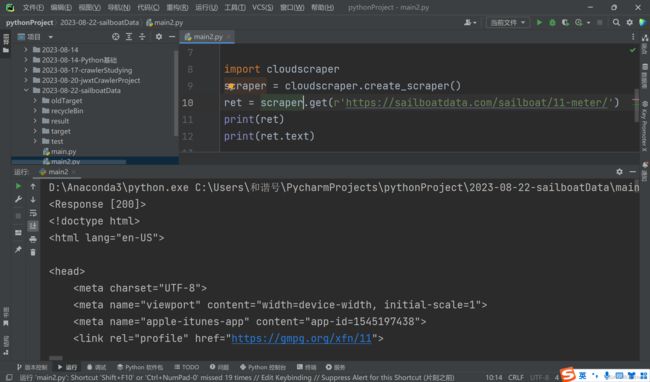
运行成功!
这样得到的内容是网页型的,我们需要做文档解析提取数据,请见我的下一篇文章。
Python爬虫之数据解析——BeautifulSoup亮汤模块(一):基础与遍历(接上文,2023美赛春季赛帆船数据解析sailboatdata.com)_和谐号hexh的博客-CSDN博客